Python学习个人记录笔记
Posted watson_pillow
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python学习个人记录笔记相关的知识,希望对你有一定的参考价值。
目录
文件操作
创建目录
import os
if not os.path.exists('./tupians'):
os.mkdir('./tupians')
存储图片
imgData = data#二进制图片数据
with open('./tupians.jpg','wb') as fp:
fp.write(imgData)
循环
for pageNum in range(1,36):
print(pageNum)
#1,2,3...
arr = [1,1,2]
for a in arr:
print(a)
#1,1,2
正则表达式
import re
ex = '<div class="one-cont">.*?<img .*?data-src="(.*?)" alt.*?</div>'
imgSrc = re.findall(ex,response,re.S)
# .*? 非贪婪匹配任意字符
# re.S 和换行符有关貌似
requests
# 发起Get请求获取文本信息,连接地址为newUrl(字符串),请求头为headers(对象)
response = requests.get(url=newUrl,headers=headers).text
# 发起Get请求获取二进制流信息,连接地址为src(字符串),请求头为headers2(对象)
imgData = requests.get(url=src,headers=headers2).content
# 发起Post请求,请求数据为 data(对象)
response = requests.post(url=newUrl,headers=headers,data=data)
response.status_code#请求状态码,可以判断请求是否成功 200
# 设置cookie 请求头中自动自动加入Cookie字段
session = requests.Session()
session.post(url=url,headers=headers,data=data).text
# 代理ip
response = requests.get(url=url,headers=headers,proxies="https":"202.12.1.22").text
代理:www.goubanjia.com
xpath
属性包含
res = requests.get(url=linkPath,headers=headers).text
tree = etree.html(res)
links = tree.xpath('//div[contains(@class,"ws_block")]/a')
asyncio
import asyncio
async def request(url):
print('begin')
return 'over'
#async修饰的函数,调用之后返回一个协程对象
c = request('www.baidu.com')
#报错There is no current event loop python
loop = asyncio.new_event_loop()
asyncio.set_event_loop(loop)
#创建一个事件循环对象 报错There is no current event loop python,使用上面两句替换
#loop = asyncio.get_event_loop()
#将协程对象注册到loop中,然后启动loop
#loop.run_until_complete(c)
###task 创建task对象
##task = loop.create_task(c)
##print(task)
##
##loop.run_until_complete(task)
##print(task)
###future 创建future对象
##task = asyncio.ensure_future(c)
##print(task)
##
##loop.run_until_complete(task)
##print(task)
#绑定回调
def callbackFn(task):
print(task.result())
task = asyncio.ensure_future(c)
task.add_done_callback(callbackFn)
loop.run_until_complete(task)
print('all over')
报错:There is no current event loop
将下面一句:
loop = asyncio.get_event_loop()
替换成下面两句即可
loop = asyncio.new_event_loop()
asyncio.set_event_loop(loop)
多任务
import asyncio
import time
async def request(url):
print('begin',url)
await asyncio.sleep(2)
print('end',url)
start = time.time()
urls= ['www.baidu.com','www.souhu.com','www.sogou.com']
loop = asyncio.new_event_loop()
asyncio.set_event_loop(loop)
stasks = []
for url in urls:
c=request(url)
task = asyncio.ensure_future(c)
stasks.append(task)
#loop = asyncio.get_event_loop()
loop.run_until_complete(asyncio.wait(stasks))
stop = time.time()
print(stop-start)
带延时服务用例
from flask import Flask
import time
app = Flask(__name__)
@app.route('/walk')
def index_walk():
time.sleep(2)
return 'i walk'
@app.route('/say')
def index_say():
time.sleep(2)
return 'i say'
@app.route('/sing')
def index_sing():
time.sleep(2)
return 'i sing'
if __name__ =='__main__':
app.run(debug=True)
基于aiohttp的异步请求
import requests
import time
import asyncio
import aiohttp
start = time.time()
urls = ['http://127.0.0.1:5000/walk','http://127.0.0.1:5000/sing','http://127.0.0.1:5000/say']
async def getPage(url):
print('begin',url)
async with aiohttp.ClientSession() as session:
#使用post()发起post请求
#headers=headers,增加头;params,data同样;proxy='http://ip:port'
async with await session.get(url) as response:
pageText = await response.text() #read()返回二进制;json()返回json对象
print('over1',url)
#response = requests.get(url=url)
print('over2',url)
