GIT科普系列3:底层存储机制Internal Objects
Posted zssure
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了GIT科普系列3:底层存储机制Internal Objects相关的知识,希望对你有一定的参考价值。
题记:
近期连续写了几篇关于git的博文,大多从日常使用过程中遇到的难点入手(例如冲突、回滚、放弃本地修改),目的是希望能够让大家从博文中找到可以直接用于实战的经验,因此并没有像其他指导手册一样事无巨细、面面俱到。如果大家希望对GIT有一个全面的了解,可以直接阅读官方文档,内部也有官方翻译的各种语言版本,不建议初学者一上来直接阅读国内相关博客或其他网站的总结类文章,原因大概有两个,其一国内的总结大多是相互摘抄,或者从官方文档直接摘录,知其然但不知其所以然;其二很多总结类的博文大多是罗列指令入手,仅有的少许真实示例讲解的也多半记录不详。虽然GIT功能很复杂,但是日常开发工作中用到的比较少,因此贸然学习很多指令反而会起到副作用,影响大家的注意力。因此在这里再次强烈推荐官方文档。
背景:
上一篇博文 GIT:git代码检出与日常维护在整合诸多国外博文和官方文档的基础上,给大家讲解了git版本库的三个基本阶段(working directory、index和commit)和如何检出原始代码。博文中依然沿袭自己的风格,并没有过多的介绍指令的各种参数和格式,仅仅是以常见的默认指令为例,介绍了git checkout和git clone等几个指令。
现在总结来看,git的各种指令主要的功能和实现的结果就是使得文件在git设定的各种状态(untracked、unmodified、modified、staged)之间进行切换。而git之所以能够使得文件存在着各种不同状态,底层原因是git采用了多阶段存储的方式(GIT可以看做是一个基于内容检索——Content-Based FileSystem——的文件系统,按照不同阶段(即不同的存储位置和格式)来标记和识别所管理文件的不同状态。本文基于官方文档的10.2 Git Internals - Git Objects章节,用本地示例的方式给大家介绍GIT的底层存储机制,让大家能形成一个宏观的认识,有一个形象的理解。
GIT的管理流程:
1. GIT仓库的初始化
git的初始化很简单,输入git init指令,会看到在当前空目录下创建一个.git隐藏文件夹,这个就是git实现一切版本管理的关键。
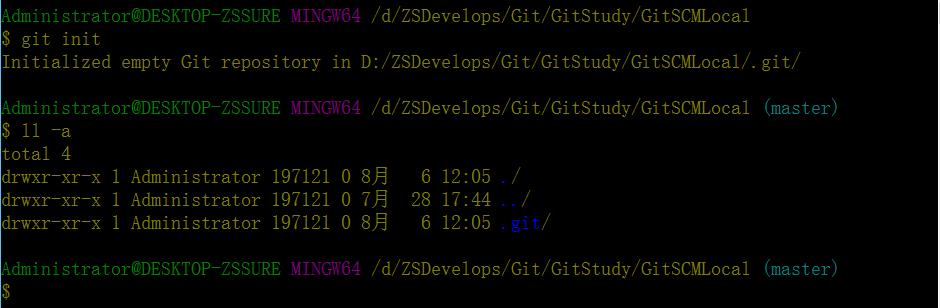
