DL:受限波尔兹曼机(RBM)能量模型
Posted happy_XYY
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了DL:受限波尔兹曼机(RBM)能量模型相关的知识,希望对你有一定的参考价值。
受限波尔兹曼机(RBM)能量模型
在学习Hinton的stack autoencoder算法(论文 Reducing the Dimensionality of Data with Neural Networks)之前需要了解什么是RBM,现在就我学习的情况,查找的资料(大部分来自博客、论文),简单介绍一下RBM。(当然,这里面还有同组实验的同学提供的资料,借用一下。。。)
目录
RBM学习算法——Gibbs采样、变分方法、对比散度、模拟退火
RBM评估
1、能量模型定义
能量模型是个什么样的东西呢?直观上的理解就是,把一个表面粗糙又不太圆的小球,放到一个表面也比较粗糙的碗里,就随便往里面一扔,看看小球停在碗 的哪个地方。一般来说停在碗底的可能性比较大,停在靠近碗底的其他地方也可能,甚至运气好还会停在碗口附近(这个碗是比较浅的一个碗);能量模型把小球停 在哪个地方定义为一种状态,每种状态都对应着一个能量,这个能量由能量函数来定义,小球处在某种状态的概率(如停在碗底的概率跟停在碗口的概率当然不一 样)可以通过这种状态下小球具有的能量来定义(换个说法,如小球停在了碗口附近,这是一种状态,这个状态对应着一个能量E,而发生“小球停在碗口附近”这 种状态的概率p,可以用E来表示,表示成p=f(E),其中f是能量函数),这就是我认为的能量模型。
这样,就有了能量函数,概率之类的东西。
波尔兹曼网络是一种随机网络。描述一个随机网络,总结起来主要有两点。
第一,概率分布函数。由于网络节点的取值状态是随机的,从贝叶斯网的观点来看,要描述整个网络,需要用三种概率分布来描述系统。即联合概率分布,边 缘概率分布和条件概率分布。要搞清楚这三种不同的概率分布,是理解随机网络的关键,这里向大家推荐的书籍是张连文所著的《贝叶斯网引论》。很多文献上说受限波尔兹曼是一个无向图,从贝叶斯网的观点看,受限波尔兹曼网络也可以看作一个双向的有向图,即从输入层节点可以计算隐层节点取某一种状态值的概率,反之亦然。
第二,能量函数。随机神经网络是根植于统计力学的。受统计力学中能量泛函的启发,引入了能量函数。能量函数是描述整个系统状态的一种测度。系统越有序或者概率分布越集中,系统的能量越小。反之,系统越无序或者概率分布越趋于均匀分布,则系统的能量越大。能量函数的最小值,对应于系统的最稳定状态。
2、 能量模型作用
为什么要弄这个能量模型呢?原因有几个。
第一、RBM网络是一种无监督学习的方法,无监督学习的目的是最大可能的拟合输入数据,所以学习RBM网络的目的是让RBM网络最大可能地拟合输入数据。
第二、对于一组输入数据来说,现在还不知道它符合那个分布,那是非常难学的。例如,知道它符合高斯分布,那就可以写出似然函数,然后求解,就能求出这个是一个什么样个高斯分布;但是要是不知道它符合一个什么分布,那可是连似然函数都没法写的,问题都没有,根本就无从下手。
好在天无绝人之路——统计力学的结论表明,任何概率分布都可以转变成基于能量的模型,而且很多的分布都可以利用能量模型的特有的性质和学习过程,有些甚至从能量模型中找到了通用的学习方法。有这样一个好东西,当然要用了。
第三、在马尔科夫随机场(MRF)中能量模型主要扮演着两个作用:一、全局解的度量(目标函数);二、能量最小时的解(各种变量对应的配置)为目标解。也就是能量模型能为无监督学习方法提供两个东西:a)目标函数;b)目标解。
换句话说,就是——使用能量模型使得学习一个数据的分布变得容易可行了。