pool = asyncio.new_event_loop()
asyncio.set_event_loop(pool)
tasks=[]
for url in urls:
c = getPage(url)
task = asyncio.ensure_future(c)
tasks.append(task)
pool.run_until_complete(asyncio.wait(tasks))
end = time.time()
print(end-start)
begin http://127.0.0.1:5000/walk
begin http://127.0.0.1:5000/sing
begin http://127.0.0.1:5000/say
over1 http://127.0.0.1:5000/say
over2 http://127.0.0.1:5000/say
over1 http://127.0.0.1:5000/walk
over1 http://127.0.0.1:5000/sing
over2 http://127.0.0.1:5000/walk
over2 http://127.0.0.1:5000/sing
2.1247029304504395
selenium
下载浏览器驱动:http://chromedriver.storage.googleapis.com/index.html
对应关系:https://blog.csdn.net/huilan_same/article/details/51896672
示例
from selenium import webdriver
from time import sleep
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
s = Service('./chromedriver.exe')
bro = webdriver.Chrome(service = s)
bro.get('https://www.taobao.com/')
#标签定位
search_input = bro.find_element('id','q')
#标签交互
search_input.send_keys('IPhone')
#执行js程序
bro.execute_script('window.scrollTo(0,document.body.scrollHeight)')
sleep(2)
#点击搜索按钮
btn = bro.find_element(By.CSS_SELECTOR,'.btn-search')
btn.click()
bro.get('https://www.baidu.com')
sleep(2)
#后退
bro.back()
sleep(2)
#前进
bro.forward()
sleep(2)
sleep(5)
bro.quit()
iframe及拖拽
from selenium import webdriver
from selenium.webdriver import ActionChains
from time import sleep
s = webdriver.chrome.service.Service('./chromedriver.exe')
bro = webdriver.Chrome(service=s)
bro.get('https://www.runoob.com/try/try.php?filename=tryhtml5_draganddrop')
#切换作用域到iframe
bro.switch_to.frame('iframeResult')
div = bro.find_element('id','drag1')
print(div)
#动作链
action = ActionChains(bro)
#点击长按指定标签
#action.click_and_hold(div)
element = bro.find_element('id','div1')
print(element)
sleep(3)
action.drag_and_drop(div, element).perform()
##element = bro.find_element('id','div1')
##action.move_to_element(element).perform()
##for i in range(5):
## #perform()立即执行动作链操作
## action.move_by_offset(0,-5).perform()
## sleep(0.3)
#释放
action.release().perform()
sleep(1)
bro.quit()
没有成功,不知道什么原因
无可视化界面
from selenium import webdriver
from time import sleep
from selenium.webdriver.chrome.options import Options
#规避检测
from selenium.webdriver import ChromeOptions
option = ChromeOptions()
option.add_experimental_option('excludeSwitches',['enable-automation'])
chrome_options = Options()
chrome_options.add_argument('--headless')
chrome_options.add_argument('--disable-gpu')
#options
s = webdriver.chrome.service.Service('./chromedriver.exe')
#options = option
bro = webdriver.Chrome(service=s,options = chrome_options)
#无头浏览器
bro.get('https://www.baidu.com')
print(bro.page_source)
sleep(2)
bro.quit()
超级鹰:
注册用户,充值,创建软件,下载示例
www.chaojiying.com/about.html
截图
from selenium import webdriver
from time import sleep
from selenium.webdriver.common.by import By
s = webdriver.chrome.service.Service('./chromedriver.exe')
bro = webdriver.Chrome(service = s)
#bro.get('https://kyfw.12306.cn/otn/login/init')
bro.get('https://www.sina.com.cn/')
bro.save_screenshot('aa.png')
#imgEle= bro.find_element('class','hxjzg')
#imgEle= bro.find_element(By.XPATH,'/html/body/div[12]/div/a[2]')
#imgEle.save_screenshot('bb.png')
sleep(4)
bro.quit()
scrapy
安装:
- pip install wheel
- 下载twisted ,地址:https://www.lfd.uci.edu/~gohlke/pythonlibs/#twisted
- 安装twisted:pip install Twisted-…whl
- pip install pywin32
- pip install scrapy
新建工程
安装时没有添加到环境变量,找到路径执行C:\\Users\\admin\\AppData\\Roaming\\Python\\Python310\\Scripts