进入到.git目录下,我们看一下内部结构,包含三个文件(config/description/HEAD)和四个文件夹(hooks/info/objects/refs)
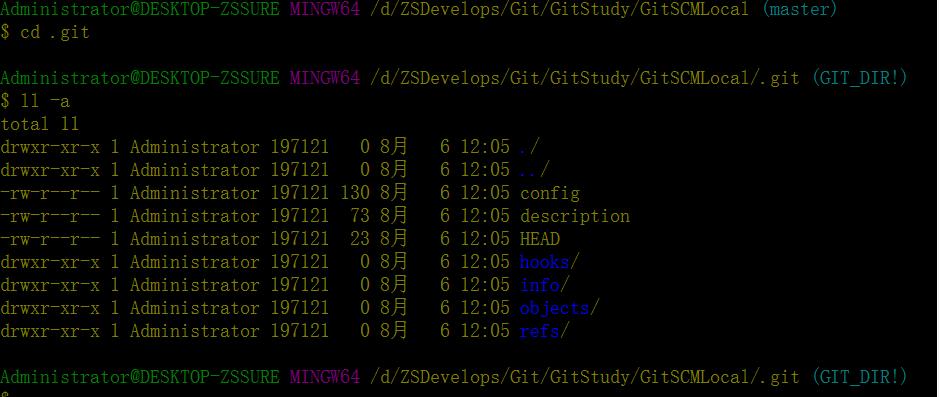
【备注】:在hooks文件夹下有部分官方给出的默认脚本示例,有兴趣的可以打开看一下,从文件名称就可以推断出脚本大致的作用节点和具体操作。
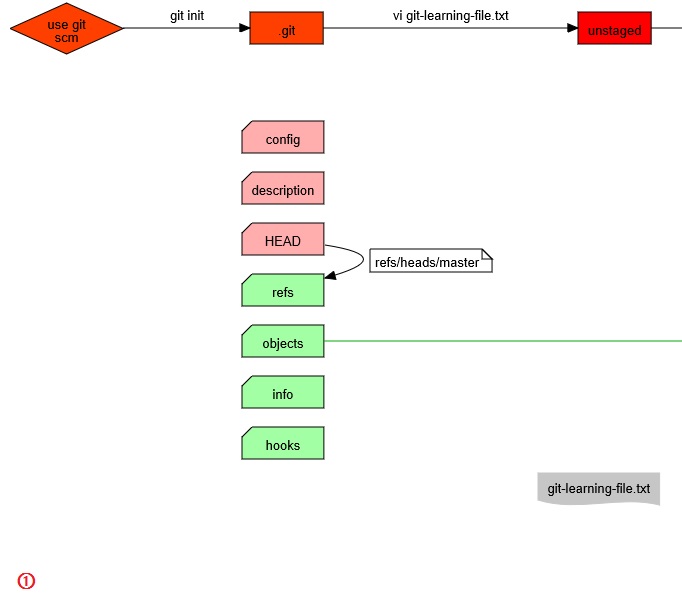
官方对各个文件和文件夹的有详细的介绍:
- config:记录与本项目相关的配置信息
- descripton:是GitWeb项目对于本仓库的基本描述
- HEAD:内部记录了当前分支的最后一次提交(默认指向refs/heads/master文件)
- hooks:记录客户端和服务端的脚本,完成相关的自动化工作(钩子脚本的目的)
- info:记录全局的文件忽略方式,用于标记不被git仓库跟踪的文件,与.gitignore类似
- objects:这是git仓库的关键,归档所有git数据库里的内容
- refs:这个也是git仓库主要内容,记录所有分支的提交对象(commit object)
我们用一张图来简单的概括一下,
2. GIT存储第一阶段:缓冲区(index or staged)
