图解 Google V8 # 11:堆和栈:函数调用是如何影响到内存布局的?
Posted 凯小默
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了图解 Google V8 # 11:堆和栈:函数调用是如何影响到内存布局的?相关的知识,希望对你有一定的参考价值。
说明
图解 Google V8 学习笔记
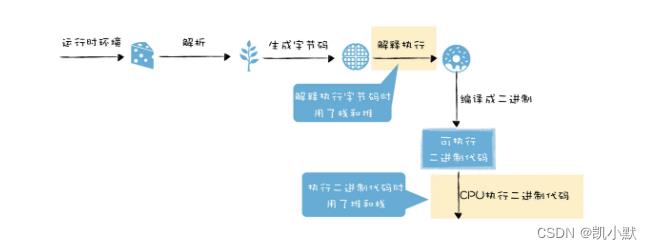
在编译流水线中的位置
先看三个例子:
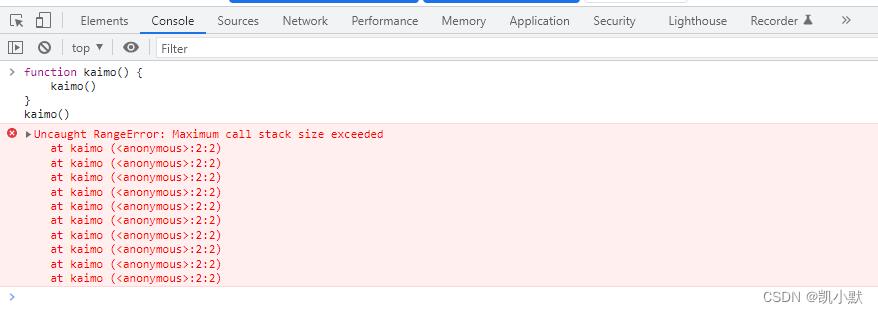
1、在同一个任务中重复调用嵌套的 kaimo 函数。
function kaimo()
kaimo()
kaimo()
V8 会报栈溢出的错误:
2、使用 setTimeout 让 kaimo 函数在不同的任务中执行。
function kaimo()
console.log(1)
setTimeout(kaimo, 0)
kaimo()
V8 能够正确执行。

3、在同一个任务中执行 kaimo 函数,但是却不是嵌套执行。
function kaimo()
console.log(1)
return Promise.resolve().then(kaimo)
kaimo()
没有栈溢出的错误,页面却出现了卡死的情况。
这相当于在当前这一轮任务里不停地创建微任务,执行,创建,执行,创建……虽然不会爆栈,但也无法去执行下一个任务,主线程被卡在这里了,所以页面会卡死。

有同学说在执行5-10分钟后,Chrome会报错:paused before potential out-of-memory crash,然后当前宏任务继续处于被挂起状态。大家可以试一下,我试了好几次都是浏览器崩溃了,就很离谱。
V8 执行这三种不同代码时,它们的内存布局是不同的,而不同的内存布局又会影响到代码的执行逻辑。
为什么使用栈结构来管理函数调用?