新建工程执行:scrapy startproject helloscrapy(C:\\Users\\admin\\AppData\\Roaming\\Python\\Python310\\Scripts\\scrapy.exe startproject helloscrapy)
新工程目录结构:
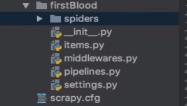
(原来插入图片的水印是可以去除的)
增加py文件
cd到firstBlood中执行命令:scrapy genspider spiderName wwww.xxx.com(C:\\Users\\admin\\AppData\\Roaming\\Python\\Python310\\Scripts\\scrapy.exe genspider spiderName wwww.xxx.com)
就会在spiders中创建一个名为 spiderName.py 的文件。
这里把spiderName换乘first后执行:
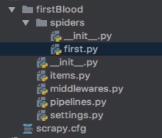
first.py内容
import scrapy
class FirstSpider(scrapy.Spider):
#爬虫文件的名称:就是爬虫源文件的唯一标识
name = "first"
#允许的域名:用来限定start_urls列表中哪些url可以进行请求发送,可注释
allowed_domains = ["www.xxx.com"]
#起始url列表:该列表中存放的url会被scrapy自动进行请求发送
start_urls = ["http://www.xxx.com/"]
#用作于数据解析,response是请求成功后的响应对象,调用次数由start_urls长度确定
def parse(self, response):
pass
执行工程:scrapy crawl spiderName,spiderName就是新创建文件的名字
请求前需要先修改裙子协议:
settings.py中ROBOTSTXT_OBEY=True改为False
设置日志输出等级:
settings.py中增加LOG_LEVEL='ERROR'
设置ua伪装,填写对应ua信息
USER_AGENT=‘Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/110.0.0.0 Safari/537.36’
如:
import scrapy
class XiaohuaSpider(scrapy.Spider):
name = "xiaohua"
#allowed_domains = ["www.xxx.com"]
start_urls = ["https://www.xiaohua.com/"]
def parse(self, response):
divList = response.xpath('//div[@class="content-left"]/div')
for div in divList:
user = div.xpath('./div[1]/div//i/text()')[0].extract()
content = div.xpath('./p/a/text()').extract()
content = ''.join(content)
print(user,content)
break
cd 到xiaohuaPro工程路径中,执行scrapy crawl xiaohua
持久化存储:
终端指令:只可以将parse的返回值存储到文本文件中。scrapy crawl first -o ./wenben.csv;文本类型需要为:‘json’, ‘jsonlines’, ‘jsonl’, ‘jl’, ‘csv’, ‘xml’, ‘marshal’, ‘pickle’
如:
import scrapy
class XiaohuaSpider(scrapy.Spider):
name = "xiaohua"
#allowed_domains = ["www.xxx.com"]
start_urls = ["https://www.xiaohua.com/"]
def parse(self, response):
alldata = []
divList = response.xpath('//div[@class="content-left"]/div')
for div in divList:
user = div.xpath('./div[1]/div//i/text()')[0].extract()
content = div.xpath('./p/a/text()').extract()
content = ''.join(content)
#print(user,content)
#break
dic =
'author':user,
'content':content
alldata.append(dic)
return alldata
基于管道:
- 在item类中定义相关的属性
- 将解析的数据封装存储到item类型的对象
- 将item类型的对象提交给管道进行持久化存储的操作
- 在管道类的process_item中要将其接收到的item对象中存储的数据进行持久化存储操作
- 在配置文件中开启管道
举例:
item.py
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.html
import scrapy
class XiaohuaproItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
author = scrapy.Field()
content = scrapy.Field()
#pass
xiaohua.py
import scrapy
from xiaohuaPro.items import XiaohuaproItem
class XiaohuaSpider(scrapy.Spider):
name = "xiaohua"
#allowed_domains = ["www.xxx.com"]
start_urls = ["https://www.xiaohua.com/"]
def parse(self, response):
alldata = []
divList = response.xpath('//div[@class="content-left"]/div')
for div in divList:
user = div.xpath('./div[1]/div//i/text()').extract()
user = ''.join(user)
content = div.xpath('./p/a/text()').extract()
content = ''.join(content)
#print(user,content)
#break
dic =
'author':user,
'content':content
alldata.append(dic)
item = XiaohuaproItem()
item['author']=user
item['content']=content
yield item#提交到了管道
return alldata
settings.py
ITEM_PIPELINES =
"xiaohuaPro.pipelines.XiaohuaproPipeline": 300,
pipelines.py
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
# useful for handling different item types with a single interface
from itemadapter import ItemAdapter
class XiaohuaproPipeline:
fp=None
#重写父类方法
def open_spider(self,spider):
print('begin')
