Python毕业设计 大数据招聘网站爬取与数据分析可视化 - flask
Posted kooerr
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python毕业设计 大数据招聘网站爬取与数据分析可视化 - flask相关的知识,希望对你有一定的参考价值。
文章目录
0 前言
🔥 这两年开始毕业设计和毕业答辩的要求和难度不断提升,传统的毕设题目缺少创新和亮点,往往达不到毕业答辩的要求,这两年不断有学弟学妹告诉学长自己做的项目系统达不到老师的要求。
为了大家能够顺利以及最少的精力通过毕设,学长分享优质毕业设计项目,今天要分享的是
🚩 招聘网站爬取与大数据分析可视化
🥇学长这里给一个题目综合评分(每项满分5分)
- 难度系数:3分
- 工作量:3分
- 创新点:3分
🧿 选题指导, 项目分享:
https://gitee.com/yaa-dc/warehouse-1/blob/master/python/README.md
1 课题背景
本项目利用 python 网络爬虫抓取常见招聘网站信息,完成数据清洗和结构化,存储到数据库中,搭建web系统对招聘信息的薪资、待遇等影响因素进行统计分析并可视化展示。
2 实现效果
首页

岗位地图

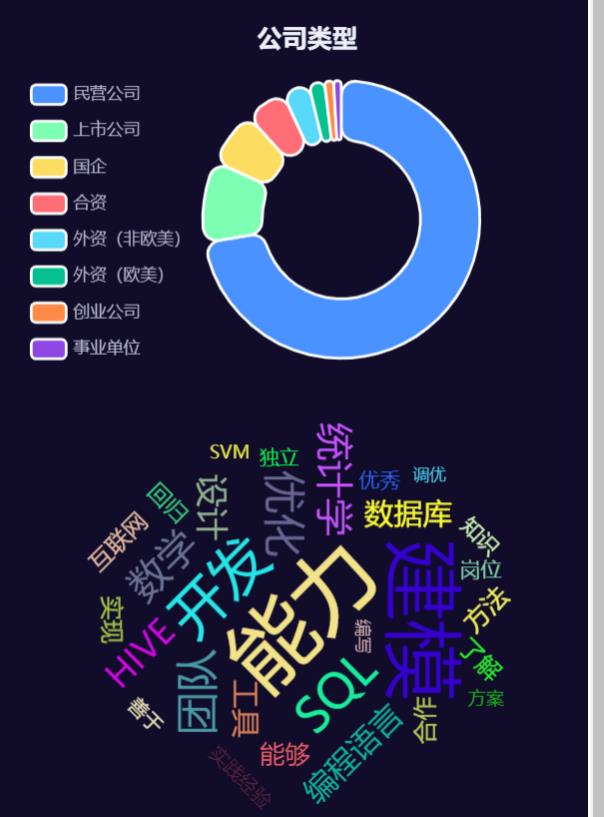
类型、词云
3 Flask框架
简介
Flask是一个基于Werkzeug和Jinja2的轻量级Web应用程序框架。与其他同类型框架相比,Flask的灵活性、轻便性和安全性更高,而且容易上手,它可以与MVC模式很好地结合进行开发。Flask也有强大的定制性,开发者可以依据实际需要增加相应的功能,在实现丰富的功能和扩展的同时能够保证核心功能的简单。Flask丰富的插件库能够让用户实现网站定制的个性化,从而开发出功能强大的网站。
本项目在Flask开发后端时,前端请求会遇到跨域的问题,解决该问题有修改数据类型为jsonp,采用GET方法,或者在Flask端加上响应头等方式,在此使用安装Flask-CORS库的方式解决跨域问题。此外需要安装请求库axios。
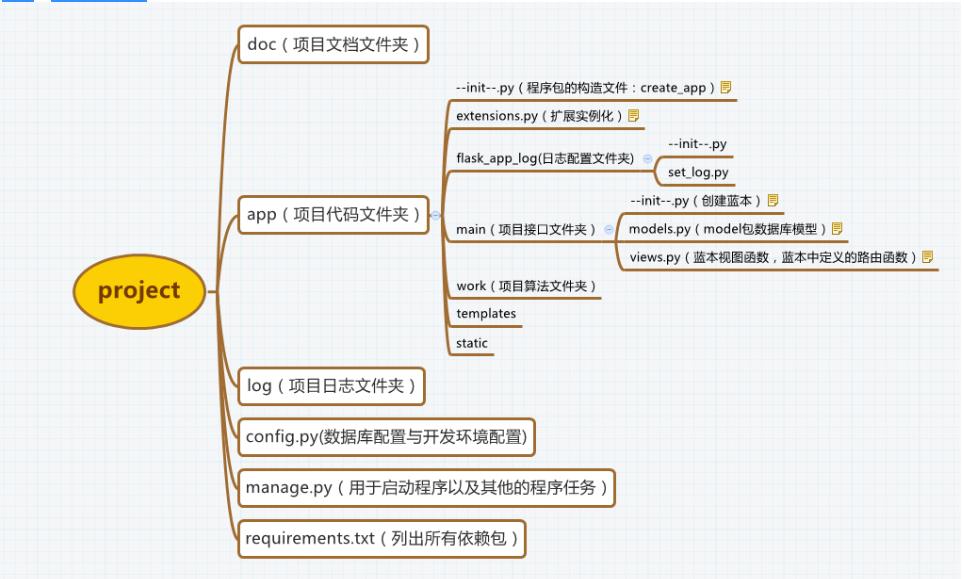
Flask项目结构图
相关代码:
from flask import Flask as _Flask, jsonify, render_template
from flask.json import JSONEncoder as _JSONEncoder
import decimal
import utils
class JSONEncoder(_JSONEncoder):
def default(self, o):
if isinstance(o, decimal.Decimal):
return float(o)
super(_JSONEncoder, self).default(o)
class Flask(_Flask):
json_encoder = JSONEncoder
app = Flask(__name__)
# 这里发现flask根本不会调用我在utils中处理数据的代码,所以直接就在这里定义了两个常量
# 如果想要爬取其它招聘岗位信息的话,先运行utils中的代码,然后运行app.py代码,同时,更改下面的datatable和job_name
datatable = 'data_mining'
job_name = '数据挖掘'
# 路由解析,每映射到一个路由就调用一个函数
@app.route('/')
def index():
return render_template("main.html")
@app.route('/title')
def get_title1():
return job_name
# 获取系统当前时间,每隔1s刷新一次
@app.route('/time')
def get_time1():
return utils.get_time()
# 对数据库中的数据进行计数、薪资取平均值、省份和学历取众数
@app.route('/c1')
def get_c1_data1():
data = utils.get_c1_data(datatable)
return jsonify("employ": data[0], "avg_salary": data[1], "province": data[2], "edu": data[3])
# 对省份进行分组,之后统计其个数,使用jsonify来将数据传输给ajax(中国地图)
@app.route('/c2')
def get_c2_data1():
res = []
for tup in utils.get_c2_data(datatable):
res.append("name": tup[0], "value": int(tup[1]))
return jsonify("data": res)
# 统计每个学历下公司数量和平均薪资(上下坐标折线图)
@app.route('/l1')
# 下面为绘制折线图的代码,如果使用这个的话需要在main.html中引入ec_left1.js,然后在controller.js中重新调用
# def get_l1_data1():
# data = utils.get_l1_data()
# edu, avg_salary = [], []
# for s in data:
# edu.append(s[0])
# avg_salary.append(s[1])
# return jsonify("edu": edu, "avg_salary": avg_salary)
def get_l1_data1():
data = utils.get_l1_data(datatable)
edu, sum_company, avg_salary = [], [], []
for s in data:
edu.append(s[0])
sum_company.append(int(s[1]))
avg_salary.append(float(s[2]))
return jsonify("edu": edu, "sum_company": sum_company, "avg_salary": avg_salary)
# 统计不同学历下公司所招人数和平均经验(折线混柱图)
@app.route('/l2')
def get_l2_data1():
data = utils.get_l2_data(datatable)
edu, num, exp = [], [], []
# 注意sql中会存在decimal的数据类型,我们需要将其转换为int或者float的格式
for s in data:
edu.append(s[0])
num.append(float(s[1]))
exp.append(float(s[2]))
return jsonify('edu': edu, 'num': num, 'exp': exp)
# 统计不同类型公司所占的数量(饼图)
@app.route('/r1')
def get_r1_data1():
res = []
for tup in utils.get_r1_data(datatable):
res.append("name": tup[0], "value": int(tup[1]))
return jsonify("data": res)
# 对猎聘网上的“岗位要求”文本进行分词后,使用jieba.analyse下的extract_tags来获取全部文本的关键词和权重,再用echarts来可视化词云
@app.route('/r2')
def get_r2_data1():
cloud = []
text, weight = utils.get_r2_data(datatable)
for i in range(len(text)):
cloud.append('name': text[i], 'value': weight[i])
return jsonify("kws": cloud)
if __name__ == '__main__':
app.run()
4 Echarts
ECharts(Enterprise Charts)是百度开源的数据可视化工具,底层依赖轻量级Canvas库ZRender。兼容了几乎全部常用浏览器的特点,使它可广泛用于PC客户端和手机客户端。ECharts能辅助开发者整合用户数据,创新性的完成个性化设置可视化图表。支持折线图(区域图)、柱状图(条状图)、散点图(气泡图)、K线图、饼图(环形图)等,通过导入 js 库在 Java Web 项目上运行。
相关代码:
# 导入模块
from pyecharts import options as opts
from pyecharts.charts import Pie
#准备数据
label=['民营公司','上市公司','国企','合资','外资(欧美)','外资(非欧美)','创业公司','事业单位']
values = [300,300,300,300,44,300,300,300]
# 自定义函数
def pie_base():
c = (
Pie()
.add("",[list(z) for z in zip(label,values)])
.set_global_opts(title_opts = opts.TitleOpts(title="公司类型分析"))
.set_series_opts(label_opts=opts.LabelOpts(formatter="b:c d%")) # 值得一提的是,d%为百分比
)
return c
# 调用自定义函数生成render.html
pie_base().render()
5 爬虫
简介
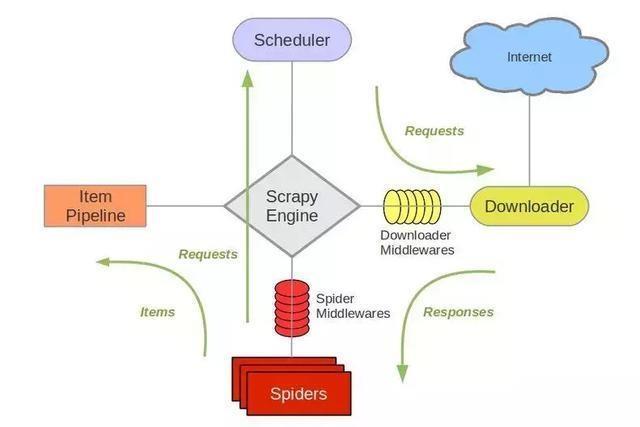
Scrapy是基于Twisted的爬虫框架,它可以从各种数据源中抓取数据。其架构清晰,模块之间的耦合度低,扩展性极强,爬取效率高,可以灵活完成各种需求。能够方便地用来处理绝大多数反爬网站,是目前Python中应用最广泛的爬虫框架。Scrapy框架主要由五大组件组成,它们分别是调度器(Scheduler)、下载器(Downloader)、爬虫(Spider)和实体管道(Item Pipeline)、Scrapy引擎(Scrapy Engine)。各个组件的作用如下:
-
调度器(Scheduler):说白了把它假设成为一个URL(抓取网页的网址或者说是链接)的优先队列,由它来决定下一个要抓取的网址是 什么,同时去除重复的网址(不做无用功)。用户可以自己的需求定制调度器。
-
下载器(Downloader):是所有组件中负担最大的,它用于高速地下载网络上的资源。Scrapy的下载器代码不会太复杂,但效率高,主要的原因是Scrapy下载器是建立在twisted这个高效的异步模型上的(其实整个框架都在建立在这个模型上的)。
-
爬虫(Spider):是用户最关心的部份。用户定制自己的爬虫(通过定制正则表达式等语法),用于从特定的网页中提取自己需要的信息,即所谓的实体(Item)。 用户也可以从中提取出链接,让Scrapy继续抓取下一个页面。
-
实体管道(Item Pipeline):用于处理爬虫(spider)提取的实体。主要的功能是持久化实体、验证实体的有效性、清除不需要的信息。
-
