saga模式Seata saga模式详解
Posted 秃秃爱健身
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了saga模式Seata saga模式详解相关的知识,希望对你有一定的参考价值。
文章目录
一、前言
更多内容见Seata专栏:https://blog.csdn.net/saintmm/category_11953405.html
至此,seata系列的内容已出:
- can not get cluster name in registry config ‘service.vgroupMapping.xx‘, please make sure registry问题解决;
- Seata Failed to get available servers: endpoint format should like ip:port 报错原因/解决方案汇总版(看完本文必解决问题)
- Seata json decode exception, Cannot construct instance of java.time.LocalDateTime报错原因/解决方案最全汇总版
- 超细的Spring Cloud 整合Seata实现分布式事务(排坑版)
- Spring Cloud整合Seata、Nacos实现分布式事务案例(巨细排坑版)【云原生】
- 分布式事务Seata源码解析一:在IDEA中启动Seata Server
- 分布式事务Seata源码解析二:Seata Server启动时都做了什么
- 分布式事务Seata源码解析三:从Spring Boot特性来看Seata Client 启动时都做了什么
- 分布式事务Seata源码解析四:图解Seata Client 如何与Seata Server建立连接、通信
- 分布式事务Seata源码解析五:@GlobalTransactional如何开启全局事务
- 分布式事务Seata源码解析六:全局/分支事务分布式ID如何生成?序列号超了怎么办?时钟回拨问题如何处理?
- 分布式事务Seata源码解析七:图解Seata事务执行流程之开启全局事务
- 分布式事务Seata源码解析八:本地事务执行流程(AT模式下)
- 分布式事务Seata源码解析九:分支事务如何注册到全局事务
- 分布式事务Seata源码解析十:AT模式回滚日志undo log详细构建过程
- 分布式事务Seata源码解析11:全局事务执行流程之两阶段全局事务提交
- 分布式事务Seata源码解析12:全局事务执行流程之全局事务回滚
- Spring Cloud整合Seata实现TCC分布式事务模式案例
- 分布式事务Seata源码解析13:TCC事务模式实现原理
- 分布式事务Seata TCC空回滚/幂等/悬挂问题、解决方案(seata1.5.1如何解决?)
- Seata XA模式概述+案例
至此,Seata常用的AT模式、TCC模式 和 XA模式已完结,本文就SAGA模式展开详细的介绍。
二、SAGA模式
1987年普林斯顿大学的Hector Garcia-Molina 和 Kenneth Salem发表了一篇论文《sagas》,它讲述了如何处理long lived transaction(长活事务)。
其核心思想在于:允许分布式事务在全部提交前提前释放占用的某些资源。
0、saga论文摘要
论文下载地址:https://www.cs.princeton.edu/research/techreps/TR-070-87
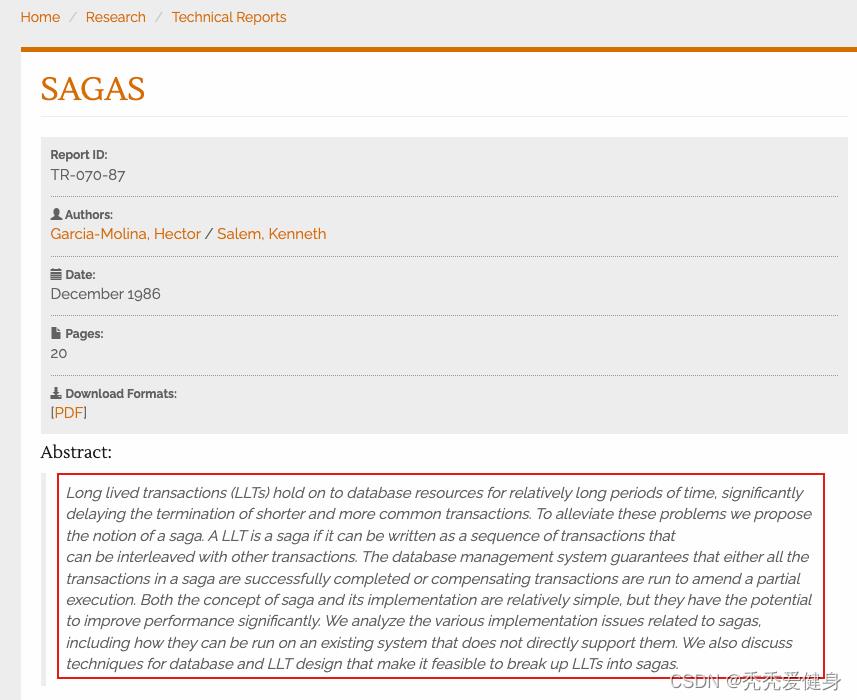
摘要内容翻译:
一个长时间事务会在相对较长的时间内占用数据库资源,明显的阻碍了较短的和公用的其他事务完成。为了缓解这些问题, 我们提出一个 saga的概念。它是由多个有序的事务组成、并且与其他事务可以交错的一个长时间事务(LLT),数据库管理系统保证成功完成 saga 中的所有事务, 或对部分进行事务补偿。saga的概念和它的实施相对简单, 但它们有可能显著提高性能。我们分析了与 sagas 相关的各种实施问题,包括如何在不直接支持它们的现有系统上运行它们。我们进行了数据库和 LLT技术讨论, 使 sagas成为LLT解决方案的可能。
1、什么是长事务?
长事务,就是需要长时间来执行的事务,这类事务往往需要访问大量的数据对象,执行周期也比较长。
二传统的事务执行时需要锁定 / 占用资源,在长事务的场景下,资源将被长期锁定,带来额外的性能消耗。
2、saga的组成
Saga由一系列的本地事务(sub-transaction Ti )组成,其中每个事务在单个服务中更新数据(即:Ti直接提交数据到库);每个Ti 都有对应的补偿动作Ci,补偿动作用于撤销Ti造成的结果。
在saga中仅有第一个事务由外部请求启动,后续每个步骤(事务)由前一个步骤(事务)完成后触发。
3、saga的两种执行场景
saga的本地事务有两种执行顺序:
- forward recovery(向前恢复):
T1, T2, T3, ..., Tn - backward recovery(向后恢复):
T1, T2, ..., Tj, Cj,..., C2, C1,其中0 < j < n
1)forward recovery
向前恢复的方式会假设每个子事务(Ti)最终都会成功,会一直重试失败的事务,这种情况下不需要补偿(Ci)。
本地事务的执行顺序类似于:T1, T2, ..., Tj(失败), Tj(重试),..., Tn,其中 j 是发生错误的sub-transaction。
适用于必须要成功的场景。
- 如果业务中,子事务最终总会成功,亦或是 补偿事务难以定义 或 不可能定义,向前恢复会更符合需求。
2)backward recovery
向后恢复的方式中任意一个子事务失败,会补偿所有已完成的事务,撤销掉之前所有已经成功的 sub-transation,使得整个saga事务的执行结果撤销。
本地事务的执行顺序类似于:T1, T2, ..., Tj, Cj,..., C2, C1,其中0 < j < n,j 是发生错误的sub-transaction。
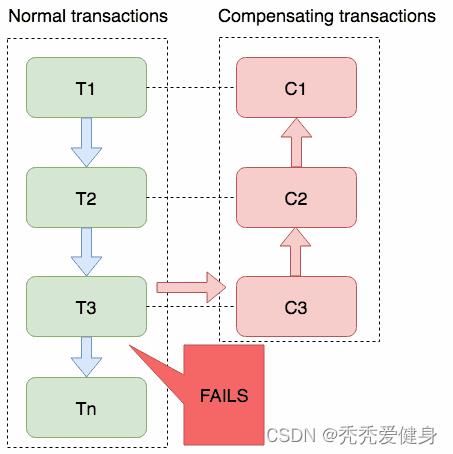
理论上补偿事务永不失败,然而,在分布式中,服务器可能会宕机,网络可能会失败,在这种情况下要提供回退措施,比如:人工干预。
4、saga log
Saga保证所有的子事务都得以完成或补偿,但saga系统本身可能会崩溃。saga崩溃有以下六种情况:
- saga收到事务请求,但尚未开始;子事务对应的微服务状态也未被Saga修改;
- saga收到事务请求,并且一些子事务已经完成。重启后,saga接着上次完成的事务继续向后执行。
- saga收到事务请求,某个子事务已经开始,但尚未完成;由于远程服务可能已完成事务,也可能事务失败,甚至服务请求超时;saga只能重新发起之前未确认完成的子事务。这里子事务必须要幂等。
- saga收到事务请求,某个子事务失败,其补偿事务尚未开始。saga重启后执行对应的补偿事务。
- saga收到事务请求,某个子事务失败,补偿事务已开始但尚未完成。补偿事务也必须是幂等的。
- saga收到事务请求,所有子事务或补偿事务均已完成。
为了处理上述六种情况,必须追踪子事务(Ti)及补偿事务(Ci)的每一步。可以通过事件的方式处理,将事件以JSON的形式存储在名为saga log的持久存储中;事件由以下六种:
- Saga started event:保存整个saga请求,其中包括多个事务/补偿请求。
- Transaction started event:保存对应事务请求
- Transaction ended event:保存对应事务请求及其回复
- Transaction aborted event:保存对应事务请求和失败的原因
- Transaction compensated event:保存对应补偿请求及其回复
- Saga ended event:标志着saga事务请求的结束(不保存任何内容)。
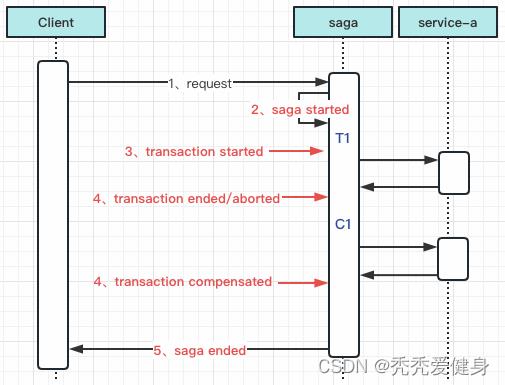
PS:注意注意
Ti和Ci要是幂等的;Ci必须要能够成功,如果无法成功需要重试、人工介入;Ti -> Ci和Ci -> Ti的执行结果必须要一样;即:不能空补偿、悬挂。
5、saga协调(saga实现方式)
saga的实现包含协调saga步骤的逻辑;
- 当请求打到saga时,协调逻辑必须选择出第一个saga参与者执行本地事务;
- 一旦前一个事务执行完成,saga协调需要选择并调用下一个saga参与者;直到saga执行了所有步骤。
- 如果任何本地事务失败,saga必须以相反的顺序执行补偿事务。
构建一个saga的协调逻辑有两种方式:
- 编排(Choreography):当没有中央协调时,每个服务产生并监听其他服务的事件,并决定是否应该采取行动。
- 控制(Orchestration):协调器服务负责集中saga的决策和排序业务逻辑。
Choreography 策略 通过事件机制实现的,每个服务都监听自己所关心的事件,每个服务执行后会发送相应的事件,监听此事件的服务执行相应的处理逻辑。
Orchestration 策略 通过状态机来实现的整体控制,定义整体的处理流程,不同状态下触发不同的动作。
1)SAGA - Choreography 策略
Choreography 是编舞(把舞者之间的动作配合都编排好)的意思。对应到分布式事务中,可以把各个服务理解为舞者。
SAGA 的 Choreography 策略其实就是要定义好先执行哪个服务,根据执行结果再触发哪些服务的执行。
Choreography 策略通过【事件机制】实现:
- 各个服务都定义好正常、异常的处理方法;
- 然后监听目标事件,根据不同的事件 调用不同的处理方法。
1> 优点:
- 简单:服务在创建,更新或删除业务时发布事件对象;
- 松耦合:参与者订阅事件并且彼此之间没有直接的了解;
2> 缺点:
- 服务之间循环依赖:saga参与者订阅彼此的事件,导致创建循环依赖关系;
- 难以理解:整体事件逻辑比较复杂,事件订阅关系很混乱;
2)SAGA - Orchestration 策略
Orchestration 是乐队编排的意思。对应到分布式事务中,各个服务是乐队中的各个演奏者,此外还有一个 总指挥(在 SAGA - Orchestration 策略中需要单独创建一个这样的角色),其是一个控制类,它唯一的职责是告诉saga参与者应该做什么。
