推荐系统笔记:lightGCN算法原理与背景
Posted 甘霖那
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了推荐系统笔记:lightGCN算法原理与背景相关的知识,希望对你有一定的参考价值。
背景
lightGCN是将图卷积神经网络应用于推荐系统当中,是对神经图协同过滤(NGCF)算法的优化和改进。lightGCN相比于其对照算法提升了16%左右,在介绍lightGCN之前应该知道NGCF的基本原理。
基本原理
首先,协同过滤的基本假设是相似的用户会对物品展现出相似的偏好,自从全面进入深度学习领域之后,一般主要是先在隐空间中学习关于user和item的embedding,然后重建两者的交互即interaction modeling,如MF做内积,NCF模拟高阶交互等。但是他们并没有把user和item的交互信息本身编码进 embedding 中,这就是NGCF想解决的点:显式建模User-Item 之间的高阶连接性来提升 embedding。
NGCF
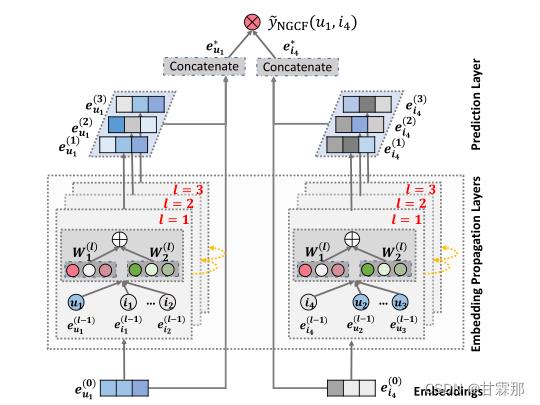
NGCF的模型如上图所示,它的传播过程分为message construction(消息构造)和message aggregation(消息聚合)两部分。按照图中的结构图可以进行分以下三层:
· Embeddings:对user和item的嵌入向量,用id来嵌入就可以了
· Embedding Propagation Layers:挖掘高阶连通性关系来捕捉交互以细化Embedding的多个嵌入传播层
· Prediction Layer:用更新之后带有交互信息的 user 和 item Embedding来进行预测
1. Embedding
即编码层,构建一个参数矩阵作为嵌入查找表:

2. Embedding Propagation Layers(核心部分)
信息构造:
对于连接的用户项对(u,i),论文将从i到u的消息定义为:
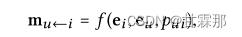
其中 是消息嵌入(即要传播的信息)。
是消息嵌入(即要传播的信息)。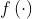 是消息编码函数,它以嵌入
是消息编码函数,它以嵌入 和
和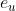 为输入,并使用系数
为输入,并使用系数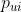 来控制边缘(u,i)上每次传播的衰减因子。具体的函数如下所示:
来控制边缘(u,i)上每次传播的衰减因子。具体的函数如下所示:
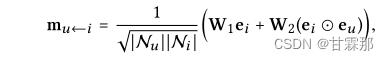
表示物品到用户的消息构造。其中W1和W2是用于提取传播有用信息的可训练权重矩阵,嵌入和表示用户和物品的embedding,用和内积相乘来获得邻域的的信息,然后再加上,即所谓的自信息(这在lightGCN中被证明是不必要的冗余)。最后的N是u和i的度用来归一化系数,可以看做是折扣系数,在lightGCN论文中被证明是不可缺少的。
信息聚合:
一阶聚合:整合从每个item的聚合信息,然后再加上用户自身节点的信息,最后再激活一下

高阶聚合:一阶往往不能满足要求,因此需要堆叠多层。
通过一阶连通性建模增强表示,我们可以堆叠更多嵌入传播层来探索高阶连通性信息。这种高阶连接性对于编码协作信号以估计用户和项目之间的相关性分数至关重要。
通过堆叠l嵌入传播层,用户(和项目)能够接收从其l跳邻居传播的消息。如图所示,用户u的表示递归公式化为:
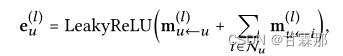
自信息和用户与物品的交互信息表示为:

