Linux应用层协议—http
Posted 一起去看日落吗
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Linux应用层协议—http相关的知识,希望对你有一定的参考价值。
🎇Linux:
- 博客主页:一起去看日落吗
- 分享博主的在Linux中学习到的知识和遇到的问题
博主的能力有限,出现错误希望大家不吝赐教- 分享给大家一句我很喜欢的话: 看似不起波澜的日复一日,一定会在某一天让你看见坚持的意义,祝我们都能在鸡零狗碎里找到闪闪的快乐🌿🌞🐾。

目录
💫 1. HTTP协议
🌟 1.1 HTTP简介
HTTP(Hyper Text Transfer Protocol)协议又叫做超文本传输协议,是一个简单的请求-响应协议,HTTP通常运行在TCP之上。
在编写网络通信代码时,我们可以自己进行协议的定制,但实际有很多优秀的工程师早就已经写出了许多非常成熟的应用层协议,其中最典型的就是HTTP协议。
🌟 1.2 认识URL
URL(Uniform Resource Lacator)叫做统一资源定位符,也就是我们通常所说的网址,是因特网的万维网服务程序上用于指定信息位置的表示方法。
一个URL大致由如下几部分构成:

- 协议方案名
http://表示的是协议名称,表示请求时需要使用的协议,通常使用的是HTTP协议或安全协议HTTPS。HTTPS是以安全为目标的HTTP通道,在HTTP的基础上通过传输加密和身份认证保证了传输过程的安全性。
常见的应用层协议:
- DNS(Domain Name System)协议:域名系统。
- FTP(File Transfer Protocol)协议:文件传输协议。
- TELNET(Telnet)协议:远程终端协议。
- HTTP(Hyper Text Transfer Protocol)协议:超文本传输协议。
- HTTPS(Hyper Text Transfer Protocol over SecureSocket Layer)协议:安全数据传输协议。
- SMTP(Simple Mail Transfer Protocol)协议:电子邮件传输协议。
- POP3(Post Office Protocol - Version 3)协议:邮件读取协议。
- SNMP(Simple Network Management Protocol)协议:简单网络管理协议。
- TFTP(Trivial File Transfer Protocol)协议:简单文件传输协议。
- 登录信息
usr:pass表示的是登录认证信息,包括登录用户的用户名和密码。虽然登录认证信息可以在URL中体现出来,但绝大多数URL的这个字段都是被省略的,因为登录信息可以通过其他方案交付给服务器。
- 服务器地址
www.example.jp表示的是服务器地址,也叫做域名,比如www.alibaba.com,www.qq.com,www.baidu.com。
需要注意的是,我们用IP地址标识公网内的一台主机,但IP地址本身并不适合给用户看。比如说我们可以通过ping命令,分别获得www.baidu.com和www.qq.com这两个域名解析后的IP地址。
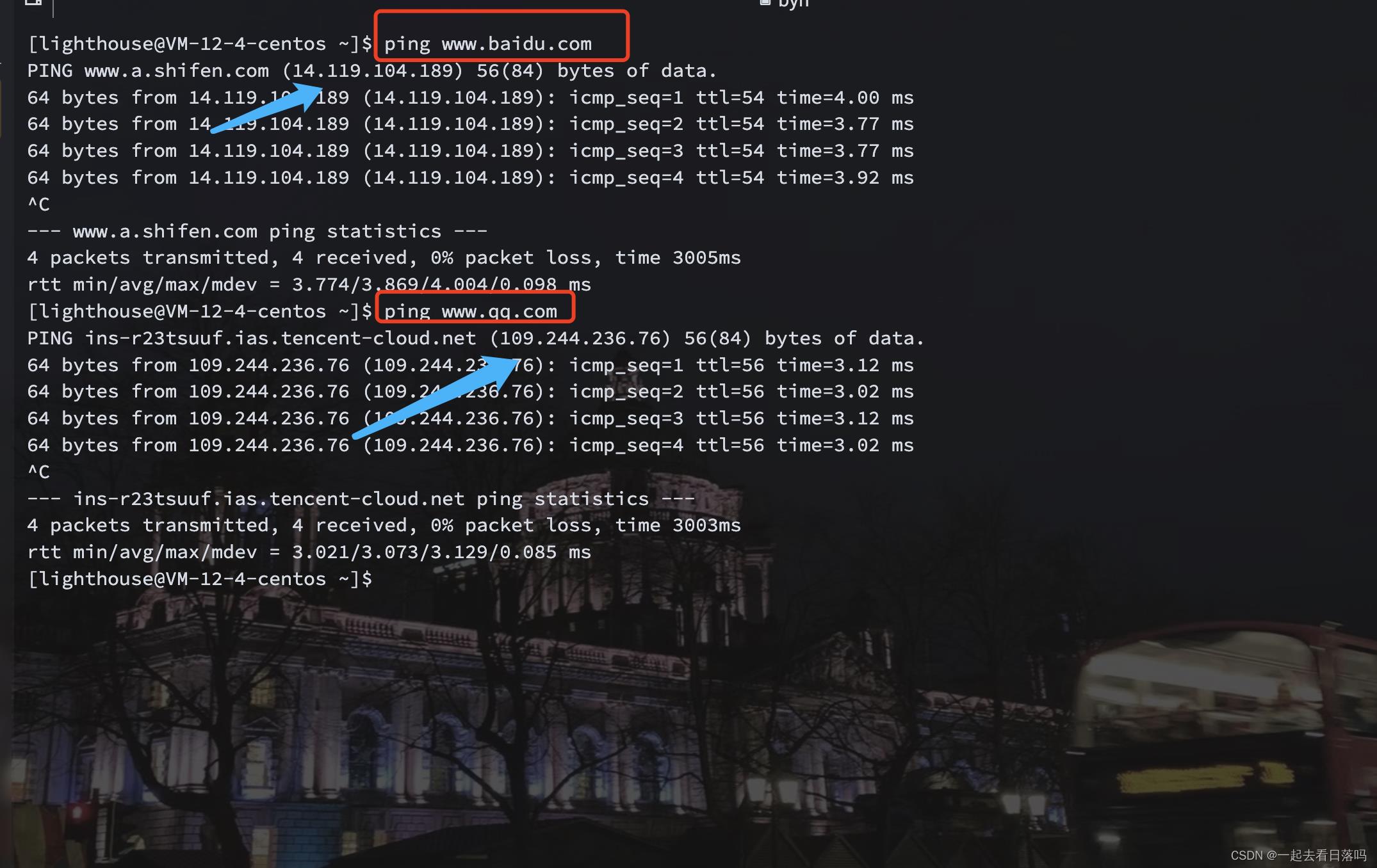
