Java初阶Array详解(上)
Posted 署前街的少年
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Java初阶Array详解(上)相关的知识,希望对你有一定的参考价值。
活动地址:CSDN21天学习挑战赛

✨矢志不渝✨

目录
一、数组的基本概念
1 . 数组的创建
int[] array1 = new int[10]; // 创建一个容纳10个int类型元素的数组
double[] array2 = new double[5]; // 创建一个容纳5个double类型元素的数组
String[] array3 = new double[3]; // 创建一个容纳3个字符串元素的数组2 . 数组的初始化
✅数组的初始化主要分为动态初始化以及静态初始化。
☁动态初始化:在创建数组时,直接指定数组中元素的个数
int[] array = new int[10];☁静态初始化:在创建数组时不直接指定数据元素个数,而直接将具体的数据内容进行指定
int[] array1 = new int[]0,1,2,3,4,5,6,7,8,9;
double[] array2 = new double[]1.0, 2.0, 3.0, 4.0, 5.0;
String[] array3 = new String[]"hello", "Java", "!!!";【注意事项】
静态初始化虽然没有指定数组的长度,编译器在编译时会根据中元素个数来确定数组的长度。
静态初始化时, 中数据类型必须与[]前数据类型一致。
静态初始化可以简写,省去后面的new T[]。
比如:
int[] array1 = 0,1,2,3,4,5,6,7,8,9,10;静态初始化和动态初始化也可以分为两步
//静态初始化
int[] array1;
array1 = new int[10];
//动态初始化
int[] array2;
array2 = new int[](10,20,30);
//此处不可省略new int[];未初始化的数组中含有其默认值

3 . 数组的使用
数组在内存中是一段连续的空间,空间的编号都是从0开始的,依次递增,该编号称为数组的下标,数组可以通过下标访问其任意位置的元素。比如:
int[]array = new int[]10, 20, 30, 40, 50;
System.out.println(array[0]);
System.out.println(array[1]);
System.out.println(array[2]);
System.out.println(array[3]);
System.out.println(array[4]);
// 也可以通过[]对数组中的元素进行修改
array[0] = 100;
System.out.println(array[0]);【注意事项】
数组是一段连续的内存空间,因此支持随机访问,即通过下标访问快速访问数组中任意位置的元素
下标从0开始,介于[0, N)之间不包含N,N为元素个数,不能越界,否则会报出下标越界异常。
//数组越界
Exception in thread"main"java.lang.ArrayIndexOutOfBoundsException: 1004. 数组遍历
-
使用for循环和 数组.length获取数组的元素并遍历
int[] array1 = new int[]10, 20, 30, 40, 50;
for(int i = 0; i < array1.length; i++)
System.out.println(array[i]);
-
for-each 遍历数组
int[] array = 1, 2, 3;
//定义数组的类型:数组名
for (int x : array)
System.out.println(x);
for-each遍历的缺点:无法获取数组的下标
-
toString 打印数组
public class Test int[] array =1,2,3,4,5,6; System.out.println(array.toString(array)); -
数组越界

5. 数组是引用类型
5.1 简单了解JVM的内存分布

-
虚拟机栈(JVM Stack): 与方法调用相关的一些信息,每个方法在执行时,都会先创建一个栈帧,栈帧中包含 有:局部变量表、操作数栈、动态链接、返回地址以及其他的一些信息,保存的都是与方法执行时相关的一些信息。比如:局部变量。当方法运行结束后,栈帧就被销毁了,即栈帧中保存的数据也被销毁了。
-
堆(Heap): JVM所管理的最大内存区域. 使用 new 创建的对象都是在堆上保存 (例如前面的 new int[]1, 2, 3 ),堆是随着程序开始运行时而创建,随着程序的退出而销毁,堆中的数据只要还有在使用,就不会被销 毁 。
5.2 引用数据类型
-
基本类型变量与引用类型变量
public static void test()
int a = 10;
int b = 20;
int[] arr = new int[]1,2,3;