通常函数有两个主要的特性:
- 函数可以被调用
- 函数具有作用域机制:作用域机制通常表现在函数执行时,会在内存中分配函数内部的变量、上下文等数据,在函数执行完成之后,这些内部数据会被销毁掉。
例子:
int getZ()
return 4;
int add(int x, int y)
int z = getZ();
return x + y + z;
int main()
int x = 5;
int y = 6;
int ret = add(x, y);
上面这段 C 代码执行流程:
- 当 main 函数调用 add 函数时,需要将代码执行控制权交给 add 函数;
- 然后 add 函数又调用了 getZ 函数,于是又将代码控制权转交给 getZ 函数;
- 接下来 getZ 函数执行完成,需要将控制权返回给 add 函数;
- 同样当 add 函数执行结束之后,需要将控制权返还给 main 函数;
- 然后 main 函数继续向下执行。
函数调用示意图如下:

嵌套调用时函数的生命周期:
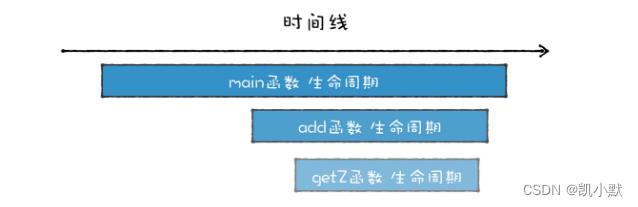
函数调用者的生命周期总是长于被调用者(后进),并且被调用者的生命周期总是先于调用者的生命周期结束 (先出)。
函数资源分配流程:
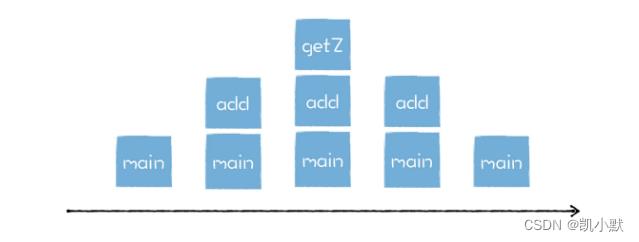
因为函数是有作用域机制的,站在函数资源分配和回收角度来看,被调用函数的资源分配总是晚于调用函数 (后进),而函数资源的释放则总是先于调用函数 (先出)。
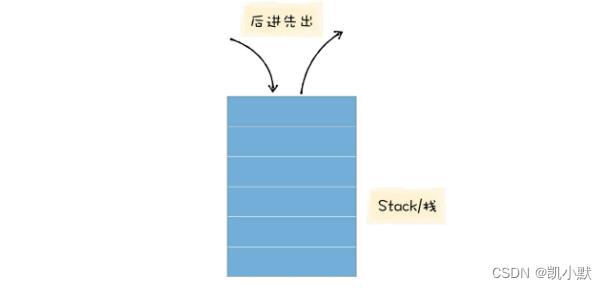
函数的生命周期和函数的资源分配情况,它们都符合后进先出 (LIFO) 的策略,而栈结构正好满足这种后进先出 (LIFO) 的需求,所以选择栈来管理函数调用关系是一种很自然的选择。
栈如何管理函数调用?
栈的变化情况是怎样的?
当执行一个函数的时候,栈怎么变化?
例子:
int main()
int x = 5;
int y = 6;
x = 100;
int z = x + y;
return z;
函数在执行过程中,其内部的临时变量会按照执行顺序被压入到栈中。

当一个函数调用另外一个函数时,栈的变化情况是怎样的?
int add(num1,num2)
int x = num1;
int y = num2;
int ret = x + y;
return ret;
int main()
int x = 5;
int y = 6;
x = 100;
int z = add(x,y);
return z;
快调用 add 函数时:
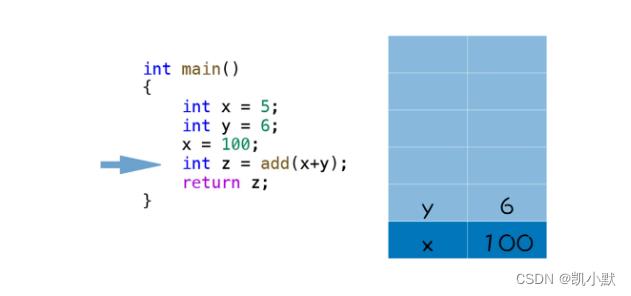
调用 add 函数的过程:
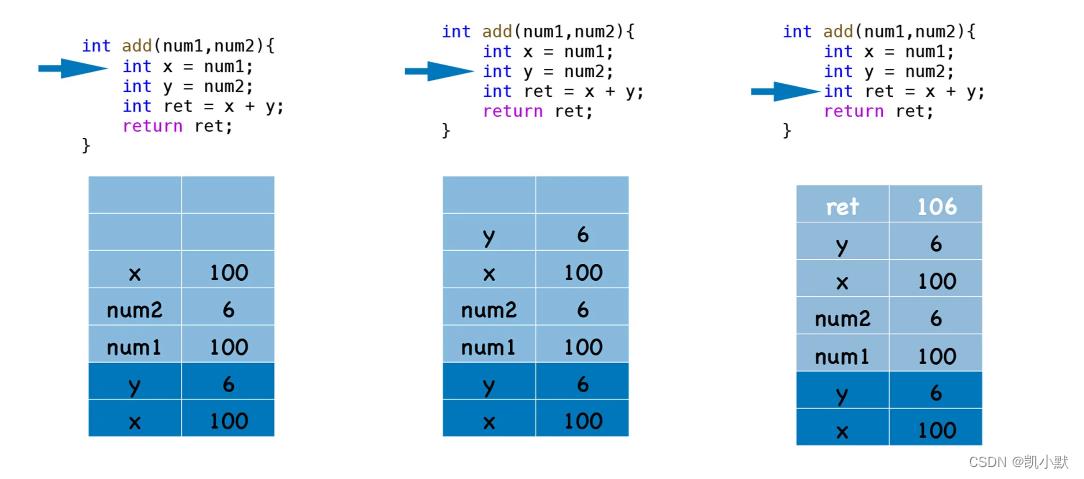
当 add 函数执行完成之后,需要将执行代码的控制权转交给 main 函数,这意味着需要将栈的状态恢复到 main 函数上次执行时的状态,我们把这个过程叫恢复现场。
怎么恢复 main 函数的执行现场呢?