self.fp = open('./xiaohua.txt','w',encoding='utf-8')
#专门处理item类型对象
#每次接受一个item对象就会被调用一次
def process_item(self, item, spider):
author = item['author']
content = item['content']
self.fp.write(author+':'+content+'\\n')
return item
#
def close_spider(self,spider):
print('end')
self.fp.close()
如果想要将数据同时存到mysql一份,需要在pipelines.py中增加以下内容:
import pymysql
class XiaohuaproMysqlPipeline:
conn = None
cursor=None
def open_spider(self,spider):
self.conn = pymysql.Connect(host='127.0.0.1',port=3306,user='root',password='123',db='xiaohua',charset='utf8')
def process_item(self, item, spider):
self.cursor = self.conn.cursor()
try:
self.cursor.execute('insert into xiaohua values("%s","%s")'%(item['author'],item["content"]))
self.conn.commit()
except Exception as e:
print(e)
self.conn.rollback()
return item #会传递给下一个即将执行存储的管道类
def close_spider(self,spider):
self.cursor.close()
self.conn.close()
同时修改settings.py
ITEM_PIPELINES =
"xiaohuaPro.pipelines.XiaohuaproPipeline": 300,
"xiaohuaPro.pipelines.XiaohuaproMysqlPipeline": 301,
分页信息的爬取
import scrapy
class YhdmSpider(scrapy.Spider):
name = "yhdm"
#allowed_domains = ["www.xxx.com"]
start_urls = ["http://www.yhdmp.net/list/"]
url = 'https://www.yhdmp.net/list/?pagesize=24&pageindex=%d'
pageName = 1
def parse(self, response):
lists = response.xpath('//div[@class="lpic"]/ul/li')
for li in lists:
name = li.xpath('./h2/a/text()'Python学习笔记
文章目录
供个人学习笔记回顾时使用.
1. 异常
没啥说的, 语法换下而已. 下文只会记录一下和JS语法不同的地方:
基础语法: try...except...finally...
一. 可以expect多个异常, 例子:
可以使用expect语句块处理不同的错误
try:
print('try...')
r = 10 / int('a')
print('result:', r)
except ValueError as e:
print('ValueError:', e)
except ZeroDivisionError as e:
print('ZeroDivisionError:', e)
finally:
print('finally...')
print('END')
二. expect之后还可以增加else语句, 用来没有错误发生时,执行else语句, 例子:
try:
print('try...')
r = 10 / int('2')
print('result:', r)
except ValueError as e:
print('ValueError:', e)
except ZeroDivisionError as e:
print('ZeroDivisionError:', e)
else:
print('no error!')
finally:
print('finally...')
print('END')
三. py自带一个logging模块, 可以用来记录错误, 例子:
import logging
def foo(s):
return 10 / int(s)
def bar(s):
return foo(s) * 2
def main():
try:
bar('0')
except Exception as e:
logging.exception(e)
main()
print('END')
通过配置,logging还可以把错误记录到日志文件里,方便事后排查。
四. 抛出错误使用raise语法 例子:
def foo(s):
n = int(s)
if n==0:
raise ValueError('invalid value: %s' % s)
return 10 / n
py错误类型种类介绍
https://docs.python.org/3/library/exceptions.html#exception-hierarchy
2. 单测
python自带单测模块, unittest, 编写单测时需要继承该类.
且命名也有规范,开头必要以test开头, 否则测试的时候不会被执行.
这里有个第一次见到的语法就是下面例子中的with语句, 用来捕获raise
例子如下:
import unittest
class asd(unittest.TestCase):
def aaa_80_to_100(self):
s1 = Student('Bart', 80)
s2 = Student('Lisa', 100)
self.assertEqual(s1.get_grade(), 'A')
self.assertEqual(s2.get_grade(), 'A')
def test_60_to_80(self):
s1 = Student('Bart', 60)
s2 = Student('Lisa', 79)
self.assertEqual(s1.get_grade(), 'B')
self.assertEqual(s2.get_grade(), 'B')
def test_0_to_60(self):
s1 = Student('Bart', 0)
s2 = Student('Lisa', 59)
self.assertEqual(s1.get_grade(), 'C')
self.assertEqual(s2.get_grade(), 'C')
def test_invalid(self):
s1 = Student('Bart', -1)
s2 = Student('Lisa', 101)
with self.assertRaises(ValueError):
s1.get_grade()
with self.assertRaises(ValueError):
s2.get_grade()
此外py这个单测模块还带了声明周期, 例子与js的mocha模块中beforeEach和afterEach功能类似, 如下
class asd(unittest.TestCase):
def setUp(self):
print('setUp...')
def tearDown(self):
print('tearDown...')
省略第一个列子代码, 输出如下:
setUp...
tearDown...
.setUp...
tearDown...
.setUp...
tearDown...
.