Orchestration 策略 通过【状态机】实现:
- 状态机中做整体控制,定义整体的处理流程,不同状态下触发不同的动作;
- 状态机由一组状态和一组由事件触发的状态 之间的转换组成;
- 每个transition都可以有一个action,对于saga来说就是一个saga参与者的调用;
- 状态之间的转换由saga参与者执行本地事务的结果触发不同的状态转换。
- 流程当前状态和本地事务的执行结果决定了状态如何转换 以及 后续执行的操作;
1> 优点:
- 简单的依赖关系:服务之间没有关联,不会引入循环依赖关系,整体结构很清晰;
- 强解耦:每个服务都实现由orchestrator调用的API,服务不需要知道saga参与者发布的事件。
2> 缺点:
- 复杂度更高:多了一个总指挥的角色,在协调器中集中了过多的业务逻辑。
3)如何选择
建议使用编排(Orchestration)方式。因为使用状态机模型可以更轻松地设计、实施和测试。
Seata的saga模式也是基于编排(Orchestration)的方式,通过状态机实现。
三、Seata saga模式
官方文档地址:https://seata.io/zh-cn/docs/user/saga.html
Seata提供的Saga模式目前只能通过状态机引擎来实现,整体机制为:
- 通过状态图来定义服务调用的流程并生成 json 状态语言定义文件;
- 换言之,需要开发者手工的进行Saga业务流程绘制,并将其转换为JSON配置文件;
- 状态图中一个节点可以是调用一个服务,节点可以配置它的补偿节点;
- 注意: 异常发生时是否进行补偿也可由用户自定义决定,可以选择不配置;
- 状态图 json 由状态机引擎驱动执行,当出现异常时状态引擎反向执行已成功节点对应的补偿节点将事务回滚;
- 在程序启动时,会根据saga状态图加载业务处理流程(包括:服务补偿处理);
- 可以实现服务编排需求,支持单项选择、并发、子流程、参数转换、参数映射、服务执行状态判断、异常捕获等功能;
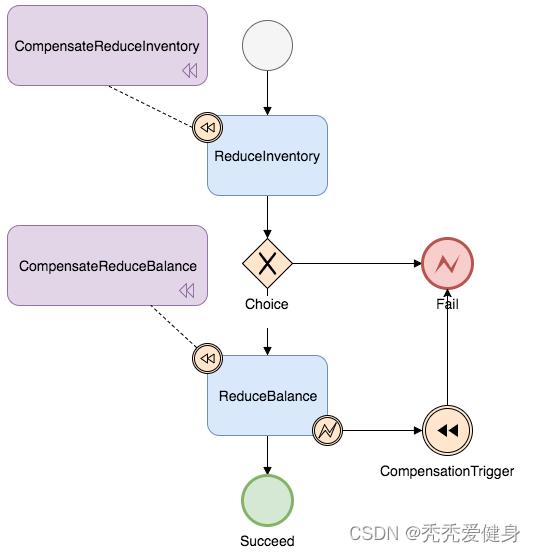
1、示例状态图
2、“状态机”介绍
seata saga的状态语言在一定程度上参考了AWS Step Functions
1)“状态机”属性
Name: 表示状态机的名称,必须唯一Comment: 状态机的描述Version: 状态机定义版本StartState: 启动时运行的第一个"状态"States: 状态列表,是一个map结构,key是"状态"的名称,在状态机内必须唯一IsRetryPersistModeUpdate: 向前重试时, 日志是否基于上次失败日志进行更新IsCompensatePersistModeUpdate: 向后补偿重试时, 日志是否基于上次补偿日志进行更新
2)“状态”属性
Type: “状态” 的类型,比如有:- ServiceTask: 执行调用服务任务
- Choice: 单条件选择路由
- CompensationTrigger: 触发补偿流程
- Succeed: 状态机正常结束
- Fail: 状态机异常结束
- SubStateMachine: 调用子状态机
- CompensateSubMachine: 用于补偿一个子状态机
ServiceName: 服务名称,通常是服务的beanId(也就是Spring容器中的beanName)- 无论是SpringCloud,还是Dubbo、HSF…,最重要的就是配置这个beanId。
ServiceMethod: 服务方法名称(也就是:Spring Bean中的某个方法名)CompensateState: 该"状态"的补偿"状态"Loop: 标识该事务节点是否为循环事务, 即由框架本身根据循环属性的配置, 遍历集合元素对该事务节点进行循环执行Input: 调用服务的输入参数列表, 是一个数组, 对应于服务方法的参数列表,$.表示使用表达式从状态机上下文中取参数,表达使用 SpringEL, 如果是常量直接写值即可Ouput: 将服务返回的参数赋值到状态机上下文中, 是一个map结构,key为放入到状态机上文时的key(状态机上下文也是一个map),value中$.是表示SpringEL表达式,表示从服务的返回参数中取值,#root表示服务的整个返回参数Status: 服务执行状态映射,框架定义了三个状态,SU 成功、FA 失败、UN 未知, 我们需要把服务执行的状态映射成这三个状态,帮助框架判断整个事务的一致性,是一个map结构,key是条件表达式,一般是取服务的返回值或抛出的异常进行判断,默认是SpringEL表达式判断服务返回参数,带$Exception开头表示判断异常类型。value是当这个条件表达式成立时则将服务执行状态映射成这个值Catch: 捕获到异常后的路由Next: 服务执行完成后下一个执行的"状态"Choices: Choice类型的"状态"里, 可选的分支列表, 分支中的Expression为SpringEL表达式, Next为当表达式成立时执行的下一个"状态"ErrorCode: Fail类型"状态"的错误码Message: Fail类型"状态"的错误信息
3)更多状态相关内容
更多详细的状态语言使用示例见github:
https://github.com/seata/seata/tree/develop/test/src/test/java/io/seata/saga/engine
3、示例状态图对应的JSON文件解析
1)JSON
"Name": "reduceInventoryAndBalance",
"Comment": "reduce inventory then reduce balance in a transaction",
"StartState": "ReduceInventory",
"Version": "0.0.1",
"States":
"ReduceInventory":
"Type": "ServiceTask",
"ServiceName": "inventoryAction",
"ServiceMethod": "reduce",
"CompensateState": "CompensateReduceInventory",
"Next": "ChoiceState",
"Input": [
"$.[businessKey]",
"$.[count]"
],
"Output":
"reduceInventoryResult": "$.#root"
,
"Status":
"#root == true": "SU",
"#root == false": "FA",
"$Exceptionjava.lang.Throwable": "UN"
,
"ChoiceState":
"Type": "Choice",
"Choices":[
"Expression":"[reduceInventoryResult] == true",
"Next":"ReduceBalance"
],
"Default":"Fail"
,
"ReduceBalance":
"Type": "ServiceTask",
"ServiceName": "balanceAction",
"ServiceMethod": "reduce",
"CompensateState": "CompensateReduceBalance",
"Input": [
"$.[businessKey]",
"$.[amount]",
"throwException" : "$.[mockReduceBalanceFail]"
],
"Output":
"compensateReduceBalanceResult": "$.#root"
,
"Status":
"#root == true": "SU",
"#root == false": "FA",
"$Exceptionjava.lang.Throwable": "UN"
,
"Catch": [
"Exceptions": [
"java.lang.Throwable"
],
"Next": "CompensationTrigger"
],
"Next": "Succeed"
,
"CompensateReduceInventory":
"Type": "ServiceTask",
"ServiceName": "inventoryAction",
"ServiceMethod": "compensateReduce",
"Input": [
"$.[businessKey]"
]
,
"CompensateReduceBalance":
"Type": "ServiceTask",
"ServiceName": "balanceAction",
"ServiceMethod": "compensateReduce",
"Input": [
"$.[businessKey]"
]
,
"CompensationTrigger":
"Type": "CompensationTrigger",
"Next": "Fail"
,
"Succeed":
"Type":"Succeed"
,
"Fail":
"Type":"Fail",
"ErrorCode": "PURCHASE_FAILED",
"Message": "purchase failed"
2)状态图解析
4、状态机设计器
Seata Saga 提供了一个可视化的状态机设计器方便用户使用,代码和运行指南请参考:
https://github.com/seata/seata/tree/develop/saga/seata-saga-statemachine-designer
- 想要使用状态机设计器,必须要安装nodeJS环境
状态机设计器截图如下:
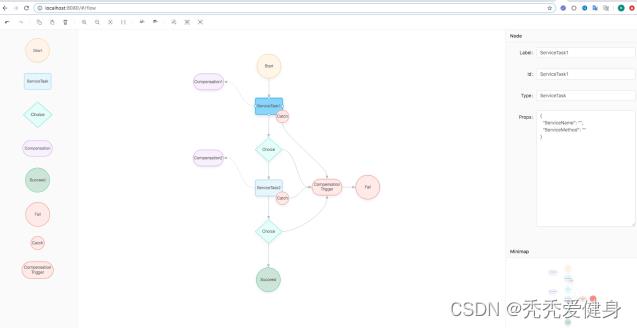
状态机设计器演示(在线画图工具)地址:http://seata.io/saga_designer/index.html
状态机设计器视频教程:http://seata.io/saga_designer/vedio.html
四、saga模式的缺陷
1、空补偿、悬挂、幂等
因为需要自己实现正向服务和逆向补偿服务,所以saga模式会遇到和TCC模式一样的问题:空补偿、悬挂、幂等
TCC模式针对这块的处理见博文: 分布式事务Seata TCC空回滚/幂等/悬挂问题、解决方案(seata1.5.1如何解决?)