如果用户看到的是这两个IP地址,那么用户在访问这个网站之前并不知道这两个网站到底是干什么的,但如果用户看到的是www.baidu.com和www.qq.com这两个域名,那么用户至少知道这两个网站分别对应的是哪家公司,因此域名具有更好的自描述性。
实际我们可以认为域名和IP地址是等价的,在计算机当中使用的时候既可以使用域名,也可以使用IP地址。但URL呈现出来是可以让用户看到的,因此URL当中是以域名的形式表示服务器地址的。
- 服务器端口号
80表示的是服务器端口号。HTTP协议和套接字编程一样都是位于应用层的,在进行套接字编程时我们需要给服务器绑定对应的IP和端口,而这里的应用层协议也同样需要有明确的端口号。
常见协议对应的端口号:
| 协议名称 | 对应端口号 |
|---|---|
| HTTP | 80 |
| HTTPS | 443 |
| SSH | 22 |
当我们使用某种协议时,该协议实际就是在为我们提供服务,现在这些常用的服务与端口号之间的对应关系都是明确的,所以我们在使用某种协议时实际是不需要指明该协议对应的端口号的,因此在URL当中,服务器的端口号一般也是被省略的。
- 带层次的文件路径
/dir/index.htm表示的是要访问的资源所在的路径。访问服务器的目的是获取服务器上的某种资源,通过前面的域名和端口已经能够找到对应的服务器进程了,此时要做的就是指明该资源所在的路径。
比如我们打开浏览器输入百度的域名后,此时浏览器就帮我们获取到了百度的首页。
 当我们发起网页请求时,本质是获得了这样的一张网页信息,然后浏览器对这张网页信息进行解释,最后就呈现出了对应的网页。
当我们发起网页请求时,本质是获得了这样的一张网页信息,然后浏览器对这张网页信息进行解释,最后就呈现出了对应的网页。
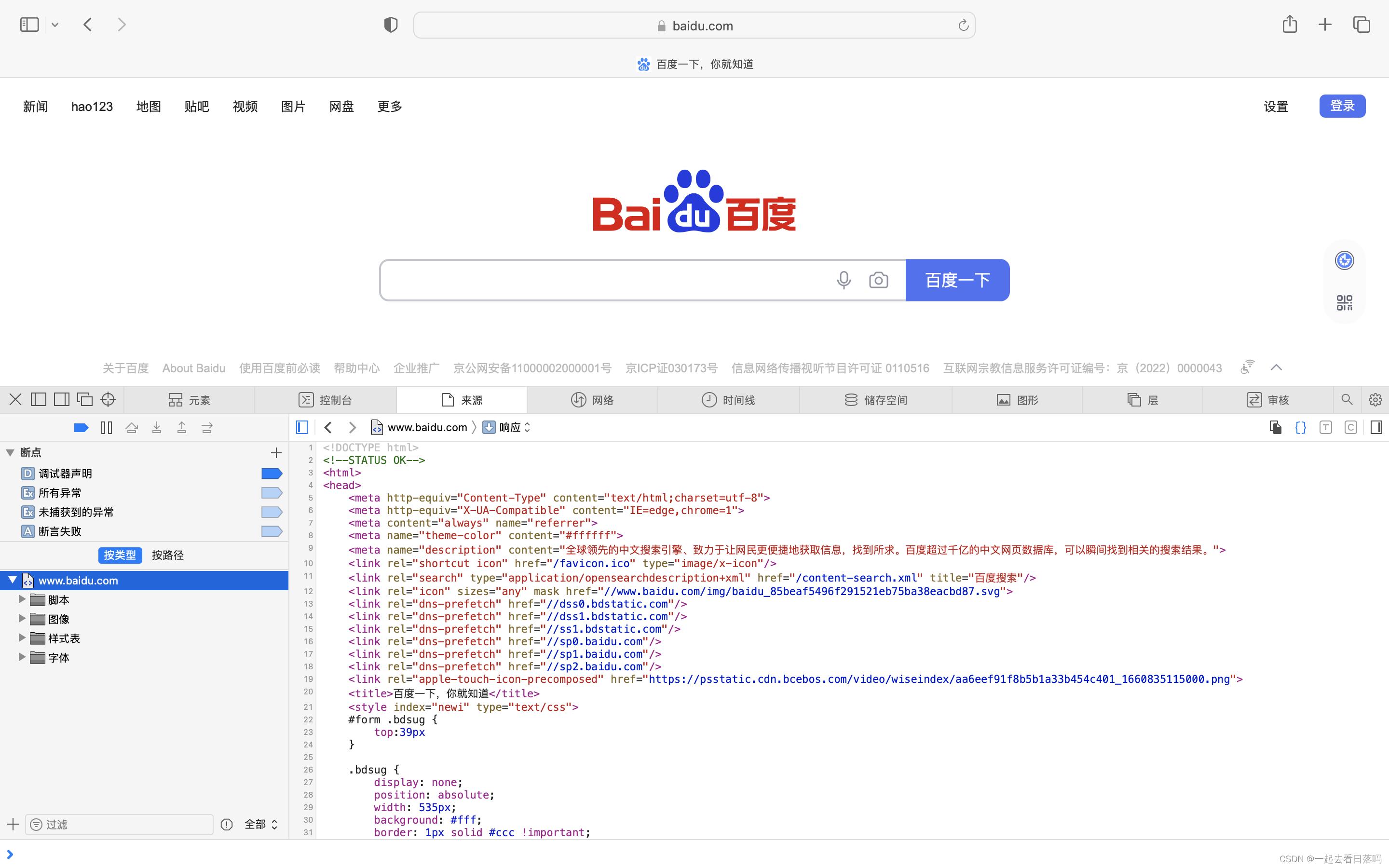
我们可以将这种资源称为网页资源,此外我们还会向服务器请求视频、音频、网页、图片等资源。HTTP之所以叫做超文本传输协议,而不叫做文本传输协议,就是因为有很多资源实际并不是普通的文本资源。
因此在URL当中就有这样一个字段,用于表示要访问的资源所在的路径。此外我们可以看到,这里的路径分隔符是/,而不是\\,这也就证明了实际很多服务都是部署在Linux上的。
- 查询字符串
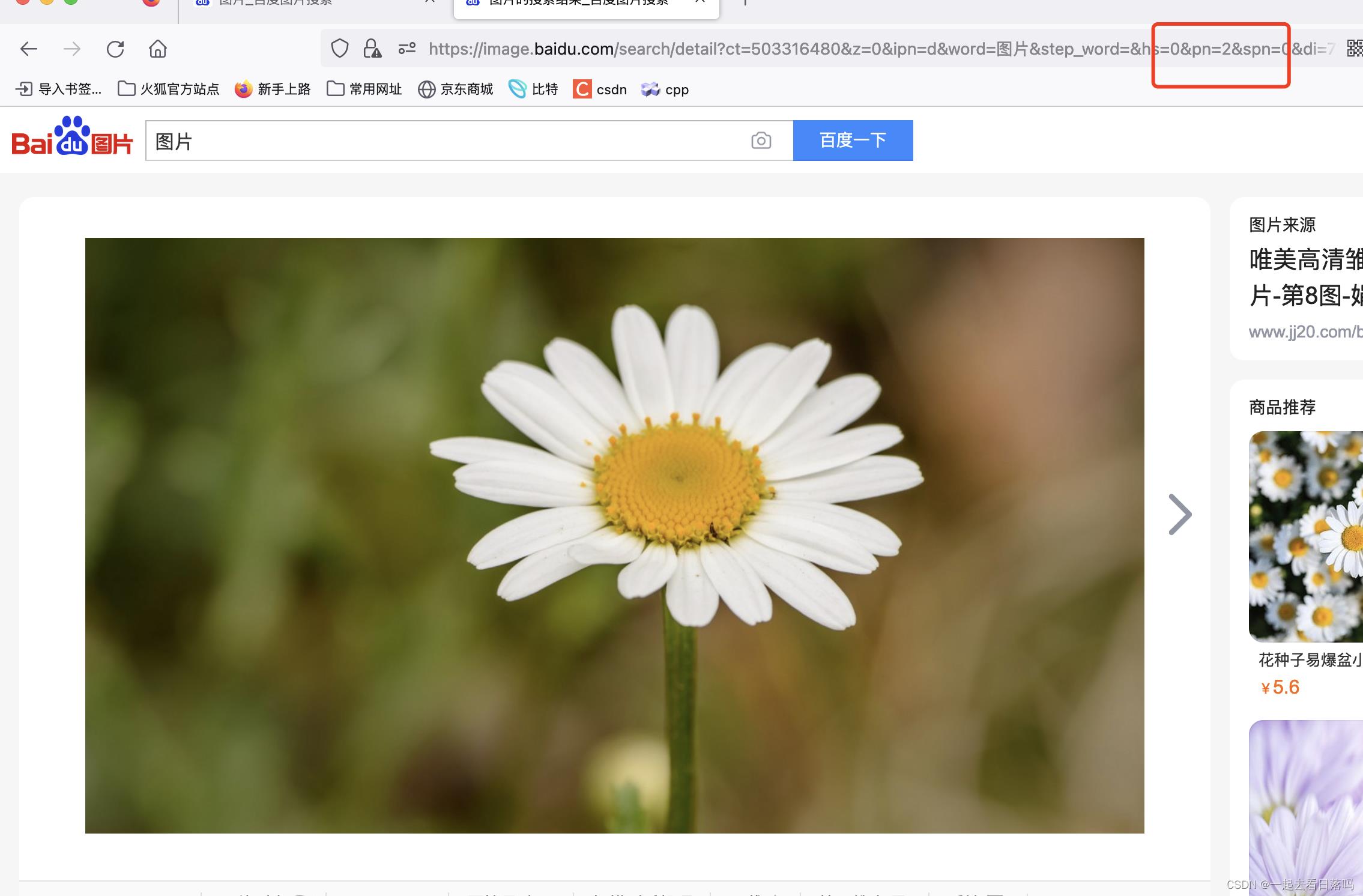
uid=1表示的是请求时提供的额外的参数,这些参数是以键值对的形式,通过&符号分隔开的。
比如我们在百度上面搜索HTTP,此时可以看到URL中有很多参数,而在这众多的参数当中有一个参数wd(word),表示的就是我们搜索时的搜索关键字wd=HTTP。
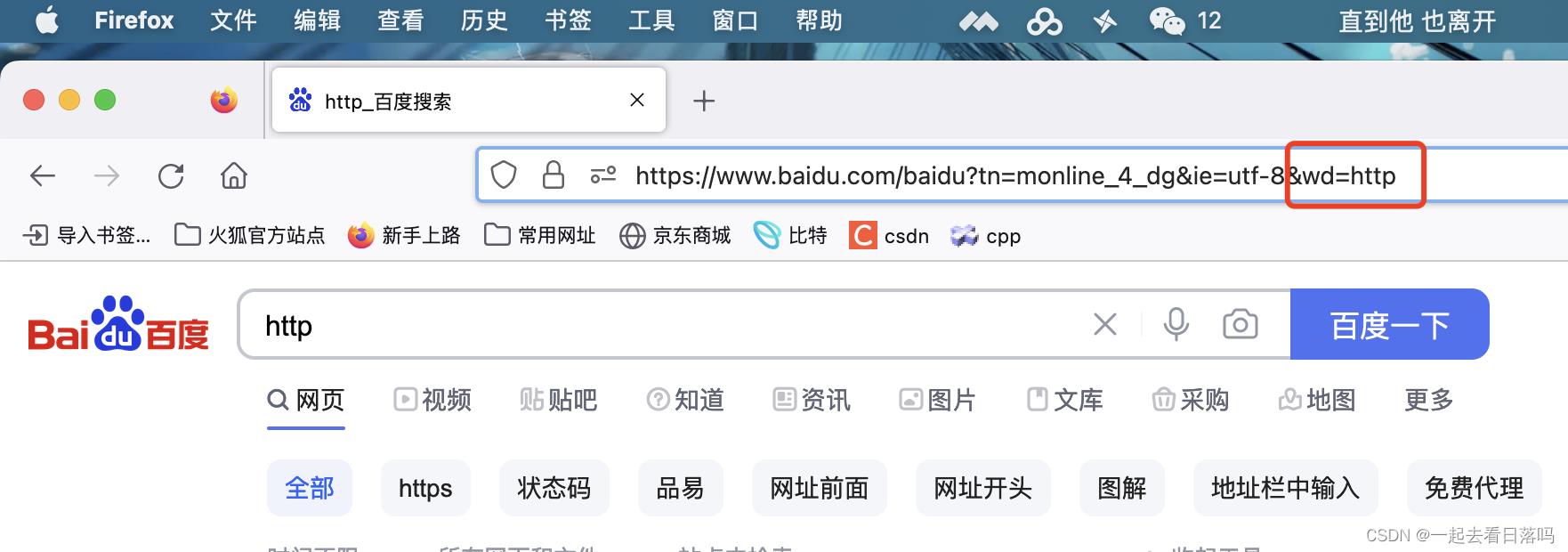
因此双方在进行网络通信时,是能够通过URL进行用户数据传送的。
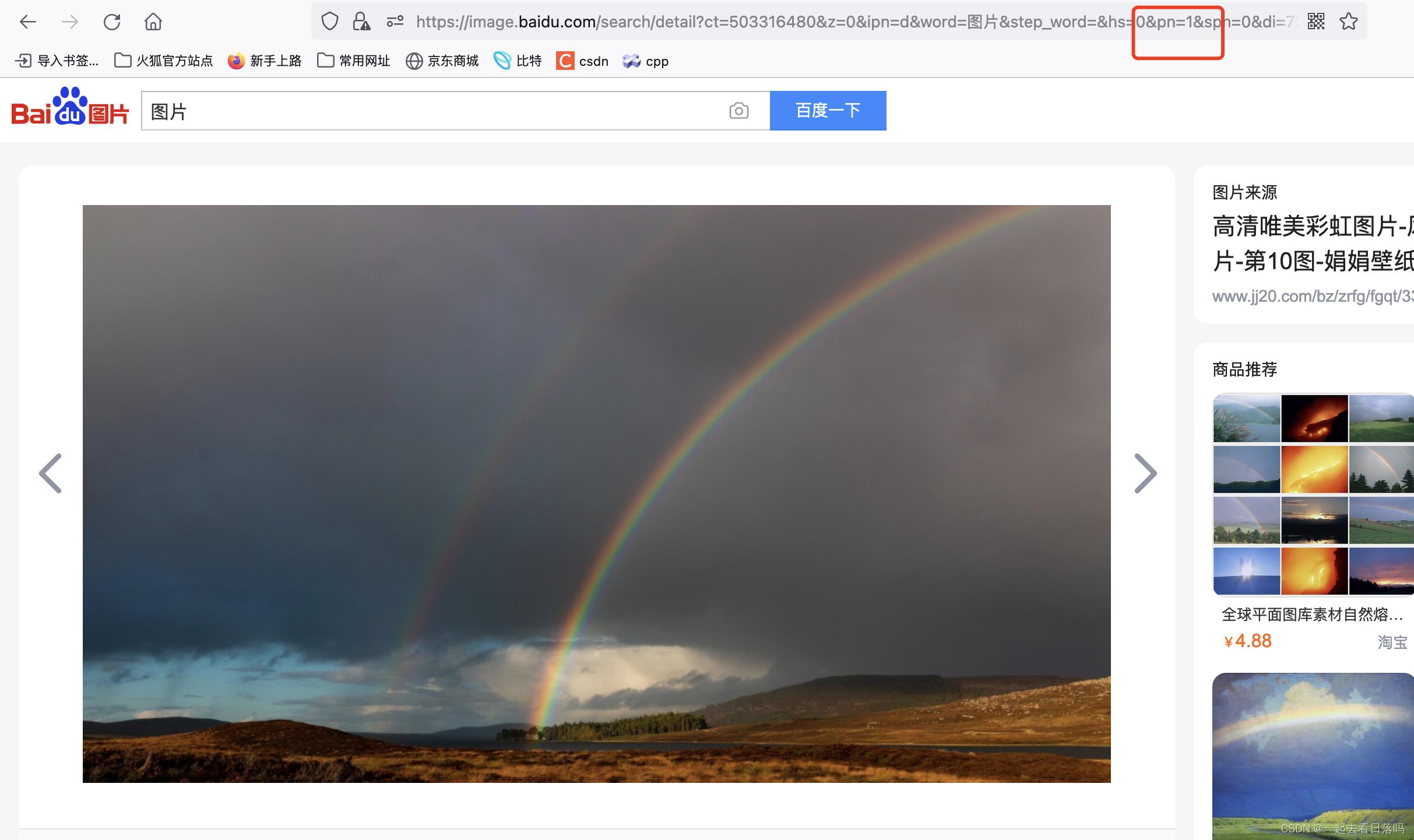
- 片段标识符
ch1表示的是片段标识符,是对资源的部分补充。
我们在看组图的时候,URL当中就会出现片段标识符。
🌟 1.3 urlencode和urldecode
像 / ? : 等这样的字符, 已经被url当做特殊意义理解了. 因此这些字符不能随意出现.