Scrapy引擎(Scrapy Engine):Scrapy引擎是整个框架的核心.它用来控制调试器、下载器、爬虫。实际上,引擎相当于计算机的CPU,它控制着整个流程。
官网架构图
相关代码:
# -*- coding: utf-8 -*-
import requests
import re
import json
import time
import pandas as pd
from lxml import etree
# 为了防止被封IP,下面使用基于redis的IP代理池来获取随机IP,然后每次向服务器请求时都随机更改我们的IP(该ip_pool搭建相对比较繁琐,此处省略搭建细节)
# 假如不想使用代理IP的话,则直接设置下方的time.sleep,并将proxies参数一并删除
proxypool_url = 'http://127.0.0.1:5555/random'
# 定义获取ip_pool中IP的随机函数
def get_random_proxy():
proxy = requests.get(proxypool_url).text.strip()
proxies = 'http': 'http://' + proxy
return proxies
# 前程无忧网站上用来获取每个岗位的字段信息
def job51(datatable, job_name, page):
# 浏览器伪装
headers =
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.63 Safari/537.36 Edg/93.0.961.47'
# 每个页面提交的参数,降低被封IP的风险
params =
'lang': 'c',
'postchannel': '0000',
'workyear': '99',
'cotype': '99',
'degreefrom': '99',
'jobterm': '99',
'companysize': '99',
'ord_field': '0',
'dibiaoid': '0'
href, update, job, company, salary, area, company_type, company_field, attribute = [], [], [], [], [], [], [], [], []
# 使用session的好处之一便是可以储存每次的cookies,注意使用session时headers一般只需放上user-agent
session = requests.Session()
# 查看是否可以完成网页端的请求
# print(session.get('https://www.51job.com/', headers=headers, proxies=get_random_proxy()))
# 爬取每个页面下所有数据
for i in range(1, int(page) + 1):
url = f'https://search.51job.com/list/000000,000000,0000,00,9,99,job_name,2,i.html'
response = session.get(url, headers=headers, params=params, proxies=get_random_proxy())
# 使用正则表达式提取隐藏在html中的岗位数据
ss = '' + re.findall(r'window.__SEARCH_RESULT__ = (.*)', response.text)[0] + ''
# 加载成json格式,方便根据字段获取数据
s = json.loads(ss)
data = s['engine_jds']
for info in data:
href.append(info['job_href'])
update.append(info['issuedate'])
job.append(info['job_name'])
company.append(info['company_name'])
salary.append(info['providesalary_text'])
area.append(info['workarea_text'])
company_type.append(info['companytype_text'])
company_field.append(info['companyind_text'])
attribute.append(' '.join(info['attribute_text']))
# time.sleep(np.random.randint(1, 2))
# 保存数据到DataFrame
df = pd.DataFrame(
'岗位链接': href, '发布时间': update, '岗位名称': job, '公司名称': company, '公司类型': company_type, '公司领域': company_field,
'薪水': salary, '地域': area, '其他信息': attribute)
# 保存数据到csv文件中
df.to_csv(f'./data/datatable/51job_datatable.csv', encoding='gb18030', index=None)
# 猎聘网上用来获取每个岗位对应的详细要求文本
def liepin(datatable, job_name, page):
# 浏览器伪装和相关参数
headers =
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.63 Safari/537.36 Edg/93.0.961.47'
job, salary, area, edu, exp, company, href, content = [], [], [], [], [], [], [], []
# 使用session的好处之一便是可以储存每次的cookies,注意使用session时headers一般只需放上user-agent
session = requests.Session()
# print(session.get('https://www.liepin.com/zhaopin/', headers=headers, proxies = get_random_proxy()))
# 通过输入岗位名称和页数来爬取对应的网页内容
# job_name = input('请输入你想要查询的岗位:')
# page = input('请输入你想要下载的页数:')
# 遍历每一页上的数据
for i in range(int(page)):
url = f'https://www.liepin.com/zhaopin/?key=job_name&curPage=i'
# time.sleep(np.random.randint(1, 2))
response = session.get(url, headers=headers, proxies = get_random_proxy())
html = etree.HTML(response.text)
# 每页共有40条岗位信息
for j in range(1, 41):
# job.append(html.xpath(f'//ul[@class="sojob-list"]/li[j]/div/div[1]/h3/@title')[0])
# info = html.xpath(f'//ul[@class="sojob-list"]/li[j]/div/div[1]/p[1]/@title')[0]
# ss = info.split('_')
# salary.append(ss[0])
# area.append(ss[1])
# edu.append(ss[2])
# exp.append(ss[-1])
# company.append(html.xpath(f'//ul[@class="sojob-list"]/li[j]/div/div[2]/p[1]/a/text()')[0])
href.append(html.xpath(f'//ul[@class="sojob-list"]/li[j]/div/div[1]/h3/a/@href')[0])
# 遍历每一个岗位的数据
for job_href in href:
# time.sleep(np.random.randint(1, 2))
# 发现有些岗位详细链接地址不全,需要对缺失部分进行补齐
if 'https' not in job_href:
job_href = 'https://www.liepin.com' + job_href
response = session.get(job_href, headers=headers, proxies = get_random_proxy())
html = etree.HTML(response.text)
content.append(html.xpath('//section[@class="job-intro-container"]/dl[1]//text()')[3])
# 保存数据
# df = pd.DataFrame('岗位名称': job, '公司': company, '薪水': salary, '地域': area, '学历': edu, '工作经验': exp, '岗位要求': content)
df = pd.DataFrame('岗位要求': content)
df.to_csv(f'./data/datatable/liepin_datatable.csv', encoding='gb18030', index=None)
🧿 选题指导, 项目分享:
https://gitee.com/yaa-dc/warehouse-1/blob/master/python/README.md
Python | 新冠肺炎疫情数据的爬取与可视化分析
前言
这两年,新冠肺炎肆虐而来,随着确诊人数的不断上升,全世界的人都陷入了恐慌中。我们经常能在手机、电视上看到各个地区疫情的情况,但那些数据大多数都是零碎的,我们不可能去记住每个数据,但我们可以用爬虫爬取各个地区发出的新闻数据,再将这些数据进行整理分析。所以我们在疫情期间可以通过访问一个网站,就能知道各个地区的疫情情况。
数据来源
爬虫设计方案
1. 爬虫名称
新冠肺炎疫情数据的爬取与可视化分析
2. 爬取内容与数据特征分析
爬取的内容包括了全球新冠肺炎疫情数据、中国各省市新冠肺炎疫情数据和福建各市新冠肺炎疫情数据。
爬取的数据都由中文和数字组成,所有数字数据都是大于等于0,不会出现小于0的情况。
3. 方案概述
分析网站页面结构,找到爬取数据的位置,根据不同的数据制定不同的爬取方法,将爬取的数据保存成csv文件,然后再将csv文件里的数据进行可视化处理。
网站页面的结构特征分析
1. 网站页面结构分析
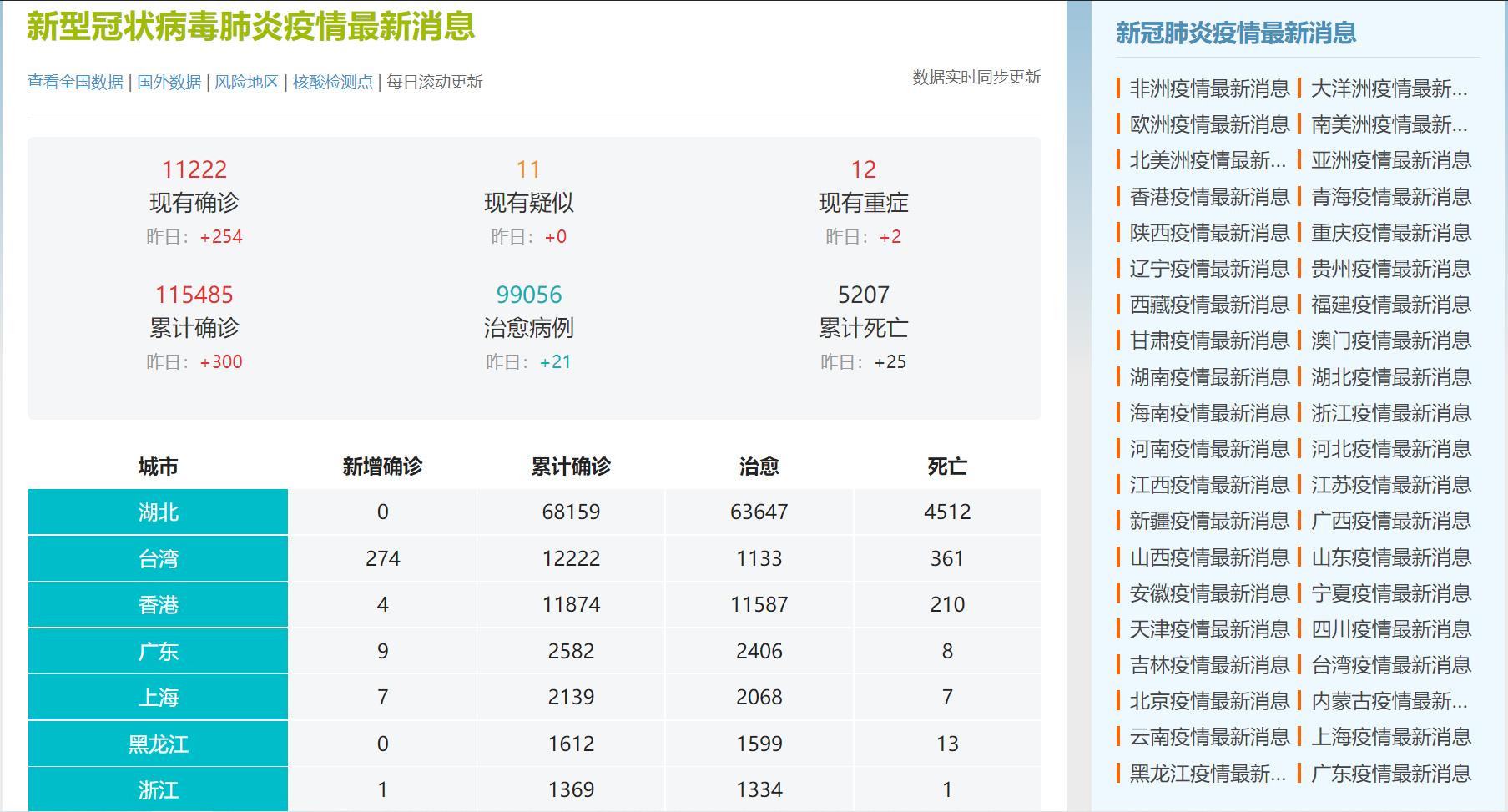
从下面的网站截图中可以看出,该网站的结构分为三个部分,一部分是左上的疫情总览,一部分是右边各个地区的疫情消息,还有一部分就是左下各个地区具体的疫情数据,而这部分数据就是我们要爬取的数据。
2. 网站html页面结构分析
从下面的网站html截图中可以看出,该网站由div标签进行分割内容,总共分了两大块,左边和右边,我们需要的数据在左边。
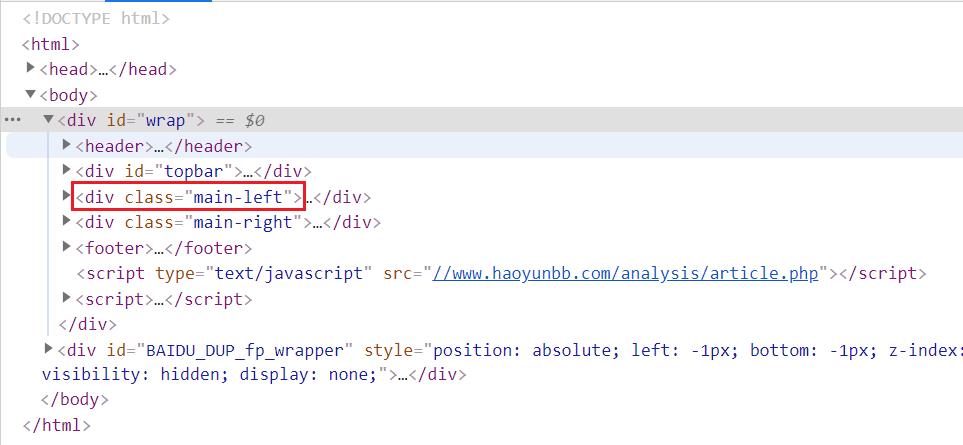