public class TestArray
public static void main(String[] args)
int[] array =2,3,5,6;
System.out.println(array);
// 可以认为array这个引用存放的是数组s
// 一个引用不能指向多个对象
//输出的是地址通过哈希得到的,可以简单理解为地址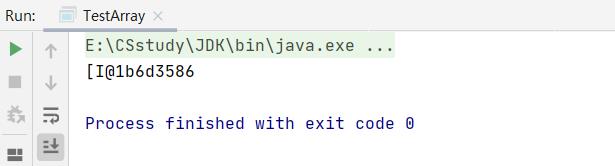
-
引用传递
public static void main(String[] args)
int[] array2 = 2, 3, 4, 3, 5;
System.out.println(Arrays.toString(array2));
int[] array3 = array2;
System.out.println(Arrays.toString(array3));
// array3这个引用指向了array2这个引用所指向的对象,通过array3修改数值也会影响原来的值
public static void main(String[] args)
int array[] = 1,2,3,4;
int array2[] =4,5,6,7;
array = array2;
System.out.println(Arrays.toString(array));
System.out.println(Arrays.toString(array2));
//array这个引用被改为指向array2所指向的对象,array原本在堆区所指向的对象被自动释放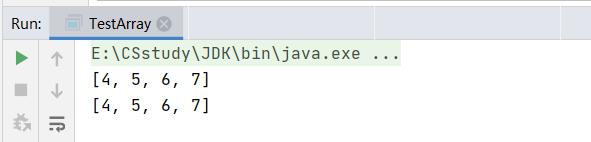
-
引用中的实参与形参
public static void main(String[] args)
int[] array1 = 1,2,3,4,5;
fun2(array1);
System.out.println(Arrays.toString(array1));
int[] array2 =6,7,8,9;
fun1(array2);
System.out.println(Arrays.toString(array2));
public static void fun2(int[] array)
array[2] = 100;
public static void fun1(int[] array)
array = new int[10];
//fun1 修改了形参自己的指向
//fun2 修改了实参所指向对象的值
//array 打印时输出的时实参指向的对象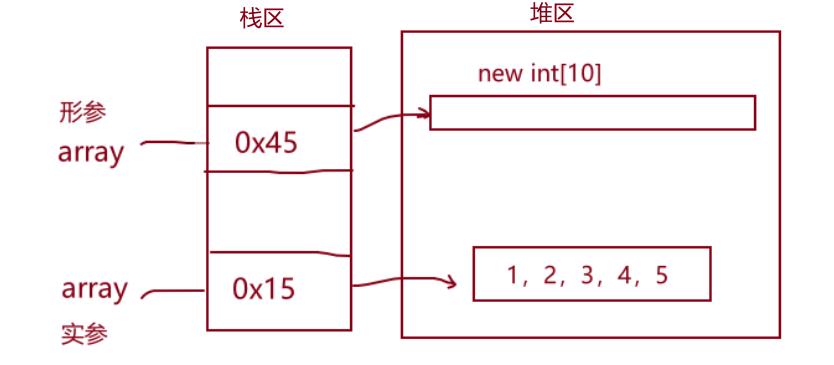

-
空指针异常
int[] arr = null;
System.out.println(arr[0]);
null 在 Java 中表示 "空引用" , 也就是一个不指向对象的引用 ,类似于 C 语言中的 NULL (空指针), 都是表示一个无效的内存位置. 因此不能对这个内存进行任何读写操作. 一旦尝试读写, 会NullPointerException.
-
数组作为返回值
public static void main(String[] args)
int[] ret = fun3();
System.out.println(Arrays.toString(ret));
public static int[] fun3()
int[] tmp = 1,2,3,4,5;
return tmp;
//返回数组并打印

二、数组的基本使用
1. 数组转字符串
/**
* 数组转字符串
* @param args
*/
public static void main(String[] args)
int[] array = 2,5,6,7,8;
String ret = Arrays.toString(array);
System.out.println(ret);

简单模拟实现
public static String myTostring(int[] tmp)
String ret ="[";
int i;
if(tmp == null)
return null;
for (i =0;i<tmp.length;i++)
ret += tmp[i];
if (i != tmp.length - 1)
ret += ",";
ret+="]";
return ret;
2. 数组的拷贝
Arrays.copyof()
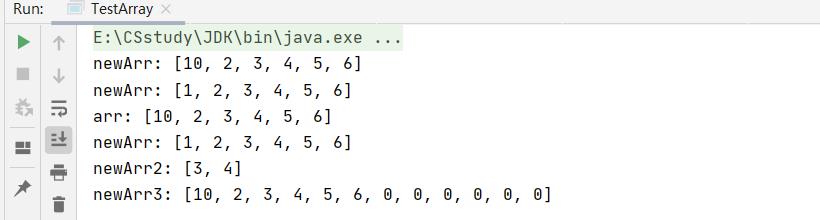
public static void main(String[] args)
// newArr和arr引用的是同一个数组
// 因此newArr修改空间中内容之后,arr也可以看到修改的结果
int[] arr = 1,2,3,4,5,6;
int[] newArr = arr;
newArr[0] = 10;
System.out.println("newArr: " + Arrays.toString(arr));
// 使用Arrays中copyOf方法完成数组的拷贝: copyOf方法在进行数组拷贝时,创建了一个新的数组
// arr和newArr引用的不是同一个数组
arr[0] = 1;
newArr = Arrays.copyOf(arr, arr.length);
System.out.println("newArr: " + Arrays.toString(newArr));
// 因为arr修改其引用数组中内容时,对newArr没有任何影响
arr[0] = 10;
System.out.println("arr: " + Arrays.toString(arr));
System.out.println("newArr: " + Arrays.toString(newArr));
// 拷贝某个范围.
int[] newArr2 = Arrays.copyOfRange(arr, 2, 4);
System.out.println("newArr2: " + Arrays.toString(newArr2));
//利用copyof特性,对数组实现扩容
int[] newArr3 = Arrays.copyOf(arr,2*arr.length);
System.out.println(Arrays.toString(newArr3));
-
Arrays.copyof()源码

