让预训练语言模型读懂数字:超对称技术发布 10 亿参数 BigBang Transformer [乾元]金融大规模预训练语言模型...
Posted AI科技大本营
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了让预训练语言模型读懂数字:超对称技术发布 10 亿参数 BigBang Transformer [乾元]金融大规模预训练语言模型...相关的知识,希望对你有一定的参考价值。

目录
1.通用大模型的缺陷
2.专注于融合训练时序-文本跨模态的预训练模型算法架构
3.学术和工业界覆盖最完整,规模最大的金融投资类数据集
4.创新的预训练方法可大幅提高语言模型准确度:Similarity Sampling 和Source Prompt
5.通用的时间向量表示组件DWT-ST2Vec可以连接不同模型
6.BBT-KG:动态追因的事理图谱
7.应用BBT大模型构建量化投资新因子,BBT模型助力多因子策略开发
8.Benchmark 评测数据集:首个中文金融NLP评测数据集
9.开发者服务:向金融和非金融行业开发者开放API,构建BBT大模型开发者生态
10.金融和经济领域的基石模型
超对称技术公司发布10亿参数金融预训练语言模型BigBang Transformer[乾元]。BBT大模型基于时序-文本跨模态架构,融合训练文本和时序两种模态数据,下游任务准确率较T5同级别模型提升近10%,并大幅提高时序预测的R2 score,跨模态架构能让语言模型识别时序数据的变化并通过人类语言来分析和阐述其发现。BBT模型可用于金融量化投资的因子挖掘,支撑多因子策略,以及广泛的数据可视化和物联网的时序数据分析等。BBT模型的目标是实现具备人类级别分析能力的预训练大模型,构建可在行业落地的通用人工智能架构。
1、通用大模型的缺陷
OpenAI的GPT-3,Google 的LaMDA, PaLM等千亿以上参数的语言模型和多模态大模型在写作,文字生成图片,对话等任务能接近乃至超越人类的智力水平。但是以上大模型有一些共同的缺陷。1. 大模型以通用的语料和数据进行预训练,在通用场景上表现良好,但是在专业领域有明显缺陷。所以GPT-3, 悟道,盘古等模型多用续写小说,写作诗歌,或者人机对话来展示大模型的能力。涉及到严肃的工作场景,则是只见打雷不见下雨。至今未见基于大模型在行业上的已经规模化应用的产品,背后的原因尚需进一步挖掘。仅用通用语料,未用行业数据进行预训练的大模型,其能力边界在哪里?如果超对称团队证明用行业数据训练的模型准确度更好,是否说明现有大模型的总体设计需要重新调整,才能获得大模型在不同行业的通用性?2 Dalle 2等预训练多模态模型在文字生成图像的应用取得惊人的效果,但是多模态模型在时序数据,表格文档数据等更实用更复杂的模态上进展不大,而这些模态占据了实际工作的大量场景。除了可以处理语言,语音,图像这三种常见模态,能读懂和分析数据也是人类智能的一种突出能力,而且人类能够并行处理语言,数据来获得结论。大模型是否也能实现人类智能对数据的分析能力,从而有效实现在工业场景的广泛应用。