比如, 某个参数中需要带有这些特殊字符, 就必须先对特殊字符进行转义.
转义的规则如下:
- 将需要转码的字符转为16进制,然后从右到左,取4位(不足4位直接处理),每2位做一位,前面加上%,编码成%XY格式
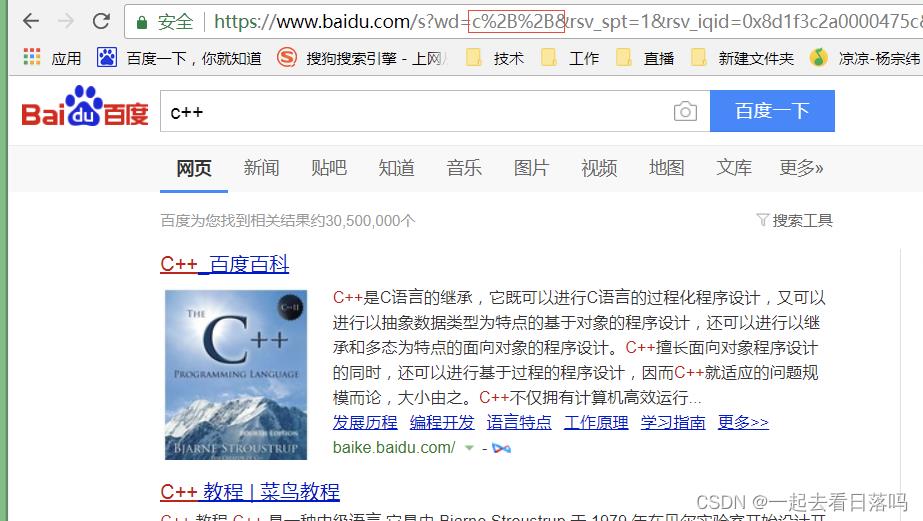
“+” 被转义成了 “%2B”
urldecode就是urlencode的逆过程;
🌟 1.4 HTTP协议格式
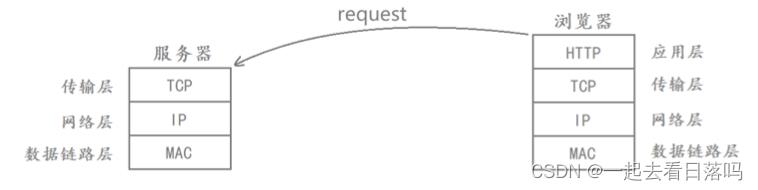
应用层常见的协议有HTTP和HTTPS,传输层常见的协议有TCP,网络层常见的协议是IP,数据链路层对应就是MAC帧了。其中下三层是由操作系统或者驱动帮我们完成的,它们主要负责的是通信细节。如果应用层不考虑下三层,在应用层自己的心目当中,它就可以认为自己是在和对方的应用层在直接进行数据交互。

下三层负责的是通信细节,而应用层负责的是如何使用传输过来的数据,两台主机在进行通信的时候,应用层的数据能够成功交给对端应用层,因为网络协议栈的下三层已经负责完成了这样的通信细节,而如何使用传输过来的数据就需要我们去定制协议,这里最典型的就是HTTP协议。
HTTP是基于请求和响应的应用层服务,作为客户端,你可以向服务器发起request,服务器收到这个request后,会对这个request做数据分析,得出你想要访问什么资源,然后服务器再构建response,完成这一次HTTP的请求。这种基于request&response这样的工作方式,我们称之为cs或bs模式,其中c表示client,s表示server,b表示browser。
由于HTTP是基于请求和响应的应用层访问,因此我们必须要知道HTTP对应的请求格式和响应格式,这就是学习HTTP的重点。
1.3.1 ⭐️ HTTP请求协议格式
HTTP请求协议格式如下:

HTTP请求由以下四部分组成:
- 请求行:[请求方法]+[url]+[http版本]
- 请求报头:请求的属性,这些属性都是以key: value的形式按行陈列的。
- 空行:遇到空行表示请求报头结束。
- 请求正文:请求正文允许为空字符串,如果请求正文存在,则在请求报头中会有一个Content-Length属性来标识请求正文的长度。
其中,前面三部分是一般是HTTP协议自带的,是由HTTP协议自行设置的,而请求正文一般是用户的相关信息或数据,如果用户在请求时没有信息要上传给服务器,此时请求正文就为空字符串。
- 如何将HTTP请求的报头与有效载荷进行分离?
当应用层收到一个HTTP请求时,它必须想办法将HTTP的报头与有效载荷进行分离。对于HTTP请求来讲,这里的请求行和请求报头就是HTTP的报头信息,而这里的请求正文实际就是HTTP的有效载荷。
我们可以根据HTTP请求当中的空行来进行分离,当服务器收到一个HTTP请求后,就可以按行进行读取,如果读取到空行则说明已经将报头读取完毕,实际HTTP请求当中的空行就是用来分离报头和有效载荷的。
如果将HTTP请求想象成一个大的线性结构,此时每行的内容都是用\\n隔开的,因此在读取过程中,如果连续读取到了两个\\n,就说明已经将报头读取完毕了,后面剩下的就是有效载荷了。
- 获取浏览器的HTTP请求
在网络协议栈中,应用层的下一层叫做传输层,而HTTP协议底层通常使用的传输层协议是TCP协议,因此我们可以用套接字编写一个TCP服务器,然后启动浏览器访问我们的这个服务器。
由于我们的服务器是直接用TCP套接字读取浏览器发来的HTTP请求,此时在服务端没有应用层对这个HTTP请求进行过任何解析,因此我们可以直接将浏览器发来的HTTP请求进行打印输出,此时就能看到HTTP请求的基本构成。
因此下面我们编写一个简单的TCP服务器,这个服务器要做的就是把浏览器发来的HTTP请求进行打印即可。
#include <iostream>
#include <fstream>
#include <string>
#include <cstring>
#include <unistd.h>
#include <sys/wait.h>
#include <sys/socket.h>
#include <sys/types.h>
#include <netinet/in.h>
#include <arpa/inet.h>
using namespace std;
int main()
//创建套接字
int listen_sock = socket(AF_INET, SOCK_STREAM, 0);
if (listen_sock < 0)
cerr << "socket error!" << endl;
return 1;
//绑定
struct sockaddr_in local;
memset(&local, 0, sizeof(local));
local.sin_family = AF_INET;
local.sin_port = htons(8081);
local.sin_addr.s_addr = htonl(INADDR_ANY);
if (bind(listen_sock, (struct sockaddr*)&local, sizeof(local)) < 0)
cerr << "bind error!" << endl;
return 2;
//监听
if (listen(listen_sock, 5) < 0)
cerr << "listen error!" << endl;
return 3;
//启动服务器
struct sockaddr peer;
memset(&peer, 0, sizeof(peer));
socklen_t len = sizeof(peer);
for (;;)
int sock = accept(listen_sock, (struct sockaddr*)&peer, &len);
if (sock < 0)
cerr << "accept error!" << endl;
continue;
if (fork() == 0) //爸爸进程
close(listen_sock);
if (fork() > 0) //爸爸进程
exit(0);
//孙子进程
char buffer[1024];