----------------------------------------------------------------------
Ran 3 tests in 0.003s
OK
3. 读写文件
和C, Node的读写文件差不多
3.1 读文件
f = open('/Users/michael/test.txt', 'r')
f.read()
f.close()
操作文件过程中为了防止raise错误, 导致文件没有关闭需要使用try
try:
f = open('/path/to/file', 'r')
print(f.read())
finally:
if f:
f.close()
更简洁写法
with open('/path/to/file', 'r') as f:
f.read()
3.2 写文件
f = open('/Users/michael/test.txt', 'w')
f.write('123')
f.close()
其它语法同上
这种File System Flags可以参考这里:
https://docs.python.org/3/library/functions.html#open
3.3. 操作文件和目录
这一节没什么说的了, 就是函数而已
# 在某个目录下创建一个新目录,首先把新目录的完整路径表示出来:
os.path.join('/Users/michael', 'testdir')
# 然后创建一个目录:
os.mkdir('/Users/michael/testdir')
# 删掉一个目录:
os.rmdir('/Users/michael/testdir')
# 对文件重命名:
os.rename('test.txt', 'test.py')
# 删掉文件:
os.remove('test.py')
4. 正则表达式
感觉这一部分和JS实在太像了, 简单记录下API好了
import re
# 1. 这里使用了'r'之后就可以不管转义的问题
# 2. '^'表示已xx开头
# 3. '$'表示已xx结尾
# 4. '\\d3-8'表示3-8个数字
m = re.match(r'^(\\d3)-(\\d3,8)$', '010-12345')
# <_sre.SRE_Match object; span=(0, 9), match='010-12345'>
m.group(0) # '010-12345'
m.group(1) # '010'
m.group(2) # '12345'
4.1 贪婪匹配
这个知识点有点忘了, 顺便回顾一下
# '+'表示贪婪匹配尽可能多的匹配字符, 因此后面匹配0位为空
re.match(r'^(\\d+)(0*)$', '102300').groups() # ('102300', '')
# '?'可以让\\d+采用非贪婪匹配
re.match(r'^(\\d+?)(0*)$', '102300').groups() # ('1023', '00')
5. 其它
5.1. StringIO BytesIO
这两个API暂时想不到用途在哪里, 见下面例子:
// 在内存中读写str
from io import StringIO
f = StringIO()
print(f.write('hello')) // 5
print(f.write(' ')) // 1
print(f.write('world!')) // 6
print(f.getvalue()) // hello world!
// 在内存中读写Byte
from io import BytesIO
f = BytesIO()
print(f.write('中文'.encode('utf-8'))) // 6
print(f.getvalue()) // b'\\xe4\\xb8\\xad\\xe6\\x96\\x87'
5.2. 序列化
有两种, 一种是变量序列化, 一种是JSON序列化. 很好理解, 见下方代码
5.2.1 pickle
# 变量序列化
import pickle
# 存到本地文件
d = dict(name='Bob', age=20, score=88)
f = open('dump.txt', 'wb')
pickle.dump(d, f) # 是个二进制数据
f.close()
# 从本地文件读取到内存
f = open('dump.txt', 'rb')
a = pickle.load(f)
f.close()
print(a)
5.2.2. JSON
# JSON序列化
import json
d = dict(name='Bob', age=20, score=88)
json.dumps(d) # 就是JSON.stringify '"age": 20, "score": 88, "name": "Bob"'
json_str = '"age": 20, "score": 88, "name": "Bob"'
json.loads(json_str) # 就是JSON.parse 'age': 20, 'score': 88, 'name': 'Bob'
python对于class dumps需要做些特殊处理, 还需要传入第二个参数
class Student(object):
def __init__(self, name, age, score):
self.name = name
self.age = age
self.score = score
s = Student('Bob', 20, 88)
print(json.dumps(s)) # 报错
# 方法1
def student2dict(std):
return
'name': std.name,
'age': std.age,
'score': std.score
# 需要先把Student实例转换成dict,然后再序列化为JSON
print(json.dumps(s, default=student2dict)) # "age": 20, "name": "Bob", "score": 88
# 方法2
# 或者直接用class的_dict_
print(json.dumps(s, default=lambda obj: obj.__dict__))
# 因此pyhton json的loads方法, 还可以直接把字符串反序列成class
def dict2student(d):
return Student(d['name'], d['age'], d['score'])
json_str = '"age": 20, "score": 88, "name": "Bob"'
print(json.loads(json_str, object_hook=dict2student)) # <__main__.Student object at 0x10cd3c190>
reference links:
以上是关于Python学习个人记录笔记的主要内容,如果未能解决你的问题,请参考以下文章