1)空补偿
saga模式可能会出现空补偿问题(原服务未执行,补偿服务执行了);
出现原因:
- 原服务 超时(丢包)
- Saga 事务触发 回滚
- 未收到 原服务请求,先收到 补偿请求
解决措施:
- 需要允许空补偿,在没有找到要补偿的业务主键时返回补偿成功并将原业务主键记录下来。
2)悬挂
saga模式可能会出现悬挂问题(补偿服务 比 原服务 先执行);
出现原因:
- 原服务 超时(拥堵)
- Saga 事务回滚,触发 回滚
- 拥堵的 原服务 到达
解决措施:
- 检查当前业务主键是否已经在空补偿记录下来的业务主键中存在,如果存在则要拒绝服务的执行。
3)幂等
原服务与补偿服务都需要保证幂等性, 由于网络可能超时, 可以设置重试策略,重试发生时要通过幂等控制避免业务数据重复更新
2、脏读问题
由于 Saga 事务不保证隔离性, 在极端情况下可能由于脏写无法完成回滚操作;
以一个比较极端的例子为例:
- 分布式事务中先给用户A充值,然后给用户B扣减余额;
- 如果在给A用户充值成功, 在事务提交以前, 其他事务把A用户的余额消费掉了;
- 此时,如果当前事务发生回滚, 这时则没有办法进行补偿了。
这就是缺乏隔离性造成的典型的问题, 实践中一般的应对方法是:
- 业务流程设计时遵循“宁可长款, 不可短款”的原则, 长款意思是客户少了钱机构多了钱, 以机构信誉可以给客户退款, 反之则是短款, 少的钱可能追不回来了。所以在业务流程设计上一定是先扣款。
- 有些业务场景可以允许让业务最终成功, 在回滚不了的情况下可以继续重试完成后面的流程, 所以状态机引擎除了提供“回滚”能力还需要提供“向前”恢复上下文继续执行的能力, 让业务最终执行成功, 达到最终一致性的目的。
分布式事务(Seata) 四大模式详解
前言
在上一节中我们讲解了,关于分布式事务和seata的基本介绍和使用,感兴趣的小伙伴可以回顾一下《别再说你不知道分布式事务了!》 最后小农也说了,下期会带给大家关于Seata中关于seata中AT、TCC、SAGA 和 XA 模式的介绍和使用,今天就来讲解关于Seata中分布式四种模型的介绍。
文中文件资源和项目在结尾都有资源链接
Seata分为三大模块,分别是 TM、RM 和 TC
TC (Transaction Coordinator) - 事务协调者:
维护全局和分支事务的状态,驱动全局事务提交或回滚。
TM (Transaction Manager) - 事务管理器:
定义全局事务的范围:开始全局事务、提交或回滚全局事务。
RM (Resource Manager) - 资源管理器:
管理分支事务处理的资源,与TC交谈以注册分支事务和报告分支事务的状态,并驱动分支事务提交或回滚。
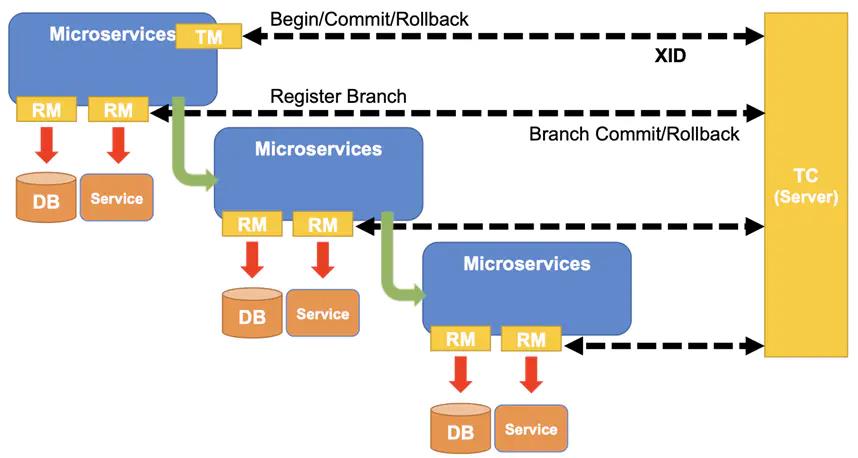
在 Seata 中,分布式事务的执行流程:
- TM 开启分布式事务(TM 向 TC 注册全局事务记录);
- 按业务场景,编排数据库、服务等事务内资源(RM 向 TC 汇报资源准备状态 );
- TM 结束分布式事务,事务一阶段结束(TM 通知 TC 提交/回滚分布式事务);
- TC 汇总事务信息,决定分布式事务是提交还是回滚;
- TC 通知所有 RM 提交/回滚 资源,事务二阶段结束。
TM 和 RM 是作为 Seata 的客户端与业务系统集成在一起,TC 作为 Seata 的服务端独立部署。
服务端存储模式支持三种:
file: 单机模式,全局事务会话信息内存中读写并持久化本地文件root.data,性能较高(默认)
DB: 高可用模式,全局事务会话信息通过DB共享,相对性能差一些
redis: Seata-Server1.3及以上版本支持,性能较高,存在事务信息丢失风险,需要配合实际场景使用
TC环境搭建详解
这里我们使用DB高可用模式,找到conf/file.conf文件
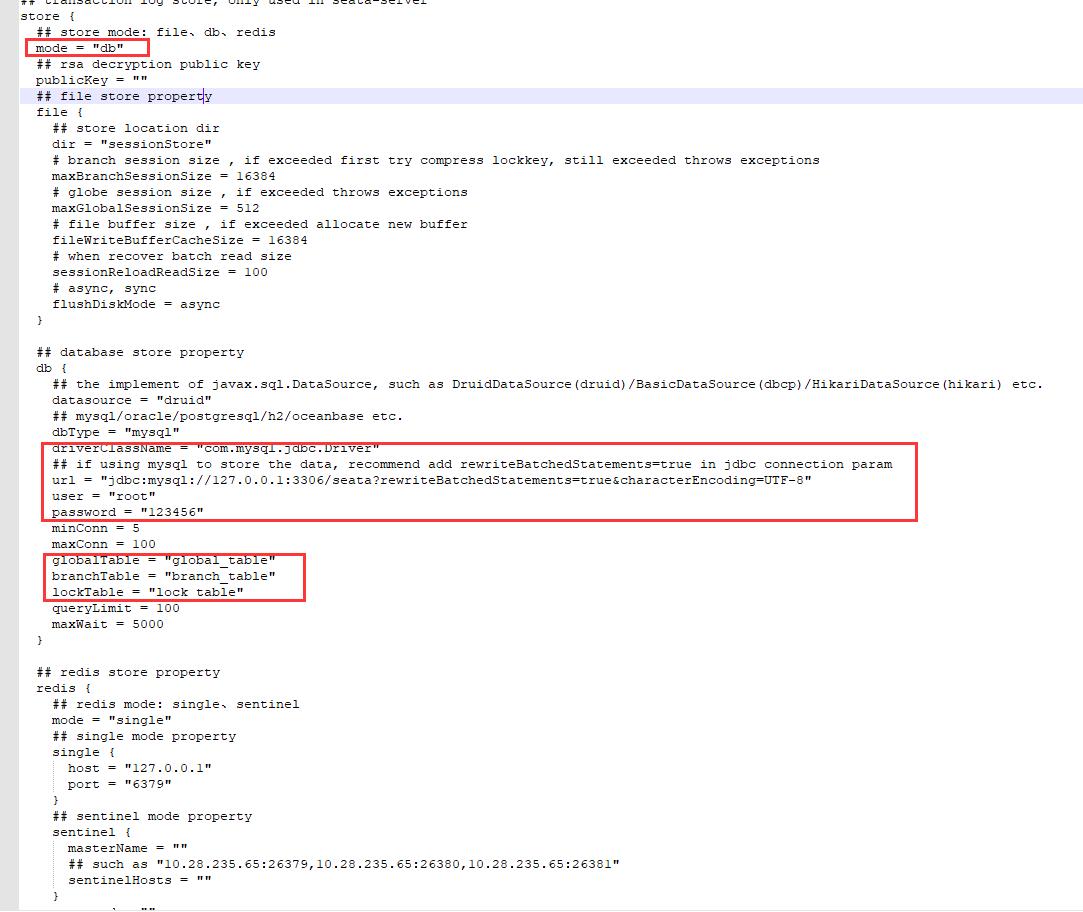
修改以上中的信息,找到对应的db配置,修改其中的jdbc连接,要注意其中涉及到三个表(global_table,branch_table,lock_table),同时 mysql5和mysql8的驱动是不一样的
mysql5:com.mysql.jdbc.Driver
mysql8:com.mysql.cj.jdbc.Driver
建表语句地址:https://github.com/seata/seata/blob/develop/script/server/db/mysql.sql
global_table: 全局事务表,每当有一个全局事务发起后,就会在该表中记录全局事务的ID
branch_table: 分支事务表,记录每一个分支事务的 ID,分支事务操作的哪个数据库等信息
lock_table: 全局锁
当上述配置好以后,重启Seata即可生效。
Seata 配置 Nacos
Seata支持注册服务到Nacos,以及支持Seata所有配置放到Nacos配置中心,在Nacos中统一维护;在
高可用模式下就需要配合Nacos来完成
首先找到 conf/registry.conf,修改registry信息
registry
# file 、nacos 、eureka、redis、zk、consul、etcd3、sofa
type = "nacos"
nacos
application = "seata-server" # 这里的配置要和客户端保持一致
serverAddr = "127.0.0.1:8848"
group = "SEATA_GROUP" # 这里的配置要和客户端保持一致
namespace = ""
cluster = "default"
username = "nacos"
password = "nacos"
config
# file、nacos 、apollo、zk、consul、etcd3
type = "nacos"
nacos
serverAddr = "127.0.0.1:8848"
namespace = ""
group = "SEATA_GROUP"
username = "nacos"
password = "nacos"
dataId = "seataServer.properties"
......