进一步分析网站的html,发现数据都在class=data-list的div标签里,在div标签里的列表标签ul,存放着中国每个省的疫情数据。

在li标签下,还有一个div,这个div里的ul列表存放的数据是每个省市的数据。
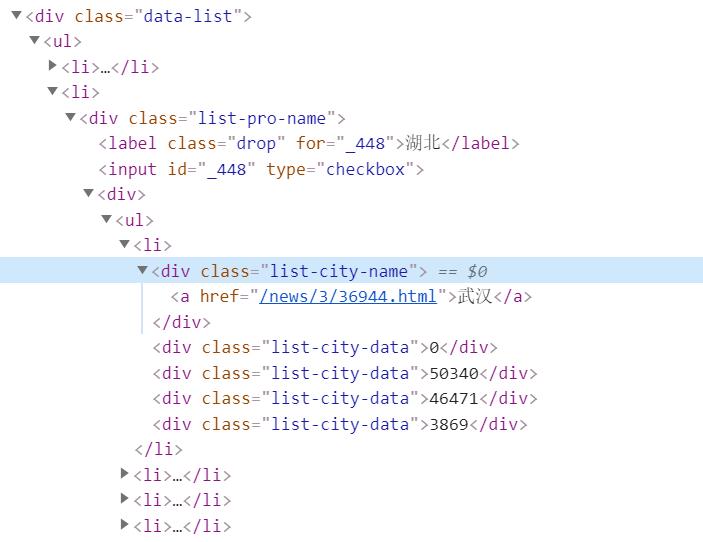
3. 标签查找方法与遍历方法
通过上面网站html页面的分析,可以画出标签树。

(1)地区名称所在标签的查找方法
各个省份的名称在class=list-pro-name的div标签里,而各省份的城市的名称在class=list-city-name的div标签里。因为这两个标签的class属性不同,所以可以用BeautifulSoup库的find()方法,利用标签属性值检索。
(2)地区疫情数据所在标签的查找方法
从上面的标签树中可以看出,省疫情数据和市疫情数据分别在不同的li标签下的div标签里,第二个li是第一个li的子标签。在这两个标签之间没有可以唯一标识的熟悉,所以要查找到这两个标签需要BeautifulSoup库的CSS选择器,通过标签的父子关系分别找到两个li标签。
爬虫程序设计
1. 数据的爬取
(1)中国新冠疫情数据的爬取
# 获取中国每个省的疫情数据
def getProvinceData(html):
total_data=[]
temporary=[]
new_diagnosis_data=[]
cumulative_diagnosis_data=[]
cured_data=[]
dead_data=[]
soup = BeautifulSoup(html,\'html.parser\')
# 找到 class=data-list 的div标签
data = soup.find(\'div\',{\'class\':\'data-list\'})
ul = data.find(\'ul\')
div = ul.find_all(\'div\',{\'class\':\'list-pro-name\'})
province_name_data=[]
for i in div:
# 获取省的名称
# 省名称在label标签里
province_name = i.find(\'label\').string
province_name_data.append(province_name)
# 用CSS选择器获取第一层的数据(每个省的数据)
diagnosis = soup.select(\'div.data-list > ul > li > div.list-city-data\')
for i in diagnosis:
temporary.append(i.string)
total = [temporary[i:i+4] for i in range(0,len(temporary),4)]
for i in range(len(total)):
# 获取新增确诊人数
new_diagnosis_data.append(total[i][0])
# 获取累计确诊人数
cumulative_diagnosis_data.append(total[i][1])
# 获取治愈人数
cured_data.append(total[i][2])
# 获取死亡人数
dead_data.append(total[i][3])
total_data.append(province_name_data)
total_data.append(new_diagnosis_data)
total_data.append(cumulative_diagnosis_data)
total_data.append(cured_data)
total_data.append(dead_data)
return total_data
(2)福建省新冠疫情数据的爬取
# 获取福建省每个市的疫情数据
def getCitiData(html):
citi_name_data=[]
new_diagnosis_data=[]
cumulative_diagnosis_data=[]
cured_data=[]
dead_data=[]
total_data=[]
soup = BeautifulSoup(html,\'html.parser\')
data = soup.find(\'div\',{\'class\':\'data-list\'})
# 找到有唯一标识的属性的input标签
input1 = data.find(\'input\',{\'id\':\'_209\'})
# 找到input标签的的父标签
div = input1.parent
# 找到所有的li
li = div.find_all(\'li\')
# 遍历li组成的列表
for i in range(1,len(li)):
# 获取市名称
citi_name = li[i].find(\'div\',{\'class\':\'list-city-name\'})
citi_name_data.append(citi_name.string+\'市\')
div = li[i].find_all(\'div\',{\'class\':\'list-city-data\'})
# 获取新增确诊人数
new_diagnosis = div[0].string
new_diagnosis_data.append(new_diagnosis)
# 获取累计确诊人数
cumulative_diagnosis = div[1].string
cumulative_diagnosis_data.append(cumulative_diagnosis)
# 获取治愈人数
cured = div[2].string
cured_data.append(cured)
# 获取死亡人数
dead = div[3].string
dead_data.append(dead)
total_data.append(citi_name_data)
total_data.append(new_diagnosis_data)
total_data.append(cumulative_diagnosis_data)
total_data.append(cured_data)
total_data.append(dead_data)
return total_data
(3)国外新冠疫情数据的爬取
# 获取全球每个国家的疫情数据
def getWorldData(html):
country_name_data=[]
new_diagnosis_data=[]
cumulative_diagnosis_data=[]
cured_data=[]
dead_data=[]
total_data=[]
soup = BeautifulSoup(html,\'html.parser\')
data = soup.find(\'div\',{\'class\':\'data-list\'})
# 因为有两层li,我们需要的是第二层的li,所以可以通过CSS选择器来获取第二层的li
data_list = data.select(\'ul > li > div > div > ul > li\')
for i in range(12,len(data_list)-1):
div = data_list[i].find_all(\'div\')
# 获取国家名称
country_name = div[0].string
country_name_data.append(country_name)
# 获取新增确诊人数
new_diagnosis = div[1].string
new_diagnosis_data.append(new_diagnosis)
# 获取累计确诊人数
cumulative_diagnosis = div[2].string
cumulative_diagnosis_data.append(cumulative_diagnosis)
# 获取治愈人数
cured = div[3].string
cured_data.append(cured)
# 获取死亡人数
dead = div[4].string
dead_data.append(dead)
total_data.append(country_name_data)
total_data.append(new_diagnosis_data)
total_data.append(cumulative_diagnosis_data)
total_data.append(cured_data)
total_data.append(dead_data)
return total_data
(4)保存数据
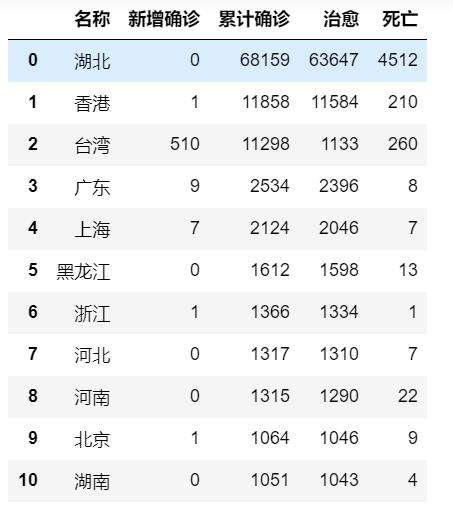
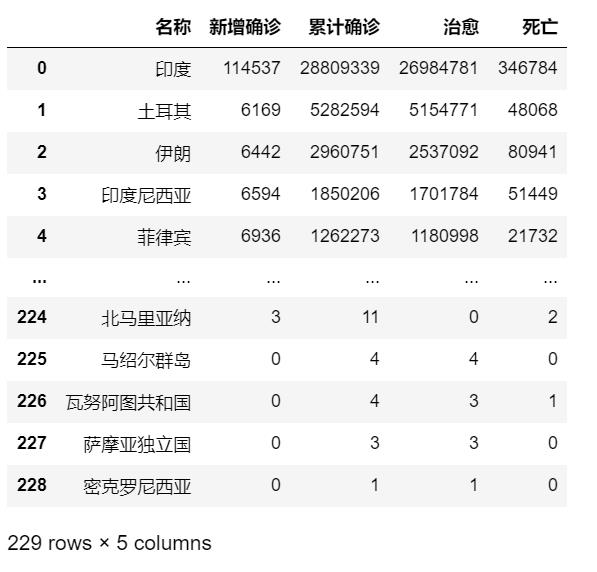
疫情数据爬取完后,通过Pandask库的to_csv()方法,将爬取后的数据保存为csv文件。
保存后的部分数据:

2. 数据清洗与处理
(1)因为全球疫情的数据量较大,所以我们可以通过pandas库来查看数据是否有异常、缺失、重复
import pandas as pd
#导入数据
df_world = pd.read_csv("各国家的新冠肺炎疫情数据.csv")
# 查看数据的简要信息
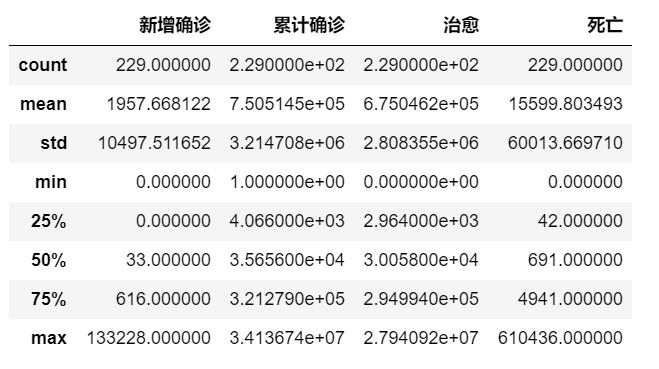
df_world.describe()
(2)通过查看数据的简要信息,数据正常,数据的最小值也不是负数
(3)通过pandas库的isnull()方法查看是否有空值
# 查看是否有空值,有空值返回True,没有空值返回False
df_world.isnull().value_counts()

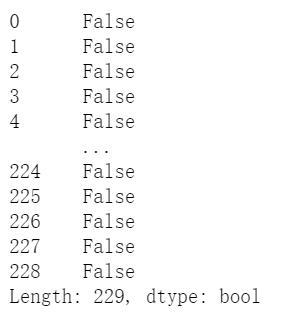
(4)通过pandas库的duplicated()方法查看是否有重复行
# 查看是否有重复行,有重复行返回True,没有重复行返回False
df_world.duplicated()
(5)为了之后能更好的分析数据,需要对数据进行排序,后面再排序也可以
#根据累计确诊人数对数据进行降序排序
df = df_world.sort_values(by=\'累计确诊\',ascending=False)
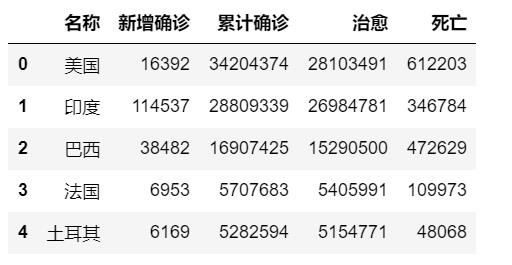
(6)保存处理后的数据
#保存处理后的数据
import pandas as pd
df = df.set_index(\'名称\')
df.to_csv("各国家的新冠肺炎疫情数据.csv",encoding=\'utf-8\')
df_world = pd.read_csv("各国家的新冠肺炎疫情数据.csv")
df_world.head()
3. 数据可视化分析
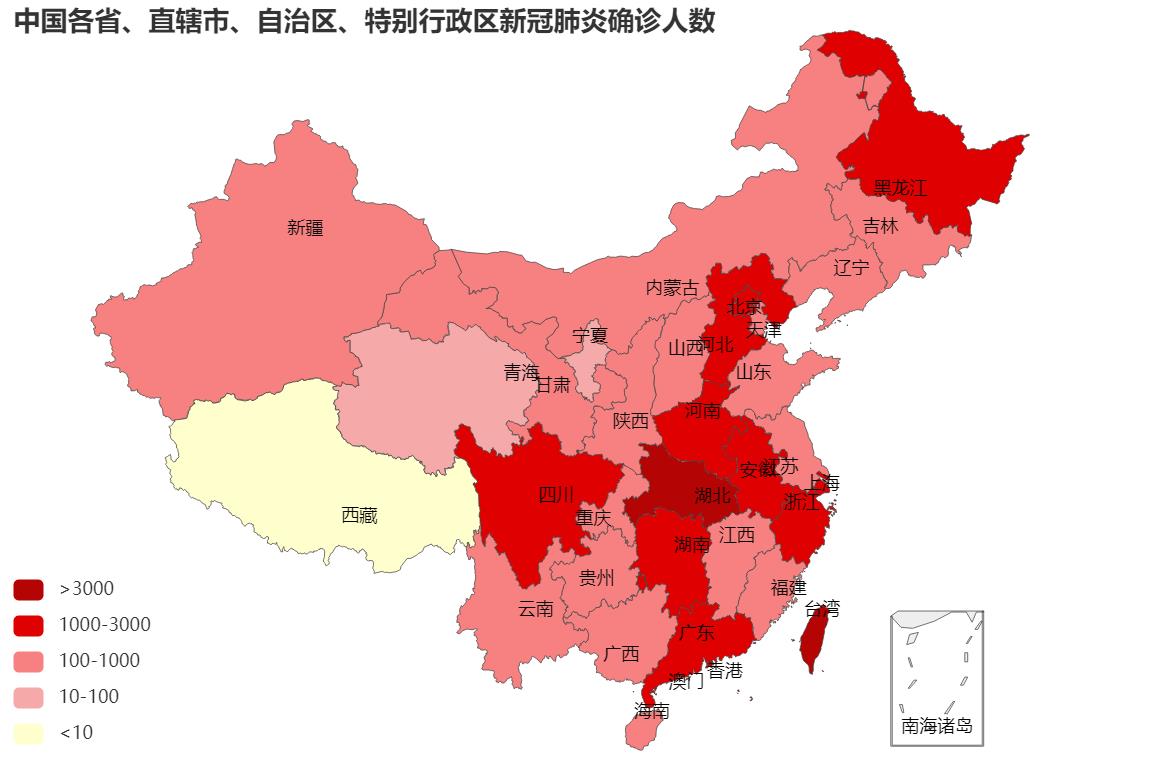
(1)中国新冠肺炎疫情地图
# 用pyecharts库画中国新冠疫情地图
from pyecharts import options as opts
from pyecharts.charts import Map
import pandas as pd
# 自定义分段图例
pieces=[
{"max": 70000, "min": 3000, "label": ">3000", "color": "#B40404"},
