牛客网算法八股刷题系列卷积函数随机梯度下降ReLU
Posted 静静的喝酒
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了牛客网算法八股刷题系列卷积函数随机梯度下降ReLU相关的知识,希望对你有一定的参考价值。
牛客网算法八股刷题系列——卷积函数、随机梯度下降、ReLU
题目描述
本节并不过多针对题目中的非线性,而更多关注随机梯度下降、卷积运算自身以及卷积运算与全连接运算在动机上的差异性。
下列哪一项在神经网络中引入了非线性 ? ( ) ?(\\quad) ?()
A \\mathcal A \\quad A随机梯度下降
B \\mathcal B\\quad B修正线性单元 ( ReLU ) (\\textReLU) (ReLU)
C \\mathcal C \\quad C卷积函数
D \\mathcal D \\quad D以上都不正确
正确答案: B \\mathcal B B
题目解析
A \\mathcal A \\quad A随机梯度下降 ( Stochastic Gradient Descent,SGD ) (\\textStochastic Gradient Descent,SGD) (Stochastic Gradient Descent,SGD)是梯度下降法( Gradient Descent,GD \\textGradient Descent,GD Gradient Descent,GD)系列的一种算法表达。
在梯度下降法的基础上,随机梯度下降的核心操作在于:每次算法迭代中的采样操作。
关于机器学习算法中的代价函数
J
\\mathcal J
J可以分解成每个样本的损失函数总和:
已知数据集合
D
=
x
(
i
)
,
y
(
i
)
i
=
1
N
\\mathcal D = \\x^(i),y^(i)\\_i=1^N
D=x(i),y(i)i=1N并以此作为‘真实分布/真实模型’
P
d
a
t
a
\\mathcal P_data
Pdata的参考。在极大似然估计与最大后验概率估计中介绍过,真实模型是客观的,是无法准确得到的分布结果。因而
D
\\mathcal D
D可理解为从真实分布
P
d
a
t
a
\\mathcal P_data
Pdata中采集出的样本组成的集合。
J
(
θ
)
=
E
x
(
i
)
,
y
(
i
)
∈
P
d
a
t
a
L
(
x
(
i
)
,
y
(
i
)
;
θ
)
=
1
N
∑
i
=
1
N
L
(
x
(
i
)
,
y
(
i
)
;
θ
)
\\beginaligned \\mathcal J(\\theta) & = \\mathbb E_x^(i),y^(i) \\in \\mathcal P_data \\mathcal L(x^(i),y^(i);\\theta) \\\\ & = \\frac1N \\sum_i=1^N \\mathcal L(x^(i),y^(i);\\theta) \\endaligned
J(θ)=Ex(i),y(i)∈PdataL(x(i),y(i);θ)=N1i=1∑NL(x(i),y(i);θ)
其中,
L
\\mathcal L
L为损失函数,根据不同的处理任务,可使用不同的损失函数,这里不过多描述。基于梯度下降法,我们需要计算代价函数关于参数
θ
\\theta
θ的梯度
∇
θ
J
(
θ
)
\\nabla_\\theta \\mathcal J(\\theta)
∇θJ(θ):
∇
θ
J
(
θ
)
=
1
N
∑
i
=
1
N
∇
θ
L
(
x
(
i
)
,
y
(
i
)
;
θ
)
\\nabla_\\theta\\mathcal J(\\theta) = \\frac1N \\sum_i=1^N \\nabla_\\theta \\mathcal L(x^(i),y^(i);\\theta)
∇θJ(θ)=N1i=1∑N∇θL(x(i),y(i);θ)
关于随机梯度下降,它的底层逻辑是:梯度自身就是期望结果,而期望可以用小规模样本近似估计。针对上式,可以使用牛顿-莱布尼兹公式,将梯度符号与积分号调换位置:
∇
θ
J
(
θ
)
=
1
N
∇
θ
[
∑
i
=
1
N
L
(
x
(
i
)
,
y
(
i
)
;
θ
)
]
\\nabla_\\theta\\mathcal J(\\theta) = \\frac1N \\nabla_\\theta \\left[\\sum_i=1^N \\mathcal L(x^(i),y^(i);\\theta)\\right]
∇θJ(θ)=N1∇θ[i=1∑NL(x(i),y(i);θ)]
因而上式描述的就是:
N
N
N个样本对应损失函数结果期望的梯度。如果样本量
N
N
N足够大,每一次求解梯度的代价(计算量)也是足够高的。
但期望自身是可以使用小规模样本近似估计,针对庞大的数据集合
D
\\mathcal D
D,在迭代过程中均匀抽取小批量(
MiniBatch
\\textMiniBatch
MiniBatch)样本
D
′
=
(
x
(
i
)
,
y
(
i
)
)
i
=
1
m
∈
D
\\mathcal D' = \\(x^(i),y^(i))\\_i=1^m \\in \\mathcal D
D′=(x(i),y(i))i=1m∈D,这个
m
m
m是一个很小的数值,从一到几百。使用这种方式进行训练,其最大的优势是大幅度缩短迭代过程中的计算时长:
E
x
(
i
)
,
y
(
i
)
∈
D
′
[
L
(
x
(
i
)
,
y
(
i
)
;
θ
)
]
≈
J
(
θ
)
g
=
1
m
∇
θ
[
∑
i
=
1
m
L
(
x
(
i
)
,
y
(
i
)
;
θ
)
]
≈
∇
θ
J
(
θ
)
\\begincases \\mathbb E_x^(i),y^(i) \\in \\mathcal D' \\left[\\mathcal L(x^(i),y^(i);\\theta)\\right] \\approx \\mathcal J(\\theta)\\\\ g = \\frac1m \\nabla_\\theta \\left[\\sum_i=1^m \\mathcal L(x^(i),y^(i);\\theta)\\right] \\approx \\nabla_\\theta \\mathcal J(\\theta) \\endcases
Ex(i),y(i)∈D′[L(x(i),y(i);θ)]≈J(θ)g=m1∇θ[∑i=1mL(x(i),y(i);θ)]≈∇θJ(θ)
具体执行过程表示如下:
- 在采样之前,将数据集
牛客网算法八股刷题系列概率密度函数累积分布函数概率质量函数
牛客网算法八股刷题系列——概率密度函数、累积分布函数、概率质量函数
题目描述
以下关于 PMF \\textPMF PMF(概率质量函数), PDF \\textPDF PDF(概率密度函数), CDF \\textCDF CDF(累积分布函数)描述错误的是 ( ) (\\quad) ()
A PDF \\mathcal A \\quad \\textPDF APDF描述的是连续型随机变量在特定取值空间的概率
B CDF \\mathcal B \\quad \\textCDF BCDF是 PDF \\textPDF PDF在特定区间上的积分
C PMF \\mathcal C \\quad \\textPMF CPMF描述的是离散型随机变量在特定取值点的概率
D \\mathcal D \\quad D有一个分布的 CDF \\textCDF CDF函数 H ( a ) \\mathcal H(a) H(a),则 H ( a ) = P ( x ≤ a ) \\mathcal H(a) = \\mathcal P(x \\leq a) H(a)=P(x≤a)
正确答案: A \\mathcal A A
题目解析
该问题中最容易被忽视的点:概率密度函数 ( Probability Density Function,PDF ) (\\textProbability Density Function,PDF) (Probability Density Function,PDF),它的函数输出值描述的是对应输入事件发生的可能性。