超对称技术公司专注于开发算法和数据产品为金融,媒体,生产制造等行业提供服务。超对称公司针对金融投资领域的应用设计和训练了一个大规模参数预训练语言模型Big Bang Transformer乾元(BBT),目前发布了Base 版本2.2亿参数和Large 版本 10亿参数。同超对称团队还针对金融行业的预训练模型发布了一套评测数据集BBT-FinCUGE,开源于Github。BBT模型参考T5的Encoder+Decoder结构,以融合处理NLU和NLG的下游任务。超对称团队整理了一套金融行业的数据集,建立了一个跨模态联合训练文本和时序数据的基于Transformer的架构。
大模型是通往Artificial General Intelligence (AGI) 的一条道路。超对称公司认为具备数据分析能力是实现AGI的基础之一。超对称技术公司联合复旦大学计算机学院肖仰华知识工场实验室,浙江大学徐仁军实验室,南开大学和北师大人工智能学院的老师,在基础理论,架构,算法实现三方面推动AGI底层算法的研发,构建AGI在产业应用的底座。该项研究获得甘肃高台“东数西算”项目和南京江苏软件园在算力基础设施上的支持。
以Google 的T5框架为参考基准,BBT模型的实验验证了以下几个结论:
1. 基于领域专业数据集预训练的大模型,比T5同级别参数模型平均下游任务准确率可以提高接近10%。
2. 不同下游任务的语料数据集比例对下游任务的准确度有影响。
3. 基于下游任务类别提供Source Prompt的提示学习能大幅提高下游任务的准确度。
4. BBT的时序模型进行多元时序预测,比普通的Transformer获得R2 score的大幅提升
5. 联合文本和时序数据数据进行训练,模型能读懂数字变化所对应的真实世界。
2、专注于融合训练时序-文本跨模态的预训练模型算法架构
传统的时序模型往往仅依赖时序本身的信息完成各种任务,而忽略了时序数据对外部信息的依赖。例如某一时刻股价、经济指标等数据的波动并不完全由这一时刻前的数据决定。语言模型具有强大的表征文本信息的能力,将语言模型与时序模型结合,既可以使得世界信息能够以文本的形式支撑时序任务的完成,又可以通过时序数据中包含的信息强化语言模型对信息的理解能力。为此超对称团队设计了基Transformer的时序-文本跨模态预训练模型,这是业内最早的专注于联合训练时序-文本二模态的预训练算法架构之一。预训练方式为通过T时刻前的文本信息和时序信息对T时刻的时序数据进行预测。时序数据和文本图像数据同时作为Embedding层输入Encoder一个双向的Transformer,输出向量进入的Decoder有NLU,NLG,Time Series三类。