能否把最优解嵌入到能量函数中至关重要,决定着我们具体问题求解的好坏。统计模式识别主要工作之一就是捕获变量之间的相关性,同样能量模型也要捕获 变量之间的相关性,变量之间的相关程度决定了能量的高低。把变量的相关关系用图表示出来,并引入概率测度方式就构成了概率图模型的能量模型。
RBM作为一种概率图模型,引入了概率就可以使用采样技术求解,在CD(contrastive divergence)算法中采样部分扮演着模拟求解梯度的角色。
能量模型需要一个定义能量函数,RBM的能量函数的定义如下
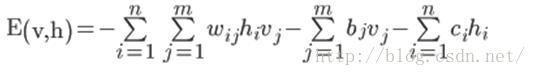
这个能量函数的意思就是,每个可视节点和隐藏节点之间的连接结构都有一个能量,通俗来说就是可视节点的每一组取值和隐藏节点的每一组取值都有一个能 量,如果可视节点的一组取值(也就是一个训练样本的值)为(1,0,1,0,1,0),隐藏节点的一组取值(也就是这个训练样本编码后的值)为 (1,0,1),然后分别代入上面的公式,就能得到这个连接结构之间的能量。
能量函数的意义是有一个解释的,叫做专家乘积系统(POE,product of expert),这个理论也是hinton发明的,他把每个隐藏节点看做一个“专家”,每个“专家”都能对可视节点的状态分布产生影响,可能单个“专家” 对可视节点的状态分布不够强,但是所有的“专家”的观察结果连乘起来就够强了。具体我也看不太懂,各位有兴趣看hinton的论文吧,中文的也有,叫《专家乘积系统的原理及应用,孙征,李宁》。
3、从能量模型到概率
为了引入概率,需要定义概率分布。根据能量模型,有了能量函数,就可以定义一个可视节点和隐藏节点的联合概率 也就是一个可视节点的一组取值(一个状态)和一个隐藏节点的一组取值(一个状态)发生的概率p(v,h)是由能量函数来定义的。
也就是一个可视节点的一组取值(一个状态)和一个隐藏节点的一组取值(一个状态)发生的概率p(v,h)是由能量函数来定义的。
这个概率不是随便定义的,而是有统计热力学的解释的——在统计热力学上,当系统和它周围的环境处于热平衡时,一个基本的结果是状态i发生的概率如下面的公式
其中Ei表示系统在状态i时的能量,T为开尔文绝对温度,b为Boltzmann常数,Z为与状态无关的常数。
我们这里的变成了E(v,h),因为(v,h)也是一个状态,其他的参数T和由于跟求解无关,就都设置为1了,Z就是我们上面联合概率分布的分母,这个分母是为了让我们的概率的和为1,这样才能保证p(v,h)是一个概率。
现在我们得到了一个概率,其实也得到了一个分布,其实这个分布还有一个好听点的名字,可以叫做Gibbs分布,当然不是一个标准的Gibbs分布,而是一个特殊的Gibbs分布,这个分布是有一组参数的,就是能量函数的那几个参数w,b,c。
有了这个联合概率,就可以得到一些条件概率,是用积分去掉一些不想要的量得到的。

(2) 从概率到极大似然
上面得到了一个样本和其对应编码的联合概率,也就是得到了RBM网络的Gibbs分布的概率密度函数,引入能量模型的目的是为了方便求解的。
现在回到求解的目标——让RBM网络的表示Gibbs分布最大可能的拟合输入数据。
其实求解的目标也可以认为是让RBM网络表示的Gibbs分布与输入样本的分布尽可能地接近。
现在看看“最大可能的拟合输入数据”这怎么定义。
假设Ω表示样本空间,q是输入样本的分布,即q(x)表示训练样本x的概率, q其实就是要拟合的那个样本表示分布的概率;再假设p是RBM网络表示的Gibbs分布的边缘分布(只跟可视节点有关,隐藏节点是通过积分去掉了,可以理 解为可视节点的各个状态的分布),输入样本的集合是S,那现在就可以定义样本表示的分布和RBM网络表示的边缘分布的KL距离