- 但这个可能性不是概率;
- 而概率描述的是函数在某范围内的积分;
- 连续型随机变量取值在任意一点概率均为 0 0 0。
举一个实际例子:一维高斯分布的概率密度函数:
f ( x ) = 1 σ ⋅ 2 π exp − ( x − μ ) 2 σ 2 f(x) = \\frac1\\sigma \\cdot \\sqrt2\\pi \\exp \\left\\-\\frac(x - \\mu)^2\\sigma^2\\right\\ f(x)=σ⋅2π1exp−σ2(x−μ)2
它的函数图像表示如下 ( μ = 0 , σ = 1 ) (\\mu=0,\\sigma=1) (μ=0,σ=1):
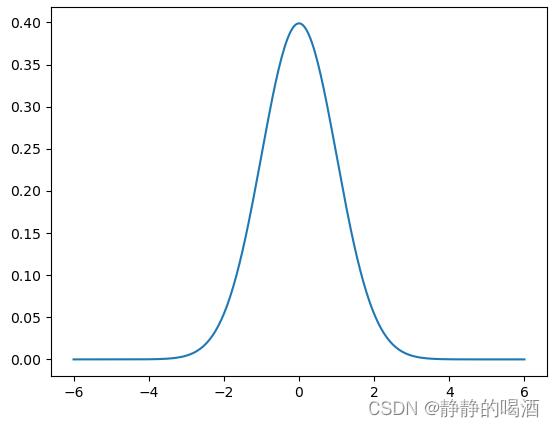
由于均值 μ = 0 \\mu=0 μ=0的原因,在图像中观察, x = 0 x=0 x=0对应的可能性是最高的:
f ( 0 ) = 1 2 π exp 0 ≈ 0.3989 f(0) = \\frac1\\sqrt2\\pi \\exp^0 \\approx 0.3989 f(0)=2π1exp0≈0.3989
但是该点对应的概率 P ( x = 0 ) = 0 \\mathcal P(x=0) =0 P(x=0)=0,但并不是说 x = 0 x = 0 x=0是不可能发生事件。
如何用概率密度函数来描述概率呢?积分。作为概率密度函数的性质,有:
∫ − ∞ + ∞ f ( x ) d x = 1 \\int_-\\infty^+\\infty f(x) dx = 1 ∫−∞+∞f(x)dx=1
如果将积分在图像中进行描述,其表示函数图像与坐标轴在某一范围内围成图像的面积。依然以 x = 0 x = 0 x=0为例,它在图像中的概率结果表示为:
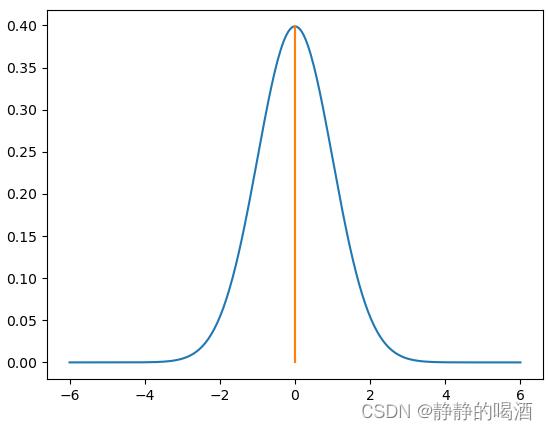
很明显,这仅仅是一个线段。而线段自身没有面积。这也可以说明:连续型随机变量取值在任意一点概率均为 0 0 0。如果想要描述 P ( − 2 < x < 0 ) \\mathcal P(-2<x<0) P(−2<x<0)的概率结果,对应在概率密度函数图像中表示为如下形式:
阴影面积部分。

因而它的概率是积分结果,而不是函数值。从另一个角度观察,如果某一个一维高斯分布方差较小,从而出现下图现象:
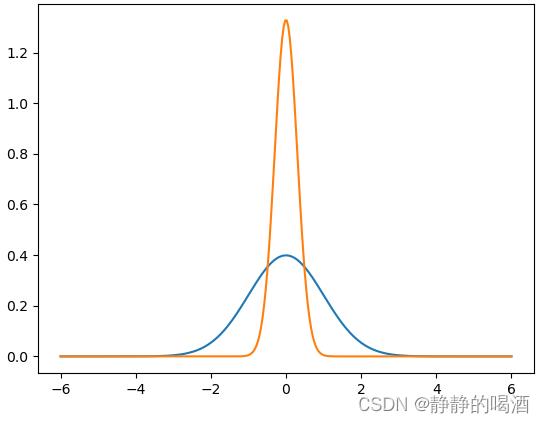
很明显,如果 PDF \\textPDF PDF函数结果表示概率值,那么橙色线中 0 0 0对应的函数结果显然超过概率结果上界 1 1 1了,自然也是不合理的。 A \\mathcal A \\quad A 选项错误。B D \\mathcal B \\quad \\mathcal D\\quad BD 选项中提到了累积分布函数 ( Cumulative Distribution Function,CDF ) (\\textCumulative Distribution Function,CDF) (Cumulative Distribution Function,CDF),首先它是概率密度函数的积分,简单来说,它将积分结果映射到了函数值上。
从计算角度来看,概率密度函数是累积分布函数的导数。依然以一维高斯分布为例,它的累积分布函数表示如下:
这里并没有将‘累积分布函数’的公式求解出来,仅通过采样的方式近似求解。