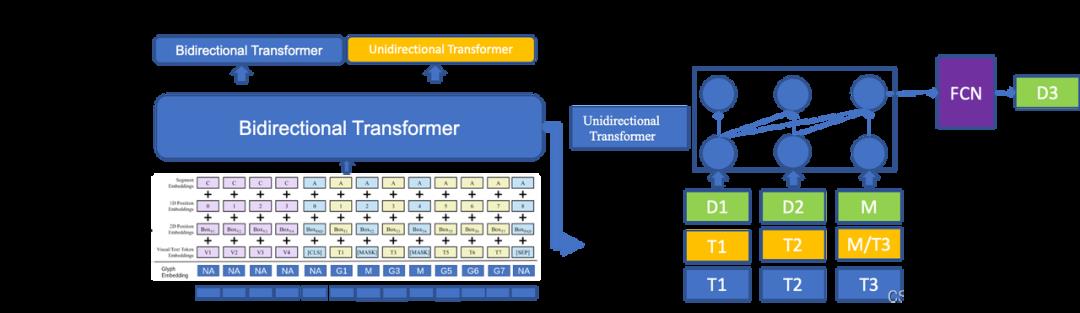
BBT模型设计了一个通用的将时间向量化输入Embedding层的模块。多元时间序列受到空间维度与时间维度两方面信号脉冲的影响,其被激活的时间、空间范围是一个连续的频谱,可大致分为低频局部脉冲、低频全局脉冲、高频局部脉冲和高频全局脉冲四方面分析这种影响。其中,“低频”/“高频”是指从时间视图描述了影响的激活范围,而“全局”/“局部”从空间视图描述了激活范围。“低频”即脉冲变化平稳,倾向于在较长时间内保持稳定;“高频”即脉冲变化剧烈;“全局”是指这种脉冲对所有时间序列产生类似的影响;“局部”是指脉冲只影响单个的时间序列,或对不同的时间序列施加不同的影响。基于此,超对称提出一种通用的、模型无关的、可学习的向量时间表示组件DWT-ST2Vec,可适用于多种模型结构与下游任务。该组件可从时空两个维度对序列的高频、低频分量进行分解,从而更加充分学习序列信息。
3、学术和工业界覆盖最完整,规模最大的金融投资类数据集
语料库的质量、数量和多样性直接影响语言模型预训练的效果,现有的中文金融预训练语言模型,例如FinBERT与英伟达发布的FinMegatron,其预训练语料在数量和多样性上十分有限。为了更好地推进中文金融自然语言处理(NLP)的发展,超对称搜集和爬取了几乎所有公开的和其他手段可以获得的中文金融语料数据,包括过去20年所有主流媒体平台发布的财经政治经济新闻,所有上市公司公告和财报,上千万份研究院和咨询机构历史上发布的所有研究报告,百万本金融经济政治等社会科学类书籍,40多个政府部位网站和地方政府网站的公告和文档,社交媒体平台用户发帖,从中清洗和整理了大规模中文金融语料库BBTCorpus,涵盖五大类别共300多GB,800亿Token的高质量多样化语料数据,是目前市面上覆盖最完整,规模最大的金融投资类数据集,具体的规模分布如表1所示。

表1:BBTCorpus语料大小分布,其中上市公司公告与研究报告的原始文件为PDF格式
4、创新的预训练方法可大幅提高语言模型准确度:Similarity Sampling 和Source Prompt
为了验证领域语料预训练的有效性,超对称团队使用在通用语料库CLUECorpus-samll上进行预训练的模型t5-v1_1-base-chinese-cluecorpussmall与超对称团队的模型进行对比,实验结果如表2所示。