recv(sock, buffer, sizeof(buffer), 0); //读取HTTP请求
cout << "--------------------------http request begin--------------------------" << endl;
cout << buffer << endl;
cout << "---------------------------http request end---------------------------" << endl;
close(sock);
exit(0);
//爷爷进程
close(sock);
waitpid(-1, nullptr, 0); //等待爸爸进程
return 0;
运行服务器程序后,然后用浏览器进行访问,此时我们的服务器就会收到浏览器发来的HTTP请求,并将收到的HTTP请求进行打印输出。
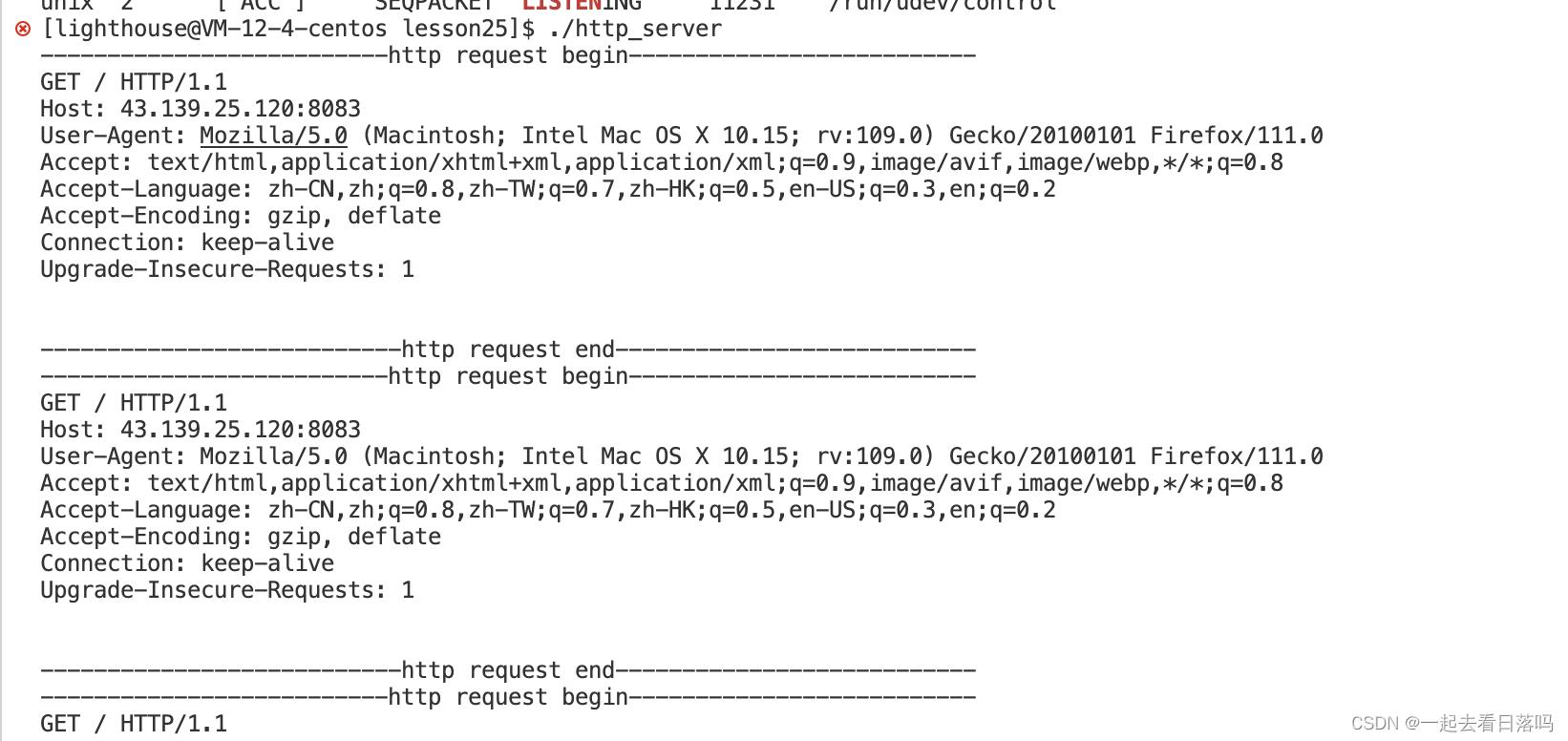
说明一下:
- 浏览器向我们的服务器发起HTTP请求后,因为我们的服务器没有对进行响应,此时浏览器就会认为服务器没有收到,然后再不断发起新的HTTP请求,因此虽然我们只用浏览器访问了一次,但会受到多次HTTP请求。
- 由于浏览器发起请求时默认用的就是HTTP协议,因此我们在浏览器的url框当中输入网址时可以不用指明HTTP协议。
- url当中的/不能称之为我们云服务器上根目录,这个/表示的是web根目录,这个web根目录可以是你的机器上的任何一个目录,这个是可以自己指定的,不一定就是Linux的根目录。
其中请求行当中的url一般是不携带域名以及端口号的,因为在请求报头中的Host字段当中会进行指明,请求行当中的url表示你要访问这个服务器上的哪一路径下的资源。如果浏览器在访问我们的服务器时指明要访问的资源路径,那么此时浏览器发起的HTTP请求当中的url也会跟着变成该路径。
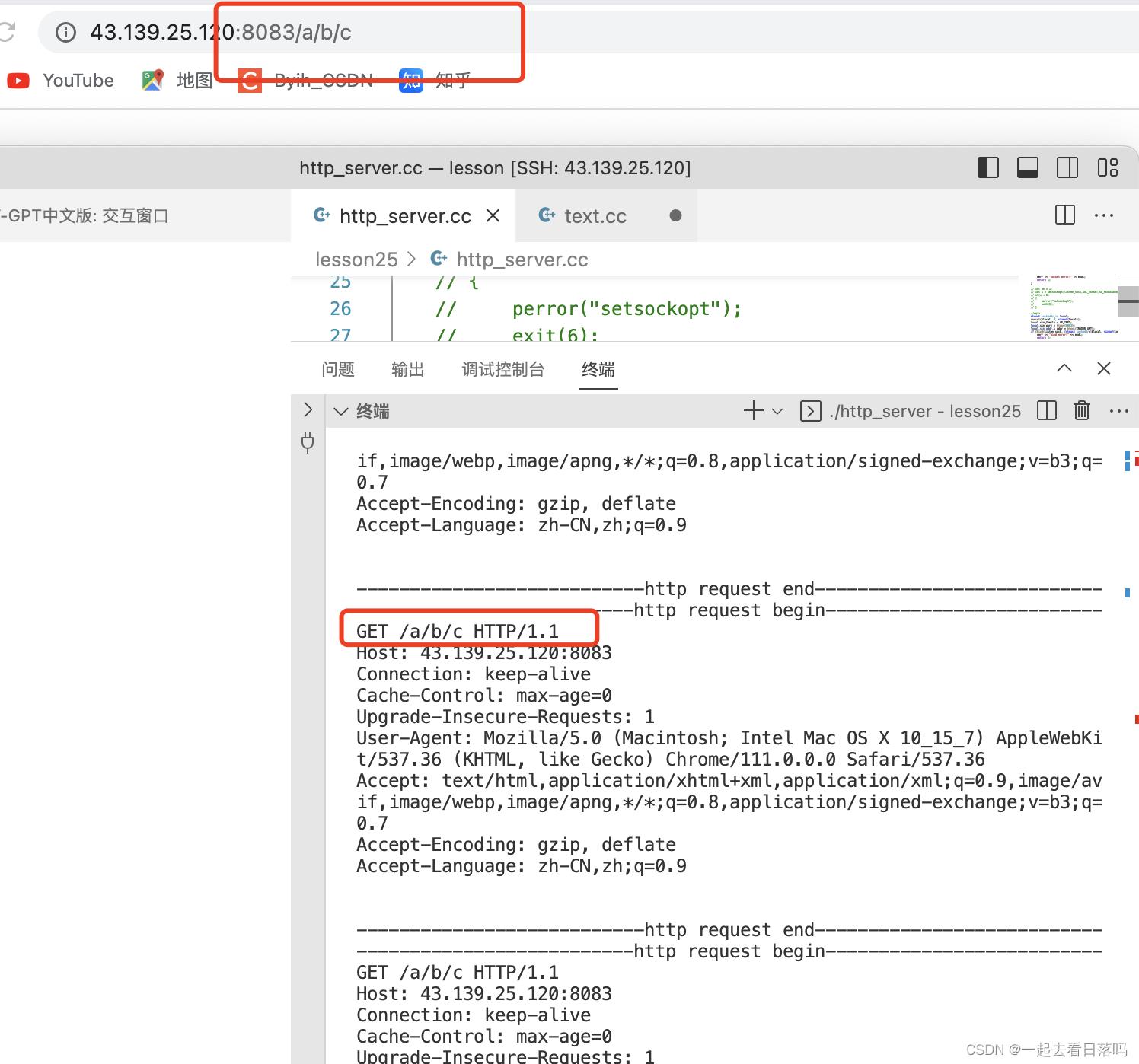
而请求报头当中全部都是以key: value形式按行陈列的各种请求属性,请求属性陈列完后紧接着的就是一个空行,空行后的就是本次HTTP请求的请求正文,此时请求正文为空字符串,因此这里有两个空行。
1.3.2 ⭐️ HTTP响应协议格式
HTTP响应协议格式如下:

HTTP响应由以下四部分组成:
- 状态行:[http版本]+[状态码]+[状态码描述]
- 响应报头:响应的属性,这些属性都是以key: value的形式按行陈列的。
- 空行:遇到空行表示响应报头结束。
- 响应正文:响应正文允许为空字符串,如果响应正文存在,则响应报头中会有一个Content-Length属性来标识响应正文的长度。比如服务器返回了一个html页面,那么这个html页面的内容就是在响应正文当中的。
如何将HTTP响应的报头与有效载荷进行分离?
对于HTTP响应来讲,这里的状态行和响应报头就是HTTP的报头信息,而这里的响应正文实际就是HTTP的有效载荷。与HTTP请求相同,当应用层收到一个HTTP响应时,也是根据HTTP响应当中的空行来分离报头和有效载荷的。当客户端收到一个HTTP响应后,就可以按行进行读取,如果读取到空行则说明报头已经读取完毕。
构建HTTP响应给浏览器
服务器读取到客户端发来的HTTP请求后,需要对这个HTTP请求进行各种数据分析,然后构建成对应的HTTP响应发回给客户端。而我们的服务器连接到客户端后,实际就只读取了客户端发来的HTTP请求就将连接断开了。
接下来我们可以构建一个HTTP请求给浏览器,鉴于现在还没有办法分析浏览器发来的HTTP请求,这里我们可以给浏览器返回一个固定的HTTP响应。我们就将当前服务程序所在的路径作为我们的web根目录,我们可以在该目录下创建一个html文件,然后编写一个简单的html作为当前服务器的首页。
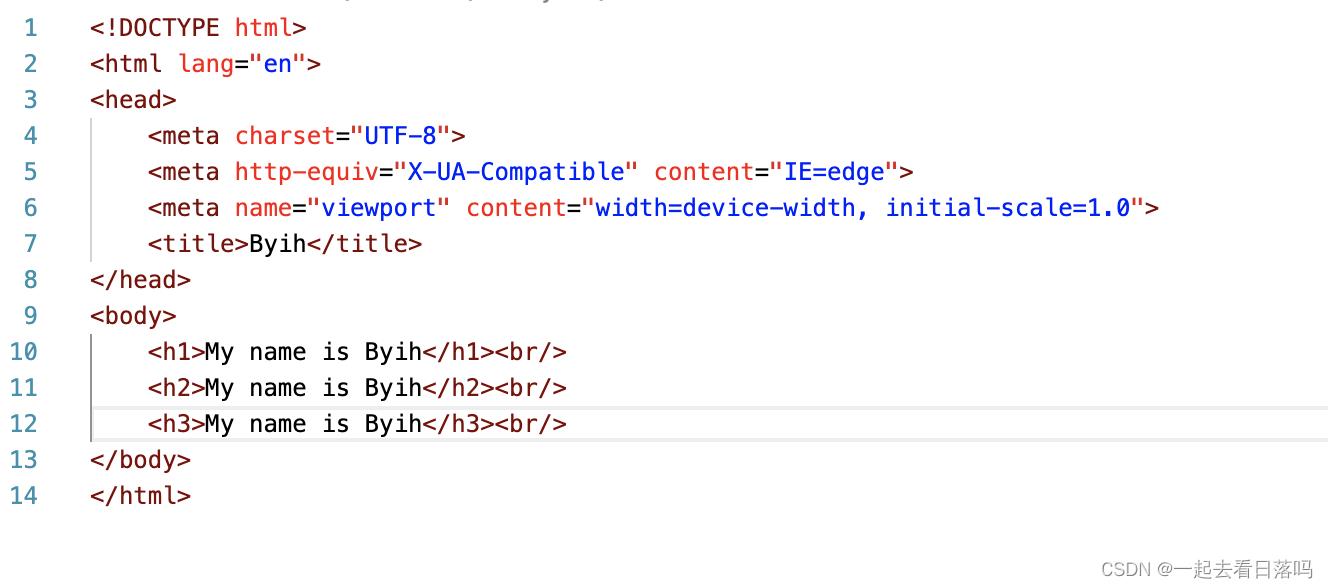
当浏览器向服务器发起HTTP请求时,不管浏览器发来的是什么请求,我们都将这个网页响应给浏览器,此时这个html文件的内容就应该放在响应正文当中,我们只需读取该文件当中的内容,然后将其作为响应正文即可。
#include <iostream>
#include <fstream>
#include <string>
#include <cstring>
#include <unistd.h>
#include <sys/wait.h>
#include <sys/socket.h>
#include <sys/types.h>
#include <netinet/in.h>
#include <arpa/inet.h>
using namespace std;
int main()
//创建套接字
int listen_sock = socket(AF_INET, SOCK_STREAM, 0);
if (listen_sock < 0)
cerr << "socket error!" << endl;
return 1;
//绑定
struct sockaddr_in local;
memset(&local, 0, sizeof(local));
local.sin_family = AF_INET;
local.sin_port = htons(8081);
local.sin_addr.s_addr = htonl(INADDR_ANY);
if (bind(listen_sock, (struct sockaddr*)&local, sizeof(local)) < 0)
cerr << "bind error!" << endl;
return 2;
//监听
if (listen(listen_sock, 5) < 0)
cerr << "listen error!" << endl;
return 3;
//启动服务器
struct sockaddr peer;
memset(&peer, 0, sizeof(peer));
socklen_t len = sizeof(peer);
for (;;)
int sock = accept(listen_sock, (struct sockaddr*)&peer, &len);