{"max": 3000, "min": 1000, "label": "1000-3000", "color": "#DF0101"},
{"max": 1000, "min": 100, "label": "100-1000", "color": "#F78181"},
{"max": 100, "min": 10, "label": "10-100", "color": "#F5A9A9"},
{"max": 10, "min": 0, "label": "<10", "color": "#FFFFCC"},
]
name = []
values = []
# 导入数据
df = pd.DataFrame(pd.read_csv("各省的新冠肺炎疫情数据.csv"))
# 处理数据,将数据处理成Map所要求的数据
for i in range(df.shape[0]): # shape[0]:行数,shape[1]:列数
name.append(df.at[i,\'名称\'])
values.append(str(df.at[i,\'累计确诊\']))
total = [[name[i],values[i]] for i in range(len(name))]
# 创建地图(Map)
china_map = (Map())
# 设置中国地图
china_map.add("确诊人数",total ,maptype="china",is_map_symbol_show=False)
china_map.set_global_opts(
# 设置地图标题
title_opts=opts.TitleOpts(title="中国各省、直辖市、自治区、特别行政区新冠肺炎确诊人数"),
# 设置自定义图例
visualmap_opts=opts.VisualMapOpts(max_=70000,is_piecewise=True,pieces=pieces),
legend_opts=opts.LegendOpts(is_show=False)
)
# 直接在notebook显示地图,默认是保存为html文件
china_map.render_notebook()
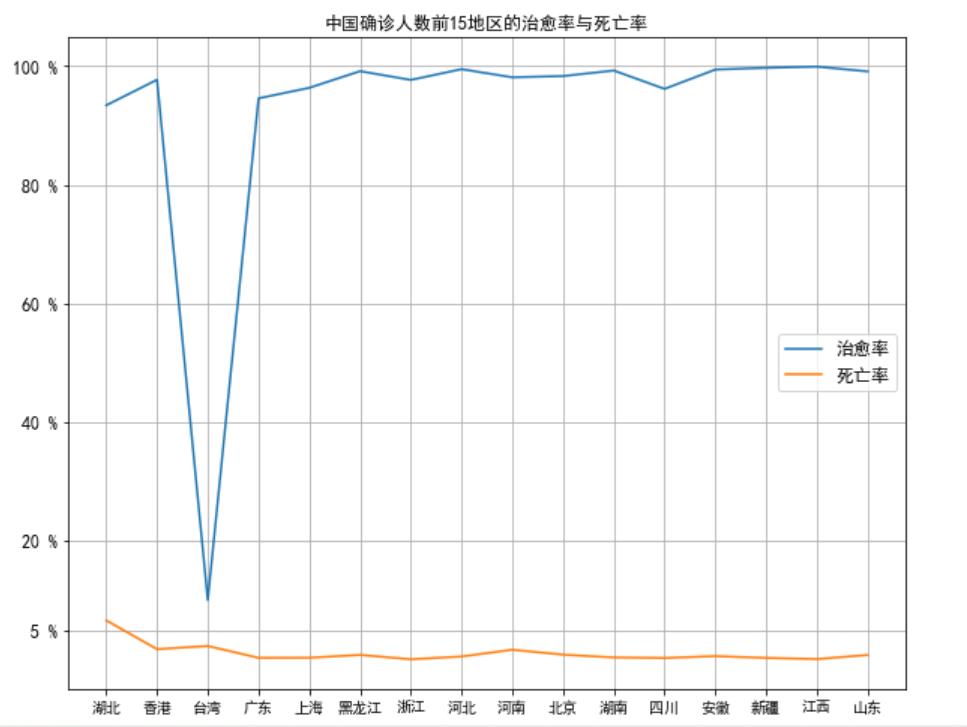
(2)中国确诊人数前15地区的治愈率与死亡率的折线图
import pandas as pd
import matplotlib.pyplot as plt
# 创建画布
fig=plt.figure(figsize=(10,8))
ax=fig.add_subplot(1,1,1)
#中文字体
plt.rcParams[\'font.family\'] = [\'SimHei\']
# 导入数据
df_china = pd.read_csv("各省的新冠肺炎疫情数据.csv")
df_china[\'治愈率\'] = df_china[\'治愈\']/df_china[\'累计确诊\']
df_china[\'死亡率\'] = df_china[\'死亡\']/df_china[\'累计确诊\']
plt.plot(df_china.iloc[0:16,0],df_china.iloc[0:16,5],label="治愈率")
plt.plot(df_china.iloc[0:16,0],df_china.iloc[0:16,6],label="死亡率")
# y轴刻度标签
ax.set_yticks([0.05,0.2,0.4,0.6,0.8,1.0])
ax.set_yticklabels(["5 %","20 %","40 %","60 %","80 %","100 %"],fontsize=12)
# 图例
plt.legend(loc=\'center right\',fontsize=12)
# 标题
plt.title("中国确诊人数前15地区的治愈率与死亡率")
# 网格
plt.grid()
plt.show()
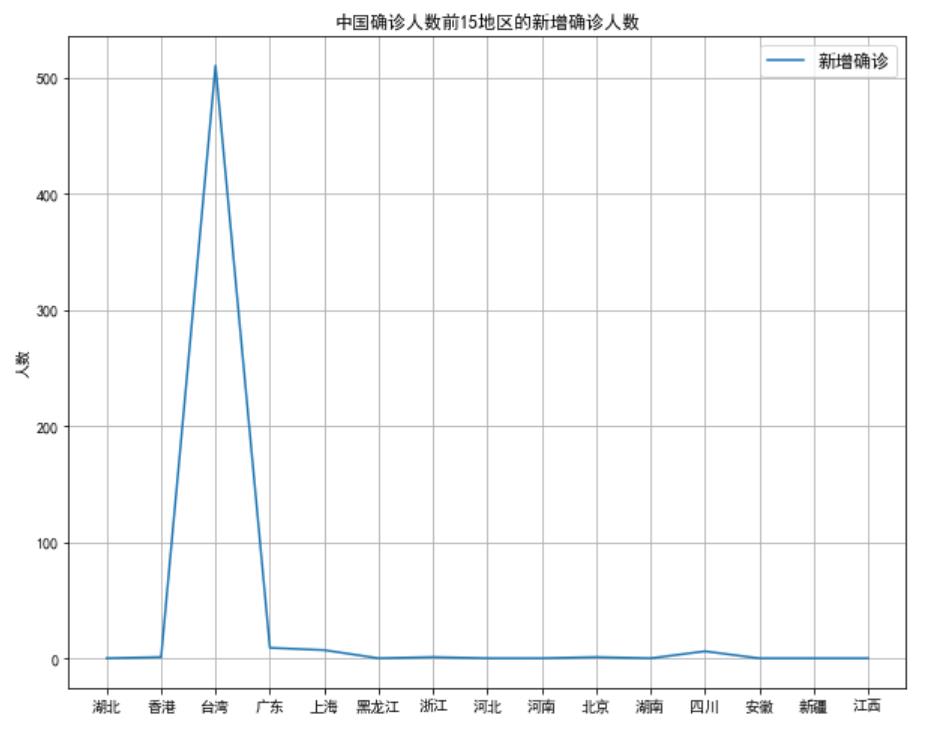
(3)中国确诊人数前15地区的新增确诊人数的折线图
import pandas as pd
import matplotlib.pyplot as plt
# 创建画布
fig=plt.figure(figsize=(10,8))
#中文字体
plt.rcParams[\'font.family\'] = [\'SimHei\']
#导入数据
df_china = pd.read_csv("各省的新冠肺炎疫情数据.csv")
plt.plot(df_china.iloc[0:15,0],df_china.iloc[0:15,1],label="新增确诊")
# 图例
plt.legend(fontsize=12)
# 标题
plt.title("中国确诊人数前15地区的新增确诊人数")
# y轴标签
plt.ylabel(\'人数\')
# 网格
plt.grid()
plt.show()
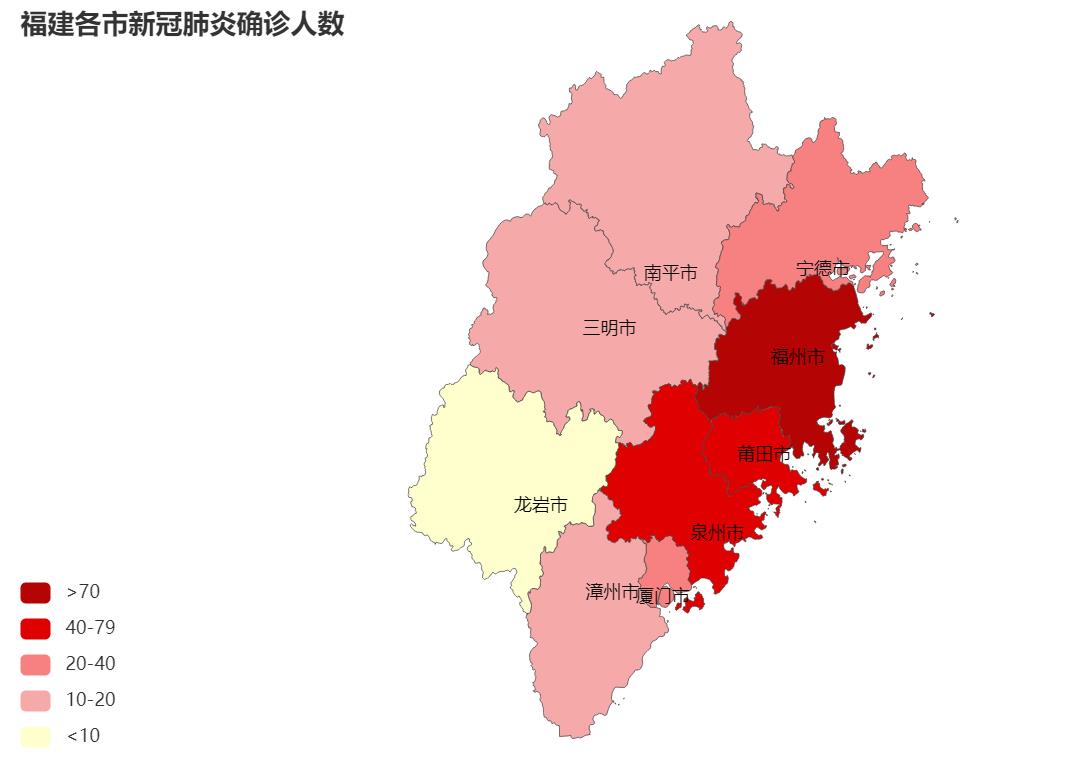
(4)福建新冠肺炎疫情地图
#用pyecharts库画福建疫情分布地图
import pandas as pd
from pyecharts.charts import Map,Geo
from pyecharts import options as opts
#自定义分段图例
pieces=[
{"max": 100, "min": 70, "label": ">70", "color": "#B40404"},
{"max": 70, "min": 40, "label": "40-79", "color": "#DF0101"},
{"max": 40, "min": 20, "label": "20-40", "color": "#F78181"},
{"max": 20, "min": 10, "label": "10-20", "color": "#F5A9A9"},
{"max": 10, "min": 0, "label": "<10", "color": "#FFFFCC"},
]
name = []
values = []
#导入数据
df_citi = pd.read_csv("各市的新冠肺炎疫情数据.csv")
# 处理数据,将数据处理成Map所要求的数据
for i in range(df_citi.shape[0]): # shape[0]:行数,shape[1]:列数
name.append(df_citi.at[i,\'名称\'])
values.append(str(df_citi.at[i,\'累计确诊\']))
total = [[name[i],values[i]] for i in range(len(name))]
# 创建地图
chinaciti_map = (Map())
# 设置福建省地图
chinaciti_map.add("确诊人数",total ,maptype="福建",is_map_symbol_show=False)
chinaciti_map.set_global_opts(
# 地图标题
title_opts=opts.TitleOpts(title="福建各市新冠肺炎确诊人数"),
# 设置自定义图例
visualmap_opts=opts.VisualMapOpts(max_=100,is_piecewise=True,pieces=pieces),
legend_opts=opts.LegendOpts(is_show=False)
)
# 直接在notebook显示地图,默认是保存为html文件
chinaciti_map.render_notebook()
(5)福建新冠肺炎疫情饼图
import matplotlib.pyplot as plt
import pandas as pd
# 创建画布
plt.figure(figsize=(6,4))
#中文字体
plt.rcParams[\'font.family\'] = [\'SimHei\']
#导入数据
df_citi = pd.read_csv("各市的新冠肺炎疫情数据.csv")
labels = df_citi[\'名称\'].values
data = df_citi[\'累计确诊\'].values
plt.pie(data ,labels=labels, autopct=\'%1.1f%%\')
#设置显示图像为圆形
plt.axis(\'equal\')
# 标题
plt.title(\'福建省各市新冠疫情比例\')
plt.show()

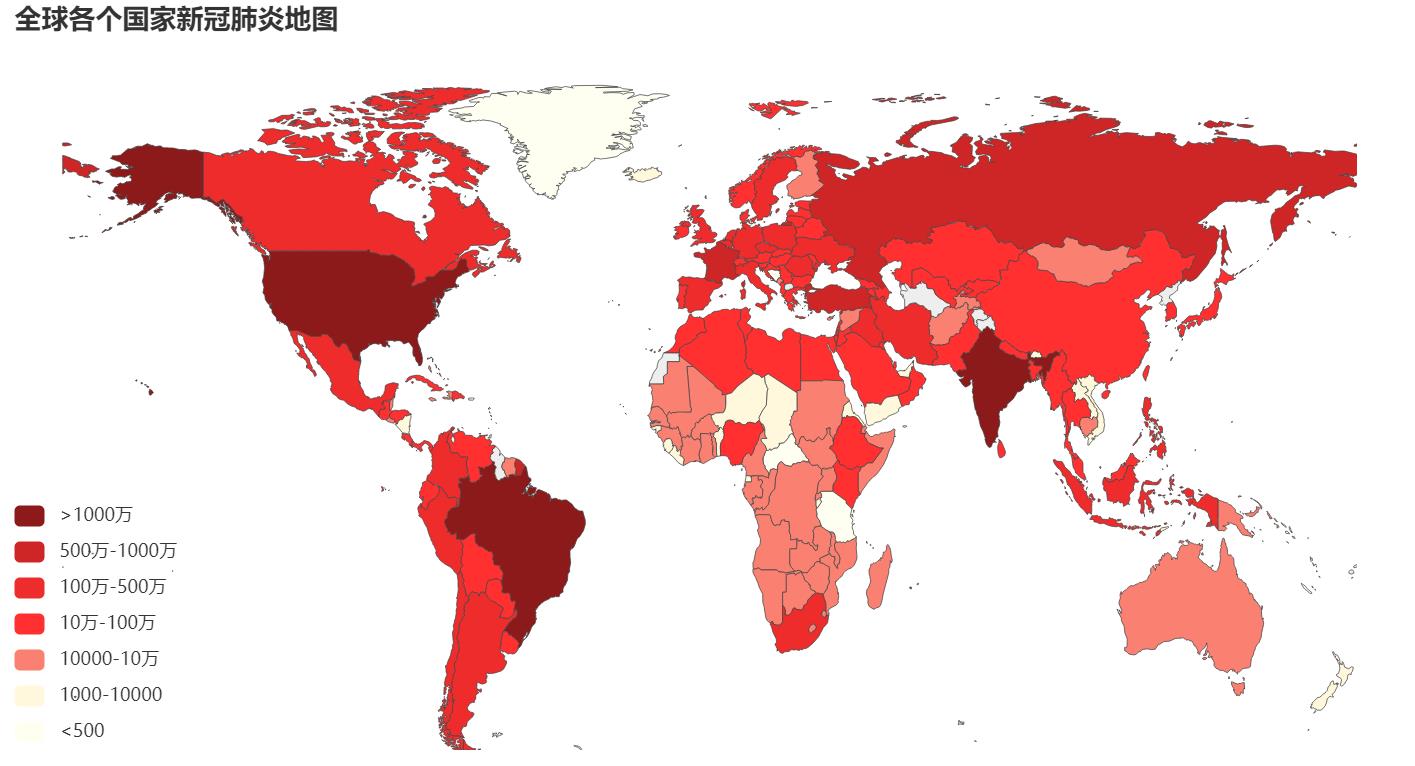
(6)全球新冠肺炎疫情地图
因为世界地图的国家名是英文的,而爬取的数据的国家名是中文的,国家名对不上会导致数据显示不到地图上,所以要先建一个映射字典,将英文替换成中文
#中文国家名映射字典
nameMap = {
\'Singapore Rep.\':\'新加坡\',\'Dominican Rep.\':\'多米尼加\',\'Palestine\':\'巴勒斯坦\',\'Bahamas\':\'巴哈马\',\'Timor-Leste\':\'东帝汶\',\'Afghanistan\':\'阿富汗\',
\'Guinea-Bissau\':\'几内亚比绍\',"Côte d\'Ivoire":\'科特迪瓦\',\'Siachen Glacier\':\'锡亚琴冰川\',"Br. Indian Ocean Ter.":\'英属印度洋领土\',\'Angola\':\'安哥拉\',
\'Albania\':\'阿尔巴尼亚\',\'United Arab Emirates\':\'阿联酋\',\'Argentina\':\'阿根廷\',\'Armenia\':\'亚美尼亚\',\'French Southern and Antarctic Lands\':\'法属南半球和南极领地\',
\'Australia\':\'澳大利亚\',\'Austria\':\'奥地利\',\'Azerbaijan\':\'阿塞拜疆\',\'Burundi\':\'布隆迪\',\'Belgium\':\'比利时\',\'Benin\':\'贝宁\',\'Burkina Faso\':\'布基纳法索\',
\'Bangladesh\':\'孟加拉国\',\'Bulgaria\':\'保加利亚\',\'The Bahamas\':\'巴哈马\',\'Bosnia and Herz.\':\'波斯尼亚和黑塞哥维那\',\'Belarus\':\'白俄罗斯\',\'Belize\':\'伯利兹\',
\'Bermuda\':\'百慕大\',\'Bolivia\':\'玻利维亚\',\'Brazil\':\'巴西\',\'Brunei\':\'文莱\',\'Bhutan\':\'不丹\',\'Botswana\':\'博茨瓦纳\',\'Central African Rep.\':\'中非\',\'Canada\':\'加拿大\',
\'Switzerland\':\'瑞士\',\'Chile\':\'智利\',\'China\':\'中国\',\'Ivory Coast\':\'象牙海岸\',\'Cameroon\':\'喀麦隆\',\'Dem. Rep. Congo\':\'刚果(金)\',\'Congo\':\'刚果(布)\',
