关于融合模型的一些简单整理(StackingBlending)
Posted 卖山楂啦prss
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了关于融合模型的一些简单整理(StackingBlending)相关的知识,希望对你有一定的参考价值。
目前,模型融合的方式有很多,比较常用的包括Voting法、Stacking法以及Blending法。
一、Voting
Voting是模型融合策略中最简单的一种方法,其融合过程不需要建立新的模型,只需要在单一模型的输出结果上完成融合。
Voting可以分为硬投票(Hard Voting)和软投票(Soft Voting)。
- 硬投票(Hard Voting)是指对每个模型给出的样本分类结果以少数服从多数的方式产生最终结果,例如对于一个二分类问题,分别使用逻辑回归模型、支持向量机模型以及随机森林模型进行预测,预测结果分别为0、1、1,那么以投票的方式输出融合结果为1。
- 软投票(Soft Voting)是指将各个模型预测样本为某一类别的概率的平均值大小来决定所属类别,例如对于一个二分类问题,分别使用逻辑回归模型、支持向量机模型以及随机森林模型对某一样本进行预测,该样本被预测为0类别或1类别的概率分别为[0:0.99,1:0.01]、[0:0.49,1:0.51]、[0:0.4,1:0.6],那么对于0类别来说,平均预测概率为(0.99+0.49+0.4)/3=0.62,而对于1类别的平均预测概率为(0.01+0.51+0.6)/3=0.38,则最终模型融合预测结果为0。
二、Stacking
Stacking是一种嵌套组合型的模型融合方法,其基本思路就是在第一层训练多个不同的基学习器,然后把第一层训练的各个基学习器的输出作为输入来训练第二层的学习器,从而得到一个最终的输出。
具体的构建思路如下:
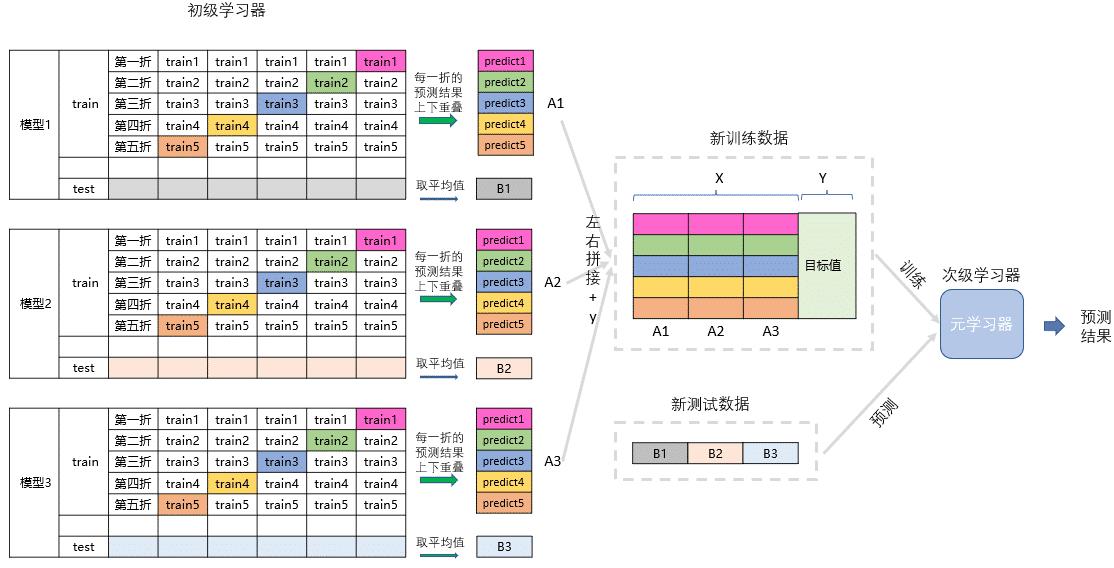