if (sock < 0)
cerr << "accept error!" << endl;
continue;
if (fork() == 0) //爸爸进程
close(listen_sock);
if (fork() > 0) //爸爸进程
exit(0);
//孙子进程
char buffer[1024];
recv(sock, buffer, sizeof(buffer), 0); //读取HTTP请求
cout << "--------------------------http request begin--------------------------" << endl;
cout << buffer << endl;
cout << "---------------------------http request end---------------------------" << endl;
#define PAGE "index.html" //网站首页
//读取index.html文件
ifstream in(PAGE);
if (in.is_open())
in.seekg(0, in.end);
int len = in.tellg();
in.seekg(0, in.beg);
char* file = new char[len];
in.read(file, len);
in.close();
//构建HTTP响应
string status_line = "http/1.1 200 OK\\n"; //状态行
string response_header = "Content-Length: " + to_string(len) + "\\n"; //响应报头
string blank = "\\n"; //空行
string response_text = file; //响应正文
string response = status_line + response_header + blank + response_text; //响应报文
//响应HTTP请求
send(sock, response.c_str(), response.size(), 0);
delete[] file;
close(sock);
exit(0);
//爷爷进程
close(sock);
waitpid(-1, nullptr, 0); //等待爸爸进程
return 0;
因此当浏览器访问我们的服务器时,服务器会将这个index.html文件响应给浏览器,而该html文件被浏览器解释后就会显示出相应的内容。

此外,我们也可以通过telnet命令来访问我们的服务器,此时也是能够得到这个HTTP响应的。
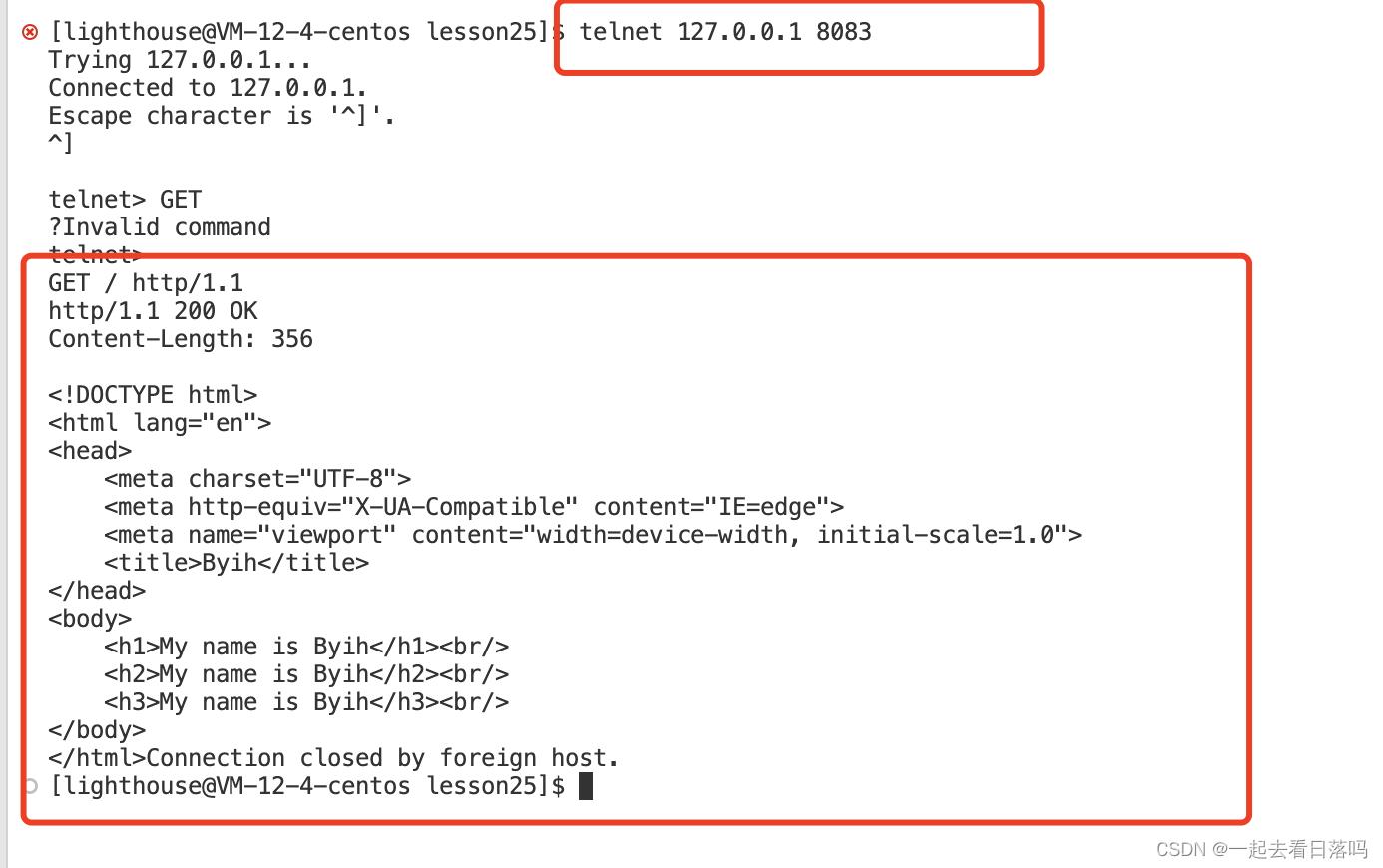
说明一下:
- 实际我们在进行网络请求的时候,如果不指明请求资源的路径,此时默认你想访问的就是目标网站的首页,也就是web根目录下的index.html文件。
- 由于只是作为示例,我们在构建HTTP响应时,在响应报头当中只添加了一个属性信息Content-Length,表示响应正文的长度,实际HTTP响应报头当中的属性信息还有很多。
HTTP为什么要交互版本?
HTTP请求当中的请求行和HTTP响应当中的状态行,当中都包含了http的版本信息。其中HTTP请求是由客户端发的,因此HTTP请求当中表明的是客户端的http版本,而HTTP响应是由服务器发的,因此HTTP响应当中表明的是服务器的http版本。
客户端和服务器双方在进行通信时会交互双方http版本,主要还是为了兼容性的问题。因为服务器和客户端使用的可能是不同的http版本,为了让不同版本的客户端都能享受到对应的服务,此时就要求通信双方需要进行版本协商。
客户端在发起HTTP请求时告诉服务器自己所使用的http版本,此时服务器就可以根据客户端使用的http版本,为客户端提供对应的服务,而不至于因为双方使用的http版本不同而导致无法正常通信。因此为了保证良好的兼容性,通信双方需要交互一下各自的版本信息。
🌟 1.5 HTTP的方法
HTTP常见的方法如下:
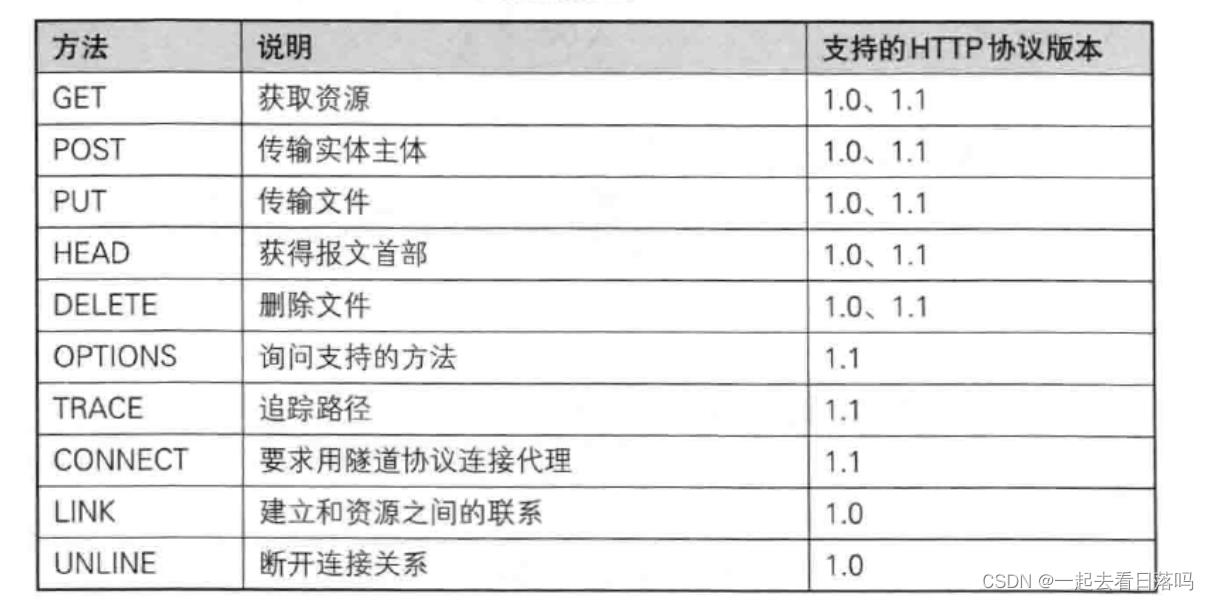
其中最常用的就是GET方法和POST方法。
GET方法和POST方法
GET方法一般用于获取某种资源信息,而POST方法一般用于将数据上传给服务器。但实际我们上传数据时也有可能使用GET方法,比如百度提交数据时实际使用的就是GET方法。
GET方法和POST方法都可以带参:
- GET方法是通过url传参的。
- POST方法是通过正文传参的。
从GET方法和POST方法的传参形式可以看出,POST方法能传递更多的参数,因为url的长度是有限制的,POST方法通过正文传参就可以携带更多的数据。
此外,使用POST方法传参更加私密,因为POST方法不会将你的参数回显到url当中,此时也就不会被别人轻易看到。不能说POST方法比GET方法更安全,因为POST方法和GET方法实际都不安全,要做到安全只能通过加密来完成。
Postman演示GET和POST的区别
如果访问我们的服务器时使用的是GET方法,此时应该通过url进行传参,可以在Params下进行参数设置,因为Postman当中的Params就相当于url当中的参数,你在设置参数时可以看到对应的url也在随之变化。
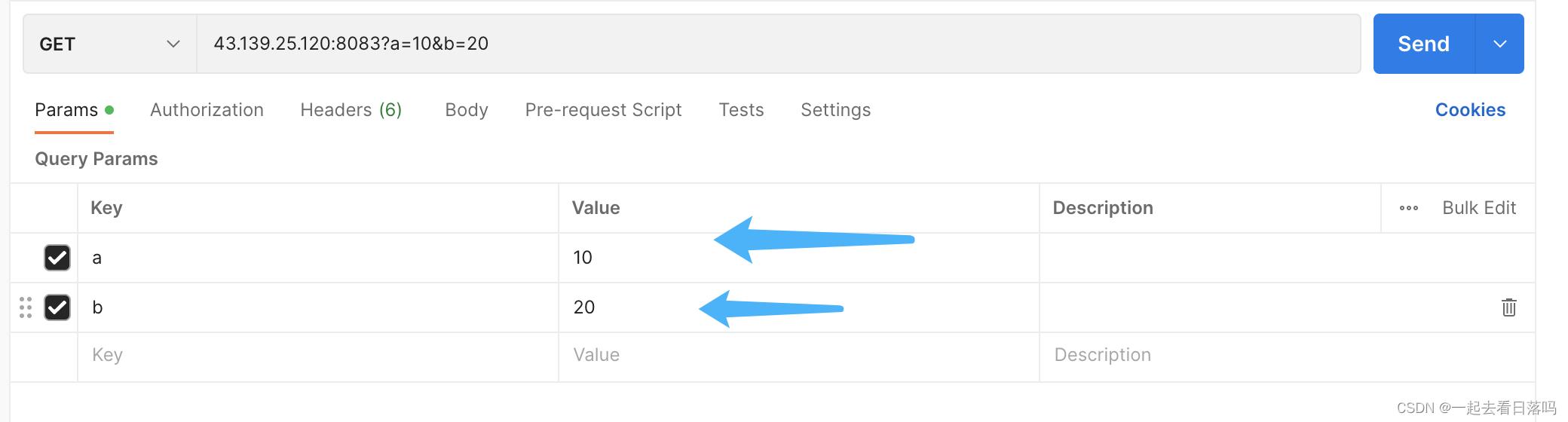
此时在我们的服务器收到的HTTP请求当中,可以看到请求行中的url就携带上了我们刚才在Postman当中设置的参数。
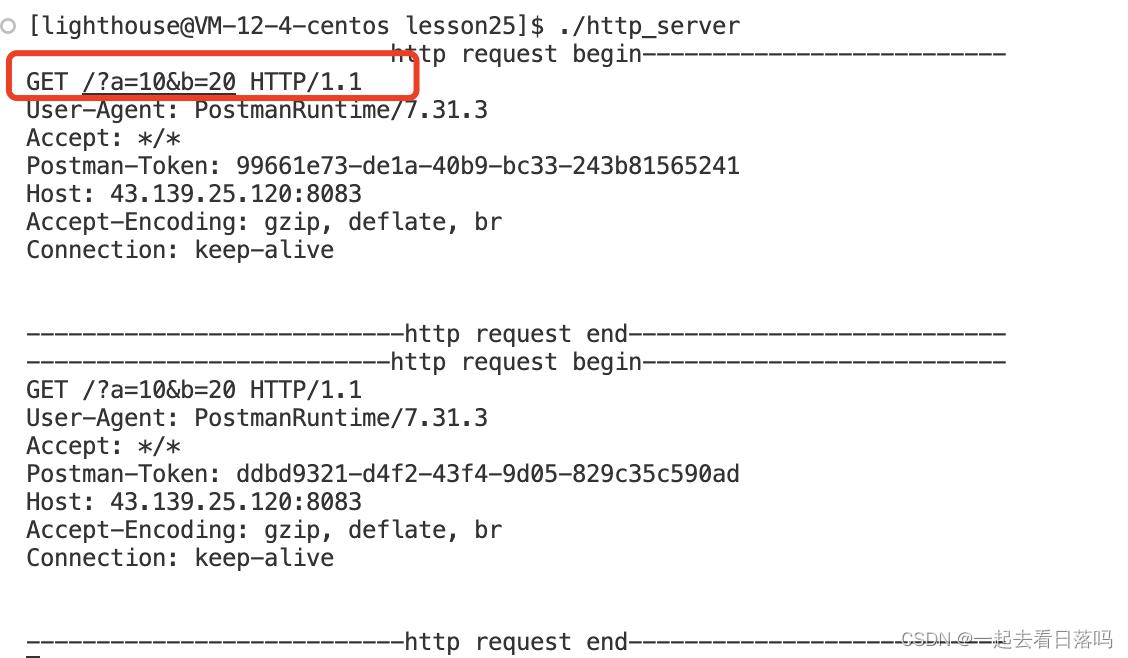
而如果我们使用的是POST方法,此时就应该通过正文进行传参,可以在Body下进行参数设置,在设置时可以选中Postman当中的raw方式传参,表示原始传参,也就是你输入的参数是什么样的实际传递的参数就是什么样的。
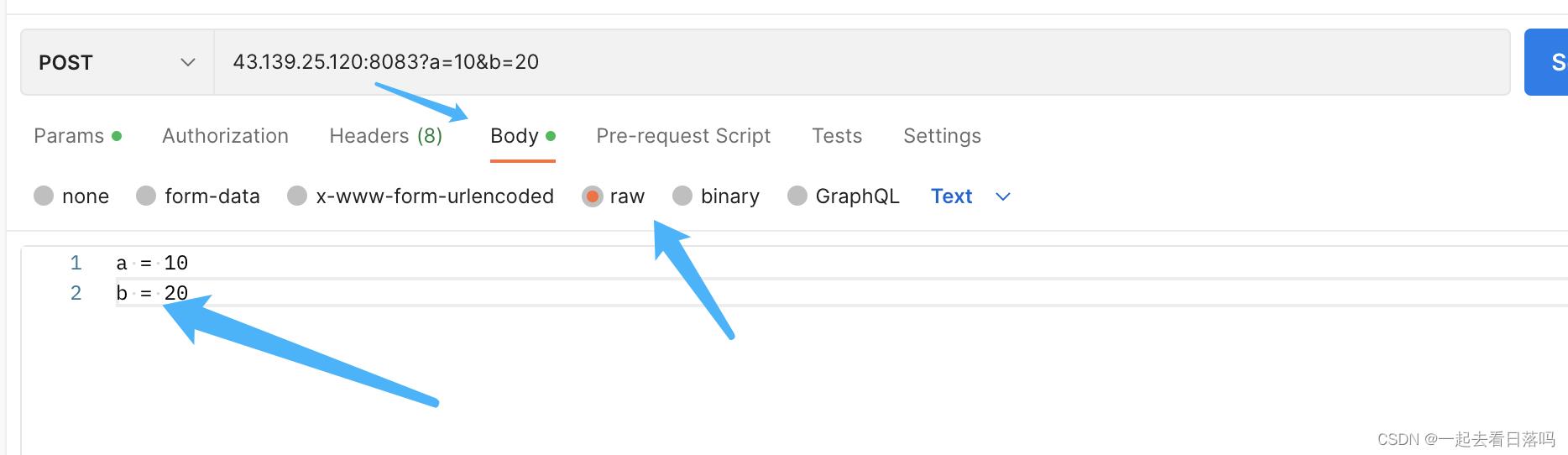
此时服务器收到的HTTP请求的请求正文就不再是空字符串了,而是我们通过正文传递的参数。