超对称团队针对具体问题对T5的预训练方式做出了创新性的改进。首先是针对预训练语料采样问题提出的语料来源相似度加权采样算法。由于超对称团队的语料库十分庞大,以至于在模型预训练的全过程中也只能采样约百分之十的文本进行训练,因此模型势必要对不同来源的语料进行随机采样。如果对所有语料进行简单随机采样,则事实上是对不同来源的语料按大小规模进行混合,即在模型进行预训练的语料子集中,公告:研报:新闻:股吧:雪球的比例约为105:11:30:74:44。超对称团队提出,相对于单纯的简单随机采样,按照评测基准中的文本与不同来源的语料的相似度进行加权采样是更加合理的选择。经过加权平均采样的语料库子集训练出的模型在评测基准上平均能取得0.7%的提升。实验结果如表2所示。这一创新点不仅适用于金融领域语言模型的预训练工作,它的思想同样可以推广到其他具备多种异质语料来源的领域,例如生物医药,法律等领域。之后,在此基础上,超对称团队进一步把模型规模扩充到十亿参数的Large级别,实验结果如表2所示。
模型 | 成绩 |
T5-base | 67.93 |
BBT-base | 71.04 |
BBT-base-ss | 71.76 |
BBT-large-ss | 73.59 |
表2:成绩为模型在评测基准上的平均成绩。T5-base代表t5-v1_1-base-chinese-cluecorpussmall。ss代表我们的首个创新点语料来源相似度加权采样算法(Similarity weighted Sampling of corpus source)。base模型的参数量均为2.2亿,large模型的参数量为10亿。
超对称团队又针对异质语料混合的问题开创性的提出了来源提示方法(Source Prompt,SP),即在预训练时,语料前放置一个代表其来源的提示。
对于语料:“据国家统计局消息,2022年5月份,全国居民消费价格同比上涨2.1%。” 预训练时在其前部放置来源提示:【新闻】 变为:“【新闻】据国家统计局消息,2022年5月份,全国居民消费价格同比上涨2.1%。”, 之后正常进行MLM预训练 。Source Prompt在Base 模型中在Similarity Sampling模型的基础上提高3.21%。
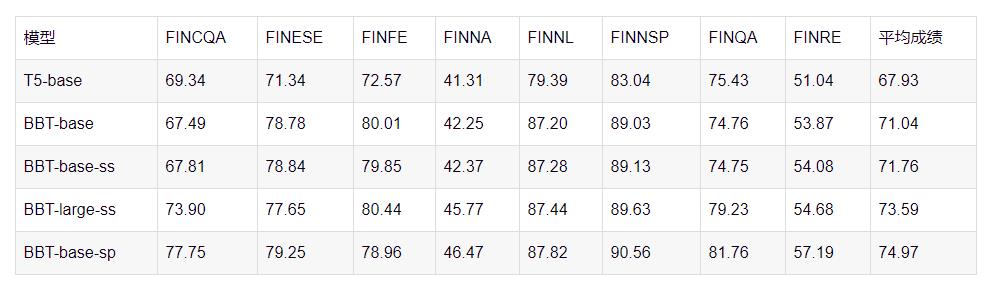
表3:T5-base 和BBT不同模型在8个下游任务的表现
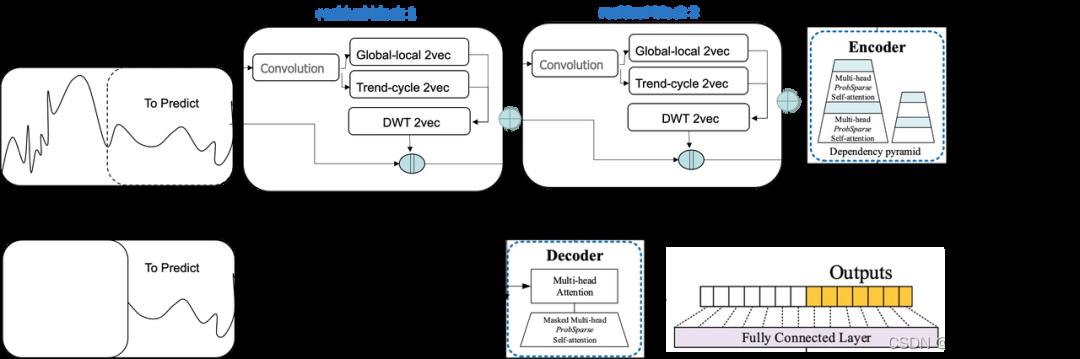
5、通用的时间向量表示组件DWT-ST2Vec可以连接不同模型
BBT模型对时序数据进行处理的基本能力包括:
提供了一种通用的、与模型无关的、可学习的向量时间表示组件DWT-ST2Vec,使得我们能够将时间作为Embedding输入Encoder,与文本联合学习
可以实现准确度更高的多元时间序列预测
可将时序数据按照“全局-局部”、“周期-趋势” “低频-高频”进行分解