用一个基础模型进行5折交叉验证,对于训练集先拿出4折作为训练数据,另外一折作为测试数据,每一次交叉验证我们都会基于训练数据训练生成的模型对测试数据进行预测,这部分预测值最后拼接起来就是第二层模型的训练集。同时每次交叉验证我们还要对数据集原来的整个测试集进行预测,最后将各部分预测值取算术平均,作为第二层模型测试集,在此之后,我们把第一层模型的训练集预测值并列合并得到的矩阵作为训练集,第一层模型的预测集预测值并列合并得到的矩阵作为测试集,带入第二层的模型,再基于它们进一步训练,从而得到最终预测结果。
(1)
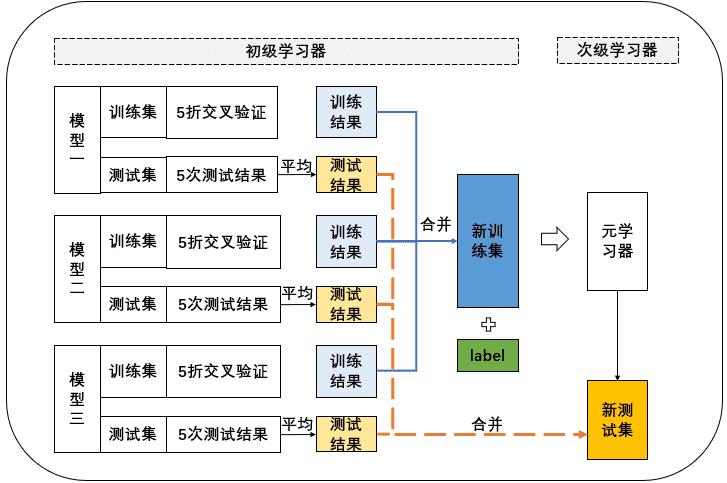
(2)
Stacking融合模型在建立时有很多技巧和注意事项,这里不过多介绍,可以多看看其他博客或者论文。
三、Blending
B1ending模型与Stacking模型预测过程大致相似,通常情况下模型训练也是要经过两轮,不同之处在于,Blending划分的训练集不需要交叉验证,而是通过独立划分出来的验证集输入到基模型中,得到第二层模型的训练数据。
具体的,B1ending模型首先将原始数据划分为训练集、验证集和测试集,其中训练集用来训练各个基模型,验证集输入已经训练好的基模型中,得出验证结果将作为第二层模型的训练集数据,测试集用来测试整体模型的性能,得出的测试结果将作为第二层模型的预测集数据。具体的构建思路如下:
(1)划分数据集

(2)融合模型构建
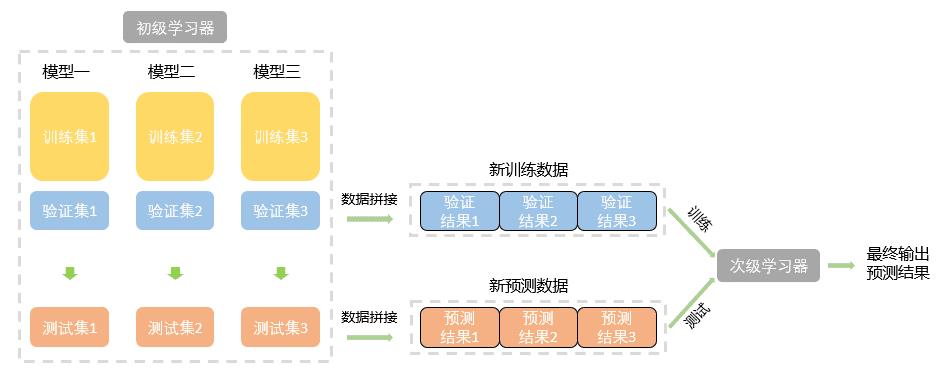
可以看出,相比较Stacking融合算法,由于没有进行五折交叉验证,因此Blending融合算法更加简单。
事实上,由于Stacking第一层模型需要进行K折交叉验证,并且训练元模型时使用的是整个训练集数量的数据,所以Stacking模型花费的总体时间要比Blending更多,第二层模型使用的数据量也要比Blending更多。
其次,Stacking有很多数据都是重复使用的,所以Stacking相比Blending可能存在信息泄漏的风险。
以上是关于关于融合模型的一些简单整理(StackingBlending)的主要内容,如果未能解决你的问题,请参考以下文章