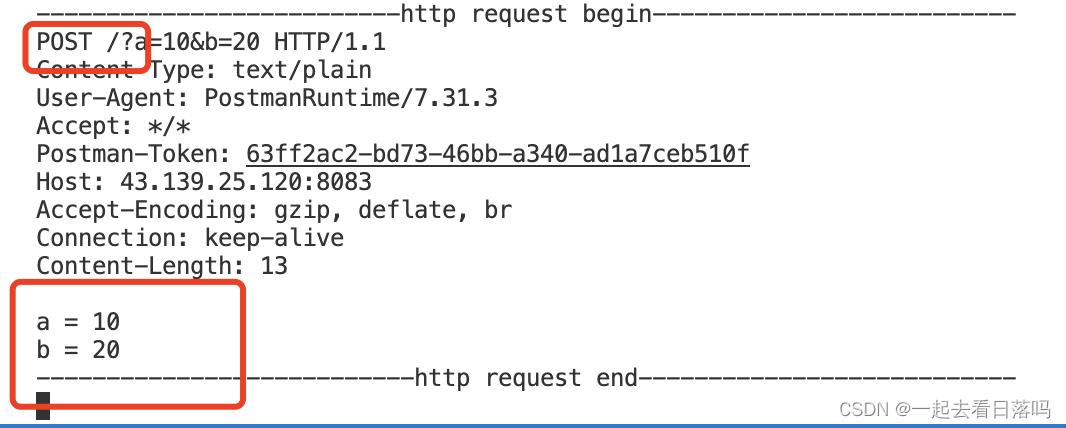
说明一下:
- 因为此时响应正文不为空字符串,因此响应报头当中出现了Content-Length属性,表示响应正文的长度。
TCP套接字演示GET和POST的区别
要演示GET方法和POST方法传参的区别,就需要让浏览器提交参数,此时我们可以在index.html当中再加入两个表单,用作用户名和密码的输入,然后再新增一个提交按钮,此时就可以让浏览器提交参数了。
当前我们是用GET方法提交参数的,当我们填充完用户名和密码进行提交时,我们的用户名和密码就会自动被同步到url当中。
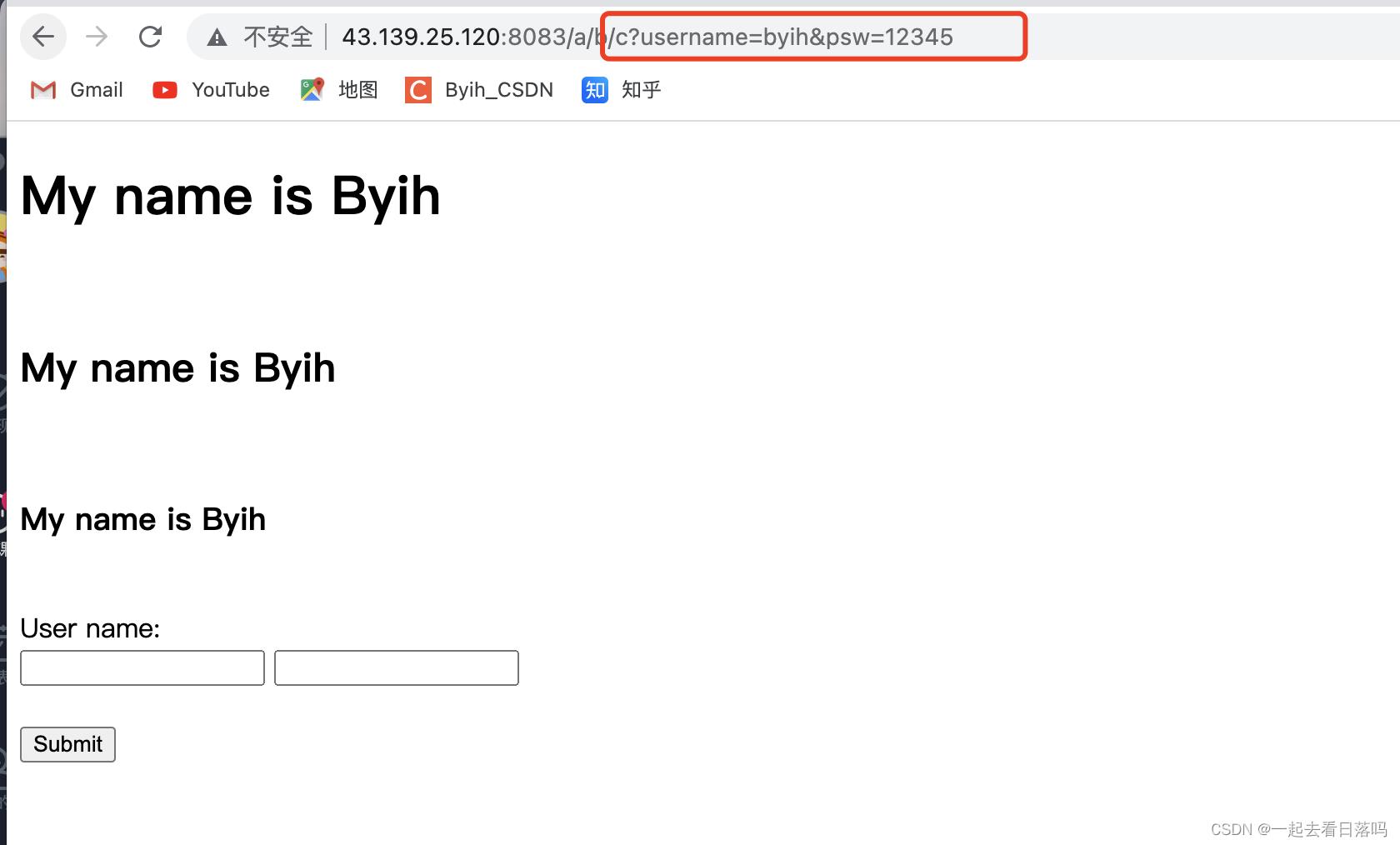 同时在服务器这边也通过url收到了刚才我们在浏览器提交的参数。
同时在服务器这边也通过url收到了刚才我们在浏览器提交的参数。

如果我们将提交表单的方法改为POST方法,此时当我们填充完用户名和密码进行提交时,对应提交的参数就不会在url当中体现出来,而会通过正文将这两个参数传递给了服务器。
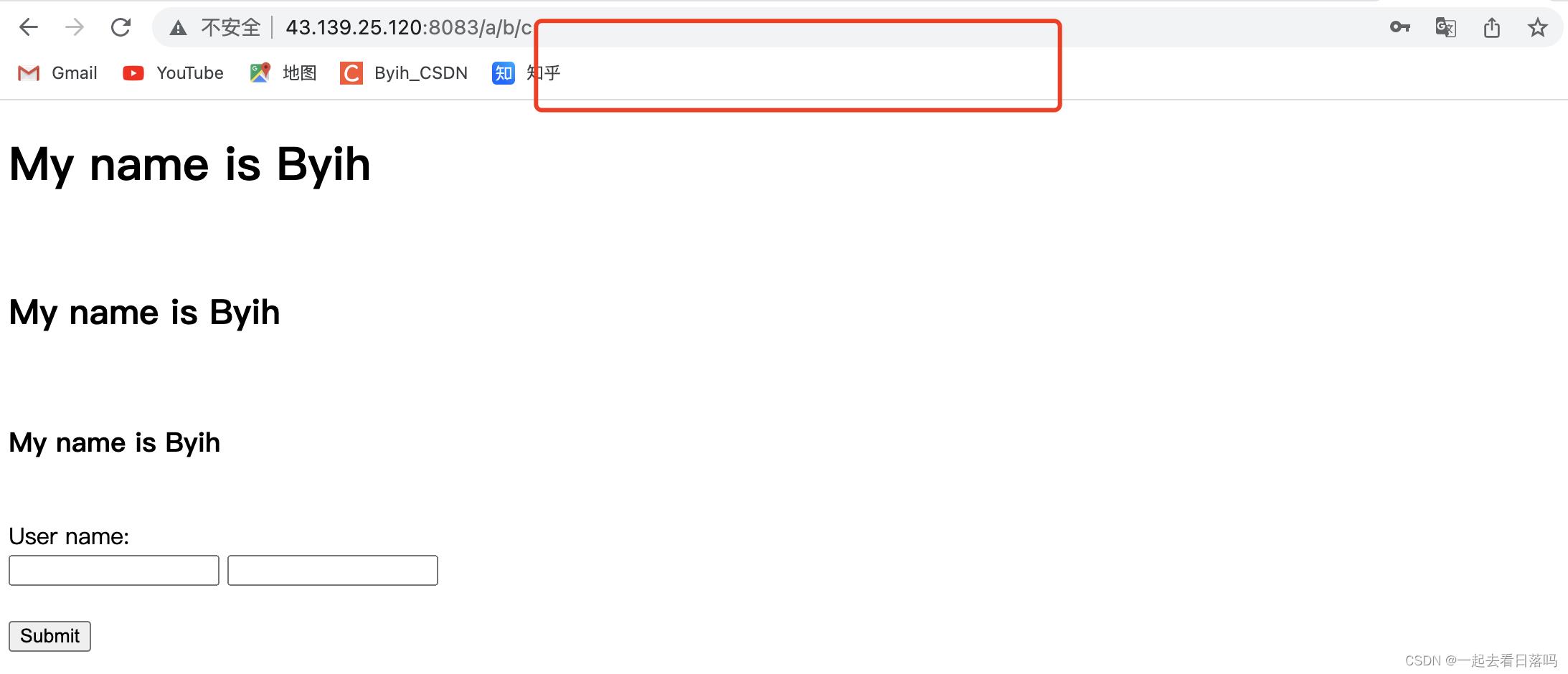 此时用户名和密码就通过正文的形式传递给服务器了。
此时用户名和密码就通过正文的形式传递给服务器了。
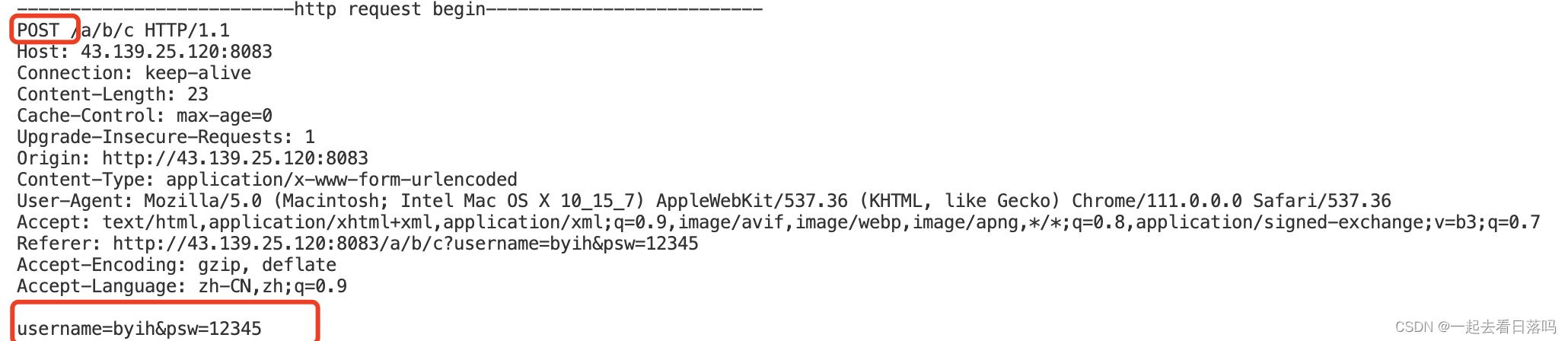
说明一下:
- 当我们使用GET方法时,我们提交的参数会回显到url当中,因此GET方法一般是处理数据不敏感的。
- 如果你要传递的数据比较私密的话你一定要用POST方法,倒不是因为POST方法更安全,实际上GET和POST方法传参时都是明文传送,所以都不安全,但是POST方法更私密,因为POST是通过正文传参的,不会将参数立马回显到浏览器的url框当中的,所以相对更私密。
🌟 1.6 HTTP的状态码
最常见的状态码,比如200(OK),404(Not Found),403(Forbidden请求权限不够),302(Redirect),504(Bad Gateway)。
Redirection(重定向状态码)
重定向就是通过各种方法将各种网络请求重新定个方向转到其它位置,此时这个服务器相当于提供了一个引路的服务。
重定向又可分为临时重定向和永久重定向,其中状态码301表示的就是永久重定向,而状态码302和307表示的是临时重定向。
临时重定向和永久重定向本质是影响客户端的标签,决定客户端是否需要更新目标地址。如果某个网站是永久重定向,那么第一次访问该网站时由浏览器帮你进行重定向,但后续再访问该网站时就不需要浏览器再进行重定向了,此时你访问的直接就是重定向后的网站。而如果某个网站是临时重定向,那么每次访问该网站时如果需要进行重定向,都需要浏览器来帮我们完成重定向跳转到目标网站。
临时重定向演示
进行临时重定向时需要用到Location字段,Location字段是HTTP报头当中的一个属性信息,该字段表明了你所要重定向到的目标网站。
我们这里要演示临时重定向,可以将HTTP响应当中的状态码改为307,然后跟上对应的状态码描述,此外,还需要在HTTP响应报头当中添加Location字段,这个Location后面跟的就是你需要重定向到的网页,比如我们这里将其设置为CSDN的首页。
#include <iostream>
#include <fstream>
#include <string>
#include <cstring>
#include <unistd.h>
#include <sys/wait.h>
#include <sys/socket.h>
#include <sys/types.h>
#include <netinet/in.h>
#include <arpa/inet.h>
using namespace std;
int main()
//创建套接字
int listen_sock = socket(AF_INET, SOCK_STREAM, 0);
if (listen_sock < 0)
cerr << "socket error!" << endl;
return 1;
//绑定
struct sockaddr_in local;
memset(&local, 0, sizeof(local));
local.sin_family = AF_INET;
local.sin_port = htons(8081);
local.sin_addr.s_addr = htonl(INADDR_ANY);
if (bind(listen_sock, (struct sockaddr*)&local, sizeof(local)) < 0)
cerr << "bind error!" << endl;
return 2;
//监听
if (
目录
在学习HTTP协议时,我们需要掌握的内容有九个点。
1.HTTP概述
- HTTP协议,HyperText Transfer Protocol,超文本传输协议。
- HTTP协议是无连接,无状态,工作在应用层的协议。
在这里解释一下HTTP协议的两个特性,无连接,无状态。
- 无连接指的是HTTP协议本身在发送HTTP数据的时候并不需要与服务端建立连接,这是从HTTP协议本身所说的。但是HTTP协议作为应用层协议,它在传输层使用的是TCP协议,TCP在传输协议的过程中是要建立连接的。
- 无状态是指HTTP协议本身是对请求和响应之间的通信状态不进行保存。现在双方的状态是服务端在实现的机制,这个机制我们称之为会话机制。也就是说在HTTP这个级别,协议对于发送过的请求或响应都不做持久化处理。
2.HTTP协议的URL解释

- a. 协议方案名:总共分为两个http与https。两个都是超文本传输协议,只不过https在http上增加了ssl加密过程,ssl是一个非对称加密,会对http双方发送的数据进行加密。
- b.登录信息:早期时显示的我们的身份与认证,现在并没有,因为是不安全的行为。
- c.域名:他最终会被DNS协议解析成为IP地址。
- d.服务端的端口号:指定服务器连接的网络端口号。若用户省略则自动使用默认端口号。
- e.带层次的文件路径:这是向服务端后台请求的资源,而他之前的'/'指的是服务器当中的逻辑根目录,而不是Linux服务器的根目录。服务端可以指定一个路径为http服务端的根目录的其实路径。