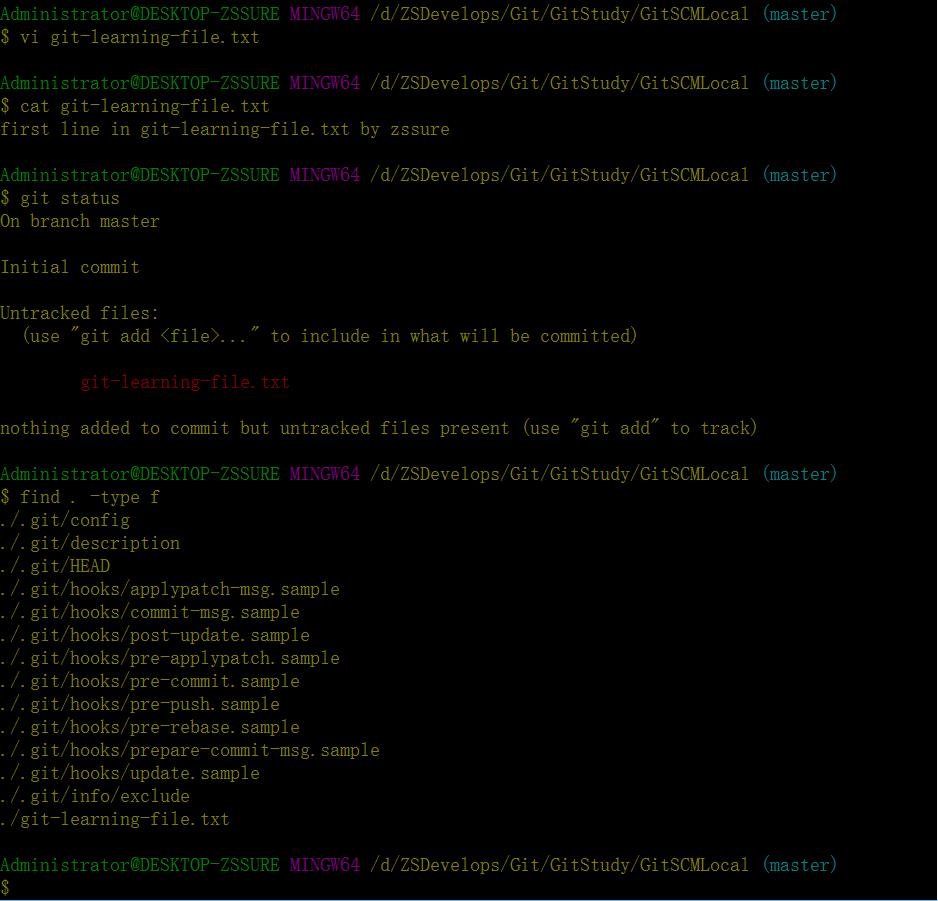
初始化完成后,我们开始正常工作,创建一个测试txt文件git-learning-file.txt,输入一行字符串。此时使用git status查看一下状态:
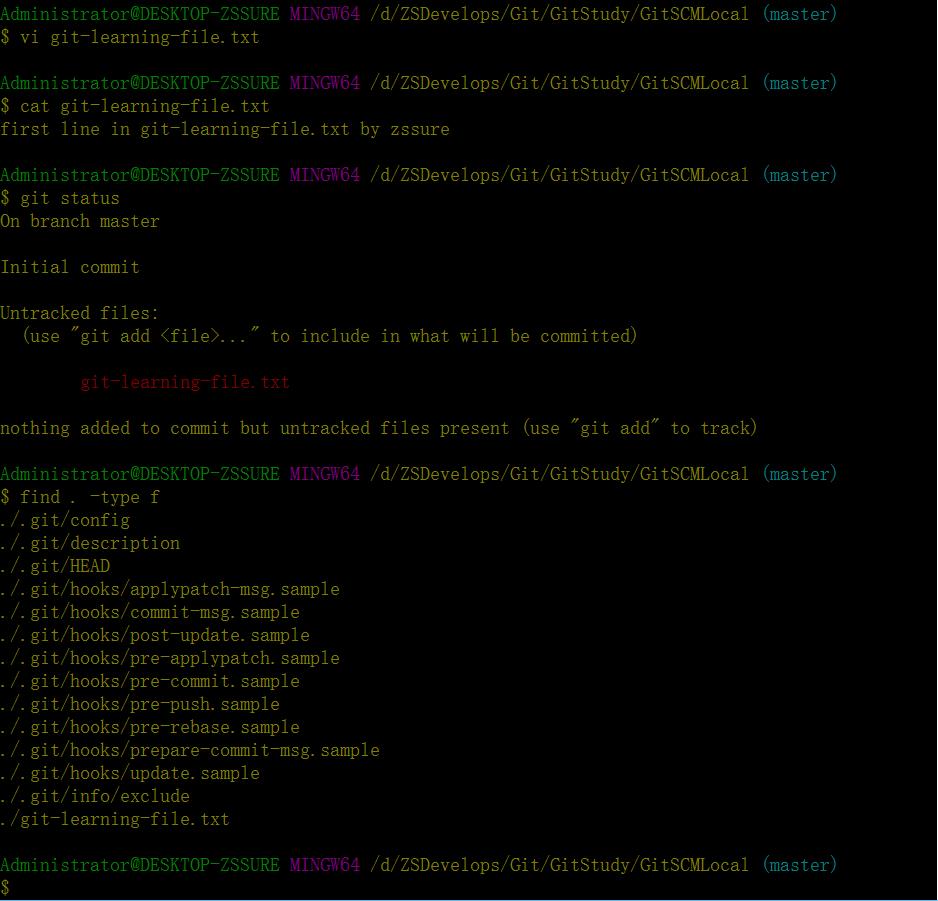
从上图可以看出git-learning-file.txt文件还没进入到git仓库内部,处于untracked状态,.git文件夹与初始化时刻相同(find . -type f指令的运行结果可以看出),并未发生任何变化,所以git status之所以能够将untracked文件标记出来,是通过排除的方式,即.git仓库中没有记录的同级目录下的所有文件。
下面我们将新增的测试文件git-learning-file.txt添加到缓冲区中,输入指令:
git add git-learning-file.txt此刻再次运行git status和find . -type f两条指令,得到的结果如下截图:
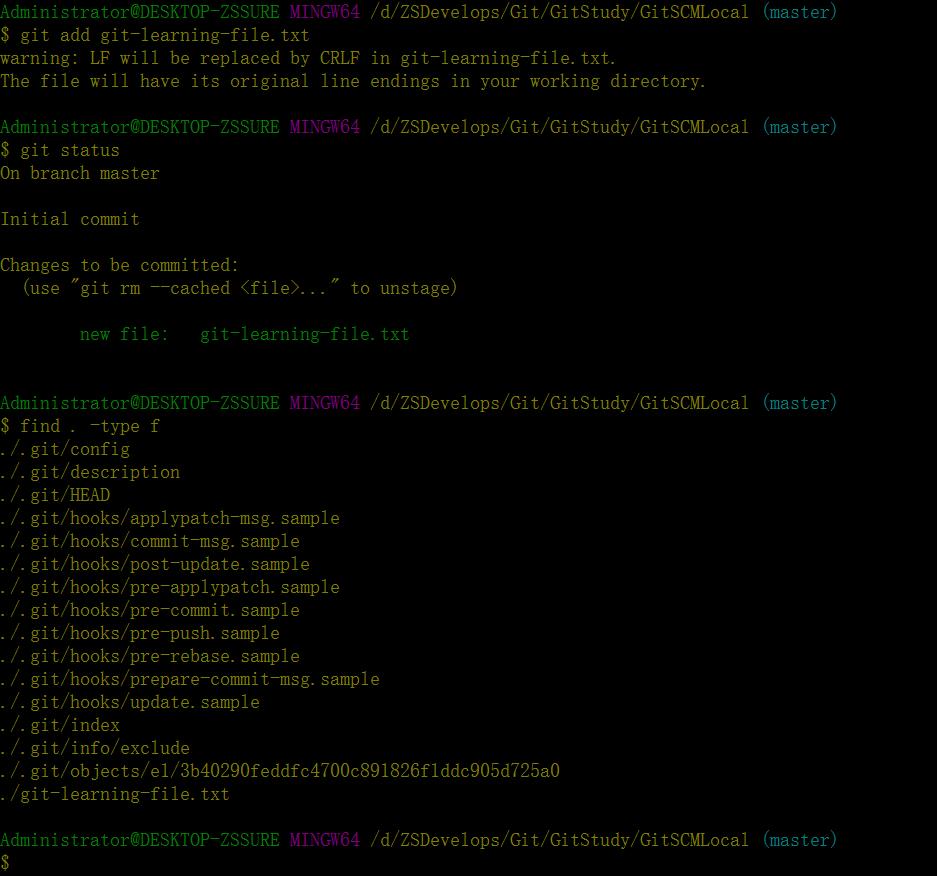