修改好后,将seata中的一些配置上传到Nacos中,因为配置项比较多,所以官方提供了一个config.txt,只下载并且修改其中某些参数后,上传到Nacos中即可。
下载地址:https://github.com/seata/seata/tree/develop/script/config-center
修改项如下:
service.vgroupMapping.mygroup=default # 事务分组
store.mode=db
store.db.driverClassName=com.mysql.cj.jdbc.Driver
store.db.url=jdbc:mysql://127.0.0.1:3306/seata?useUnicode=true&characterEncoding=UTF-8&serverTimezone=Asia/Shanghai
store.db.user=root
store.db.password=123456
修改好这个文件以后,把这个文件放到seata目录下
把这些配置都加入到Nacos配置中,要借助一个脚本来进行执行,官方已经提供好。
地址为:https://github.com/seata/seata/blob/develop/script/config-center/nacos/nacos-config.sh
新建一个nacos-config.sh文件,将脚本内容复制进去,修改congfig.txt的路径
上述文件修改好后,打开git工具,将nacos-config.sh工具拖拽到窗体中即可或者使用命令
sh nacos-config.sh -h 127.0.0.1 -p 8848 -g SEATA_GROUP -t 88b8f583-43f9-4272-bd46-78a9f89c56e8 -u nacos -w nacos
-h:nacos地址
-p:端口,默认8848
-g:seata的服务列表分组名称
-t:nacos命名空间id
-u和-w:nacos的用户名和密码
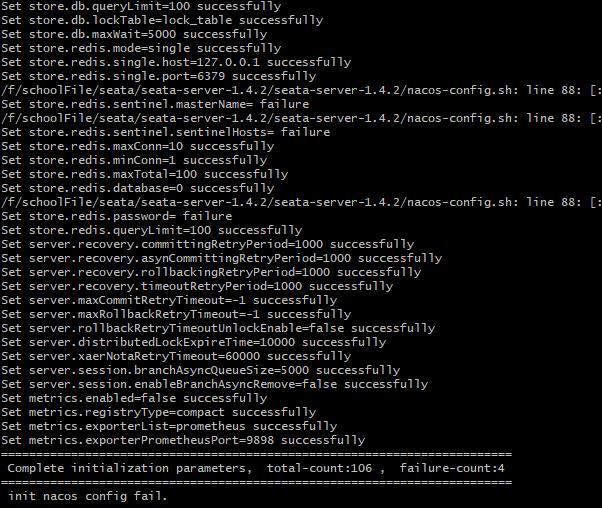
最后会有四个执行失败,是因为redis报错的关系,这个可以忽略,不影响正常使用。最后可以看到在Nacos中有很多的配置项,说明导入成功。再重新其中seata,成功监听到8091端口,表示前置工作都已经准备完成。
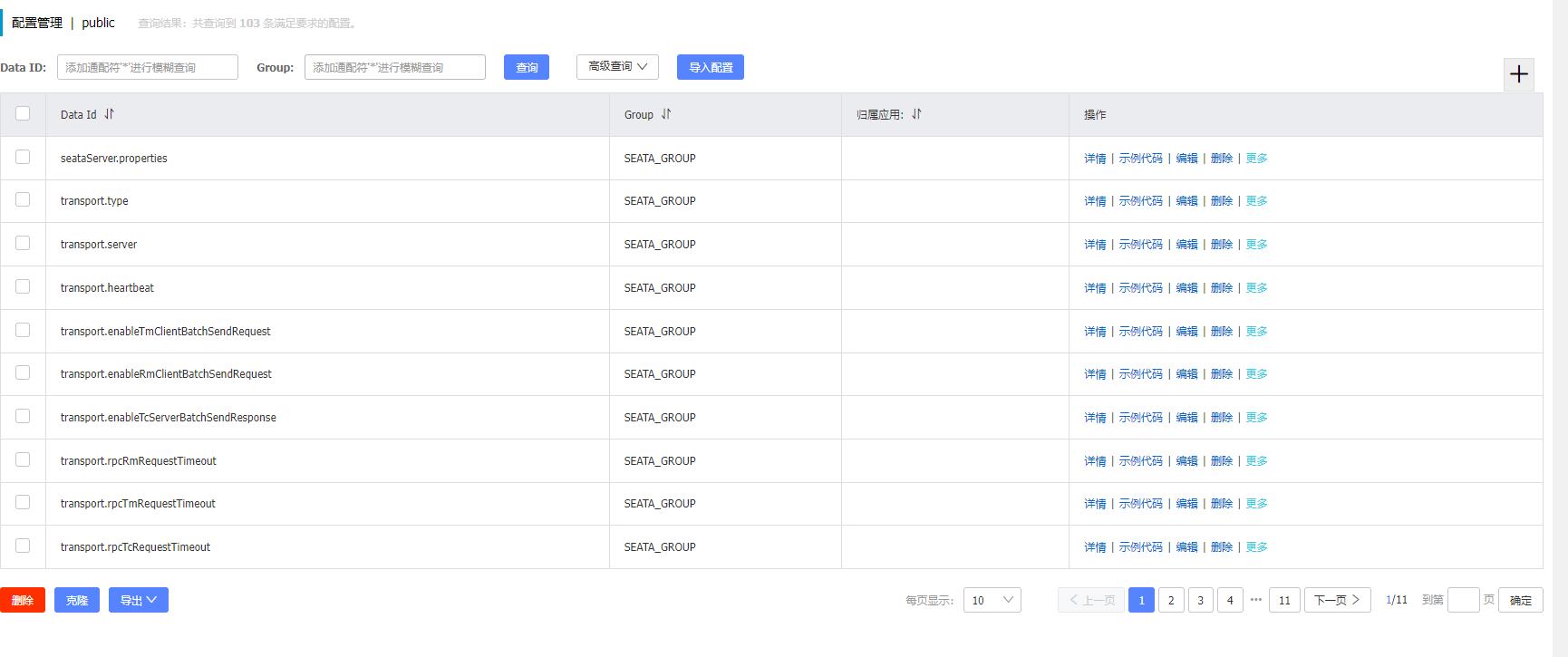
Seata的事务模式
Seata 定义了全局事务的框架,主要分为以下几步
- TM 向 TC请求 发起(Begin)、提交(Commit)、回滚(Rollback)等全局事务
- TM把代表全局事务的XID绑定到分支事务上
- RM向TC注册,把分支事务关联到XID代表的全局事务中
- RM把分支事务的执行结果上报给TC
- TC发送分支提交(Branch Commit)或分支回滚(Branch Rollback)命令给RM
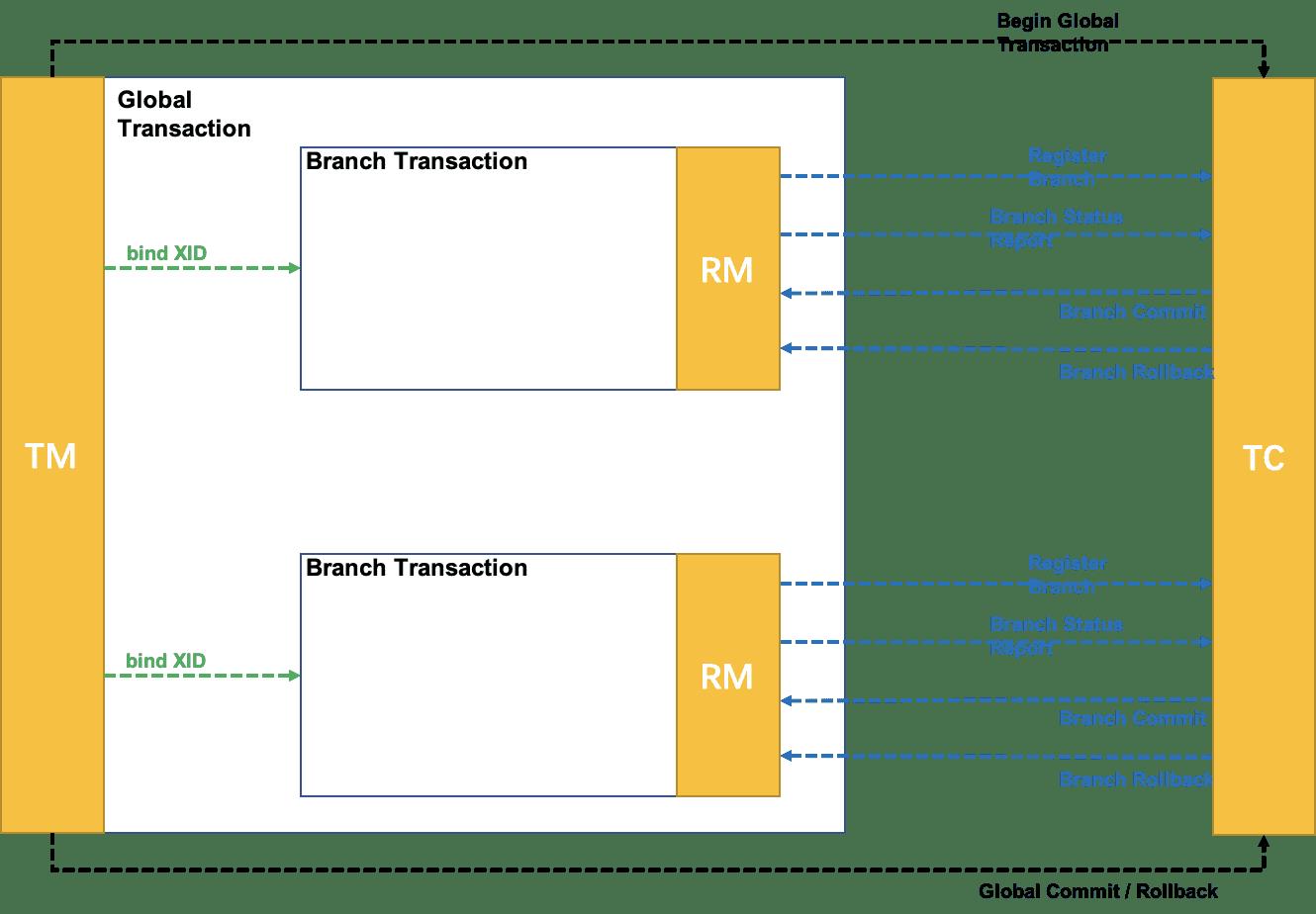
Seata 的 全局事务 处理过程,分为两个阶段:
- 执行阶段 :执行分支事务,并保证执行结果满足是可回滚的(Rollbackable) 和持久化的(Durable)。
- 完成阶段: 根据 执行阶段 结果形成的决议,应用通过 TM 发出的全局提交或回滚的请求给 TC,TC 命令 RM 驱动 分支事务 进行 Commit 或 Rollback。
Seata 的所谓事务模式是指:运行在 Seata 全局事务框架下的 分支事务 的行为模式。准确地讲,应该叫作 分支事务模式。
不同的 事务模式 区别在于 分支事务 使用不同的方式达到全局事务两个阶段的目标。即,回答以下两个问题:
- 执行阶段 :如何执行并 保证 执行结果满足是可回滚的(Rollbackable) 和持久化的(Durable)。
- 完成阶段: 收到 TC 的命令后,如何做到分支的提交或回滚?
我们以AT模式为例:
- 执行阶段:
- 可回滚:根据 SQL 解析结果,记录回滚日志
- 持久化:回滚日志和业务 SQL 在同一个本地事务中提交到数据库
- 完成阶段:
- 分支提交:异步删除回滚日志记录
- 分支回滚:依据回滚日志进行反向补偿更新
接下来就进入重头戏,Seata四大模式的介绍。
Seata-XA模式
Seata 1.2.0 版本发布了新的事务模型:XA模式,实现了对XA协议的支持。对于XA模式我们需要从三个点去解析它。
- XA模式是什么
- 为什么支持XA
- XA模式如何实现和使用
XA模式简介
首先需要知道XA模型是什么,XA 规范早在上世纪 90 年代初就被提出,用于解决分布式事务领域的问题,他也是最早的分布式事务处理方案,因为需要数据库内部也是支持XA模式的,比如MYSQL,XA模式具有强一致性的特点,因此他对数据库占用时间比较长,所以性能比较低。
XA模式属于两阶段提交。
-
第一阶段进行事务注册,将事务注册到TC中,执行SQL语句。
-
第二阶段TC判断无事务出错,通知所有事务提交,否则回滚。
-
在第一到第二阶段过程中,事务一直占有数据库锁,因此性能比较低,但是所有事务要么一起提交,要么一起回滚,所以能实现强一致性。
无论是AT模式、TCC还是SAGA,这些模式的提出,都是源于XA规范对某些业务场景无法满足
什么是XA协议
XA规范是X/OPEN组织定义的分布式事务处理(DTP,Distributed Transaction Processing)标准,XA规范描述了全局事务管理器和局部资源管理器之间的接口,XA规范的目的是允许多个资源(如数据库,应用服务器,消息队列等)在同一事务中访问,这样可以使 ACID 属性跨越应用程序而保持有效。
