TIS的计算公式
Posted 无线认证x英利检测
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了TIS的计算公式相关的知识,希望对你有一定的参考价值。
根据读者的要求,本篇我们继续学习TIS的计算公式。我们知道TIS跟TRP是对应的,一个是接收机的总辐射灵敏度,一个是发射机的总辐射功率。在3GPP 5G NR无天线传导口的1-O基站以及1-O和2-O的基站/终端测量中,虽有TRP的要求,但却没有TIS的要求,仅要求EIS。那么目前真正有TIS测量需求的,是CTIA的终端OTA标准,以及3GPP关于5G NR FR1的OTA测试标准(正在制定过程中)。
01
—
TIS/TRS
对于TIS(Total Isotropic Sensitivity:总的各向同性的灵敏度),在3GPP中称为TRS(Total Radiated Sensitivity,总辐射灵敏度)。我们可以认为是同一种概念的两种表达。
在CTIA标准中,TIS的离散化公式如下所示:
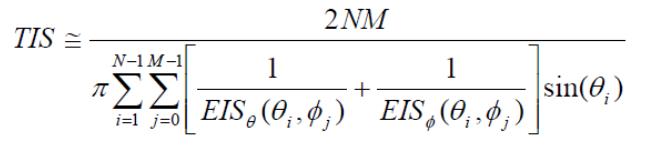
而3GPP 38.834中TRS的离散化公式也基本follow了CTIA标准:
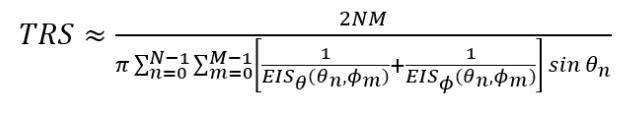
其中EIS是在每个方向和极化测量的辐射 effective isotropic sensitivity:有效各向同性灵敏度。相当于TRP计算公式中需测量的EIRP。N和M以及θ和ϕ 角,
同TRP中的定义是一样的。TRP的计算公式-1
1.TRP <==> TIS/TRS;
2.EIRP <==> EIS;
我们想当然地觉得TIS/TRS应该跟TRP是一样的,那为什么公式表达跟TRP有如此差别呢?TIS/TRS的积分计算形式为什么是倒数形式呢?是不是觉得TIS/TRS的公式应该类似TRP,是这样的?
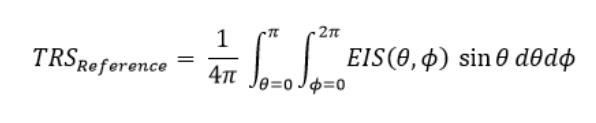
其实这本没有错,关键是我们在探寻两个极化的EISθ和EISϕ时,出现了问题。
如果我们在计算TRP的时候,将EIRP写成下式是理所当然的:
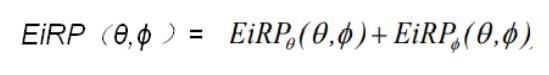
然而,如果我们将EIS也写成类似上面的式子,就大错特错了。
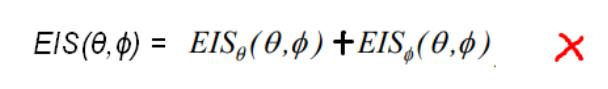