- f.查询字符串:他是提交给服务端的数据。在这里要注意,1.他的格式为key=value,如果有多个,则格式为key=value&key1=value1。2.再提交上去的的内容有通俗意义的字符串要进行转码,将字符采用16进制进行表示。使用%这个字符+urlencode之后的字符来表示,其中%是告诉我们服务端后面的内容是经过urlencode的字符,需要服务端进行解码。
- g.片段标识符:现在已经不太常用,使用它通常可以标记出已经湖区资源的子资源(文档内的某个位置)。
拓展:
非对称加密分为了公钥与私钥,服务端持有私钥,http客户端持有公钥。在HTTP客户端使用公钥进行加密,加密完后传输到服务端,服务端用私钥进行解密就可以得到原生的内容,而在网路传输过程当中,如果有人进行网络数据的抓取由于他没有私钥,他拿到的数据是解析不了的,也就是说即使拿到了数据包也是一堆乱码,这就完成了对传输数据的保密过程。
3.HTTP协议的数据流
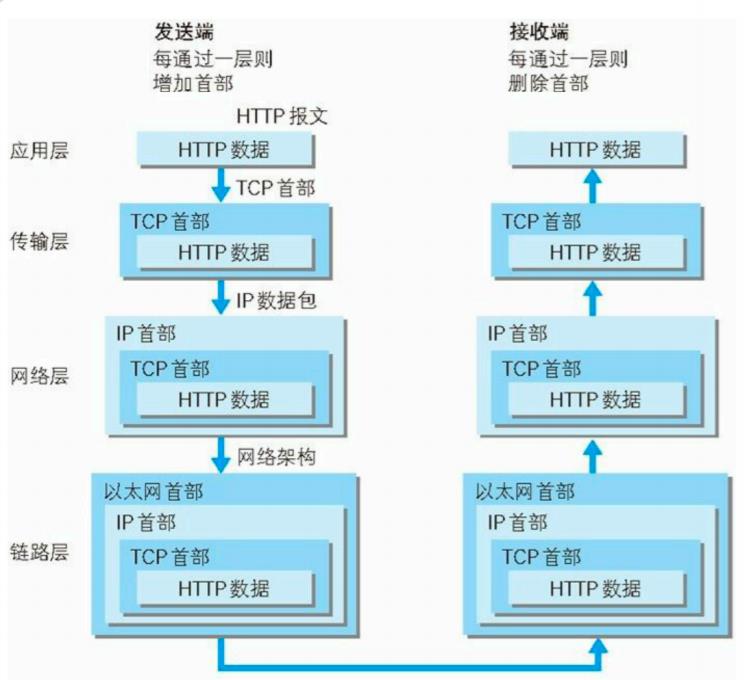
左边我们可以理解为是浏览器,右边可以理解为HTTP的服务端。浏览器在这里会先产生一个HTTP数据,HTTP数据就按照HTTP协议格式将它进行封装并且交给传输层;传输层得到后在这里打上TCP首部然后递交给网络层;网络成在这里打上IP协议的包头后递交给数据链路层;数据链路层打上以太网头部和以太网尾部传递给物理层;物理层将这个二进制处理成过电信号在网络当中进行传输,传输到对端,对端拿到数据之后再将其转化成二进制和格式,然后层层去掉原生数据的封装,最后拿到的数据还是按照HTTP协议组织得到的数据。在这里数据流还是牵扯到了两点,封装与分用。
4.HTTP协议的格式
HTTP协议规定,请求从客户端发出,最后服务端响应该请求并返回。话句话说肯定是先从客户端开始建立通信的,服务器端在没有接受到请求之前是不会发送相应。
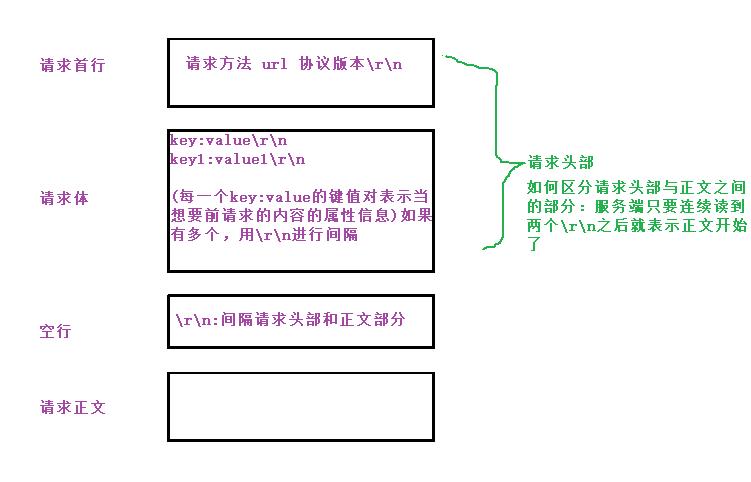
4.1HTTP请求格式
HTTP的请求格式分为了四个部分:请求首行(方法URI协议版本),请求体(key:value的属性行),空行,请求正文 。
我们先给出框架,如下图:
4.2HTTP响应格式
HTTP响应格式有四部分,分别是响应首行(协议首行,状态码,状态码解释),响应体,空行和响应内容。

5.HTTP协议的版本
- HTTP/0.9:HTTP 于 1990 年问世。那时的 HTTP 并没有作为正式的标准被建⽴。 现在的 HTTP其实含有 HTTP1.0 之前版本的意思,因此被称为 HTTP/0.9。
- HTTP/1.0:HTTP 正式作为标准被公布是在1996 年的 5 ⽉,版本被命名为 HTTP/1.0,并记载于 RFC1945。虽说是初期标准,但该协议标准⾄今仍被⼴泛使⽤在服务器端。
- HTTP/1.1:这是目前主流的HTTP协议版本。
- HTTP/2.0:0 新 ⼀代HTTP/2.0 正在制订中,但要达到较⾼的使⽤覆盖率,仍需假以时⽇。
6.HTTP协议的请求方法
请求方法当中比较常见的有Get与Post。
6.1GET方法与POST方法
- Get:向服务端索要某些资源,也可以给服务端提供少量的数据在URL当中(少量的原因是URL的长度是有限制的,所以不能无限制给服务端提交数据在"查询字符串当中",且URL在不同浏览器当中是不同的)。
- Post:给服务器传输资源的方法,提交的数据实在请求正文当中传输给服务端。
- POST与GET对比:POST方法比GET方法更加私密。不能说POST方法比GET方法更加安全,因为无论GET方法是在URL当中提交数据,还是POST方法在请求正文当中提交数据,都是明文传输。
6.2其他的请求方法
- PUT:它用来传输文件。HTTP没有校验,一般情况下,后台的服务端是不支持PUT方法的。
- HEAD:获取响应头部,只获取响应首行和请求体,为了测试请求资源是否有效。
- DELETE:删除文件。HTTP没有校验,一般情况下,后台的服务端是不支持DELETE方法的。
- OPTIONS:询问服务端支持的方法。
常见的请求方法的说明,如下表:
方法 说明 支持HTTP协议版本 GET
获取资源 1.0,1.1 POST 传输实体主体 1.0,1.1 PUT 传输文件 1.0,1.1 HEAD 获得报文首部 1.0,1.1 OPTIONS 询问支持的方法 1.1 TRACE 追踪路径 1.1 DELETE 删除文件 1.0,1.1 CONNECT 要求用隧道协议连接代理 1.1 LINK 建立和资源之间的联系 1.0 UNLINE 断开连接关系 1.0
7.HTTP协议的响应状态码
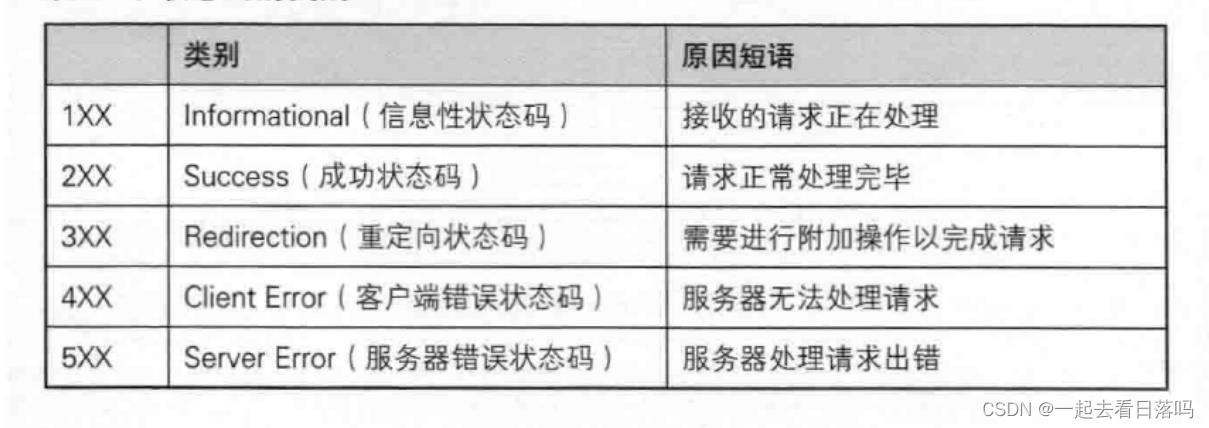
7.1状态码类别
类别 原因短语 1XX Informational(信息性状态码) 接受的请求正在处理 2XX Success(成功状态码) 请求正常处理完毕 3XX Redirection(重定向状态码) 需要进行附加操作以完成请求 4XX Client Error(客户端错误代码) 服务器无法处理请求,访问资源不正确或者访问页面不存在 5XX Sever Error(服务器错误状态码) 服务器处理请求出错
7.2具体的响应状态码
- 200:OK,表示从客户端发来的请求在服务端被正常处理了。
- 302:Found,临时重定向行为,在服务器当中,资源的URI已经临时重定向d奥其他位置。
- 404:Not Found,服务器桑没有请求资源,访问的页面不存在。
- 502:Bad Getway,坏的网关
8.请求/相应的常见字段
- Content-Type:正文的类型(text/html:返回原生的html页面; application/json:json数据类型)
- Content-Length:正文的长度
- Host:保存服务端的IP和端口信息
- User-Agent:保存的是操作系统和浏览器版本的信息
- Location:保存重定向的网页地址
- Connection:keep-alive,保持长连接(HTTP底层使用到的TCP保持长连接)
