Spark TopK问题解法
Posted fansy1990
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spark TopK问题解法相关的知识,希望对你有一定的参考价值。
软件版本及平台:
CDH5.8、四子节点(cpu:2核、内存:4G)、JDK:1.7、IDEA14 、 Spark:1.6.0-cdh5.7.3; 代码下载:问题描述:
现有用户项目评分数据,其格式如下所示:u1,item1,0.0913375062480507
u2,item1,0.4061823571029518
u3,item1,0.021727289053235843
u4,item1,0.24172510761164112
u5,item1,0.7898802150245668
u6,item1,0.2166110282064876现需要求得每个用户对项目的评分前10个的数据,如下所示:
(u9,List((item74540,0.9999953894581668), (item76768,0.9999930103445652), (item21169,0.9999889286058848), (item4820,0.9999782306748293), (item85543,0.9999663834573093), (item8372,0.9999487766494871), (item99252,0.9999365275502845), (item23653,0.9999347307884792), (item19615,0.9999236599402785), (item30399,0.999918672799968)))
(u18,List((item48113,0.9999984432903763), (item44728,0.9999823700583934), (item65298,0.9999721951269472), (item11426,0.9999686624512639), (item72669,0.9999525503292274), (item36801,0.9999334853565013), (item49233,0.9999283335977657), (item67481,0.9999041428222344), (item47549,0.9998546064810947), (item66968,0.999842604478957)))思路:
思路有三种:- a. 读取数据后,使用把数据转换为(user,(item,pref))这样的键值对;b. 然后使用combineByKey把相同user的数据整合起来;c. 最后调用map,针对每个(user,List((item,pref)))这样的数据中的List进行排序,然后取其前k个;
- 参考思路1中的a.b.c步骤,只是在c步骤不是对List直接排序取前k个,而是使用一个堆栈,得到List中pref最大的k个值返回;
- a. 读取数据后,构造(StringDouble(user,pref),item)这样的键值对,同时需要对StringDouble这样的类构造比较方法;b. 调用repartitionAndSortWithinPartitions方法来对RDD进行分区,分区规则根据key来,把相同的用户分为一个区,所以这里要定义一个分区器;c. 调用mapPartition对每个partition也就是每个用户取其前k个值返回;
思路1:
对整合后的每个用户的项目按照其评分进行排序,取其前k个; 代码如下:/**
*先合并所有用户的item,然后对每个item排序,然后取前k个
* @param input
* @param output
* @param k
*/
def fun1(sc:SparkContext,input:String ,output:String, k :Int,num:Int) =
val start = System.currentTimeMillis;
sc.textFile(input,num).mapx => val f = x.split(",");(f(0),(f(1),f(2).toDouble)).
combineByKey((x:(String,Double)) => List(x),
(c:List[(String,Double)], x:(String,Double)) => c :+ x ,
(c1:List[(String,Double)], c2:List[(String,Double)]) => c1 ::: c2).
map(x => (x._1 , x._2.sortWith((x,y) => x._2 > y._2).take(10))).
saveAsTextFile(output)
println("fun1,k: "+k+",input:"+input+",num:"+num+"---> time:"+
(System.currentTimeMillis - start )*1.0 /1000 +" s")
思路2:
对整合后的每个用户的项目按照其评分使用堆栈求其前k个; 代码如下:/**
* 先合并所有用户item,然后使用堆栈获取k个top值
* @param sc
* @param input
* @param output
* @param k
*/
def fun2(sc:SparkContext,input:String ,output:String, k :Int,num:Int) =
val start = System.currentTimeMillis
sc.textFile(input,num).mapx => val f = x.split(",");(f(0),(f(1),f(2).toDouble)).
combineByKey((x:(String,Double)) => List(x),(c:List[(String,Double)], x:(String,Double)) => c :+ x ,
(c1:List[(String,Double)], c2:List[(String,Double)]) => c1 ::: c2).
map(x => (x._1 ,MyUtils.top10(x._2,k))).saveAsTextFile(output)
println("fun2,k: "+k+",input:"+input+",num:"+num+"---> time:"+
(System.currentTimeMillis - start )*1.0 /1000 +" s")
package org.apache.spark.util
import org.apache.spark.util
/**
* Created by fansy on 2016/12/13.