该公式的理解为,每次传播时,聚合邻接结点信息时,邻接结点都是上次聚合更新后的结点信息(一定不是初始的embedding,结点信息每次更新都会发生变化的)
高阶的消息堆叠如图所示:

首先就是将i4、i5、i2三个物品的信息聚合到u2中,(其实在这个聚合过程进行的同时其他结点也都进行了相应的聚合邻接结点信息,例如在此时u1也聚合了i1、i2、i3的信息),然后用u1和u2继续传播聚合给i2(此时i2结点在此时已经包含图三所有结点的信息),然后再将i1、i2、i3信息给u1。至此物品i4经过三层转手操作,通过路径上的结点一步步传递到u1手中。
为了便利与计算,其矩阵形式表示如下:
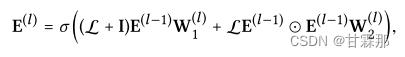
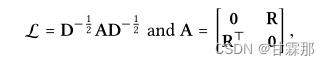
A是邻接矩阵,L就是归一化后的邻接矩阵,将得到的所有阶的embedding信息拼接起来起来作为最终的节点表示,再内积得到预测结果:
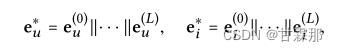
至于为什么矩阵表示是这样作者并未介绍,也无从考证,后续可以进一步研究。
损失函数如图:

是比较常规的成对计算损失的损失函数。
3. Prediction Layer
预测部份较为简单,直接将用户的最终编码和物品表示的最终编码相乘得到用户评分矩阵类似的排序。即如图:

这里编码的到的方式和lightGCN的方式有所不同,以后会介绍到。
代码实现参考以下链接:github:https://github.com/huangtinglin/NGCF-PyTorch
LightGCN
和NGCF的不同点在于:lightGCN将GCN中最常见的两种设计:特征转换和非线性激活弃用,因为他们对模型并无实质性作用,另外LightGCN认为自信息的作用不大,也没有使用自信息链接。
论文链接:
- LightGCN: https://arxiv.org/abs/2002.02126
- BPR: https://arxiv.org/ftp/arxiv/papers/1205/1205.2618.pdf
整体模型示意图如图所示:
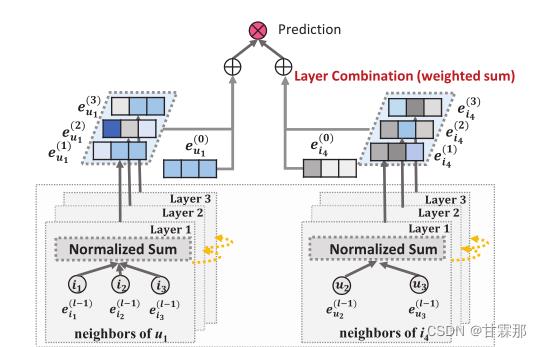
GCN的基本思想是通过平滑图上的特征来学习节点的表示。为此,它迭代执行图卷积,即聚合邻居的特征作为目标节点的新表示。这种邻域聚合同样可以抽象为:
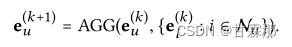
可见公式中没有再使用自信息链接,作者通过消融实验证明了自信息的多余。
迭代公式如下所示,通过迭代和最后加权求和的方式求取最后对用户和物品的编码并预测:

也就是说在堆叠多层图卷积神经网络时,最后的编码是每一层的编码都会参与,按照权重进行求和的,作者提出可以通过注意力机制进行学习该权重,但事实上使用平均权重的效果就会很好,利用注意力机制不一定能取得更好的效果还会加重模型负担。于是加权公式如下:
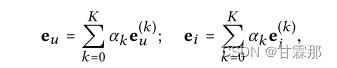
预测部分和NGCF方式基本一样,直接将用户的最终编码和物品表示的最终编码相乘得到用户评分矩阵类似的排序。