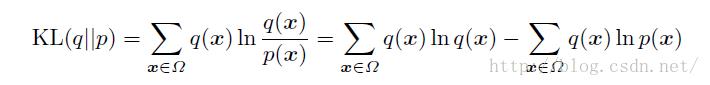
如果输入样本表示的分布与RBM表示的Gibbs分布完全符合,这个KL距离就是0,否则就是一个大于0的数。
第一项其实就是输入样本的熵(熵的定义),输入样本定了熵就定了;第二项没法直接求,但是如果用蒙特卡罗抽样(后面有章节会介绍),让抽中的样本是输入样本(输入样本肯定符合分布q(x)),第二项可以用 来估计,其中的l表示训练样本个数。由于KL的值肯定是不小于0,所以第一项肯定不小于第二项,让第二项取得最大值,就能让KL距离最小;最后,还可以发现,最大化
来估计,其中的l表示训练样本个数。由于KL的值肯定是不小于0,所以第一项肯定不小于第二项,让第二项取得最大值,就能让KL距离最小;最后,还可以发现,最大化 ,相当于最大化
,相当于最大化 ,而这就是极大似然估计。
,而这就是极大似然估计。
结论就是求解输入样本的极大似然,就能让RBM网络表示的Gibbs分布和样本本身表示的分布最接近。
这就是为什么RBM问题最终可以转化为极大似然来求解。
既然要用极大似然来求解,这个当然是有意义的——当RBM网络训练完成后,如果让这个RBM网络随机发生若干次状态(当然一个状态是由(v,h)组成的),这若干次状态中,可视节点部分(就是v)出现训练样本的概率要最大。
这样就保证了,在反编码(从隐藏节点到可视节点的编码过程)过程中,能使训练样本出现的概率最大,也就是使得反编码的误差尽最大的可能最小。
例如一个样本(1,0,1,0,1)编码到(0,1,1),那么,(0,1,1)从隐藏节点反编码到可视节点的时候也要大概率地编码到(1,0,1,0,1)。
到这,能量模型到极大似然的关系说清楚了,,可能有点不太对,大家看到有什么不对的提一下,我把它改了。
之前想过用似然函数最大的时候,RBM网络的能量最小这种思路去解释,结果看了很多的资料,都实在没有办法把那两个极值联系起来。这个冤枉路走了好久,希望大家在学习的时候多注意,尽量避免走这个路。
下面就说怎么求解了。求解的意思就是求RBM网络里面的几个参数w,b,c的值,这个就是解,而似然函数(对数似然函数)是目标函数。最优化问题里面的最优解和目标函数的关系大家务必先弄清楚。
4、求解极大似然
既然是求解极大似然,就要对似然函数求最大值,求解的过程就是对参数求导,然后用梯度上升法不断地把目标函数提升,最终到达停机条件(在这里看不懂的同学就去看参考文献中的《从极大似然到EM》),
设参数为(注意是参数是一组参数),则似然函数可以写为
为了省事L(v│θ)=p(v|θ)写成p(v)了,然后就可以对它的对数进行求导了(因为直接求一个连乘的导数太复杂,所以变成对数来求)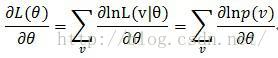
可以看到,是对每个p(v)求导后再加和,然后就有了下面的推导了。

到了这一步的时候,我们又可以发现问题了。我们可以看到的是,对每一个样本,第二个等号后面的两项其实都像是在求一个期望,第一项求的是 这个函数在概率p(h|v)下的期望,第二项求的是
这个函数在概率p(h|v)下的期望,第二项求的是 这个函数在概率p(v,h)下面的期望。
这个函数在概率p(v,h)下面的期望。
还有论文是这么解释的,上面的公式,对w求偏导,还可以再进一步转化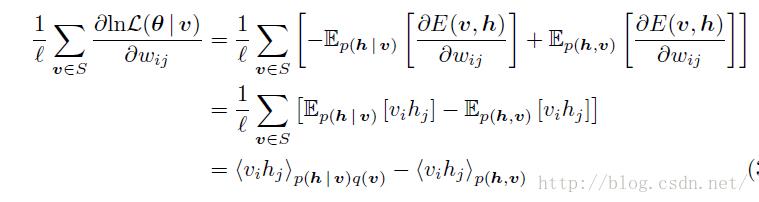
注意:从第二个“=”号到第三个“=”号的时候,第二个“=”号的方括号里面的第一项是把蒙特卡罗抽样的用法反过来了,从抽样回到了积分,所以得到了一个 期望;第二项就是因为对每个训练样本,第二项的值算出来都一样,所以累加以后的结果除以l,相当于没有变化,还是那个期望,只是表达的形式换了。