*/
object MyUtils
implicit val sortStringDoubleByDouble = new Ordering[(String,Double)]
override def compare(a: (String,Double), b: (String,Double)) = (b._2 - a._2 ).toInt
/**
* 使用堆栈获取最大值k个
* @param items
* @param k
* @return
*/
def top10(items : List[(String,Double)], k:Int):List[(String,Double)] =
val queue = new BoundedPriorityQueue[(String,Double)](k)(sortStringDoubleByDouble)
queue ++= util.collection.Utils.takeOrdered(items.iterator, k)(sortStringDoubleByDouble)
queue.toList
思路3:
使用自定义Key类型,使用repartitionAndSort,自定义分区器,mapPartition来获取topk; 1. 首先定义key类型:/**
* 根据d排序,由于每个分区的s是一样的,所以只需要根据d排序即可
* @param s
* @param d
*/
case class StringDoubleKey(s:String,d:Double)
object StringDoubleKey
implicit def orderingByDouble[A <: StringDoubleKey] : Ordering[A] =
Ordering.by(x => - x.d)
/**
* partition根据 键值对的s进行分区
* 需要保证每个用户放到一个分区里面
* @param userNum
*/
case class partition(userNum:Map[String,Int]) extends Partitioner
override def getPartition(key: Any): Int =
userNum(key.asInstanceOf[StringDoubleKey].s)
override def numPartitions: Int = userNum.size
/**
* 每个用户的数据组成一个partition,然后每个partition获取topk
* @param sc
* @param input
* @param output
* @param k
* @param num partition的个数没有用
*/
def fun3(sc:SparkContext,input:String ,output:String, k :Int,num:Int) =
var start = System.currentTimeMillis
val data = sc.textFile(input).mapx => val f = x.split(",");(StringDoubleKey(f(0),f(2).toDouble),f(1))
val userNum = data.map(x => x._1.s).distinct.collect
println("fun3,k: "+k+",input:"+input+",num:"+num+"---> time:"+
(System.currentTimeMillis - start )*1.0 /1000 +" s")
start = System.currentTimeMillis()
data.repartitionAndSortWithinPartitions( partition(userNum.zip(0 until userNum.size).toMap)).mapPartitions(topK(k)).saveAsTextFile(output)
println("fun3,k: "+k+",input:"+input+",num:"+num+"---> time:"+
(System.currentTimeMillis - start )*1.0 /1000 +" s")
主函数里面先求得所有用户的distinct值(去重),然后把各个用户使用0到用户个数-1进行映射;接着调用repartitionAndSortWithInPartitions方法进行每个partition内部排序,其排序逻辑就采用StringDoubleKey的排序逻辑;最后,调用mapPartition对每个partition取前k个值就可以了,这里topK返回的同样是一个函数; 4. 定义topK函数
/**
* 每个partition返回一条记录
* topk ,返回用户,list((item,pref),(item,pref))
* @param k
* @param iter
* @return
*/
def topK(k :Int )(iter : Iterator[(StringDoubleKey,String)]):Iterator[(String,List[(String,Double)])] =
val pre = iter.next
val user = pre._1.s
var items_pref = List[(String, Double)]((pre._2,pre._1.d))
for (cur <- iter if items_pref.length < k)