XA 规范 使用两阶段提交(2PC,Two-Phase Commit)来保证所有资源同时提交或回滚任何特定的事务。因为XA规范最早被提出,所以几乎所有的主流数据库都保有对XA规范的支持。
分布式事务DTP模型定义的角色如下:
- AP:即应用程序,可以理解为使用DTP分布式事务的程序,例如订单服务、库存服务
- RM:资源管理器,可以理解为事务的参与者,一般情况下是指一个数据库的实例(MySql),通过资源管理器对该数据库进行控制,资源管理器控制着分支事务
- TM:事务管理器,负责协调和管理事务,事务管理器控制着全局事务,管理实务生命周期,并协调各个RM。全局事务是指分布式事务处理环境中,需要操作多个数据库共同完成一个工作,这个工作即是一个全局事务。
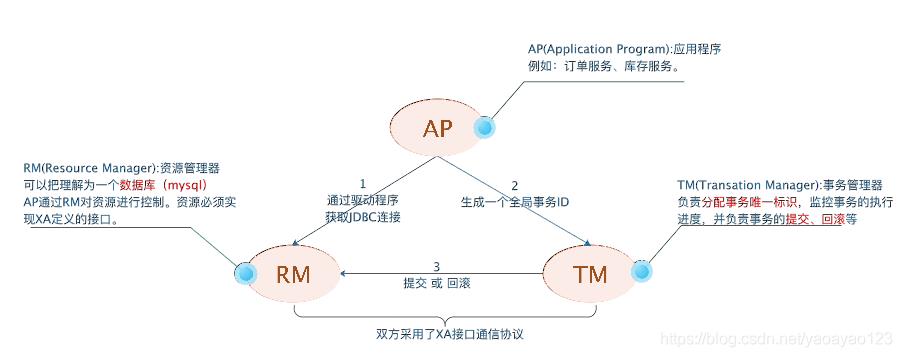
DTP模式定义TM和RM之间通讯的接口规范叫XA,简单理解为数据库提供的2PC接口协议,基于数据库的XA协议来实现的2PC又称为XA方案。
现在有应用程序(AP)持有订单库和库存库,应用程序(AP)通过TM通知订单库(RM)和库存库(RM),进行扣减库存和生成订单,这个时候RM并没有提交事务,而且锁定资源。
当TM收到执行消息,如果有一方RM执行失败,分别向其他RM也发送回滚事务,回滚完毕,释放锁资源
当TM收到执行消息,RM全部成功,向所有RM发起提交事务,提交完毕,释放锁资源。
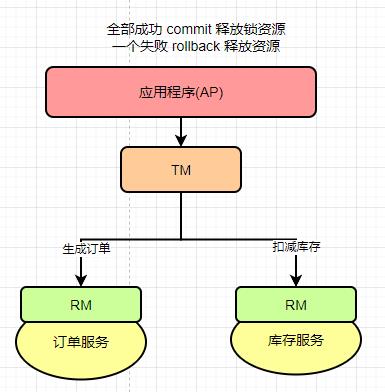
分布式通信协议XA规范,具体执行流程如下所示:
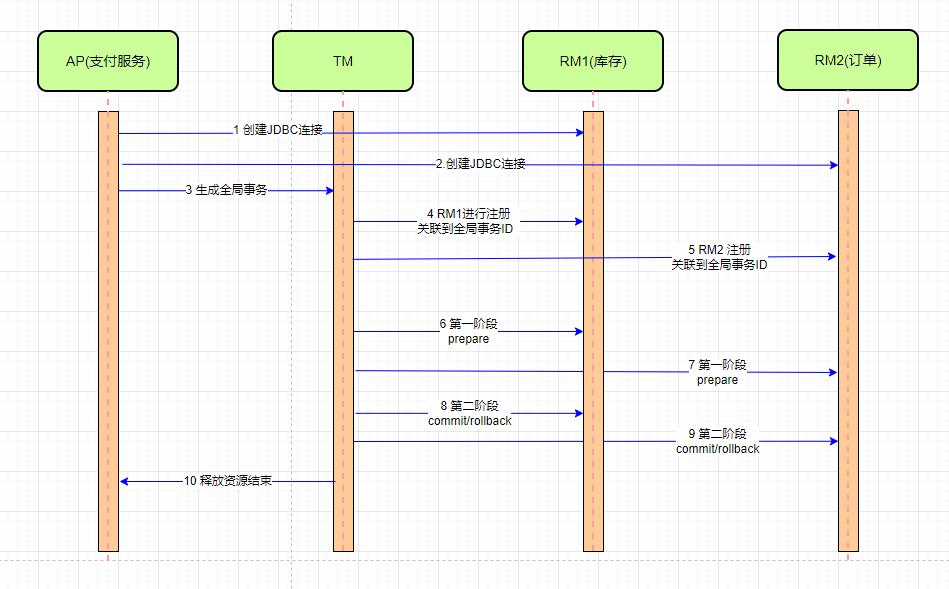
第一步:AP创建了RM1,RM2的JDBC连接。
第二步:AP通知生成全局事物ID,并把RM1,RM2注册到全局事务ID
第三步:执行二阶段协议中的第一阶段prepare
第四步:根据prepare请求,决定整体提交或回滚。
但是对于XA而言,如果一个参与全局事务的资源“失联”了,那么就意味着TM收不到分支事务结束的命令,那么它锁定的数据,将会一直被锁定,从而产生死锁,这个也是Seata需要重点解决的问题。
在Seata定义的分布式事务架构中,利用事务资源(数据局、消息)等对XA协议进行支持,用XA协议的机制来管理分支事务。
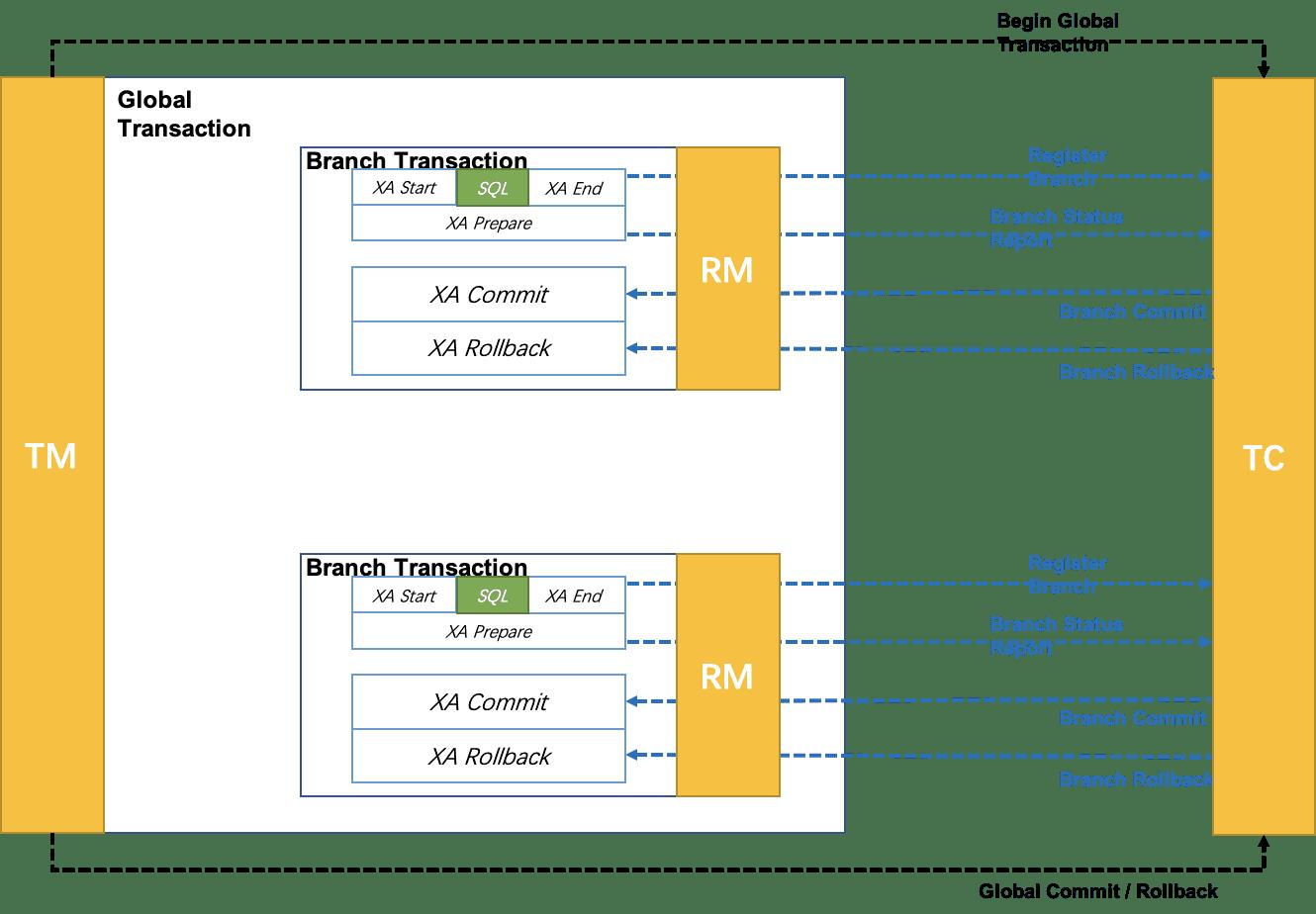
-
执行阶段:
- 可回滚:业务SQL操作在XA分支中进行,有资源管理器对XA协议的支持来保证可回滚
- 持久化:ZA分支完成以后,执行 XA prepare,同样,由资源对XA协议的支持来保证持久化
-
完成阶段:
- 分支提交:执行XA分支的commit
- 分支回滚:执行XA分支的rollback
XA存在的意义
Seata 已经支持了三大事务模式:AT\\TCC\\SAGA,这三个都是补偿型事务,补偿型事务处理你机制构建在 事务资源 之上(要么中间件层面,要么应用层),事务资源本身对于分布式的事务是无感知的,这种对于分布式事务的无感知存在有一个根本性的问题,无法做到真正的全局一致性。
例如一个库存记录,在补偿型事务处理过程中,用80扣减为60,这个时候仓库管理员查询数据结果,看到的是60,之后因为异常回滚,库存回滚到原来的80,那么这个时候库存管理员看到的60,其实就是脏数据,而这个中间状态就是补偿型事务存在的脏数据。
和补偿型事务不同,XA协议要求事务资源 本身提供对规范和协议的支持,因为事务资源感知并参与分布式事务处理过程中,所以事务资源可以保证从任意视角对数据的访问有效隔离性,满足全局数据的一致性。
XA模式的使用
官方案例:https://github.com/seata/seata-samples
项目名:seata-samples
业务开始: business-xa
库存服务: stock-xa
订单服务: order-xa
账号服务: account-xa
把这个项目案例下载下来以后,找到项目名为seata-xa的目录,里面有测试数据库的链接,如果不想用测试数据库,只需要修改官方文档中数据库配置信息即可。
首先关注的是 business-xa项目,更多的关注BusinessService.purchase()方法
@GlobalTransactional
public void purchase(String userId, String commodityCode, int orderCount, boolean rollback)
String xid = RootContext.getXID();
LOGGER.info("New Transaction Begins: " + xid);
//调用库存减库存
String result = stockFeignClient.deduct(commodityCode, orderCount);
if (!SUCCESS.equals(result))
throw new RuntimeException("库存服务调用失败,事务回滚!");
//生成订单
result = orderFeignClient.create(userId, commodityCode, orderCount);
if (!SUCCESS.equals(result))
throw new RuntimeException("订单服务调用失败,事务回滚!");
if (rollback)
throw new RuntimeException("Force rollback ... ");