由此我们可以看出,git add指令执行成功后,git-learning-file.txt文件已经被标记为staged状态(截图中的绿色标记)。此时可以看到在.git/objects目录下多出了一个文件e1/3b4029。——这与上文介绍的objects目录的作用一致,用于存储所有git仓库数据库的内容,以文件的形式存储(因为git是一款基于内容检索的文件系统)。
这里我们可以使用官方给出的工具git cat-file查看一下多出来的这个文件存储的内容是啥?输入如下指令:
#cat指令本身在linux下就是现实文件内容的工具,谁让git的作者与linux是同一个大神呢
#-p是print的意思,用于直接将内容打印到stdout
git cat-file -p e13b4029结果如下:

这正是我们缓冲区git-learning-file.txt文件的内容,依然用一张图来概括一下:

由此我们可以对git如何管理和归档文件有一个宏观的认识,说到底就是:
一个基于内容检索的文件系统,Content-Basd Filesystem。我们常见的文件系统(NTFS、FAT、FAT32)是基于地址的方式来检索,即先给定具体的地址(32位或64位)然后从地址编号所对应的存储单元内部取出文件内容,而Content-Based Filesystem恰恰相反,是通过对文件整个内容进行运算,得到的结果才是一个真实的存储位置,类似于哈希映射,为了叙述方便,这里就简单的理解为哈希映射吧。
