Spark读写Hive添加PMML支持
Posted fansy1990
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spark读写Hive添加PMML支持相关的知识,希望对你有一定的参考价值。
软件版本:
CDH:5.8.0;Hadoop:2.6.0 ; Spark:1.6.0; Hive:1.1.0;JDK:1.7 ; SDK:2.10.6(Scala)
工程下载:https://github.com/fansy1990/spark_hive_source_destination/releases/tag/V1.1
目标:
在Spark加载PMML文件处理数据(参考:http://blog.csdn.net/fansy1990/article/details/53293024)及Spark读写Hive(http://blog.csdn.net/fansy1990/article/details/53401102)的基础上,整合这两个操作,即使用Spark读取Hive表数据,然后加载PMML文件到模型,使用模型对读取对Hive数据进行处理,得到新的数据,写入到新的Hive表。
实现:
1. 工程pom文件,工程pom文件添加了spark、spark-hive以及pmml的依赖支持,如下:
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/maven-v4_0_0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>cdh5.7.3</groupId>
<artifactId>spark_hive</artifactId>
<version>1.0-SNAPSHOT</version>
<inceptionYear>2008</inceptionYear>
<properties>
<scala.version>2.10.6</scala.version>
<spark.version>1.6.0-cdh5.7.3</spark.version>
</properties>
<repositories>
<repository>
<id>cloudera</id>
<url>https://repository.cloudera.com/artifactory/cloudera-repos/</url>
</repository>
</repositories>
<dependencies>
<!-- Spark -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.10</artifactId>
<version>$spark.version</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-mllib_2.10</artifactId>
<version>$spark.version</version>
<exclusions>
<exclusion>
<groupId>org.jpmml</groupId>
<artifactId>pmml-model</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.jpmml</groupId>
<artifactId>pmml-evaluator</artifactId>
<version>1.2.15</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_2.10</artifactId>
<version>$spark.version</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.10</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.specs</groupId>
<artifactId>specs</artifactId>
<version>1.2.5</version>
<scope>test</scope>
</dependency>
</dependencies>
<build>
<sourceDirectory>src/main/scala</sourceDirectory>
<testSourceDirectory>src/test/scala</testSourceDirectory>
<plugins>
<plugin>
<groupId>org.scala-tools</groupId>
<artifactId>maven-scala-plugin</artifactId>
<version>2.15.2</version>
<executions>
<execution>
<goals>
<goal>compile</goal>
<goal>testCompile</goal>
</goals>
</execution>
</executions>
<configuration>
<scalaVersion>$scala.version</scalaVersion>
<args>
<arg>-target:jvm-1.7</arg>
</args>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>2.4.2</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<createDependencyReducedPom>false</createDependencyReducedPom>
<finalName>example-$project.version</finalName>
<artifactSet>
<excludes>
<exclude>oro*</exclude>
<exclude>org.apache.*:*</exclude>
<exclude>junit:junit</exclude>
<exclude>org.sc*</exclude>
<exclude>org.sp*</exclude>
<exclude>org.sl*</exclude>
<exclude>org.r*</exclude>
<exclude>org.c*</exclude>
<exclude>org.t*</exclude>
<exclude>org.e*</exclude>
<exclude>org.u*</exclude>
<exclude>org.x*</exclude>
<exclude>org.js*</exclude>
<exclude>org.jo*</exclude>
<exclude>org.f*</exclude>
<exclude>org.m*</exclude>
<exclude>org.o*</exclude>
<exclude>*:xml-apis</exclude>
<exclude>log4j*</exclude>
<exclude>org.antlr*</exclude>
<exclude>org.datanucleus*</exclude>
<exclude>net*</exclude>
<exclude>commons*</exclude>
<exclude>com.j*</exclude>
<exclude>com.x*</exclude>
<exclude>com.n*</exclude>
<exclude>com.i*</exclude>
<exclude>com.t*</exclude>
<exclude>com.c*</exclude>
<exclude>com.gi*</exclude>
<exclude>com.google.code*</exclude>
<exclude>com.google.p*</exclude>