其实现方法较之前差不多,我们只需要在order-xa里面(OrderService.create),添加人为错误(int i = 1/0;)
public void create(String userId, String commodityCode, Integer count)
String xid = RootContext.getXID();
LOGGER.info("create order in transaction: " + xid);
int i = 1/0;
// 定单总价 = 订购数量(count) * 商品单价(100)
int orderMoney = count * 100;
// 生成订单
jdbcTemplate.update("insert order_tbl(user_id,commodity_code,count,money) values(?,?,?,?)",
new Object[] userId, commodityCode, count, orderMoney);
// 调用账户余额扣减
String result = accountFeignClient.reduce(userId, orderMoney);
if (!SUCCESS.equals(result))
throw new RuntimeException("Failed to call Account Service. ");
里面有一个方法可以进行XA模式和AT模式的转换OrderXADataSourceConfiguration.dataSource
@Bean("dataSourceProxy")
public DataSource dataSource(DruidDataSource druidDataSource)
// DataSourceProxy for AT mode
// return new DataSourceProxy(druidDataSource);
// DataSourceProxyXA for XA mode
return new DataSourceProxyXA(druidDataSource);
我们启动这四个服务,访问地址 http://localhost:8084/purchase
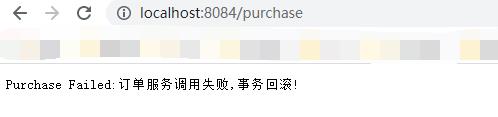
我们可以其中报错,然后再去看对应数据库的数据,没有发生更改,说明我们的XA模式生效了,当你dubug去看里面的库存服务的时候,当操作数据更改的时候,数据库里面其实也是没有记录的,因为XA是强一致性,只有当事务结束完成以后,才会更改其中的数据。
XA模式的加入,补齐了Seata在全局一致性场景下的缺口,形成了AT、TCC、Saga、XA 四大事务模式的版图,基本满足了所有场景分布式事务处理的需求。
其中XA和AT是无业务侵入的,而TCC和Saga是有一定业务侵入的。
Seata-AT模式
先来介绍一下AT模式,AT模式是一种没有侵入的分布式事务的解决方案,在AT模式下,用户只需关注自己的业务SQL,用户的业务SQL作为一阶段,Seata框架会自动生成事务进行二阶段提交和回滚操作。
两阶段提交协议的演变:
-
一阶段:业务数据和回滚日志记录在同一个本地事务中提交,释放本地锁和连接资源。
-
二阶段:
提交异步化,非常快速地完成。
回滚通过一阶段的回滚日志进行反向补偿。
AT模式主要特点
- 最终一致性
- 性能较XA高
- 只在第一阶段获取锁,在第一阶段进行提交后释放锁。
在一阶段中,Seata会拦截 业务SQL ,首先解析SQL语义,找到要操作的业务数据,在数据被操作前,保存下来记录 undo log,然后执行 业务SQL 更新数据,更新之后再次保存数据 redo log,最后生成行锁,这些操作都在本地数据库事务内完成,这样保证了一阶段的原子性。
相对一阶段,二阶段比较简单,负责整体的回滚和提交,如果之前的一阶段中有本地事务没有通过,那么就执行全局回滚,否在执行全局提交,回滚用到的就是一阶段记录的 undo Log ,通过回滚记录生成反向更新SQL并执行,以完成分支的回滚。当然事务完成后会释放所有资源和删除所有日志。
AT流程分为两阶段,主要逻辑全部在第一阶段,第二阶段主要做回滚或日志清理的工作。流程如下:
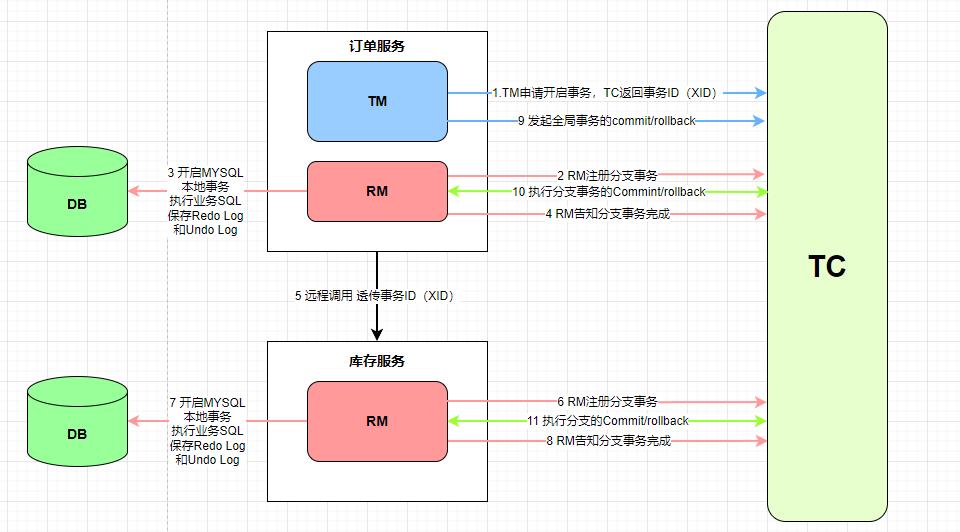
从上图中我们可以看到,订单服务中TM向TC申请开启一个全局事务,一般通过@GlobalTransactional标注开启,TC会返回一个全局事务ID(XID),订单服务在执行本地事务之前,RM会先向TC注册一个分支事务,
订单服务依次生成undo log 执行本地事务,生成redo log 提交本地事务,向TC汇报,事务执行OK。
订单服务发起远程调用,将事务ID传递给库存服务,库存服务在执行本地事务之前,先向TC注册分支事务,库存服务同样生成undo Log和redo Log,向TC汇报,事务状态成功。
如果正常全局提交,TC通知RM一步清理掉本地undo和redo日志,如果存在一个服务执行失败,那么发起回滚请求。通过undo log进行回滚。
在这里还会存在一个问题,因为每个事务从本地提交到通知回滚这段时间里面,可能这条数据已经被其他事务进行修改,如果直接用undo log进行回滚,可能会导致数据不一致的情况,
这个时候 RM会用 redo log进行验证,对比数据是否一样,从而得知数据是否有别的事务进行修改过,undo log是用于被修改前的数据,可以用来回滚,redolog是用于被修改后的数据,用于回滚校验。