原因是:EIRP可以通过两个极化值线性功率相加求和的方式来计算,然而EIS与EIRP不同,EIS是BER,BLER,吞吐量...高于阈值的最小功率。比方说,当EIS接收到功率-80dBm时,计算出的误码率/吞吐量等符合要求。此时需要将功率继续降低至-81dBm,-82dBm,等等,直到BER,BLER,吞吐量等下降到阈值以下,记录此时的EIS的值,即为所需要的值。如果按照上面的公式来计算两个极化测到的EISθ和EISϕ,那么得出的结果必然是比那个较高的(也就是较差的灵敏度)的那个极化的EIS更高(或更差)。例如:
1.EISθ = -79.72 dBm;
2. EISϕ = -83.45 dBm;
3. 如果按照上面错误的公式计算,则
4. EIS = -78.19 dBm
显然不应该是我们所要的结论。
02
—
TIS的公式推导
但我们仍然可以借鉴TRP的公式对TIS进行改造,我们先来复习一下TRP的积分公式:
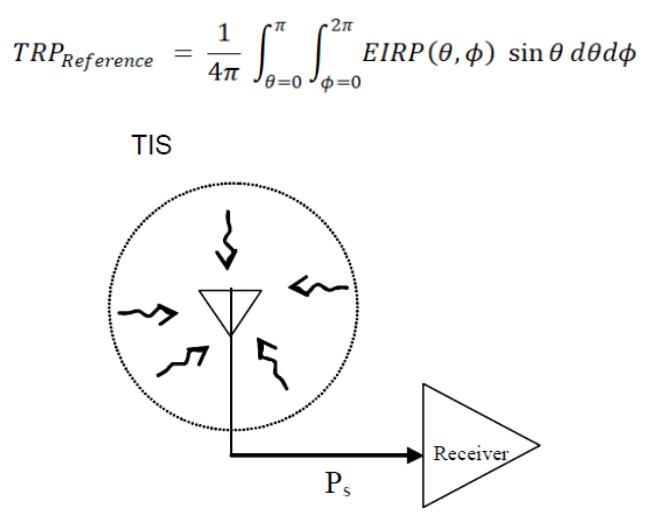
由上图,我们可以将EUT接收器的总灵敏度Ps用下面的积分公式来表示。可以将PTIS挪到积分运算里面,则PTIS与天线分别在(θ,ϕ)方向上的增益G相乘(dB相加)即为那个极化的EIS。所以从这个原则上说,TRS/TIS与TRP的公式形式是一致的。
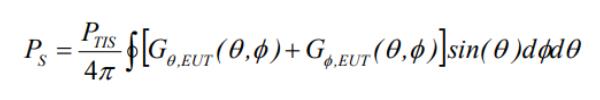
接下来我们可以将天线分别在(θ,ϕ)方向上的增益G替换成以下形式:Gx,EUT是EUT的天线在(θ,ϕ)方向上的相对各向同性增益(在极化x)。EISx(θ,ϕ)辐射灵敏度相当于在(θ,ϕ)方向上,在极化x输入的最小信号功率,这个功率能够满足BER,BLER,吞吐量等的最低性能标准。
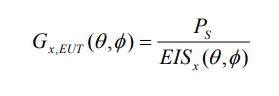
所以有下面的推导:
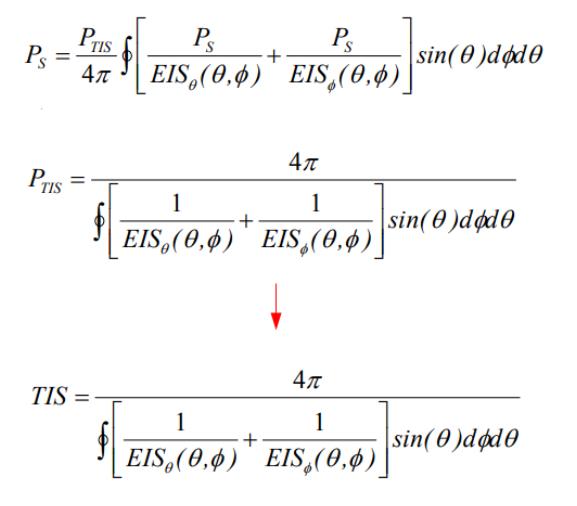
到了这一步,再进行离散化,参考TRP的计算公式-1中的结论,则得到:
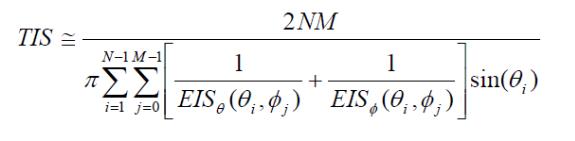
其实,如果天线效率为100%,则TIS=Ps。我们只是利用他们做了一个相互的推导,得到我们希望得到的结论。
TRP <==> TIS/TRS;EIRP <==> EIS;EISθ = -79.72 dBm;EISϕ = -83.45 dBm;如果按照上面错误的公式计算,则EIS = -78.19 dBm