这样的话,这个梯度还可以这么理解,第一项等于输入样本数据的自由能量函数偏导在样本本身的那个分布下的期望值 (q(v,h)=p(h|v)q(v),q表示输入样本和他们对应的隐藏增状态表示的分布),而第二项是自由能量函数的偏导在RBM网络表示的Gibbs 分布下的期望值。
第一项是可以求的,因为训练样本有了,也就是使用蒙特卡罗估算期望的时候需要的样本已经抽好了,只要求个均值就可以了。
第二项也是可以求的,但是要对v和h的组合的所有可能的取值都遍历一趟,这就可能没法算了;想偷懒的话,悲剧就在于,现在是没有RBM网络表示的Gibbs分布下的样本的(当然后面会介绍这些怎么抽)。
为了进行下面的讨论,把这个梯度再进一步化简,看看能得到什么。根据能量函数的公式,是有三个参数的w,b和c,就分别对这三个参数求导

到了这一步,来分析一下,从上面的联合概率那一堆,我们可以得到下面的
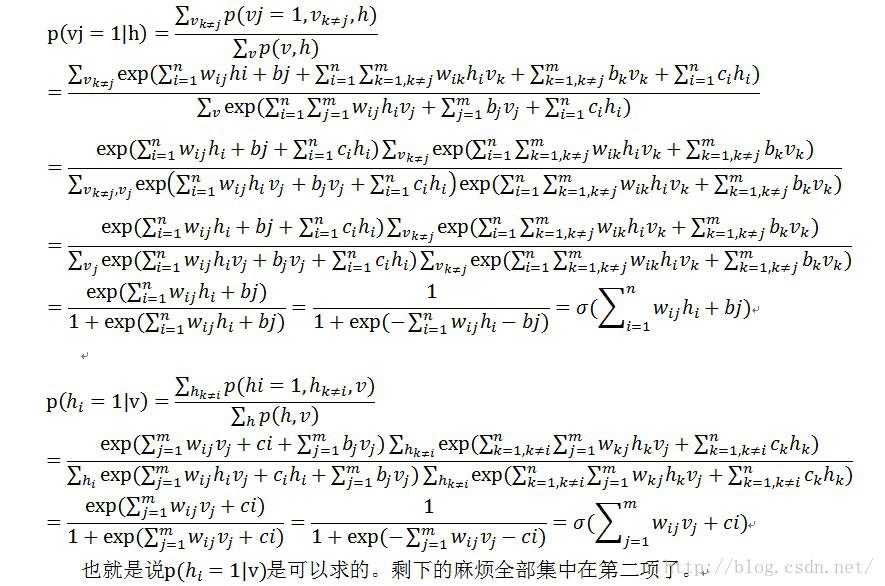
要求第二项,就要遍历所有可能的v的值,然后根据公式去计算几个梯度的值,那样够麻烦的了,还好蒙特卡罗给出了一个偷懒的方法,见后面的章。
只要抽取一堆样本,这些样本符合RBM网络表示的Gibbs分布的(也就是符合参数确定的Gibbs分布p(x)的),就可以把上面的三个偏导数估算出来。
对于上面的情况,是这么处理的,对每个训练样本x,都用某种抽样方法抽取一个它对应的符合RBM网络表示的Gibbs分布的样本(对应的意思就是符 合参数确定的Gibbs分布p(x)的),假如叫y;那么,对于整个的训练集x1,x2,…xl来说,就得到了一组符合RBM网络表示的Gibbs分 布的样本y1,y2,…,yl,然后拿这组样本去估算第二项,那么梯度就可以用下面的公式来近似了
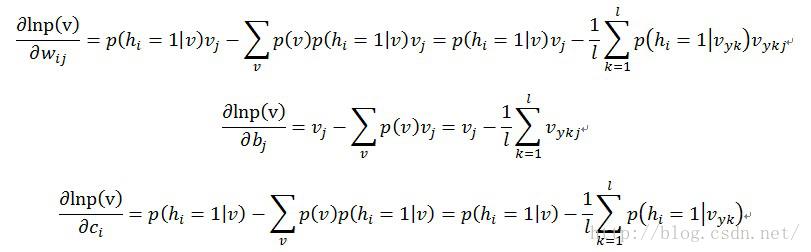
其中xk表示第k个训练样本,yk表示第k个训练样本对应的RBM网络表示的Gibbs分布(不妨将这个分布称为R)的样本(yk是根据分布R抽取的样 本,而且这个样本是从xk出发,用Gibbs抽样抽取出来的,也就是说yk服从分布R,可以用来估算第二项,同时yk跟xk有关),Vyk表示可视节点取 值为yk的时候的状态,那么Vykj就表示yk的第j个特征的取值。
这样,梯度出来了,这个极大似然问题可以解了,最终经过若干论迭代,就能得到那几个参数w,b,c的解。
式子中的v是指x1,x2,…xl中的一个样本,因为 ,对样本进行累加时,第一项是对所有样本进行累加,而第二项都是一样的(是一个积分的结果,与被积变量无关,是一个标量),所以累加后1/l就没有了,只有对l项y进行累加,到了下面CD-k算法的时候,每次只对一个x和一个y进行处理,最外层对x做L次循环后得到的累加结果是一样的.
,对样本进行累加时,第一项是对所有样本进行累加,而第二项都是一样的(是一个积分的结果,与被积变量无关,是一个标量),所以累加后1/l就没有了,只有对l项y进行累加,到了下面CD-k算法的时候,每次只对一个x和一个y进行处理,最外层对x做L次循环后得到的累加结果是一样的.
上面提到的“某种抽样方法”,现在一般就用Gibbs抽样,然后hinton教授还根据这个弄出了一个CD-k算法,就是用来解决RBM的抽样的。下面一章就介绍这个吧。
参考文献
能量函数和概率分布 http://blog.csdn.net/itplus/article/details/19168989
对数似然函数 http://blog.csdn.net/itplus/article/details/19169027
 开发者涨薪指南
开发者涨薪指南
 48位大咖的思考法则、工作方式、逻辑体系
48位大咖的思考法则、工作方式、逻辑体系
以上是关于DL:受限波尔兹曼机(RBM)能量模型的主要内容,如果未能解决你的问题,请参考以下文章