\'Colombia\':\'哥伦比亚\',\'Costa Rica\':\'哥斯达黎加\', \'Cuba\':\'古巴\',\'N. Cyprus\':\'北塞浦路斯\',\'Cyprus\':\'塞浦路斯\',\'Czech Rep.\':\'捷克\',\'Germany\':\'德国\',
\'Djibouti\':\'吉布提\',\'Denmark\':\'丹麦\',\'Algeria\':\'阿尔及利亚\',\'Ecuador\':\'厄瓜多尔\',\'Egypt\':\'埃及\',\'Eritrea\':\'厄立特里亚\',\'Spain\':\'西班牙\',\'Estonia\':\'爱沙尼亚\',
\'Ethiopia\':\'埃塞俄比亚\',\'Finland\':\'芬兰\',\'Fiji\':\'斐\',\'Falkland Islands\':\'福克兰群岛\',\'France\':\'法国\',\'Gabon\':\'加蓬\',\'United Kingdom\':\'英国\',\'Georgia\':\'格鲁吉亚\',
\'Ghana\':\'加纳\',\'Guinea\':\'几内亚\',\'Gambia\':\'冈比亚\',\'Guinea Bissau\':\'几内亚比绍\',\'Eq. Guinea\':\'赤道几内亚\',\'Greece\':\'希腊\',\'Greenland\':\'格陵兰岛\',
\'Guatemala\':\'危地马拉\',\'French Guiana\':\'法属圭亚那\',\'Guyana\':\'圭亚那\',\'Honduras\':\'洪都拉斯\',\'Croatia\':\'克罗地亚\',\'Haiti\':\'海地\',\'Hungary\':\'匈牙利\',
\'Indonesia\':\'印度尼西亚\',\'India\':\'印度\',\'Ireland\':\'爱尔兰\',\'Iran\':\'伊朗\',\'Iraq\':\'伊拉克\',\'Iceland\':\'冰岛\',\'Israel\':\'以色列\',\'Italy\':\'意大利\',\'Jamaica\':\'牙买加\',
\'Jordan\':\'约旦\',\'Japan\':\'日本\',\'Kazakhstan\':\'哈萨克斯坦\',\'Kenya\':\'肯尼亚\',\'Kyrgyzstan\':\'吉尔吉斯斯坦\',\'Cambodia\':\'柬埔寨\',\'Korea\':\'韩国\',\'Kosovo\':\'科索沃\',
\'Kuwait\':\'科威特\',\'Lao PDR\':\'老挝\',\'Lebanon\':\'黎巴嫩\',\'Liberia\':\'利比里亚\',\'Libya\':\'利比亚\',\'Sri Lanka\':\'斯里兰卡\',\'Lesotho\':\'莱索托\',\'Lithuania\':\'立陶宛\',
\'Luxembourg\':\'卢森堡\',\'Latvia\':\'拉脱维亚\',\'Morocco\':\'摩洛哥\',\'Moldova\':\'摩尔多瓦\',\'Madagascar\':\'马达加斯加\',\'Mexico\':\'墨西哥\',\'Macedonia\':\'马其顿\',
\'Mali\':\'马里\',\'Myanmar\':\'缅甸\',\'Montenegro\':\'黑山\',\'Mongolia\':\'蒙古国\',\'Mozambique\':\'莫桑比克\', \'Mauritania\':\'毛里塔尼亚\',\'Malawi\':\'马拉维\',
\'Malaysia\':\'马来西亚\',\'Namibia\':\'纳米比亚\',\'New Caledonia\':\'新喀里多尼亚\',\'Niger\':\'尼日尔\',\'Nigeria\':\'尼日利亚\',\'Nicaragua\':\'尼加拉瓜\',\'Netherlands\':\'荷兰\',
\'Norway\':\'挪威\',\'Nepal\':\'尼泊尔\',\'New Zealand\':\'新西兰\',\'Oman\':\'阿曼\',\'Pakistan\':\'巴基斯坦\',\'Panama\':\'巴拿马\',\'Peru\':\'秘鲁\',\'Philippines\':\'菲律宾\',
\'Papua New Guinea\':\'巴布亚新几内亚\',\'Poland\':\'波兰\',\'Puerto Rico\':\'波多黎各\',\'Dem. Rep. Korea\':\'朝鲜\',\'Portugal\':\'葡萄牙\',\'Paraguay\':\'巴拉圭\',
\'Qatar\':\'卡塔尔\',\'Romania\':\'罗马尼亚\',\'Russia\':\'俄罗斯\',\'Rwanda\':\'卢旺达\',\'W. Sahara\':\'西撒哈拉\',\'Saudi Arabia\':\'沙特阿拉伯\',\'Sudan\':\'苏丹\',
\'S. Sudan\':\'南苏丹\',\'Senegal\':\'塞内加尔\',\'Solomon Is.\':\'所罗门群岛\',\'Sierra Leone\':\'塞拉利昂\',\'El Salvador\':\'萨尔瓦多\',\'Somaliland\':\'索马里兰\',
\'Somalia\':\'索马里\',\'Serbia\':\'塞尔维亚\',\'Suriname\':\'苏里南\',\'Slovakia\':\'斯洛伐克\',\'Slovenia\':\'斯洛文尼亚\',\'Sweden\':\'瑞典\',\'Swaziland\':\'斯威士兰\',
\'Syria\':\'叙利亚\',\'Chad\':\'乍得\',\'Togo\':\'多哥\',\'Thailand\':\'泰国\',\'Tajikistan\':\'塔吉克斯坦\',\'Turkmenistan\':\'土库曼斯坦\',\'East Timor\':\'东帝汶\',
\'Trinidad and Tobago\':\'特里尼达和多巴哥\',\'Tunisia\':\'突尼斯\',\'Turkey\':\'土耳其\',\'Tanzania\':\'坦桑尼亚\',\'Uganda\':\'乌干达\',\'Ukraine\':\'乌克兰\',
\'Uruguay\':\'乌拉圭\',\'United States\':\'美国\',\'Uzbekistan\':\'乌兹别克斯坦\',\'Venezuela\':\'委内瑞拉\',\'Vietnam\':\'越南\',\'Vanuatu\':\'瓦努阿图\',\'West Bank\':\'西岸\',
\'Yemen\':\'也门\',\'South Africa\':\'南非\',\'Zambia\':\'赞比亚\',\'Zimbabwe\':\'津巴布韦\'
}
映射字典弄好后,就可以作图了
#用pyecharts库画全球疫情分布地图
import pandas as pd
from pyecharts.charts import Map,Geo
from pyecharts import options as opts
#自定义分段图例
pieces=[
{"max": 50000000, "min": 10000000, "label": ">1000万", "color": "#8B1A1A"},
{"max": 10000000, "min": 5000000, "label": "500万-1000万", "color": "#CD2626"},
{"max": 5000000, "min": 1000000, "label": "100万-500万", "color": "#EE2C2C"},
{"max": 1000000, "min": 100000, "label": "10万-100万", "color": "#FF3030"},
{"max": 100000, "min": 10000, "label": "10000-10万", "color": "#FA8072"},
{"max": 10000, "min": 1000, "label": "1000-10000", "color": "#FFF8DC"},
{"max": 1000, "min": 0, "label": "<500", "color": "#FFFFF0"},
]
name = []
values = []
# 导入数据
df_world = pd.read_csv("各国家的新冠肺炎疫情数据.csv")
df_china = pd.read_csv("各省的新冠肺炎疫情数据.csv")
# 因为爬取的全球数据不包括中国,所以要把中国的数据加进去
china_data = sum(df_china[\'累计确诊\'])
values.append(china_data)
name.append(\'中国\')
# 处理数据,将数据处理成Map所要求的数据
for i in range(df_world.shape[0]): # shape[0]:行数,shape[1]:列数
name.append(df_world.at[i,\'名称\'])
values.append(str(df_world.at[i,\'累计确诊\']))
total = [[name[i],values[i]] for i in range(len(name))]
world_map = (Map())
#设置地图为世界地图、设置中文国家名、设置不显示国家首都红点
world_map.add("确诊人数",total ,maptype="world",name_map=nameMap,is_map_symbol_show=False)
#设置不显示国家名
world_map.set_series_opts(label_opts=opts.LabelOpts(is_show=False))
world_map.set_global_opts(
# 标题
title_opts=opts.TitleOpts(title="全球各个国家新冠肺炎确诊人数"),
#设置自定义分段图例
visualmap_opts=opts.VisualMapOpts(max_=50000000,is_piecewise=True,pieces=pieces),
legend_opts=opts.LegendOpts(is_show=False)
)
# 直接在notebook显示地图,默认是保存为html文件
world_map.render_notebook()
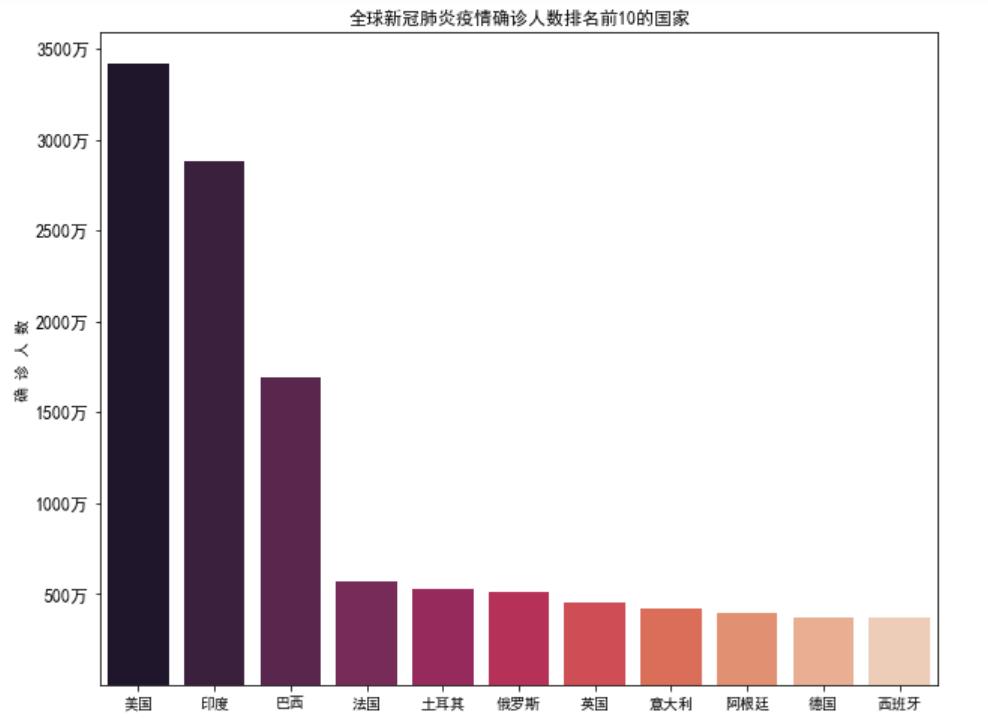
(7)全球新冠肺炎疫情确诊人数排名前10的国家的条形图
# 全球新冠肺炎疫情确诊人数排名前10的国家
import seaborn as sns
import matplotlib.pyplot as plt
import pandas as pd
#画布大小
fig=plt.figure(figsize=(10,8))
ax=fig.add_subplot(1,1,1)
#中文字体
plt.rcParams[\'font.family\'] = [\'SimHei\']
#导入数据
df_world = pd.read_csv("各国家的新冠肺炎疫情数据.csv")