以上信息由英利检测(Teslab)整理发布,欢迎一起讨论,我们一直在关注这方面的发展,如有引用也请注明出处。
国家高新技术企业;唯一覆盖中国和欧美运营商认证服务机构;业内最为优秀第三方认证服务商之一;专业的人做专业的事;
入库:┆移动┆联通┆电信┆中国广电┆
欧美:┆GCF┆PTCRB┆VzW┆ATT┆TMO┆FCC┆
中国:┆CCC┆SRRC┆CTA┆
号码:┆IMEI┆MAC┆MEID┆EAN┆
TIS教程-安装
简介
TIS(Triton Inference Server)是NVIDIA推出的AI模型部署框架,前身为ensorRT Inference Server,它支持多种深度学习框架作为backend(如TensorFlow、PyTorch、TensorRT、ONNX等)甚至可以集成多个backend,如下图所示,通过TIS部署的服务可以通过HTTP或者gRPC的方式请求。目前,PyTorch的模型部署其实还不是很完善,主流的部署框架其实就是TorchServe和Triton,相较于前者使用Java,我这边还是比较喜欢Triton一些,所以这个系列的核心就是利用Triton部署PyTorch模型。

安装
安装Triton之前必须确保显卡驱动正确安装,且已经成功安装docker和nvidia-docker,具体可以参考我之前的教程,因为后续的安装都需要基于docker来进行(也推荐采用这种方式)。
接下来,需要登录NVIDIA NGC以便于获取镜像的地址,不过这时并不能成功获取镜像,需要先获得API Key才能获取镜像,注册流程见下图。

注册后,使用下面的框中命令登录docker,登录成功后(会有Login Succeeded提示)。

接着,再访问TIS镜像地址获取镜像地址,并使用下图框中的命令拉取最新的镜像。当然,这个版本很新,对显卡驱动要求较高,我所用的机器的显卡驱动也才455版本,因此我这里使用旧版本,命令如下。

docker pull nvcr.io/nvidia/tritonserver:20.10-py3
此时也可以通过将镜像保存到本地以便使用,这是因为其实从nvidia官方下载这个镜像其实挺慢的。相关的命令如下。
# 保存镜像
docker save -o tritonserver-20.10-py3.tar nvcr.io/nvidia/tritonserver:20.10-py3
# 加载镜像
sudo docker load < tritonserver-21.07-py3.tar
运行
