Hive性能调优
Posted fansy1990
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hive性能调优相关的知识,希望对你有一定的参考价值。
软件环境:Hive1.2.1 /Hadoop2.6.4 ;直接使用Hive Cli模式运行;
1. 设置执行引擎
set hive.execution.engine=mr;
set hive.execution.engine=spark;2. 针对mr调优,可以设置参数(针对map端):
set mapred.max.split.size=1000000;10个 = 10 M / 1000000
mapreduce.map.memory.mb=4096 // 设置申请map资源 内存
mapreduce.map.cpu.vcores=1 //设置申请cpu资源(useless)
那假设现在有144个map任务,集群资源为:3子节点*8G内存*8核cpu,启动Hive的MR任务,同时会有多少个任务在运行呢?
要回答这个问题,就需要梳理下MapReduce运行任务时,YARN资源分配的流程;
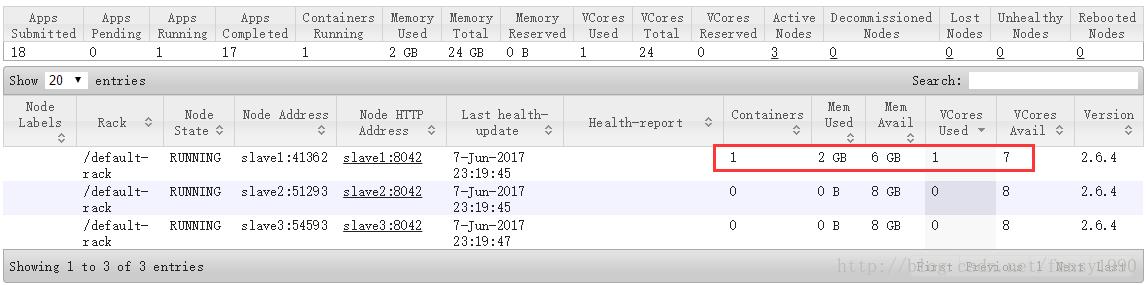
1)YARN启动MR任务时,会首先启动一个ApplicationMaster来管理当前任务,所以启动后,这个ApplicationMaster会占用一定资源,比如我这里占用资源2G内存,1核cpu,会被随机分配到一个节点上,比如我这里的slave1节点:
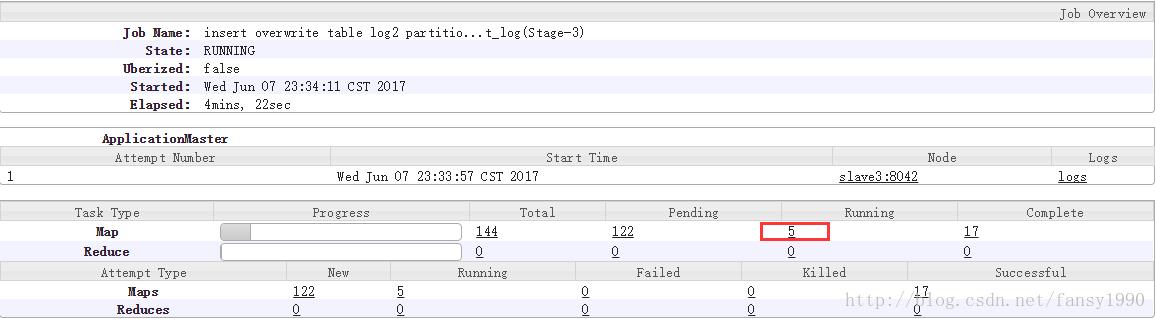
2) 接下来怎么判断可以同时运行多少个Map任务呢?
现在集群还剩资源= 22G内存+23核cpu ,如果map任务配置内存为4G,核心为1核那么,能同时运行:
5 = min(22G/4G = 5 , 23/ 1 = 23 )
也就是同时运行5个map任务,如下:
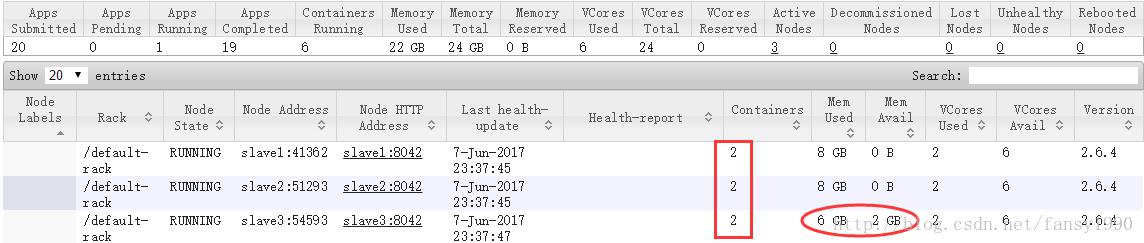
3)那这时集群还剩多少资源呢?
(3*8G内存 + 3*8核CPU )- (1核CPU,2G内存) - 5 * (4G内存,1核CPU) = (2G内存,18核CPU)
验证一下:
3. 针对mr调优,可以设置参数(针对reduce端),这个暂时没有实验,暂时给出一个参考:
mapreduce.job.reduces=2(可手工设置)
Hive.exec.reducers.max (hive设置的最大可用reducer)
hive.exec.reducers.bytes.per.reducer (hive默认每1G文件分配一个reduce)
分配算法
num_reduce_tasks=min[maxReucers,input.size/perReducer]脚踏实地,专注
转载请注明blog地址:http://blog.csdn.NET/fansy1990
以上是关于Hive性能调优的主要内容,如果未能解决你的问题,请参考以下文章