sns.barplot(x = df_world.iloc[0:11,0].values,y =df_world.iloc[0:11,2].values,palette="rocket")
#y轴刻度标签
ax.set_yticks([5000000,10000000,15000000,20000000,25000000,30000000,35000000])
ax.set_yticklabels(["500万","1000万","1500万","2000万","2500万","3000万","3500万"],fontsize=12)
#标题
plt.title("全球新冠肺炎疫情确诊人数排名前10的国家",fontsize=12)
#y轴标签
plt.ylabel("确 诊 人 数")
plt.show()
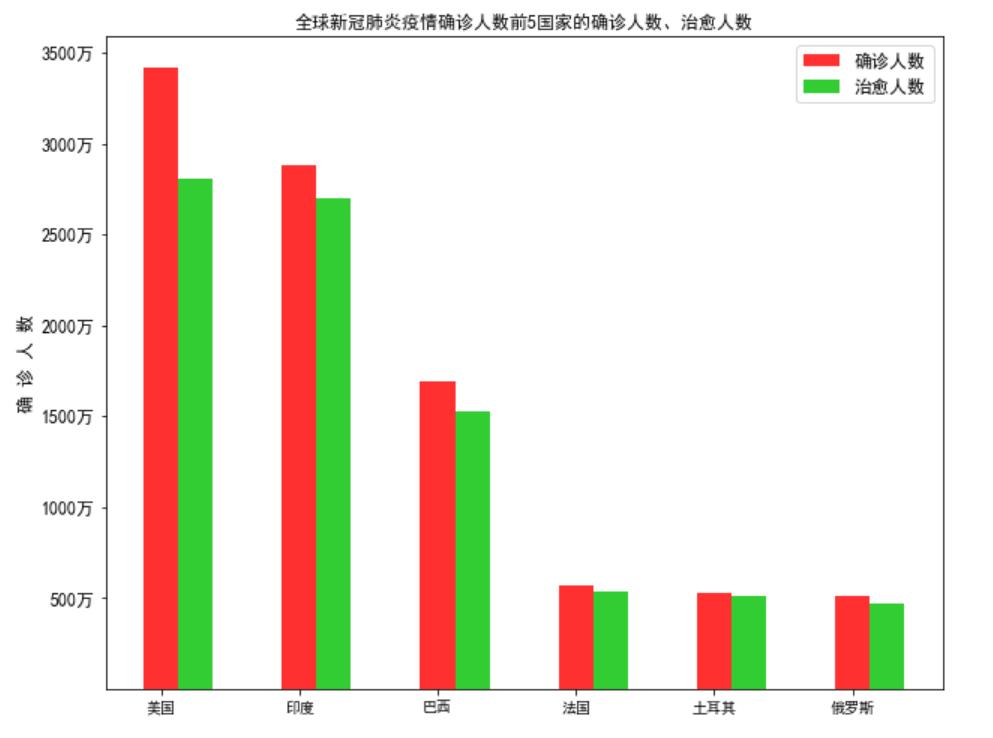
(8)全球新冠肺炎疫情确诊人数前5国家的确诊人数、治愈人数的条形图
import matplotlib.pyplot as plt
#画布大小
fig=plt.figure(figsize=(10,8))
ax=fig.add_subplot(1,1,1)
#中文字体
plt.rcParams[\'font.family\'] = [\'SimHei\']
#导入数据
df_world = pd.read_csv("各国家的新冠肺炎疫情数据.csv")
#国家
country = df_world.iloc[0:6,0]
#确诊人数
diagnosis = df_world.iloc[0:6,2]
#治愈人数
cured = df_world.iloc[0:6,3]
x = list(range(len(country)))
#设置间距
total_width, n = 0.5, 2
width = total_width / n
#柱状图1
for i in range(len(x)):
x[i] += width
plt.bar(x, diagnosis, width=width, label=\'确诊人数\', tick_label=country,color=\'#FF3030\' )
#柱状图2
for i in range(len(x)):
x[i] += width
plt.bar(x, cured, width=width, label=\'治愈人数\',color=\'#32CD32\')
#y轴刻度标签
ax.set_yticks([5000000,10000000,15000000,20000000,25000000,30000000,35000000])
ax.set_yticklabels(["500万","1000万","1500万","2000万","2500万","3000万","3500万"],fontsize=12)
#标题
plt.title("全球新冠肺炎疫情确诊人数前5国家的确诊人数、治愈人数")
#y轴标签
plt.ylabel("确 诊 人 数",fontsize=12)
#图例
plt.legend(loc=\'upper right\',fontsize=12)
plt.show()
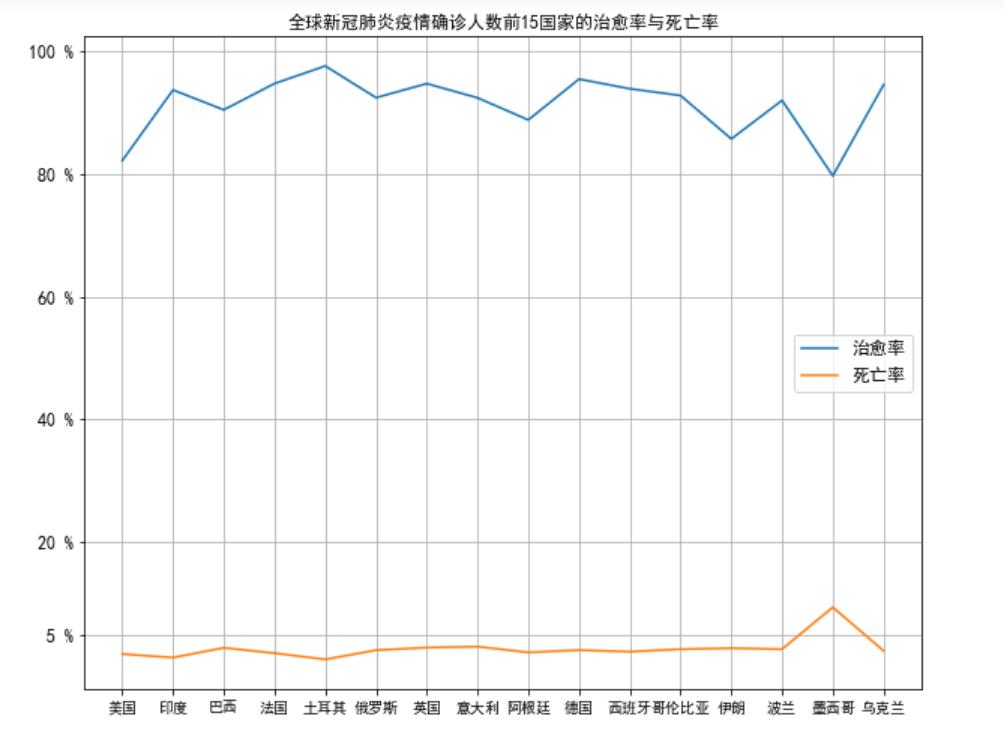
(9)全球新冠肺炎疫情确诊人数前15国家的治愈率与死亡率的折线图
import pandas as pd
import matplotlib.pyplot as plt
# 创建画布
fig=plt.figure(figsize=(10,8))
ax=fig.add_subplot(1,1,1)
#中文字体
plt.rcParams[\'font.family\'] = [\'SimHei\']
#导入数据
df_world = pd.read_csv("各国家的新冠肺炎疫情数据.csv")
df_world[\'治愈率\'] = df_world[\'治愈\']/df_world[\'累计确诊\']
df_world[\'死亡率\'] = df_world[\'死亡\']/df_world[\'累计确诊\']
plt.plot(df_world.iloc[0:16,0],df_world.iloc[0:16,5],label="治愈率")
plt.plot(df_world.iloc[0:16,0],df_world.iloc[0:16,6],label="死亡率")
#y轴刻度标签
ax.set_yticks([0.05,0.2,0.4,0.6,0.8,1.0])
ax.set_yticklabels(["5 %","20 %","40 %","60 %","80 %","100 %"],fontsize=12)
plt.legend(loc=\'center right\',fontsize=12)
plt.title("全球新冠肺炎疫情确诊人数前15国家的治愈率与死亡率")
plt.grid()
plt.show()
完整代码
疫情数据爬取的完整代码
import requests
from bs4 import BeautifulSoup
import pandas as pd
# 主函数
def main():
# 中国新冠疫情数据网址
url = "https://www.haoyunbb.com/news/3/36573.html"
html = getUrlData(url)
total_data1 = getProvinceData(html)
total_data2 = getCitiData(html)
# 全球(国外)新冠疫情数据网址
url = "https://www.haoyunbb.com/news/3/39230.html"
html = getUrlData(url)
total_data3 = getWorldData(html)
saveData(total_data1,total_data2,total_data3)
# 获取网页数据
def getUrlData(url):
try:
# get请求,设置超时时间
r = requests.get(url,headers=headers,timeout=30)
r.raise_for_status
r.encoding=r.apparent_encoding
html = r.text
return html
except:
return \'发生异常\'
# 获取中国每个省的疫情数据
def getProvinceData(html):
total_data=[]
temporary=[]
new_diagnosis_data=[]
cumulative_diagnosis_data=[]
cured_data=[]
dead_data=[]
soup = BeautifulSoup(html,\'html.parser\')
# 找到 class=data-list 的div标签
data = soup.find(\'div\',{\'class\':\'data-list\'})
ul = data.find(\'ul\')
div = ul.find_all(\'div\',{\'class\':\'list-pro-name\'})
province_name_data=[]
for i in div:
# 获取省的名称
# 省名称在label标签里
province_name = i.find(\'label\').string
province_name_data.append(province_name)
# 用CSS选择器获取第一层的数据(每个省的数据)
diagnosis = soup.select(\'div.data-list > ul > li > div.list-city-data\')
for i in diagnosis:
temporary.append(i.string)
total = [temporary[i:i+4] for i in range(0,len(temporary),4)]
for i in range(len(total)):
# 获取新增确诊人数
new_diagnosis_data.append(total[i][0])
# 获取累计确诊人数
cumulative_diagnosis_data.append(total[i][1])
# 获取治愈人数
cured_data.append(total[i][2])
# 获取死亡人数
dead_data.append(total[i][3])
total_data.append(province_name_data)
total_data.append(new_diagnosis_data)
total_data.append(cumulative_diagnosis_data)
total_data.append(cured_data)
total_data.append(dead_data)
return total_data
# 获取福建省每个市的疫情数据
def getCitiData(html):
citi_name_data=[]
new_diagnosis_data=[]
cumulative_diagnosis_data=[]
cured_data=[]
dead_data=[]
total_data=[]
soup = BeautifulSoup(html,\'html.parser\')
data = soup.find(\'div\',{\'class\':\'data-list\'})
# 找到有唯一标识的属性的input标签
input1 = data.find(\'input\',{\'id\':\'_209\'})
# 找到input标签的的父标签
div = input1.parent
# 找到所有的li
li = div.find_all(\'li\')
# 遍历li组成的列表
for i in range(1,len(li)):
# 获取市名称
citi_name = li[i].find(\'div\',{\'class\':\'list-city-name\'})
citi_name_data.append(citi_name.string+\'市\')
div = li[i].find_all(\'div\',{\'class\':\'list-city-data\'})
# 获取新增确诊人数
new_diagnosis = div[0].string
new_diagnosis_data.append(new_diagnosis)
# 获取累计确诊人数
cumulative_diagnosis = div[1].string
cumulative_diagnosis_data.append(cumulative_diagnosis)
# 获取治愈人数
cured = div[2].string
cured_data.append(cured)
# 获取死亡人数
dead = div[3].string
dead_data.append(dead)
total_data.append(citi_name_data)
total_data.append(new_diagnosis_data)
total_data.append(cumulative_diagnosis_data)
total_data.append(cured_data)
total_data.append(dead_data)
return total_data