- Cookie:他是服务端返回给浏览器的,由浏览器进行保存Cookie;在访问服务器其他界面的时候,由浏览器自动在请求体当中加上Cookie。(它的作用:服务端通过Cookie当中的value值,可以得到服务端生成的sessionid,通过会话id,可以在服务端查询出来是哪一个用户的session;浏览器通过请求当中的Cookie信息提交到服务端,服务端就可以通过Cookie保存的会话信息,进行会话校验)。
9.代码模拟实现HTTP协议与浏览器的交互
#include <stdio.h>
#include <unistd.h>
#include <string.h>
#include <sys/socket.h>
#include <netinet/in.h>
#include <arpa/inet.h>
#include <sstream>
using namespace std;
int main(){
int listen_sock = socket(AF_INET, SOCK_STREAM, IPPROTO_TCP);
if(listen_sock < 0){
perror("socket");
return 0;
}
struct sockaddr_in addr;
addr.sin_family = AF_INET;
addr.sin_port = htons(28989);
//0.0.0.0 : 本地所有的网卡地址
addr.sin_addr.s_addr = inet_addr("0.0.0.0");
int ret = bind(listen_sock, (struct sockaddr*)&addr, sizeof(addr));
if(ret < 0){
perror("bind");
return 0;
}
ret = listen(listen_sock, 1);
if(ret < 0){
perror("listen");
return 0;
}
struct sockaddr_in cli_addr;
socklen_t cli_addrlen = sizeof(cli_addr);
int newsockfd = accept(listen_sock, (struct sockaddr*)&cli_addr, &cli_addrlen);
if(newsockfd < 0){
perror("accept");
return 0;
}
printf("accept new connect from client %s:%d\\n", inet_ntoa(cli_addr.sin_addr), ntohs(cli_addr.sin_port));
while(1){
//接收
char buf[1024] = {0};
ssize_t recv_size = recv(newsockfd, buf, sizeof(buf) - 1, 0);
if(recv_size < 0){
perror("recv");
continue;
}
else if(recv_size == 0){
printf("peer close connect\\n");
close(newsockfd);
return 0;
}
printf("%s\\n", buf);
memset(buf, '\\0', sizeof(buf));
string body = "<html><h1>hello</h1></html>";
stringstream ss;
ss << "HTTP/1.1 302 Found\\r\\n";
//ss << "Content-Type: text/html\\r\\n";//相应首行
//ss << "Content-Length: " << body.size() << "\\r\\n";//响应体
ss << "Location: https://www.baidu.com/\\r\\n";
ss << "\\r\\n";
send(newsockfd, ss.str().c_str(), ss.str().size(), 0);
send(newsockfd, body.c_str(), body.size(), 0);
}
close(listen_sock);
return 0;
}
10.自定制协议
10.1TCP粘包的现象
我们在了解自定制协议之前先举个例子:
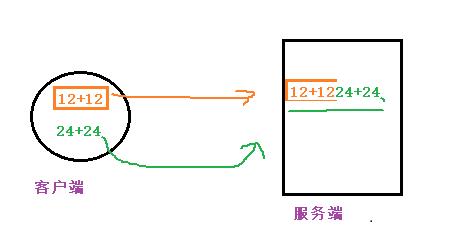
现在客户端使用send接口给服务端发送了一串数据给服务端12+12,此时客户端有发送一条数据24+24,两条数据依次被丢入网络当中,因为TCP是面向字节流的,此时两条数据到达服务端的传输层的TCP协议,而此时两条数据之间没有任何的分隔符。当应用层调用recv接口将数据拿到,但是服务端没有办法分析是12+12,24+24还是12+1224+24,此时服务端没有办法进行拆分,我们将这种现象称之为TCP粘包问题。
即就是TCP服务端没有办法针对TCP数据进行拆分,拆分成为不同的请求。因为TCP是面向字节流的,数据之间并没有明显的间隔,就导致服务端无法拆分数据。
10.2解决TCP粘包的现象
那么就在应用层自定制我们的协议,用来解决TCP粘包问题。
解决方案:
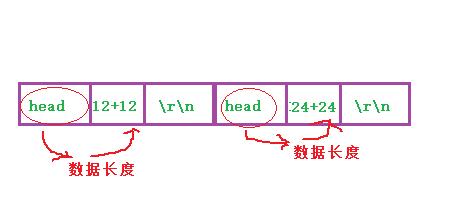
- 定义应用层自己的协议数据结构,来描述发送到数据
- 每一条数据都会友谊和分隔符(\\r\\n),来间隔前后两条数据。
10.3序列化和反序列化
序列化:将对象转换成二进制数据
反序列化:将二进制数据转化成对象
举个栗子:假设在这里有一个结构体
struct a{
string name;
string passwd;
};
我们知道这个结构体当中的两个string对象有可能在我们进程虚拟地址空间中并非连续存储,而如果不转化则会发送一些无效的数据,因此将当前的结构体中的对象转化成连续的二进制数据,这样就不会传输无效的数据,这种方式称之为序列化。而反序列化就与其相反。
josn也是一个好的使用方式。json是一种key/value的数据结构,可以支持嵌套定义,也可以支持多种基础类型(int,string,char)。同时也支持将josn对象序列化成二进制序列,也可以将二进制反序列化成josn对象。