矩阵表示也和NGCF的方式基本相同:
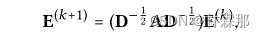


其中D是(M+N)×(M+N)对角矩阵,其中每个条目Dii表示邻接矩阵a(也称为度矩阵)的第i行向量中非零条目的数量。
模型在损失函数上做了一定处理,使用了BPR loss损失函数,有关这个损失函数的部分请参考我的另一篇博客:推荐系统笔记(一):BPR Loss个性化推荐_甘霖那的博客-CSDN博客
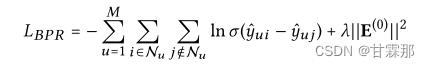
BPR loss对排序方法进行了改进,可以改进模型的收敛速度和效果。
总结
LightGCN通过消融实验证明了非线性激活和特征转换这些GCN的结构在推荐系统中并不适用,这很可能是因为推荐系统中每个图节点仅仅使用了用户或者物品的ID进行模型搭建和训练,因此节点信息并不像图片信息那么丰富,也就不需要那么复杂的结构了。消融实验结果如图 :
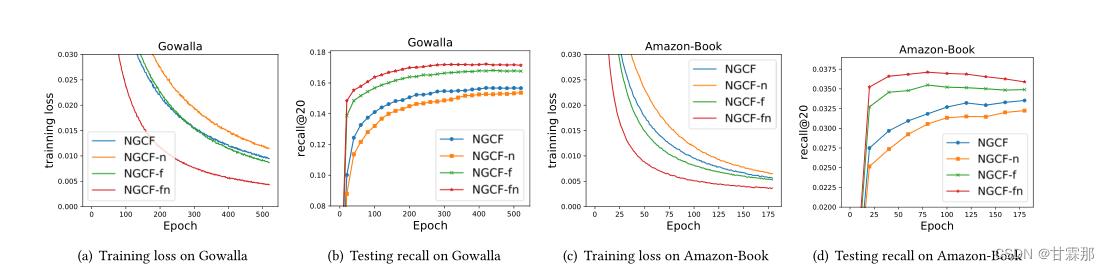
分别对比了以下几种消融实验的结果:
•NGCF-f,删除特征转换矩阵W1和W2。
•NGCF-n,去除非线性激活函数σ。
•NGCF fn,去除特征转换矩阵和非线性激活函数。
结果显示NGCF fn的结果要比NGCF的结果更加优秀,提升16%,可以认为该两种结构确实不是必须的。
论文实现的pytorch代码链接如下:
GitHub - gusye1234/LightGCN-PyTorch: The PyTorch implementation of LightGCN
tensorflow的实现代码如下:
下一篇笔记将介绍复现论文的步骤和过程!
参考链接:图卷积网络在推荐系统中的应用NGCF(Neural Graph Collaborative Filtering)配套pytorch的代码解释_只想做个咸鱼的博客-CSDN博客_ngcf代码
基于spark mlllib的推荐系统学习笔记
背景
大势所趋,几乎所有的项目都在向机器学习、深度学习靠拢:怎么在行为分析类项目中植入机器学习相关算法?目前,有两个可行的场景:智能路径与在线推荐。
- 智能路径
输入转化目标,按照转化率的高低输出一组用户的转化路径。这个功能针对大型、多业务流程的系统。 - 在线推荐
根据用户自身的属性以及点击等行为数据,在会话结束后,向用户推荐相关的产品。相对而言,在线推荐更加符合我们的业务场景
技术驱动业务,真的很费劲,再加上项目中的一些沟通问题,让人心累。一个人都跑完了马拉松,还有什么做不到:你强大的身体与心理素质足以KO一个在线推荐系统。本文旨在梳理在线推荐相关知识点,以及如何在当前项目中落地在线推荐的一些思路。
问题
在线推荐怎么落地?对于一个没有做过推荐系统的小白来说,还是老老实实一步一步学吧
分析
一、推荐系统概述
推荐系统的核心是推荐引擎,目前大致有三类推荐引擎:
A. 基于人口的统计学推荐 Demographic-based Rec
最简单的一种推荐算法,简单的根据系统用户的基本属性发现用户的相关度,然后将相似用户喜欢的其他物品推荐给当前用户:
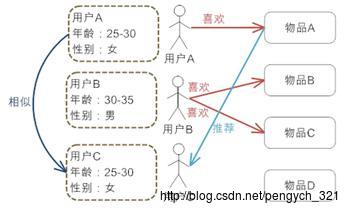
如上图,系统发现用户A与C 比较相似,就会把A喜欢的物品推荐给C
B. 基于内容的推荐 Content-based Rec
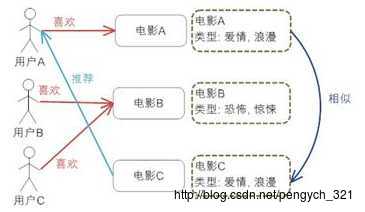
首先按照电影的特征比如类型、导演与主演名称、时长等建模,实现分类。如上图,由于电影A与电影C 属于同一个类型的电影,对于喜欢看电影A的用户,我们就可以给他推荐类似的电影C。
上面介绍的两类推荐引擎只能对客观上相似的人/物进行互推,没法对主观上相似的人/物进行推荐-下面介绍的CFR可以做到。
C. 基于协同过滤的推荐 Collaborative Filtering-based Rec
协同过滤是在分析大量的用户行为数据基础上,推荐算法中最经典最常用的,可以为分三类:
基于用户的协同过滤(User-based CFR)
基本思路是相似的人对相似的物品感兴趣。基于用户的协同过滤与基于人口统计学的推荐机制都是计算用户的相似度,但计算方式不同:前者是基于用户的历史行为数据偏好计算用户的相似度,而后者只考虑用户本身的特征:

如上图,用户A与B相似度高,这个时候可以将用户A,B购买过的产品互推,比如把用户A购买过的旅游分期,推荐给用户B。也可以把用户B购买过的超薪贷推荐给用户A。
基于项目的协同过滤(Item-based CFR)
根据用户
根据所有用户对物品或者信息的评价,发现物品和物品之间的相似度,然后根据用户的历史偏好信息将类似的物品推荐给该用户:
用户A、B在购买物品A的时候,都购买了C,可以认为物品A,C比较相似。因此给用户C推荐物品C。
- 基于模型的协同过滤(Model-based CFR)
基于模型的协同过滤推荐就是基于样本的用户喜好信息,训练一个模型,然后根据实时的用户喜好的信息进行预测推荐。常用模型有三种:
1)最近邻模型:基于距离的协同过滤算法
2)矩阵分解模型:基于矩阵分解的模型
3)图模型:社会网络图模型(Graph)
由于spark mllib中的协同过滤当前支持的是矩阵分解模型,即通过某种学习算法(常用的有ALS与 SVD)学习得到Latent Factor,因此有必要掌握LF是什么,详见 nick lee 关于Latent Factor的介绍
二、基于spark mllib的Model-base CF 推荐算法实现
这里选用python,基于jupyter notebook做实验,代码来自spark 2.2官网自带:
from pyspark.sql import SparkSession
from pyspark.ml.evaluation import RegressionEvaluator
from pyspark.ml.recommendation import ALS
from pyspark.sql import Row
spark = SparkSession \\
.builder \\
.appName("pyspark-als cf") \\
.getOrCreate()
print(spark) 输出 :
<pyspark.sql.session.SparkSession object at 0x7fcf282bfed0>lines = spark.read.text("file:///opt/cloudera/spark2/data/mllib/als/sample_movielens_ratings.txt").rdd
parts = lines.map(lambda row: row.value.split("::"))
ratingsRDD = parts.map(lambda p: Row(userId=int(p[0]), movieId=int(p[1]),rating=float(p[2]), timestamp=long(p[3])))
ratings = spark.createDataFrame(ratingsRDD)
(training, test) = ratings.randomSplit([0.8, 0.2]) print(test.count())// 测试用输出: 300
als = ALS(maxIter=5, regParam=0.01, userCol="userId", itemCol="movieId", ratingCol="rating",
coldStartStrategy="drop")
model = als.fit(training)
predictions = model.transform(test)
evaluator = RegressionEvaluator(metricName="rmse", labelCol="rating",
predictionCol="prediction")
rmse = evaluator.evaluate(predictions)
print("Root-mean-square error = " + str(rmse)) 输出: Root-mean-square error = 1.67116362396
# Generate top 10 movie recommendations for each user
userRecs = model.recommendForAllUsers(10)
# Generate top 10 user recommendations for each movie
movieRecs = model.recommendForAllItems(10)
# $example off$
userRecs.show()
+------+--------------------+
|userId| recommendations|