如果数据没有被其他事务修改过,可以直接进行回滚,如果是脏数据,redolog校验后进行处理。
实战
了解了AT模型的基本操作,接下来就来实战操作一下,关于AT模型具体是如何实现的。首先设计两个服务 cloud-alibaba-seata-order 和 cloud-alibaba-seata-stock
表结构t_order、t_stock和undo_log三张表,项目源码和表结构,加上undo_log表,此表用于数据的回滚,文末有链接。
cloud-alibaba-seata-order核心代码如下:
controller
@RestController
public class OrderController
@Autowired
private OrderService orderService;
@GetMapping("order/create")
@GlobalTransactional //开启分布式事务
public String create()
orderService.create();
return "订单创建成功!";
OrderService
public interface OrderService
void create();
StockClient
@FeignClient(value = "seata-stock")
public interface StockClient
@GetMapping("/stock/reduce")
String reduce();
OrderServiceImpl
@Service
public class OrderServiceImpl implements OrderService
@Autowired
private OrderMapper orderMapper;
@Autowired
private StockClient stockClient;
@Override
public void create()
//扣减库存
stockClient.reduce();
System.out.println("扣减库存成功!");
//手工异常 用于回滚库存信息
int i = 1/0;
System.err.println("异常!");
//创建订单
orderMapper.createOrder();
System.out.println("创建订单成功!");
OrderMapper
@Mapper
public interface OrderMapper
@Insert("insert into t_order (order_no,order_num) value (order_no+1,1)")
void createOrder();
cloud-alibaba-seata-stock核心代码如下:
@RestController
public class StockController
@Autowired
private StockService stockService;
@GetMapping("stock/reduce")
public String reduce()
stockService.reduce();
return "库存数量已扣减:"+ new Date();
public interface StockService
void reduce();
@Service
public class StockServiceImpl implements StockService
@Autowired
StockMapper stockMapper;
@Override
public void reduce()
stockMapper.reduce();
@Mapper
@Repository
public interface StockMapper
@Update("update t_stock set order_num = order_num - 1 where order_no = 1 ")
void reduce();
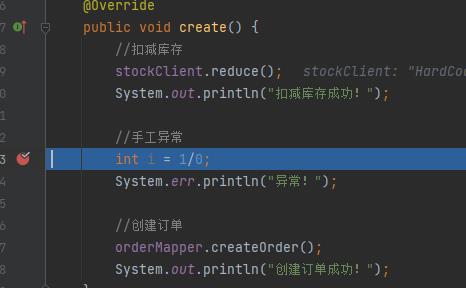
代码都比较简单,我们就不做过多的描述,基本注释也都有,,首先我们需要将order和stock服务都跑起来,在之前我们的Nacos和Seata都要启动起来,这个时候我们访问order的Rest接口,http://localhost:8087/order/create,为了验证undo_log的表是用于存储回滚数据,我们在OrderServiceImpl.create()中添加断点,用debug的方式启动
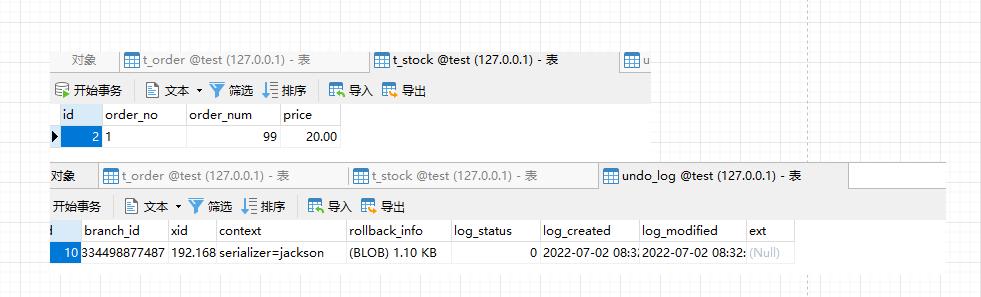
然后访问http://localhost:8087/order/create,当程序卡在这个节点的时间,我们去看undo_log和库存表,会发现,库存确实减少了,而且undo_log也出现了对应的快照记录修改当前的数据信息,这个数据就是用来回滚的数据,
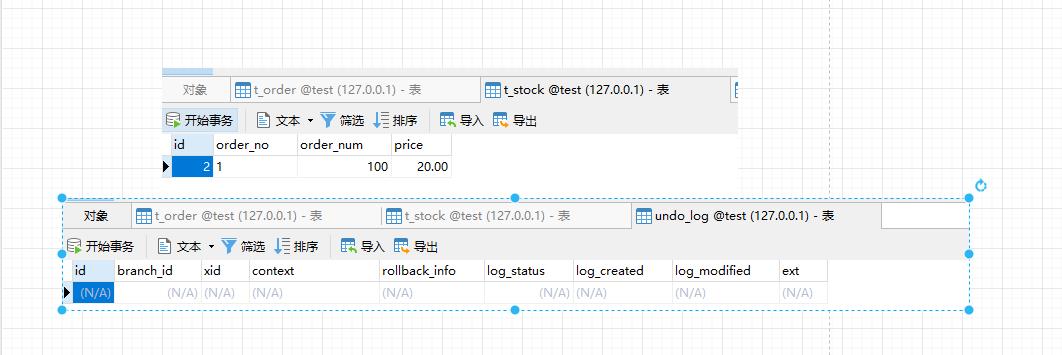
但是当我们F9通过以后,库存数量恢复,并且undo_log表的数据行也没有了,这个时候证明我们的Seata事务生效,回滚成功。
到这里我们就验证了AT事务的执行过程,相比于XA和TCC等事务模型,Seata的AT模型可以应对大多数的业务场景,并且可以做到无业务侵入,开发者无感知,对于整个事务的协调、提交或者回滚操作,都可以通过AOP完成,开发者只需要关注业务即可。