<exclude>com.f*</exclude>
<exclude>com.su*</exclude>
<exclude>com.a*</exclude>
<exclude>com.e*</exclude>
<exclude>javax*</exclude>
<exclude>s*</exclude>
<exclude>i*</exclude>
<exclude>j*</exclude>
<exclude>a*</exclude>
<exclude>x*</exclude>
</excludes>
</artifactSet>
<relocations>
<relocation>
<pattern>com.google.common</pattern>
<shadedPattern>com.shaded.google.common</shadedPattern>
</relocation>
<relocation>
<pattern>org.dmg.pmml</pattern>
<shadedPattern>org.shaded.dmg.pmml</shadedPattern>
</relocation>
<relocation>
<pattern>org.jpmml.agent</pattern>
<shadedPattern>org.shaded.jpmml.agent</shadedPattern>
</relocation>
<relocation>
<pattern>org.jpmml.model</pattern>
<shadedPattern>org.shaded.jpmml.model</shadedPattern>
</relocation>
<relocation>
<pattern>org.jpmml.schema</pattern>
<shadedPattern>org.shaded.jpmml.schema</shadedPattern>
</relocation>
</relocations>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>
2. 测试环境构建:
1)首先是生成pmml文件,这个文件已经由其他程序生成,如下:
<?xml version="1.0" encoding="UTF-8" standalone="yes"?>
<PMML version="4.2" xmlns="http://www.dmg.org/PMML-4_2">
<Header description="linear SVM">
<Application name="Apache Spark MLlib"/>
<Timestamp>2016-11-16T22:17:47</Timestamp>
</Header>
<DataDictionary numberOfFields="4">
<DataField name="field_0" optype="continuous" dataType="double"/>
<DataField name="field_1" optype="continuous" dataType="double"/>
<DataField name="field_2" optype="continuous" dataType="double"/>
<DataField name="target" optype="categorical" dataType="string"/>
</DataDictionary>
<RegressionModel modelName="linear SVM" functionName="classification" normalizationMethod="none">
<MiningSchema>
<MiningField name="field_0" usageType="active"/>
<MiningField name="field_1" usageType="active"/>
<MiningField name="field_2" usageType="active"/>
<MiningField name="target" usageType="target"/>
</MiningSchema>
<RegressionTable intercept="0.0" targetCategory="1">
<NumericPredictor name="field_0" coefficient="-0.36682158807862086"/>
<NumericPredictor name="field_1" coefficient="3.8787681305811765"/>
<NumericPredictor name="field_2" coefficient="-1.6134308474471166"/>
</RegressionTable>
<RegressionTable intercept="0.0" targetCategory="0"/>
</RegressionModel>
</PMML> 2)准备hive表及表数据:
-- field_0,field_1,field_2
-- 98,97,96
create table svm (
field_0 double ,
field_1 double,
field_2 double
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
STORED AS TEXTFILE;
-- import data , get ride of first line
load data inpath 'svm.data' into table svm;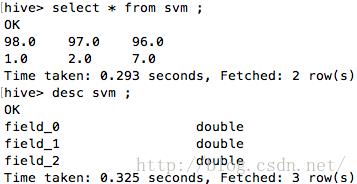
3) 编译及打包:下载工程后,先执行build-》Make project,看到target目录下生成classes文件,如下:
因为使用了java和scala混合编程,所以这里需要先编译,然后在执行maven的package命令,这样的到的jar包才会包含pmml-spark的相关class文件,并且由于这里没有引入pmml-spark的依赖,只是把其源码放到这里而已,所以需要这样做,打包后,得到target目录下的所需jar包;
4)调用:
直接使用spark-submit的方式进行调用,其命令如下:
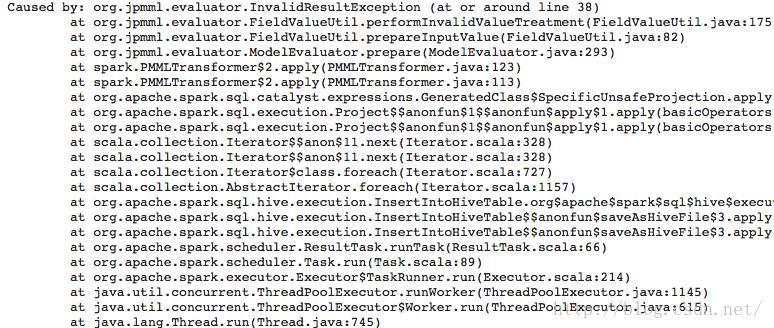
spark-submit --class pmml.SparkReadWriteHiveWithPMML --master yarn --deploy-mode cluster --jars /usr/lib/hive/lib/datanucleus-core-3.2.10.jar --files /usr/lib/hive/conf/hive-site.xml example-1.0-SNAPSHOT.jar svm tmp4 /tmp/svm.pmml如果输出表存在,那么会报错(如tmp4存在):
首先是yarn任务,如下:
接着是hive中的表,如下:
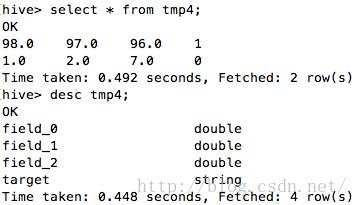
从hive表中可以看到数据被pmml模型正确的预测得到了。
总结:
1. Hive表如果使用分区表情况会比较复杂,暂时没有验证过;
2. 如果hive表已经存在,那么会出现异常,是否可以考虑在代码中把输出的表删掉?
3. pmml-spark依赖是否可以直接写入pom文件,而不需要把源码放入工程?
如果您觉得lz的文章还行,并且您愿意动动手指,可以为我投上您的宝贵一票!谢谢!
http://blog.csdn.net/vote/candidate.html?username=fansy1990
以上是关于Spark读写Hive添加PMML支持的主要内容,如果未能解决你的问题,请参考以下文章