+------+--------------------+
| 28|[[92,5.185784], [...|
| 27|[[62,3.536236], [...|
| 16|[[51,4.992403], [...|
| 3|[[83,5.032247], [...|
| 20|[[22,4.7084303], ...|
| 5|[[55,4.538338], [...|
| 15|[[46,4.8945246], ...|
| 17|[[32,6.925795], [...|
| 9|[[53,5.3842697], ...|
| 23|[[55,5.188475], [...|
| 7|[[25,4.9242287], ...|
| 21|[[29,4.9428506], ...|
| 14|[[63,5.0648594], ...|
| 0|[[62,4.9426017], ...|
| 18|[[83,5.0963383], ...|
| 26|[[51,7.0873837], ...|
| 12|[[27,5.009531], [...|
| 22|[[75,5.0503945], ...|
| 1|[[75,5.2247057], ...|
| 13|[[29,3.2354996], ...|
+------+--------------------+
only showing top 20 rows
movieRecs.show()
+-------+--------------------+
|movieId| recommendations|
+-------+--------------------+
| 31|[[12,3.7782545], ...|
| 85|[[16,4.7374864], ...|
| 65|[[23,4.781863], [...|
| 53|[[9,5.3842697], [...|
| 78|[[26,1.7019612], ...|
| 81|[[28,4.965597], [...|
| 28|[[1,3.0670986], [...|
| 27|[[12,5.009531], [...|
| 44|[[18,3.7394714], ...|
| 91|[[22,3.9710066], ...|
| 93|[[2,4.952039], [2...|
| 52|[[8,5.04642], [14...|
| 16|[[12,3.936932], [...|
| 3|[[14,2.9027457], ...|
| 20|[[17,4.8047595], ...|
| 96|[[24,4.8344407], ...|
| 5|[[16,3.139203], [...|
| 41|[[4,3.8788776], [...|
| 43|[[8,4.0396466], [...|
| 15|[[12,1.9187665], ...|
+-------+--------------------+
only showing top 20 rows简单看一下,有5个参数:
maxIter=5, regParam=0.01, userCol="userId", itemCol="movieId", ratingCol="rating",
coldStartStrategy="drop"这里有几个问题 :
1) maxIter、regParam以及rating参数的值怎么确定,怎么自动更新?
2) rmse 值在哪个范围内模型的效果算是可接受的?
3) rating 这个特征向量值怎么获取(喜好评价规则怎么建立)?
三、Model-Base CF 在项目中的应用
参 考: github Movie-Rec-Project-by Spark&Flask
项目解读:github 核心代码解读
on-line move rec system
四、在线推荐@魔镜的实施方案预想
折腾了这么久,现实是目前对C的产品只有薪资贷、超薪贷、毕分期与旅游贷4种,因此可以考虑分两步:
1)伪在线推荐
实时读取 kafka 中的行为数据,然后调用前期做的精准营销规则引擎,判断用户是否符合某种产品的使用情况,将符合条件的产品,在用户会话结束时,以邮件的形式,发送营销信息。
2)在线推荐
待金融产品丰富后再进行,具体实现,参考三中的项目。
参考
【1】行者小猪
【2】推荐系统的常用算法原理和实现
【3】Collaborative Filtering Spark 官网
【4】nick lee 关于Latent Factor的解答
以上是关于推荐系统笔记:lightGCN算法原理与背景的主要内容,如果未能解决你的问题,请参考以下文章