通过与文本的融合学习,大模型可以针对时序数据变化生成文字
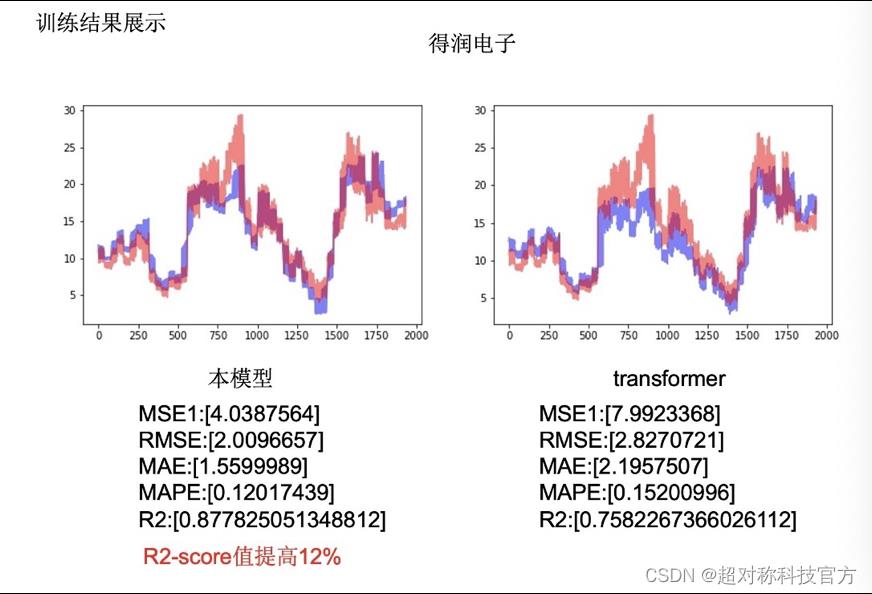
随机选取40家国内上市公司,以开盘股价的时间序列为主要评测对象,以股票开盘以来长度为4000的序列数据为训练集,以4000-4200的序列数据为测试集进行训练。以测试集的MSE,RMSE,MAE,MAPE指标加总为评测指标。以Transformer为基线,训练出的模型在评测基准上,在MSE,RMSE,MAE,MAPE上有平均0.5%-2%的提升。
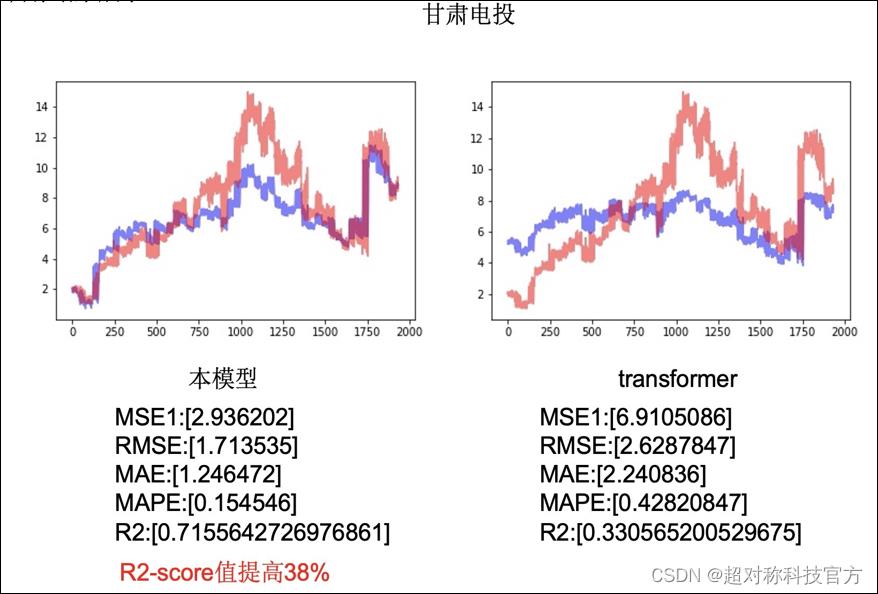
BBT的时序-文本的跨模态架构能够通过辨识股价变化,触发NLU的能力,生成类似分析师和散户投资者的评论 。
输入股价

模型能基于所学习的海量新闻,写出类似专业新闻记者一样的评论:


也能像散户投资者一样谈论市场趋势:


BBT时序-文本跨模态架构,能实现让模型来阅读公司的财报和新闻来写出一篇公司发展趋势分析报告,也能让模型学习品牌在电商平台的多年销售数据和产品特性,来预测产品未来销售量进而写出针对性市场营销报告,或者让模型学习制造业生产机器的监控数据,写出非专业人员也能懂的运维故障报告。
6、BBT-KG:动态追因的事理图谱
超对称团队构建了中国20万一级市场公司和4500家A股上市公司的知识图谱,用于知识增强的语言模型学习。BBT-KG与市面上的金融知识图谱不同在于,超对称团队通过语言模型的能力,构建了动态的新闻事件和企业之间的关联关系和事件之间的因果关系,从而让模型具备能力判断新发生的事件对公司和市场的影响,并对市场波动追因溯源。
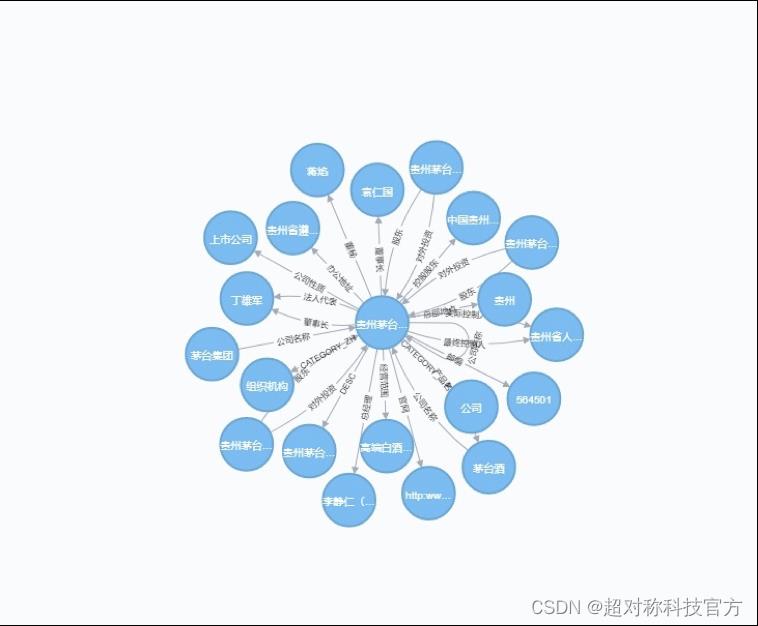
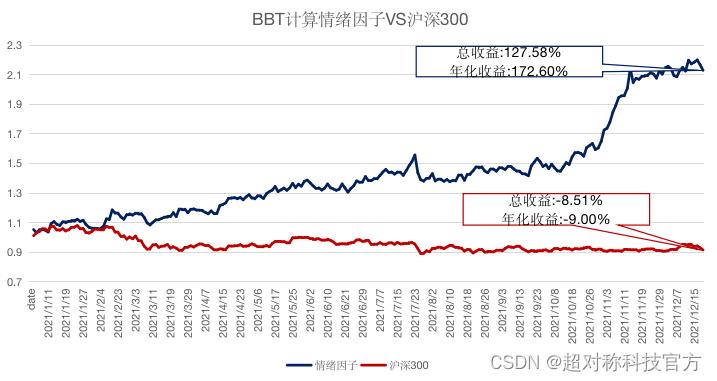
7、应用BBT大模型构建量化投资新因子,BBT模型助力多因子策略开发
超对称团队应用BBT模型计算个股的情绪指数,再监测相邻时段的情绪变化,选取突出变化作为多空因子构建量化因子策略,最终收益远超市场。超对称团队回溯情绪指数杰出的选股能力,发现模型能有效地学习金融财经类文本,并量化地反应市场的信息,创造性地提供另类因子。除了计算市场情绪,BBT模型拥有的多维度能力也同样可以运用在财经金融领域。例如利用BBT的事件抽取能力,可以抽取出同类事件或新闻与量价数据做对照,以研究不同事件传导到市场速度的快慢;BBT还可以通过超对称团队独有的金融知识图谱学习供应链中经济个体间的相互关系,以机器学习的方法来消除因子间的共线性,为传统线性回归多因子模型为传统线性回归多因子模型带来颠覆性创新;除此之外,BBT的负面消息识别能力还可以为信用风险评估体系增加实时舆情监控,新闻分类能力更是能帮助财务分析师和金融分析师快速处理大量信息,以获得更全面客观的结论。