# 获取全球每个国家的疫情数据
def getWorldData(html):
country_name_data=[]
new_diagnosis_data=[]
cumulative_diagnosis_data=[]
cured_data=[]
dead_data=[]
total_data=[]
soup = BeautifulSoup(html,\'html.parser\')
data = soup.find(\'div\',{\'class\':\'data-list\'})
# 因为有两层li,我们需要的是第二层的li,所以可以通过CSS选择器来获取第二层的li
data_list = data.select(\'ul > li > div > div > ul > li\')
for i in range(12,len(data_list)-1):
div = data_list[i].find_all(\'div\')
# 获取国家名称
country_name = div[0].string
country_name_data.append(country_name)
# 获取新增确诊人数
new_diagnosis = div[1].string
new_diagnosis_data.append(new_diagnosis)
# 获取累计确诊人数
cumulative_diagnosis = div[2].string
cumulative_diagnosis_data.append(cumulative_diagnosis)
# 获取治愈人数
cured = div[3].string
cured_data.append(cured)
# 获取死亡人数
dead = div[4].string
dead_data.append(dead)
total_data.append(country_name_data)
total_data.append(new_diagnosis_data)
total_data.append(cumulative_diagnosis_data)
total_data.append(cured_data)
total_data.append(dead_data)
return total_data
# 保存数据
def saveData(total_data1,total_data2,total_data3):
df1 = data(total_data1)
df2 = data(total_data2)
df3 = data(total_data3)
# 将爬取的数据保存为csv文件
df1.to_csv("各省的新冠肺炎疫情数据.csv",encoding=\'utf-8\')
df2.to_csv("各市的新冠肺炎疫情数据.csv",encoding=\'utf-8\')
df3.to_csv("各国家的新冠肺炎疫情数据.csv",encoding=\'utf-8\')
def data(total_data):
df = pd.DataFrame({\'名称\':total_data[0],\'新增确诊\':total_data[1],\'累计确诊\':total_data[2],\'治愈\':total_data[3],\'死亡\':total_data[4]})
# 将名称列设置为索引列
df = df.set_index(\'名称\')
return df
# 程序入口
if __name__== "__main__":
main()
# 数据清洗与处理
#因为全球疫情的数据量较大,所以我们可以通过pandas库来查看数据是否有异常、缺失、重复
import pandas as pd
#导入数据
df_world = pd.read_csv("各国家的新冠肺炎疫情数据.csv")
# 查看数据的简要信息
# 通过查看数据的简要信息,数据正常,数据的最小值也不是负数
df_world.describe()
# 查看是否有空值,有空值返回True,没有空值返回False
df_world.isnull().value_counts()
# 查看是否有重复行,有重复行返回True,没有重复行返回False
df_world.duplicated()
#根据累计确诊人数对数据进行降序排序
df = df_world.sort_values(by=\'累计确诊\',ascending=False)
#保存处理后的数据
import pandas as pd
df = df.set_index(\'名称\')
df.to_csv("各国家的新冠肺炎疫情数据.csv",encoding=\'utf-8\')
df_world = pd.read_csv("各国家的新冠肺炎疫情数据.csv")
df_world.head()
# 数据可视化
# 用pyecharts库画中国新冠疫情地图
from pyecharts import options as opts
from pyecharts.charts import Map
import pandas as pd
# 自定义分段图例
pieces=[
{"max": 70000, "min": 3000, "label": ">3000", "color": "#B40404"},
{"max": 3000, "min": 1000, "label": "1000-3000", "color": "#DF0101"},
{"max": 1000, "min": 100, "label": "100-1000", "color": "#F78181"},
{"max": 100, "min": 10, "label": "10-100", "color": "#F5A9A9"},
{"max": 10, "min": 0, "label": "<10", "color": "#FFFFCC"},
]
name = []
values = []
# 导入数据
df = pd.DataFrame(pd.read_csv("各省的新冠肺炎疫情数据.csv"))
# 处理数据,将数据处理成Map所要求的数据
for i in range(df.shape[0]): # shape[0]:行数,shape[1]:列数
name.append(df.at[i,\'名称\'])
values.append(str(df.at[i,\'累计确诊\']))
total = [[name[i],values[i]] for i in range(len(name))]
# 创建地图(Map)
china_map = (Map())
# 设置中国地图
china_map.add("确诊人数",total ,maptype="china",is_map_symbol_show=False)
china_map.set_global_opts(
# 设置地图标题
title_opts=opts.TitleOpts(title="中国各省、直辖市、自治区、特别行政区新冠肺炎确诊人数"),
# 设置自定义图例
visualmap_opts=opts.VisualMapOpts(max_=70000,is_piecewise=True,pieces=pieces),
legend_opts=opts.LegendOpts(is_show=False)
)
# 直接在notebook显示地图,默认是保存为html文件
china_map.render_notebook()
中国确诊人数前15地区的治愈率与死亡率折线图
import pandas as pd
import matplotlib.pyplot as plt
# 创建画布
fig=plt.figure(figsize=(10,8))
ax=fig.add_subplot(1,1,1)
#中文字体
plt.rcParams[\'font.family\'] = [\'SimHei\']
# 导入数据
df_china = pd.read_csv("各省的新冠肺炎疫情数据.csv")
df_china[\'治愈率\'] = df_china[\'治愈\']/df_china[\'累计确诊\']
df_china[\'死亡率\'] = df_china[\'死亡\']/df_china[\'累计确诊\']
plt.plot(df_china.iloc[0:16,0],df_china.iloc[0:16,5],label="治愈率")
plt.plot(df_china.iloc[0:16,0],df_china.iloc[0:16,6],label="死亡率")
# y轴刻度标签
ax.set_yticks([0.05,0.2,0.4,0.6,0.8,1.0])
ax.set_yticklabels(["5 %","20 %","40 %","60 %","80 %","100 %"],fontsize=12)
# 图例
plt.legend(loc=\'center right\',fontsize=12)
# 标题
plt.title("中国确诊人数前15地区的治愈率与死亡率")
# 网格
plt.grid()
plt.show()
# 中国确诊人数前15地区的新增确诊人数折线图
import pandas as pd
import matplotlib.pyplot as plt
# 创建画布
fig=plt.figure(figsize=(10,8))
#中文字体
plt.rcParams[\'font.family\'] = [\'SimHei\']
#导入数据
df_china = pd.read_csv("各省的新冠肺炎疫情数据.csv")
plt.plot(df_china.iloc[0:15,0],df_china.iloc[0:15,1],label="新增确诊")
# 图例
plt.legend(fontsize=12)
# 标题
plt.title("中国确诊人数前15地区的新增确诊人数")
# y轴标签
plt.ylabel(\'人数\')
# 网格
plt.grid()
plt.show()
#用pyecharts库画福建疫情分布地图
import pandas as pd
from pyecharts.charts import Map,Geo
from pyecharts import options as opts
#自定义分段图例
pieces=[
{"max": 100, "min": 70, "label": ">70", "color": "#B40404"},
{"max": 70, "min": 40, "label": "40-79", "color": "#DF0101"},
{"max": 40, "min": 20, "label": "20-40", "color": "#F78181"},
{"max": 20, "min": 10, "label": "10-20", "color": "#F5A9A9"},
{"max": 10, "min": 0, "label": "<10", "color": "#FFFFCC"},
]
name = []
values = []
#导入数据
df_citi = pd.read_csv("各市的新冠肺炎疫情数据.csv")
# 处理数据,将数据处理成Map所要求的数据
for i in range(df_citi.shape[0]): # shape[0]:行数,shape[1]:列数
name.append(df_citi.at[i,\'名称\'])