import math import matplotlib.pyplot as plt import numpy as np def pdf(mu,sigma,x): return (1 / (math.sqrt(2 * math.pi) * sigma)) * math.exp(-1 * (((x - mu) ** 2) / (2 * (sigma ** 2)))) def func(x): return math.exp(-1 *(x ** 2)) def erf(x): if x > 0: x_l = np.arange(0,x,0.01) y_l = np.array([func(i) for i in x_l]) else: x_l = np.arange(x,0,0.01) y_l = np.array([-1 * func(i) for i in x_l]) res = (2 / (math.sqrt(math.pi))) * np.trapz(y_l,x_l) return res def cdf(mu,sigma,x): input_x = (x - mu) / (sigma * (2 ** 0.5)) return 0.5 * (1 + erf(input_x)) if __name__ == '__main__': mu_0,sigma_0 = 0,1 mu_1,sigma_1 = 0.8,1.5 x = list(np.linspace(-6,6,300)) y = [cdf(mu_0,sigma_0,i) for i in x] y_pdf = [pdf(mu_0,sigma_0,i) for i in x] plt.plot(x,y,c="tab:orange") plt.plot(x,y_pdf,c="tab:blue") plt.show()对应函数图像表示如下。其中蓝色线表示概率密度函数;对应的橙色线表示对应的累积分布函数。
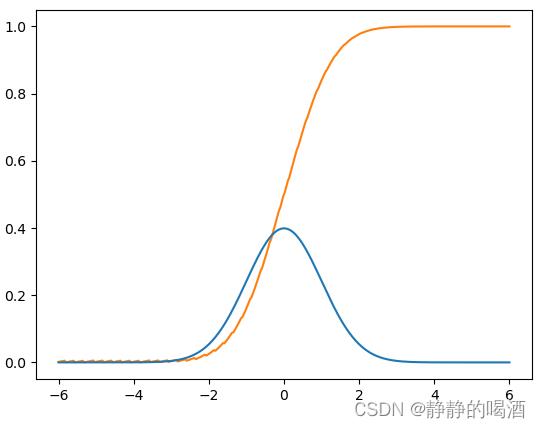
B \\mathcal B \\quad B 选项是累积分布函数的定义;关于 D \\mathcal D \\quad D 选项,这里以 a = 1 a = 1 a=1为例,它的概率密度函数的积分结果与累积分布函数结果分别表示如下:
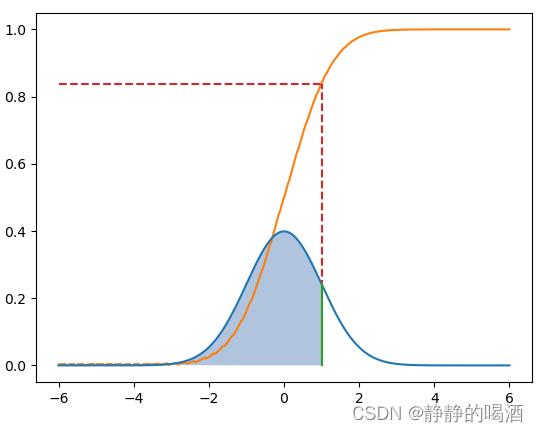
其中红色虚线与 CDF \\textCDF CDF交点对应的函数值等于阴影部分面积,而阴影部分面积就是 P ( x ≤ a ) \\mathcal P(x \\leq a) P(x≤a)的概率值。C \\mathcal C \\quad C 选项,关于概率质量函数 ( Probability Mass Function,PMF ) (\\textProbability Mass Function,PMF) (Probability Mass Function,PMF),它与概率密度函数不同,由于是离散型随机变量,这导致概率质量函数不连续。具体公式表示如下:
f X ( x ) = P ( X = x ) x ∈ S 0 x ∈ R \\ S f_\\mathcal X(x) = \\begincases \\mathcal P(\\mathcal X = x) \\quad x \\in \\mathcal S \\\\ 0 \\quad x \\in \\mathbb R \\backslash \\mathcal S \\endcases fX(x)=P(X=x)x∈S0x∈R\\S
相关描述为: S \\mathcal S S表示随机变量 X \\mathcal X X能够取到数值 x x x的集合;而 R \\ S \\mathbb R \\backslash \\mathcal S R\\S表示实数集合 R \\mathbb R R中除去 S \\mathcal S S之外的剩余集合。- 当 X \\mathcal X X取集合 S \\mathcal S S中的某一具体值 x x x时,对应概率为 P ( X = x ) \\mathcal P(\\mathcal X = x) P(X=x);
- 当 X \\mathcal X X取集合 R \\ S \\mathbb R \\backslash \\mathcal S R\\S中的值时,其对应概率结果必然为 0 0 0。
这意味着概率质量函数的函数值就是该自变量对应的概率值。这也是它与概率密度函数的主要区别。
以上是关于牛客网算法八股刷题系列卷积函数随机梯度下降ReLU的主要内容,如果未能解决你的问题,请参考以下文章