items_pref .::= (cur._2, cur._1.d)
Array((user,items_pref)).iterator
topK实现采用柯里化方式返回一个函数,这里需要注意的是接收的参数以及返回的参数,由于每个partition传过来的参数是Iterator[(StringDoubleKey,String)],并且输出的应该是(user,List(Item,pref),后面的list是前k个;同时在处理iterator的时候,也要注意其遍历一次的特性,取了next后,再接着访问的就是iter下面的一个值了;
实验:
1. 生成数据: 生成数据一共分为多个用户多个项目构成,其代码如下所示:sc.parallelize(for( i <- 1 to 100000; j <- 1 to 50) yield ("u"+j,"item"+i,Math.random),4).map(x => x._1+","+x._2+","+x._3).saveAsTextFile("/tmp/user1000_item3w")
sc.parallelize(for( i <- 1 to 30000; j <- 1 to 100) yield ("u"+j,"item"+i,Math.random),4).map(x => x._1+","+x._2+","+x._3).saveAsTextFile("/tmp/user300_item3w")
sc.parallelize(for( i <- 1 to 300000; j <- 1 to 10) yield ("u"+j,"item"+i,Math.random),4).map(x => x._1+","+x._2+","+x._3).saveAsTextFile("/tmp/user10_item30w")
sc.parallelize(for( i <- 1 to 500000; j <- 1 to 10) yield ("u"+j,"item"+i,Math.random),4).map(x => x._1+","+x._2+","+x._3).saveAsTextFile("/tmp/user10_item50w")
sc.parallelize(for( i <- 1 to 1000000; j <- 1 to 10) yield ("u"+j,"item"+i,Math.random),4).map(x => x._1+","+x._2+","+x._3).saveAsTextFile("/tmp/user10_item100w")sc.parallelize(for( j <- 1 to 100000) yield "u"+j,32).flatMap(x => for(j <- 1 to 1000) yield (x,"item"+j,Math.random)).map(x => x._1+","+x._2+","+x._3).saveAsTextFile("/tmp/user10w_item1k")其在HDFS上的截图如下所示:

2. 调用代码: 编写一个for循环来运行任务,代码如下:
#!/bin/bash
echo "Start..."
input=("user_100_item_3w" "user_20_item_10w" "user_50_item_10w")
method=(1 2)
partition=(4 8 12 16 20 24 28 32)
for i in $input[@]
do
for m in $method[@]
do
for p in $partition[@]
do
echo "input:_$i ,method: $m ,par: _$p,"
spark-submit --name "input :$i,method:fun$m,partition:$p" --class topk.TopK --master yarn --deploy-mode cluster --driver-memory 3G --executor-memory 3G --num-executors 8 top.jar "/tmp/$i" "/tmp/fun$m_$i_par$p" $m 10 $p 1>/dev/null 2>/dev/null ;
done
done
done
#!/bin/bash
echo "Start..."
input=("user10_item30w" "user10_item50w" "user10_item100w")
method=(1 2)
partition=(16 20 24 28 32)
for i in $input[@]
do
for m in $method[@]
do
for p in $partition[@]
do
echo "input:_$i ,method: $m ,par: _$p,"
spark-submit --name "input :$i,method:fun$m,partition:$p" --class topk.TopK --master yarn --deploy-mode cluster --driver-memory 3G --executor-memory 3G --num-executors 8 top.jar "/tmp/$i" "/tmp/fun$m_$i_par$p" $m 10 $p 1>/dev/null 2>/dev/null ;
done
done
done
#!/bin/bash
echo "Start..."