values.append(str(df_citi.at[i,\'累计确诊\']))
total = [[name[i],values[i]] for i in range(len(name))]
# 创建地图
chinaciti_map = (Map())
# 设置福建省地图
chinaciti_map.add("确诊人数",total ,maptype="福建",is_map_symbol_show=False)
chinaciti_map.set_global_opts(
# 地图标题
title_opts=opts.TitleOpts(title="福建各市新冠肺炎确诊人数"),
# 设置自定义图例
visualmap_opts=opts.VisualMapOpts(max_=100,is_piecewise=True,pieces=pieces),
legend_opts=opts.LegendOpts(is_show=False)
)
# 直接在notebook显示地图,默认是保存为html文件
chinaciti_map.render_notebook()
#福建省各市新冠疫情比例饼图
import matplotlib.pyplot as plt
import pandas as pd
# 创建画布
plt.figure(figsize=(6,4))
#中文字体
plt.rcParams[\'font.family\'] = [\'SimHei\']
#导入数据
df_citi = pd.read_csv("各市的新冠肺炎疫情数据.csv")
labels = df_citi[\'名称\'].values
data = df_citi[\'累计确诊\'].values
plt.pie(data ,labels=labels, autopct=\'%1.1f%%\')
#设置显示图像为圆形
plt.axis(\'equal\')
# 标题
plt.title(\'福建省各市新冠疫情比例\')
plt.show()
#用pyecharts库画全球疫情分布地图
import pandas as pd
from pyecharts.charts import Map,Geo
from pyecharts import options as opts
#自定义分段图例
pieces=[
{"max": 50000000, "min": 10000000, "label": ">1000万", "color": "#8B1A1A"},
{"max": 10000000, "min": 5000000, "label": "500万-1000万", "color": "#CD2626"},
{"max": 5000000, "min": 1000000, "label": "100万-500万", "color": "#EE2C2C"},
{"max": 1000000, "min": 100000, "label": "10万-100万", "color": "#FF3030"},
{"max": 100000, "min": 10000, "label": "10000-10万", "color": "#FA8072"},
{"max": 10000, "min": 1000, "label": "1000-10000", "color": "#FFF8DC"},
{"max": 1000, "min": 0, "label": "<500", "color": "#FFFFF0"},
]
name = []
values = []
# 导入数据
df_world = pd.read_csv("各国家的新冠肺炎疫情数据.csv")
df_china = pd.read_csv("各省的新冠肺炎疫情数据.csv")
# 因为爬取的全球数据不包括中国,所以要把中国的数据加进去
china_data = sum(df_china[\'累计确诊\'])
values.append(china_data)
name.append(\'中国\')
# 处理数据,将数据处理成Map所要求的数据
for i in range(df_world.shape[0]): # shape[0]:行数,shape[1]:列数
name.append(df_world.at[i,\'名称\'])
values.append(str(df_world.at[i,\'累计确诊\']))
total = [[name[i],values[i]] for i in range(len(name))]
world_map = (Map())
#设置地图为世界地图、设置中文国家名、设置不显示国家首都红点
world_map.add("确诊人数",total ,maptype="world",name_map=nameMap,is_map_symbol_show=False)
#设置不显示国家名
world_map.set_series_opts(label_opts=opts.LabelOpts(is_show=False))
world_map.set_global_opts(
# 标题
title_opts=opts.TitleOpts(title="全球各个国家新冠肺炎地图"),
#设置自定义分段图例
visualmap_opts=opts.VisualMapOpts(max_=50000000,is_piecewise=True,pieces=pieces),
legend_opts=opts.LegendOpts(is_show=False)
)
# 直接在notebook显示地图,默认是保存为html文件
world_map.render_notebook()
# 全球新冠肺炎疫情确诊人数排名前10的国家
import seaborn as sns
import matplotlib.pyplot as plt
import pandas as pd
#画布大小
fig=plt.figure(figsize=(10,8))
ax=fig.add_subplot(1,1,1)
#中文字体
plt.rcParams[\'font.family\'] = [\'SimHei\']
#导入数据
df_world = pd.read_csv("各国家的新冠肺炎疫情数据.csv")
sns.barplot(x = df_world.iloc[0:11,0].values,y =df_world.iloc[0:11,2].values,palette="rocket")
#y轴刻度标签
ax.set_yticks([5000000,10000000,15000000,20000000,25000000,30000000,35000000])
ax.set_yticklabels(["500万","1000万","1500万","2000万","2500万","3000万","3500万"],fontsize=12)
#标题
plt.title("全球新冠肺炎疫情确诊人数排名前10的国家",fontsize=12)
#y轴标签
plt.ylabel("确 诊 人 数")
plt.show()
import matplotlib.pyplot as plt
#画布大小
fig=plt.figure(figsize=(10,8))
ax=fig.add_subplot(1,1,1)
#中文字体
plt.rcParams[\'font.family\'] = [\'SimHei\']
#导入数据
df_world = pd.read_csv("各国家的新冠肺炎疫情数据.csv")
#国家
country = df_world.iloc[0:6,0]
#确诊人数
diagnosis = df_world.iloc[0:6,2]
#治愈人数
cured = df_world.iloc[0:6,3]
x = list(range(len(country)))
#设置间距
total_width, n = 0.5, 2
width = total_width / n
#柱状图1
for i in range(len(x)):
x[i] += width
plt.bar(x, diagnosis, width=width, label=\'确诊人数\', tick_label=country,color=\'#FF3030\' )
#柱状图2
for i in range(len(x)):
x[i] += width
plt.bar(x, cured, width=width, label=\'治愈人数\',color=\'#32CD32\')
#y轴刻度标签
ax.set_yticks([5000000,10000000,15000000,20000000,25000000,30000000,35000000])
ax.set_yticklabels(["500万","1000万","1500万","2000万","2500万","3000万","3500万"],fontsize=12)
#标题
plt.title("全球新冠肺炎疫情确诊人数前5国家的确诊人数、治愈人数")
#y轴标签
plt.ylabel("确 诊 人 数",fontsize=12)
#图例
plt.legend(loc=\'upper right\',fontsize=12)
plt.show()
import pandas as pd
import matplotlib.pyplot as plt
# 创建画布
fig=plt.figure(figsize=(10,8))
ax=fig.add_subplot(1,1,1)
#中文字体
plt.rcParams[\'font.family\'] = [\'SimHei\']
#导入数据
df_world = pd.read_csv("各国家的新冠肺炎疫情数据.csv")
df_world[\'治愈率\'] = df_world[\'治愈\']/df_world[\'累计确诊\']
df_world[\'死亡率\'] = df_world[\'死亡\']/df_world[\'累计确诊\']
plt.plot(df_world.iloc[0:16,0],df_world.iloc[0:16,5],label="治愈率")
plt.plot(df_world.iloc[0:16,0],df_world.iloc[0:16,6],label="死亡率")
#y轴刻度标签
ax.set_yticks([0.05,0.2,0.4,0.6,0.8,1.0])
ax.set_yticklabels(["5 %","20 %","40 %","60 %","80 %","100 %"],fontsize=12)
plt.legend(loc=\'center right\',fontsize=12)
plt.title("全球新冠肺炎疫情确诊人数前15国家的治愈率与死亡率")
plt.grid()
plt.show()
总结
因为这次的主题爬虫爬的是最基础的网站,所以进行的还是比较顺利的。在数据的可视化上,除了用pyecharts库的Map模块将数据显示到地图上花了一些功夫,其他都还好,达到了我的预期效果。
因为现在很多网站是用JSON存储数据或者用JS动态加载数据的,所以之后会多学习这些方面的知识。
以上是关于Python毕业设计 大数据招聘网站爬取与数据分析可视化 - flask的主要内容,如果未能解决你的问题,请参考以下文章