arraycopy()
int[] arr = 1,2,3,4,5,6;
int copy[] = new int[arr.length];
System.arraycopy(arr,0,copy,0,arr.length-3);
(被拷贝的数组1,拷贝数组1的起始位置,目的数组2,数组2的起始位置,拷贝长度)
//支持局部的拷贝
System.out.println("copy: " + Arrays.toString(copy));
Arrays.copyofRange()
int[] arr = 1,2,3,4,5,6;
int copy2[] = Arrays.copyOfRange(arr,3,5);
//拷贝的下标范围为[3,5);
System.out.println(Arrays.toString(copy2));
array.clone()
int[] arr = 1,2,3,4,5,6;
int copy3[] = arr.clone();
System.out.println("arr: "+Arrays.toString(arr));
System.out.println("copy3: "+Arrays.toString(copy3));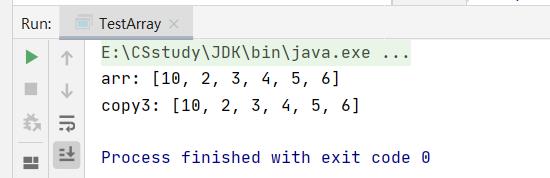
3.数组的排序
int array[] = 1,4,5,3,6,2;
System.out.println("排序前");
System.out.println(Arrays.toString(array));
Arrays.sort(array);
System.out.println("排序后");
System.out.println(Arrays.toString(array));
下期预告:Array的综合使用
💖如果文章对你有帮助,请多多点赞、收藏、评论、关注支持!!💖
数据结构初阶链表详解无哨兵位单向非循环链表
链表概念及结构
概念:链表是一种物理存储结构上非连续、非顺序的存储结构,数据元素的逻辑顺序是通过链表中的指针链接次序实现的 。