8、Benchmark 评测数据集:首个中文金融NLP评测数据集
评测基准对自然语言处理(NLP)的发展起着重要的指导作用,而在中文金融NLP的研究与应用蓬勃发展的同时,业界缺少一个权威的评测基准。为了解决这个问题,超对称团队提出了BBT-FinCUGE,开源地址GitHub.com/ssymmetry/BBT-FinCUGE-Application 。这是一个中文金融自然语言理解和生成评测基准,具有以下特点:(1)专业性:所有数据集的筛选和标记工作都有金融专家的参与。(2) 实用性:所有任务均由金融专家进行实用性评分,作为任务选择和最终评分的依据。评测基准共包含以下八个数据集:
(1)论坛情绪分析FinFE
在股吧和雪球等股民论坛中,股民们每天会产出海量的评论文本,其中包含有感性的情感输出和理性的涨跌预测等内容。针对这些文本,该数据集要求模型学习并预测文本的情绪指数(0、1、2,分别代表消极、中性和积极)
(2)事件抽取FinQA
事件抽取是指自动从文本中识别事件的发生,抽取事件参数并整理成结构化数据的算法,包括企业投融资、上市、收购等事件的检测和参数抽取。(为了更好的横向对比不同的模型,我们将该数据集整理为阅读理解问答(QA)的形式)
(3)因果事件抽取FinCQA
与常规事件抽取不同,因果事件抽取专注于在文本中识别出具有因果关系的两个事件及其事件参数,并将其整理为机构化数据。我们的因果事件数据集包含对大宗商品领域的因果事件识别,识别的事件类型包括台风/地震,供给增加/减少,需求增加/减少,价格上升/下降等可能为原因和结果事件及其对应关系和对应的产品、地区等参数 。(为了更好的横向对比不同的模型,我们将该数据集整理为阅读理解问答(QA)的形式)
(4)新闻文本摘要FinNA
中文金融新闻摘要生成任务。该数据集取自于新浪财经的大规模中文短新闻,包含了20000条真实的中文短文本数据和对应的摘要。
(5)关系抽取FinRE
一个人工精标注的财经金融领域的数据集。给定句子和其中的头尾实体,要求模型预测头尾实体之间的关系。该数据集由新浪财经新闻语料标注得到,其中命名实体为商业公司,在关系上设计了44个金融领域的关系类别(双向),包含拥有、持股、竞争、收购、交易、合作、减持等财经金融领域的特有关系类别。
(6)负面消息识别及主体判定FinNSP
本数据集包含两个任务:
负面信息判定:判定该文本是否包含金融实体的负面信息。如果该文本不包含负面信息,或者包含负面信息但负面信息未涉及到金融实体,则负面信息判定结果为0。
负面主体判定:如果任务1中包含金融实体的负面信息,继续判断负面信息的主体对象是实体列表中的哪些实体。
(7)新闻分类FinNL