由于Seata需要在不同的服务之间传递全局唯一的事务ID,和Dubbo等框架集成会比较友好,例如Dubbo可以用过隐士传参来进行事务ID的传递,整个事务ID的传播过程对开发者也可以做到无感知。
Seata-TCC模式
具体使用案例:https://seata.io/zh-cn/blog/integrate-seata-tcc-mode-with-spring-cloud.html
什么是TCC
TCC 是分布式事务中的二阶段提交协议,它的全称为 Try-Confirm-Cancel,即资源预留(Try)、确认操作(Confirm)、取消操作(Cancel),他们的具体含义如下:
- Try:对业务资源的检查并预留;
- Confirm:对业务处理进行提交,即 commit 操作,只要 Try 成功,那么该步骤一定成功;
- Cancel:对业务处理进行取消,即回滚操作,该步骤回对 Try 预留的资源进行释放。
TCC 是一种侵入式的分布式事务解决方案,以上三个操作都需要业务系统自行实现,对业务系统有着非常大的入侵性,设计相对复杂,但优点是 TCC 完全不依赖数据库,能够实现跨数据库、跨应用资源管理,对这些不同数据访问通过侵入式的编码方式实现一个原子操作,更好地解决了在各种复杂业务场景下的分布式事务问题。
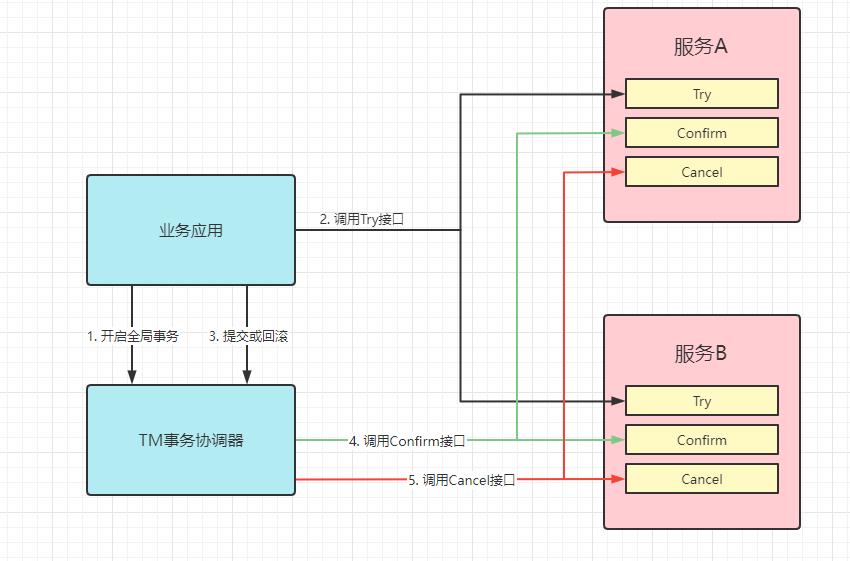
TCC和AT区别
AT 模式基于 支持本地 ACID 事务 的 关系型数据库:
- 一阶段 prepare 行为:在本地事务中,一并提交业务数据更新和相应回滚日志记录。
- 二阶段 commit 行为:马上成功结束,自动 异步批量清理回滚日志。
- 二阶段 rollback 行为:通过回滚日志,自动 生成补偿操作,完成数据回滚。
相应的,TCC 模式,不依赖于底层数据资源的事务支持:
- 一阶段 prepare 行为:调用自定义 的 prepare 逻辑。
- 二阶段 commit 行为:调用自定义 的 commit 逻辑。
- 二阶段 rollback 行为:调用自定义 的 rollback 逻辑。
所谓 TCC 模式,是指支持把 自定义 的分支事务纳入到全局事务的管理中。
特点:
- 侵入性比较强,并且需要自己实现相关事务控制逻辑
- 在整个过程基本没有锁,性能较强
Seata-Saga模式
Saga模式是SEATA提供的长事务解决方案,在Saga模式中,业务流程中每个参与者都提交本地事务,当出现某一个参与者失败则补偿前面已经成功的参与者,一阶段正向服务和二阶段补偿服务(执行处理时候出错了,给一个修复的机会)都由业务开发实现。
Saga 模式下分布式事务通常是由事件驱动的,各个参与者之间是异步执行的,Saga 模式是一种长事务解决方案。
之前我们学习的Seata分布式三种操作模型中所使用的的微服务全部可以根据开发者的需求进行修改,但是在一些特殊环境下,比如老系统,封闭的系统(无法修改,同时没有任何分布式事务引入),那么AT、XA、TCC模型将全部不能使用,为了解决这样的问题,才引用了Saga模型。
比如:事务参与者可能是其他公司的服务或者是遗留系统,无法改造,可以使用Saga模式。
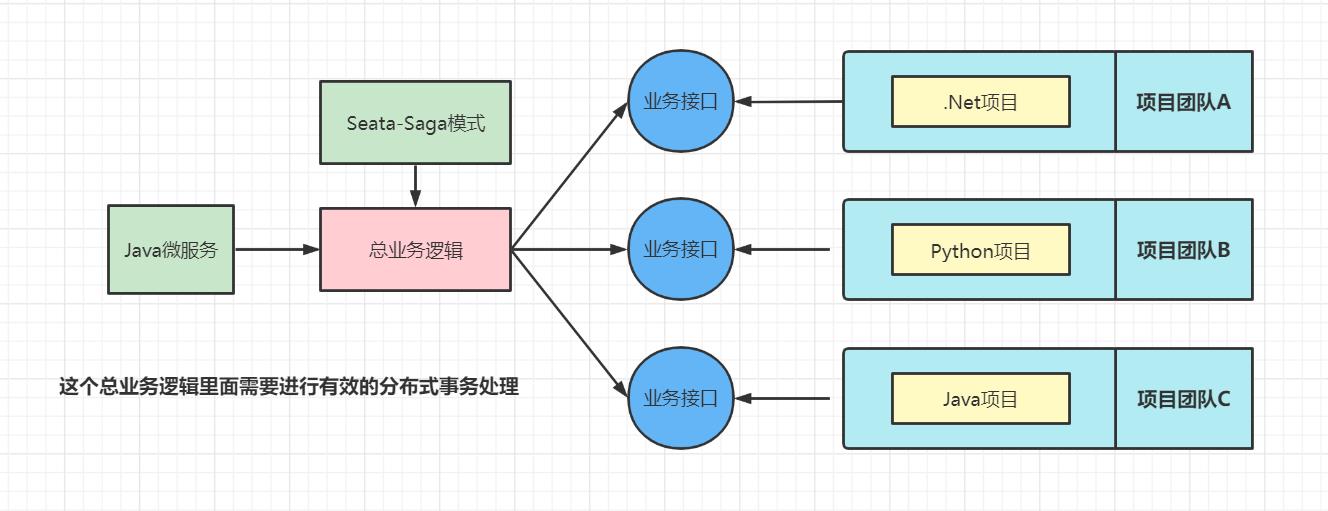
Saga模式是Seata提供的长事务解决方案,提供了异构系统的事务统一处理模型。在Saga模式中,所有的子业务都不在直接参与整体事务的处理(只负责本地事务的处理),而是全部交由了最终调用端来负责实现,而在进行总业务逻辑处理时,在某一个子业务出现问题时,则自动补偿全面已经成功的其他参与者,这样一阶段的正向服务调用和二阶段的服务补偿处理全部由总业务开发实现。
Saga状态机
目前Seata提供的Saga模式只能通过状态机引擎来实现,需要开发者手工的进行Saga业务流程绘制,并且将其转换为Json配置文件,而后在程序运行时,将依据子配置文件实现业务处理以及服务补偿处理,而要想进行Saga状态图的绘制,一般需要通过Saga状态机来实现。
基本原理:
- 通过状态图来定义服务调用的流程并生成json定义文件
- 状态图中一个节点可以调用一个服务,节点可以配置它的补偿节点
- 状态图 json 由状态机引擎驱动执行,当出现异常时状态引擎反向执行已成功节点对应的补偿节点将事务回滚
- 可以实现服务编排需求,支持单项选择、并发、子流程、参数转换、参数映射、服务执行状态判断、异常捕获等功能
Saga状态机的应用
官方文档地址:https://seata.io/zh-cn/docs/user/saga.html
Seata Safa状态机可视化图形设计器使用地址:https://github.com/seata/seata/blob/develop/saga/seata-saga-statemachine-designer/README.zh-CN.md
总结
总的来说在Seata的中AT模式基本可以满足百分之80的分布式事务的业务需求,AT模式实现的是最终一致性,所以可能存在中间状态,而XA模式实现的强一致性,所以效率较低一点,而Saga可以用来处理不同开发语言之间的分布式事务,所以关于分布式事务的四大模型,基本可以满足所有的业务场景,其中XA和AT没有业务侵入性,而Saga和TCC具有一定的业务侵入。
到这里我们的Seata分布式事务就讲完了,如果有不懂或者有疑问的小伙伴记得评论区留言。
关于资料和项目源码,公众号后台: seata ,即可获取
我是牧小农怕什么真理无穷,进一步有进一步的欢喜,大家加油!
以上是关于saga模式Seata saga模式详解的主要内容,如果未能解决你的问题,请参考以下文章