在运行镜像之前,我们按照官方的推荐建立一个模型仓库,该仓库中按照模型名存放着tensorrt engine文件,该文件夹有如下格式,具体如何设置配置文件后面的文章会提到(主要是模型配置文件和各个版本的模型文件,参考官方示例,这里的1指的就是版本1)。
model_repository/
└── inception_graphdef
├── 1
│ └── model.graphdef
├── config.pbtxt
└── inception_labels.txt
然后,我们运行可使用GPU的镜像并将模型仓库映射到容器中的根目录下的models文件夹中,命令如下,其中的命令均为docker常用命令(设置是使用本机第3号GPU卡),这里不多做赘述,可以查看我的Docker教程。
docker run --gpus '"device=3"' --rm -p8000:8000 -p8001:8001 -p8002:8002 -v/home/zhouchen/model_repository:/models nvcr.io/nvidia/tritonserver:20.10-py3 tritonserver --model-repository=/models
此时出现下图所示的状态,没有报ERROR代表服务开启成功。
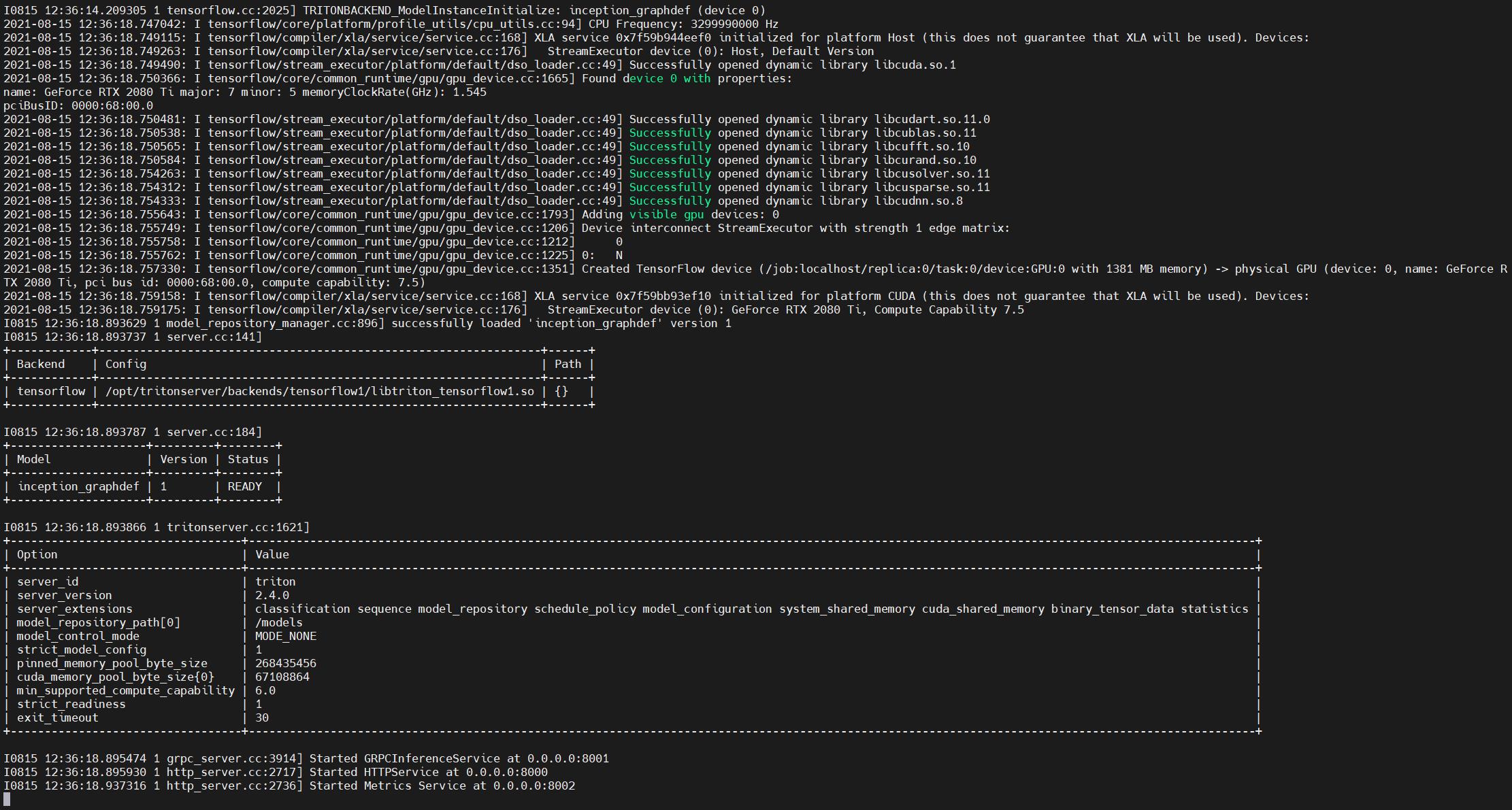
由于这时候后端还没有写具体的接口,这里调用默认接口测试一下,使用命令curl -v localhost:8000/v2/health/ready,有如下的反馈代表后端部署成功,可以正常访问。
* Trying 127.0.0.1...
* TCP_NODELAY set
* Connected to localhost (127.0.0.1) port 8000 (#0)
> GET /v2/health/ready HTTP/1.1
> Host: localhost:8000
> User-Agent: curl/7.58.0
> Accept: */*
>
< HTTP/1.1 200 OK
< Content-Length: 0
< Content-Type: text/plain
<
* Connection #0 to host localhost left intact
至此,初步TIS的部署就初步完成了。
总结
本文主要介绍了Triton Inference Server的安装教程,具体可以查看官方文档。
以上是关于TIS的计算公式的主要内容,如果未能解决你的问题,请参考以下文章