把金融新闻分类为一个或多个与其描述内容相关的类别。新闻采样于新浪财经,目前共有公司(个股)、行业(板块)、大盘、中国、国际、经济、政策、期货、债券、房地产、外汇、虚拟货币、新冠、能源等14个类别 。
(8)事件主体抽取
本评测任务的主要目标是从真实的新闻语料中,抽取特定事件类型的主体。即给定一段文本T,和文本所属的事件类型S,从文本T中抽取指定事件类型S的事件主体。即输入:一段文本,事件类型S;输出:事件主体
9、开发者服务:向金融和非金融行业开发者开放API,构建BBT大模型开发者生态
超对称团队面向金融和非金融行业的开发者开放11项API能力,建设BBT大模型开发者生态。第一批开放的API能力包括:文章摘要,社交媒体情绪识别,新闻情绪识别,新闻分类标签,命名实体识别,关系抽取,事件抽取,事件因果抽取,公告抽取,负面消息和主体识别。
API文档:https://www.ssymmetry.com/newproduct/bbtlink
10、金融和经济领域的基石模型
BBT 1.0版本模型的目标是为金融投资建立统一的人工智能算法框架,基于transformer构建能融合训练金融投资涉及的不同模态数据的架构。在统一架构的基础上训练大规模参数预训练模型,随着模型参数和训练数据集继续增大,超对称团队有希望开发出在金融领域接近人类智能水平的模型。作为金融领域的基石模型,BBT模型为所有金融投资,经济分析,商业咨询等场景的深度学习下游任务提供微调服务。金融投资领域有大量从业机构和人员,大厂有财力雇佣算法工程师,小团队却用不起基本的文本抽取算法。BBT模型作为金融领域的算法基础设施,让所有从业者配备同级别的武器,让全行业站在同一起跑线去竞争更优的投资策略,从而推动金融和经济市场更高效的信息和要素流动。
让模型读懂数字,是BBT模型专注开发的一种时序-文本跨模态架构的能力,这是人类追求的通用人工智能的最核心能力之一。模型能在海量时序数据中识别出变化的模式和规律,并通过预训练语言大模型将其与现实世界准确对应,从而在数据世界和人类语言世界建立起桥梁,将会给更广泛的数字化技术带来革命,包括商业数据分析,数据可视化,数据库技术等。BBT模型不仅可以应用于金融,在时序数据处理需求为主的生产制造,物联网,智慧城市,互联网大数据分析都有应用的潜力。

CSDN音视频技术开发者在线调研正式上线!
现邀开发者们扫码在线调研


往期回顾
分享
点收藏
点点赞
点在看以上是关于让预训练语言模型读懂数字:超对称技术发布 10 亿参数 BigBang Transformer [乾元]金融大规模预训练语言模型...的主要内容,如果未能解决你的问题,请参考以下文章
看MindSpore加持下,如何「炼出」首个千亿参数中文预训练语言模型?
R语言caret包构建xgboost模型实战:特征工程(连续数据离散化因子化无用特征删除)配置模型参数(随机超参数寻优10折交叉验证)并训练模型