栈顶指针是在栈操作过程中,有一个专门的栈指针(习惯上称它为TOP),指出栈顶元素所在的位置。
在寄存器中保存一个永远指向当前栈顶的指针即可。
栈顶指针的作用就是告诉你应该往哪个位置添加新元素,这个指针通常存放在
esp 寄存器中。如果你想往栈中添加一个元素,那么你需要先根据esp 寄存器找到当前栈顶的位置,然后在栈顶上方添加新元素,新元素添加之后,还需要将新元素的地址更新到esp 寄存器中。
所以当 add 函数执行结束时,只需要将栈顶指针向下移动,就可以恢复 main 函数的执行现场了。
add 函数即将执行结束的状态:
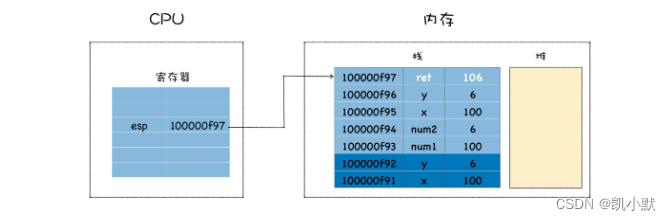
恢复 mian 函数执行现场:
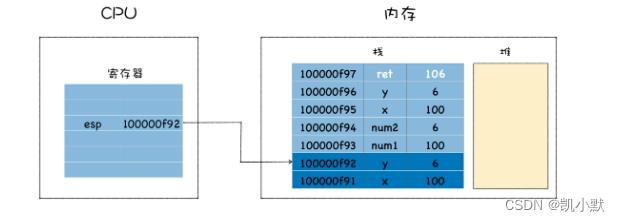
CPU 是怎么知道要移动到这个地址呢?
CPU 的解决方法是增加了另外一个
ebp 寄存器,用来保存当前函数的起始位置,我们把一个函数的起始位置也称为栈帧指针,ebp 寄存器中保存的就是当前函数的栈帧指针。
ebp 寄存器保存了栈帧指针:
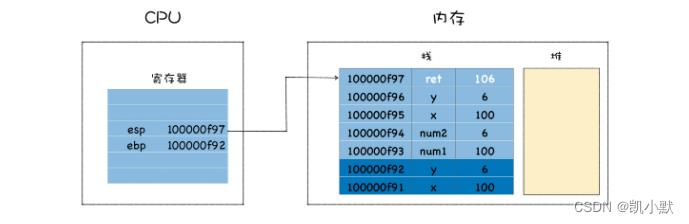
在 main 函数调用 add 函数的时候:
- main 函数的栈顶指针就变成了 add 函数的栈帧指针
- 需要将 main 函数的栈顶指针保存到 ebp 中
当 add 函数执行结束之后:只需要取出 main 函数的栈顶指针写到 esp 中即可
- 需要销毁 add 函数的栈帧
- 并恢复 main 函数的栈帧
这就相当于将栈顶指针移动到 main 函数的区域。
如何恢复 main 函数的栈帧指针呢?