input=("user_100_item_3w" "user_20_item_10w" "user_50_item_10w" "user10_item30w" "user10_item50w" "user10_item100w")
method=(3)
partition=(4) # partition个数没有影响
for i in $input[@]
do
for m in $method[@]
do
for p in $partition[@]
do
echo "input:_$i ,method: $m ,par: _$p,"
spark-submit --name "input :$i,method:fun$m,partition:$p" --class topk.TopK --master yarn --deploy-mode cluster --driver-memory 3G --executor-memory 3G --num-executors 8 top.jar "/tmp/$i" "/tmp/fun$m_$i_par$p" $m 10 $p 1>/dev/null 2>/dev/null ;
done
done
done
当然上面的代码第一个和第二个可以合并,第三个代码是测试第三种方法的代码; 3. 测试结果 等待所有程序运行完成,可以看到任务监控以及HDFS监控,如下:

查找日志,可以看到具体时间,如下:

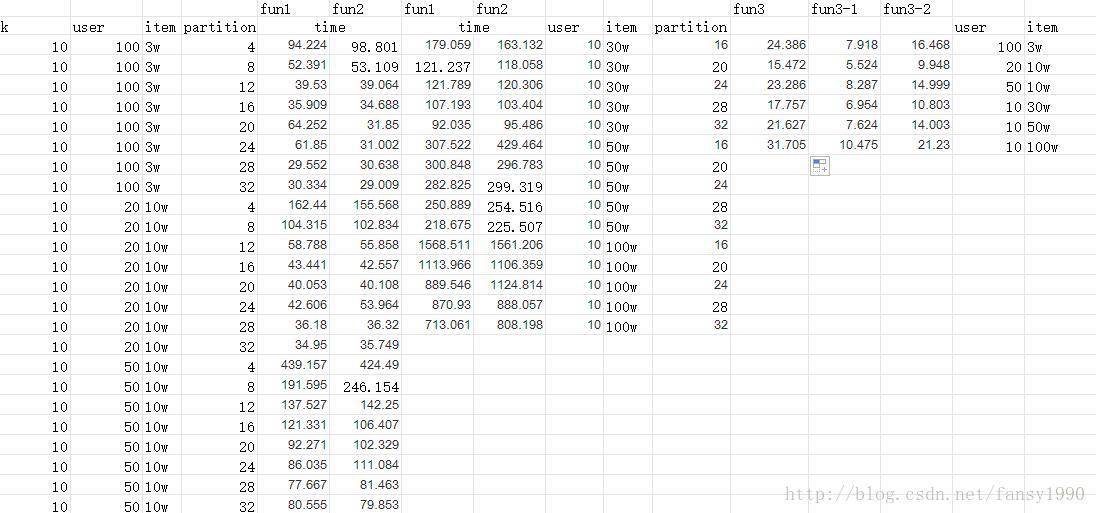
各个时间整理,如下表所示:
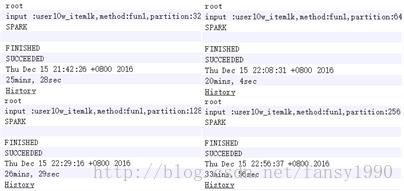
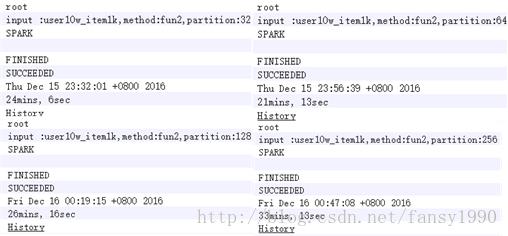
使用10w用户,1k的数据量进行TopK操作,得到的结果分别如下:

总结
1. 思路1和思路2总体时间相差不多,但是从直观的想法来看,一般情况下思路2要比思路1的效率高,但是从实验中并没有看到这样的效果; 2. 思路1和思路2其partition的个数从数据来看是越大越好,但是这个应该是和数据量比较小有关,当数据量很大的时候partition在一定范围其效果最好; 3. 思路3总体看来会比思路1/思路2的效果好,但是当用户多的时候,使用思路3其效率应该会下降很多;如果您觉得lz的文章还行,并且您愿意动动手指,可以为我投上您的宝贵一票!谢谢!
http://blog.csdn.net/vote/candidate.html?username=fansy1990
以上是关于Spark TopK问题解法的主要内容,如果未能解决你的问题,请参考以下文章