3. GIT存储第二阶段:提交(commit)
从初始化git init(文件的untracked),到git add(staged状态),上两节已经做了简单介绍。随后我们来看一下commit提交,即:
git commit -m "add git-learning-file.txt"运行成功后,还是使用git status和find . -type f两条指令来看一下git仓库和当前目录的状态:
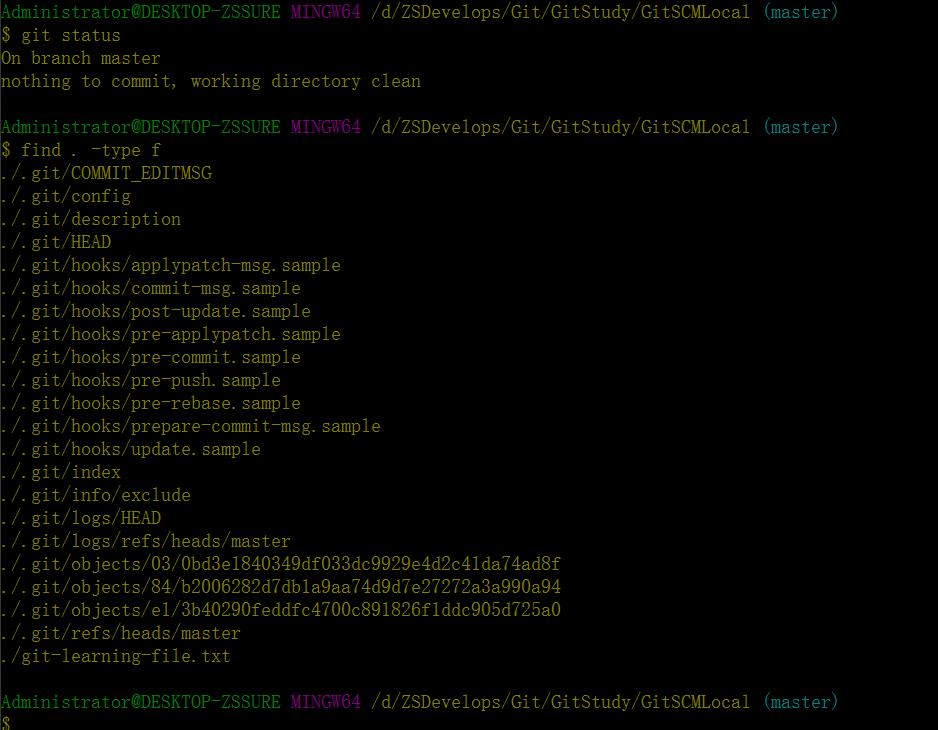
由上图可以看出,git commit成功后在git add基础上objects文件夹内又多出了两个文件,030bd3e和84b2006(从文件的归档路径和命名方式可以看出git使用了SHA-1算法对文件内容进行了校验——即基于文件内容的哈希映射系统),再次使用官方的git cat-file工具查看一下这两个文件的内容:
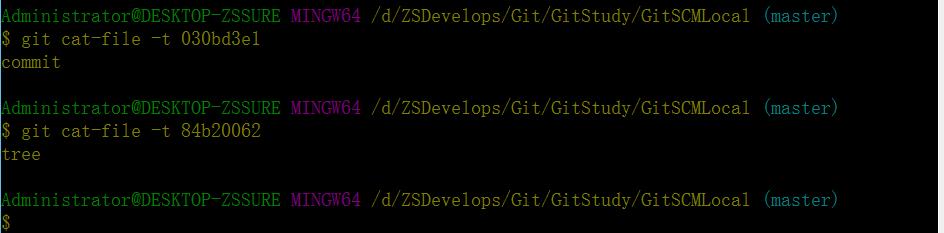
由此看出多出的两个文件,一个是commit对象,一个是tree对象(关于blob、commit、tree三个对象的具体介绍,请阅读官方文档Git Objects)。
还是用一张图概括:
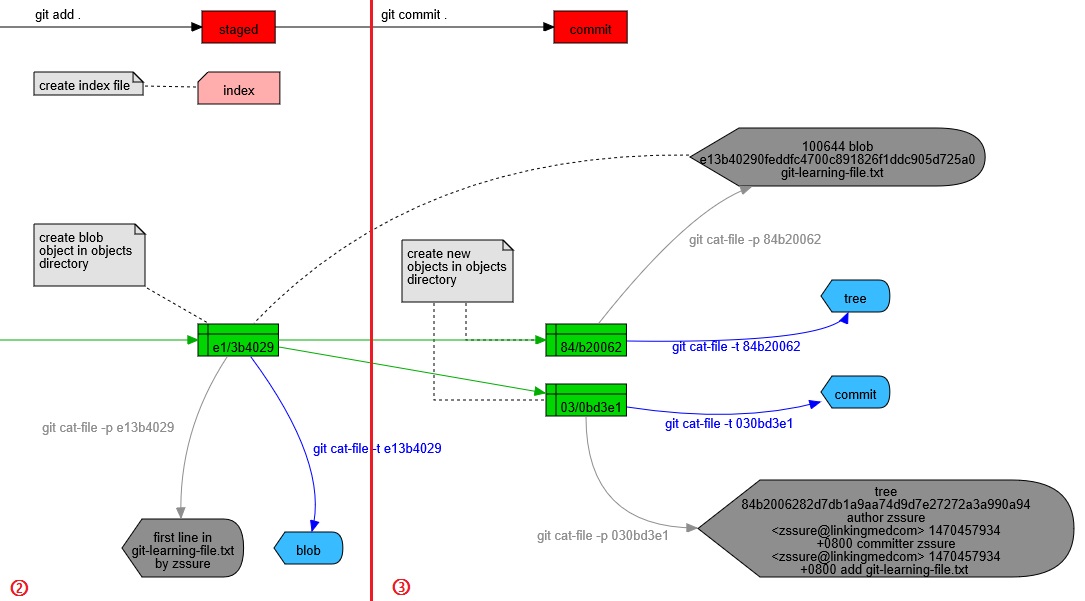
总结:
用完整的一张图来概括总结上述“GIT的管流程”,如下:
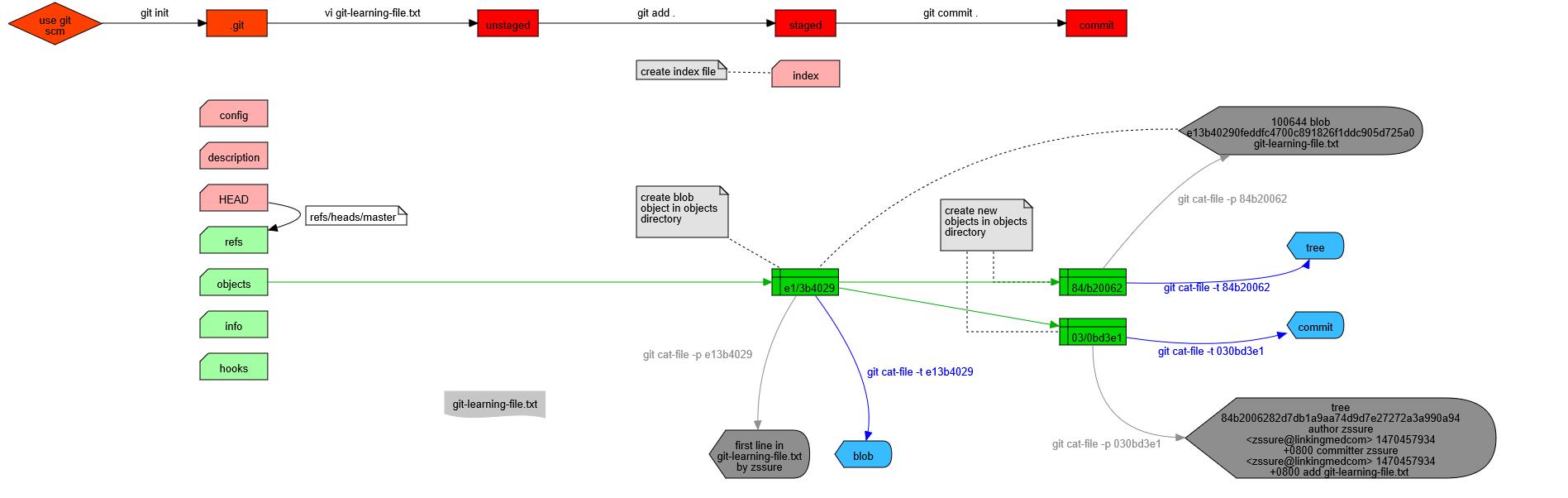
至此我们就简单的探究了一下GIT仓库内部的数据库存储机制和相关细节,此刻可以联想一下上一篇博文介绍的git clone和git checkout等指令,其原理也是一样的:
正是上图中概括的数据归档机制,使得GIT能够详细记录与仓库同级目录下所有文件的各种状态。也正是因为此,后续git checkout等指令才能自如的从已归档的数据库中取出、复原或覆盖(丢弃)当前工作环境的文件,实现版本的自由管理。
后续博文会基于该底层机制继续介绍日常开发工作中常用的指令(例如git reset、git revert、git branch),“知其然知其所以然”,了解了git底层归档的机制,想必后续的学习会更清晰、透彻。
【备注】由于CSDN博客模板限制,想看高清原图,在图片右键选择“在新标签页中打开图片”即可看到原图。
作者:zssure@163.com
时间:2016-08-06
以上是关于GIT科普系列3:底层存储机制Internal Objects的主要内容,如果未能解决你的问题,请参考以下文章