每个栈帧对应着一个未运行完的函数,栈帧中保存了该函数的返回地址和局部变量。栈帧也叫过程活动记录。
通常的方法是在 main 函数中调用 add 函数时,CPU 会将当前 main 函数的栈帧指针保存在栈中:
- 首先取出 ebp 中的指针,写入 esp 中
- 然后从栈中取出之前保留的 main 的栈帧地址,将其写入 ebp 中
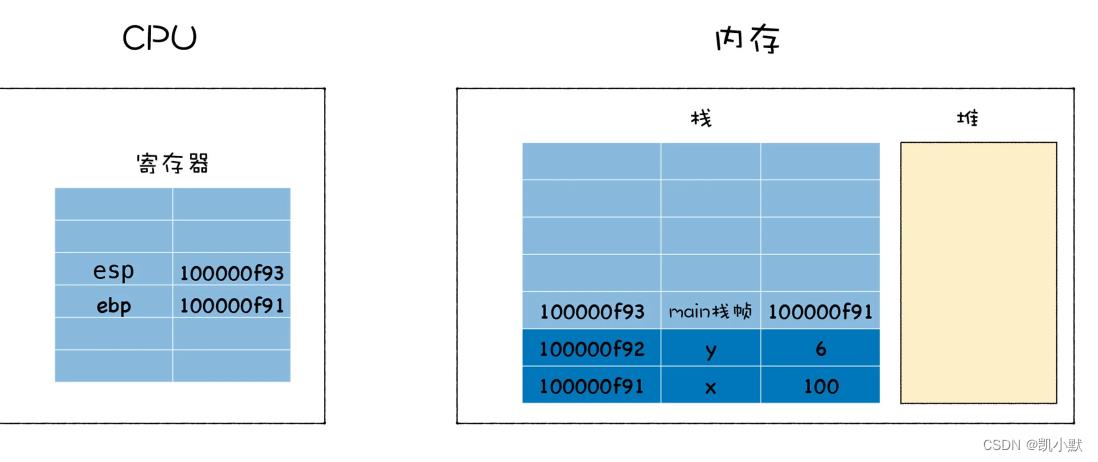
这样 ebp 和 esp 就都恢复了,可以继续执行 main 函数了。
堆
和栈空间不同,存放在堆空间中的数据是不要求连续存放的,从堆上分配内存块没有固定模式的,你可以在任何时候分配和释放它。
下面代码中有 new int、new Point 这种语句,当执行这些语句时,表示要在堆中分配一块数据,然后返回指针,通常返回的指针会被保存到栈中。
struct Point
int x;
int y;
;
int main()
int x = 5;
int y = 6;
int *z = new int;
*z = 20;
Point p;
p.x = 100;
p.y = 200;
Point *pp = new Point();
pp->y = 400;
pp->x = 500;
delete z;
delete pp;
return 0;
当 main 函数快执行结束时,堆和栈的状态:
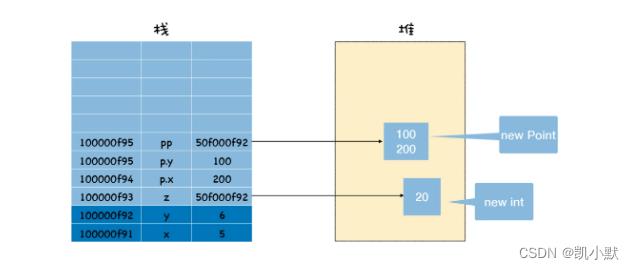
上图中 p 和 pp 都是地址,它们保存在栈中,指向了在堆中分配的空间。
- C/C++ 这种手动管理内存的语言,如果没有手动销毁堆中的数据,那么就会造成内存泄漏
- javascript,Java 使用了自动垃圾回收策略,可以实现垃圾自动回收,但也会带来一些性能问题
参考资料
以上是关于图解 Google V8 # 11:堆和栈:函数调用是如何影响到内存布局的?的主要内容,如果未能解决你的问题,请参考以下文章