- 链式结构在逻辑上是连续的,但是在物理上不一定连续
- 现实中的结点一般都是从堆上申请出来的
- 从堆上申请的空间,是按照一定的策略来分配的,两次申请的空间可能连续,也可能不连续
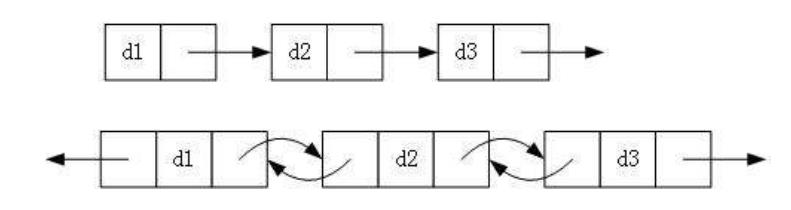
实际上链表的结构非常多样,组合起来有8种链表结构。
1.单向或双向
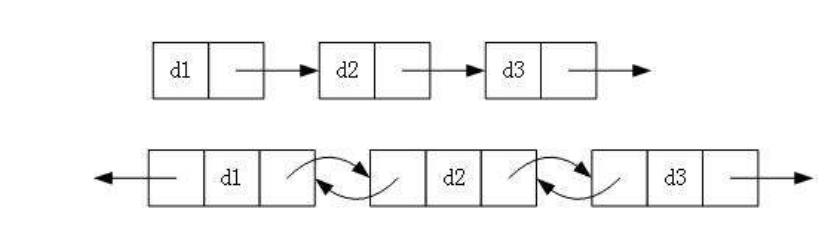
2.带头或者不带头
3. 循环与非循环
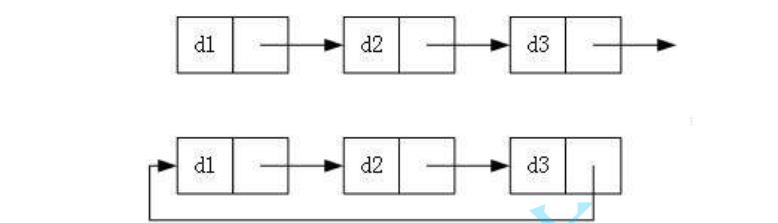
本文介绍的是 无头单向非循环链表。
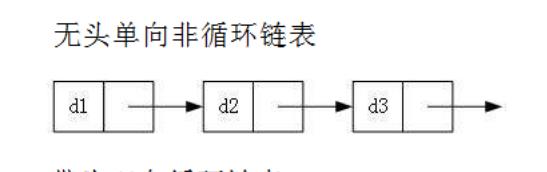
无头单向非循环链表:结构简单,一般不会单独用来存数据。实际中更多是作为其他数据结构的子结构,如哈希桶、图的邻接表等等。另外这种结构在笔试面试中出现很多。
SListNode结点结构体
链表是由一个一个结点链接起来的,所以在创建一条链表前,首先要创建一个结点。结点由两部分组成:数据域和指针域。
typedef int SLTDataType;
typedef struct SListNode {
SLTDataType data;
struct SListNode* next;
}SLTNode;
函数接口
// 动态申请一个结点
SLTNode* BuySListNode(SLTDataType x);
// 单链表打印
void SListPrint(SLTNode* phead);
// 单链表尾插
void SListPushBack(SLTNode** pphead, SLTDataType x);
// 单链表头插
void SListPushFront(SLTNode** pphead, SLTDataType x);
// 单链表尾删
void SListPopBack(SLTNode** pphead);
// 单链表头删
void SListPopFront(SLTNode** pphead);
// 单链表查找
SLTNode* SListFind(SLTNode* phead, SLTDataType x);
// 单链表在pos位置之后插入x
void SListInsertAfter(SLTNode* pos, SLTDataType x);
// 单链表删除pos位置之后的值
void SListEraseAfter(SLTNode* pos);
// 单链表的销毁
void SListDestroy(SLTNode** pphead);
下面对以上功能进行实现。
打印单链表
打印单链表,需要从头指针指向的位置开始,依次向后打印,直到指针指向NULL,结束打印。
void SListPrint(SLTNode* phead) {
SLTNode* cur = phead;
while (cur != NULL) {
printf("%d->", cur->data);
cur = cur->next;
}
printf("NULL\\n");
}
单链表尾插
void SListPushBack(SLTNode** pphead, SLTDataType x) {
assert(pphead);
SLTNode* newnode = BuySListNode(x);
if (*pphead == NULL) {
*pphead = newnode;
}
else {
SLTNode* tail = *pphead;
while (tail->next != NULL) {
tail = tail->next;
}
tail->next = newnode;
}
}
注意:
- 此处的
assert(pphead);是为了防止传入的不是二级指针。 - 对单链表增加一个结点时,都要用到申请一个新的结点,所以我们不妨把该功能封装成一个函数。
SLTNode* BuySListNode(SLTDataType x) {
SLTNode* newnode = (SLTNode*)malloc(sizeof(SLTNode));
if (newnode == NULL) {
printf("malloc fail\\n");
exit(-1);
}
newnode->data = x;
newnode->next = NULL;
return newnode;
}
单链表头插
void SListPushFront(SLTNode** pphead, SLTDataType x) {
SLTNode* newnode = BuySListNode(x);
newnode->next = *pphead;
*pphead = newnode;
}
单链表尾删
注意点:
- 需要二级指针
- 对空链表,一个结点,两个及两个以上的结点分情况讨论
void SListPopBack(SLTNode** pphead) {
assert(*pphead != NULL);
// 一个结点
if ((*pphead)->next == NULL) {
free (*pphead);
*pphead = NULL;
}
else {
// 两个及两个以上结点
SLTNode* tail = *pphead;
while (tail->next->next != NULL) {
tail = tail->next;
}
free(tail->next);
tail->next = NULL;
}
}
单链表头删
注意:
- 需要判断是否为空链表。
- 更新头指针
void SListPopFront(SLTNode** pphead) {
assert(*pphead != NULL);
SLTNode* next = (*pphead)->next;
free(*pphead);
*pphead = next;
}
查找结点
遍历一遍链表,找到则返回当前结点,否则返回 NULL。
SLTNode* SListFind(SLTNode* phead, SLTDataType x) {
for (SLTNode* cur = phead; cur != NULL; cur = cur->next) {
if (cur->data == x) {
return cur;
}
}
return NULL;
}
单链表在pos位置之后插入x
这里首先引出一个问题,为什么需要选择在pos之后插入,而不是在pos之前插入呢?
其实是有原因的。如果只是在pos之后插入,无需遍历链表就可以操作;如果要在pos之前进行插入,需要遍历一遍链表,然而时间开销大(相比),O(N)。
注意点
- 判断是否属于尾插
- 插入结点的顺序 !!! 不可颠倒
newnode->next = pos->next;
pos->next = newnode;
void SListInsertAfter(SLTNode* pos, SLTDataType x) {
SLTNode* newnode = BuySListNode(x);
if (pos->next == NULL) {
// 尾插
pos->next = newnode;
}
else {
newnode->next = pos->next;
pos->next = newnode;
}
}
单链表删除pos位置之后的值
void SListEraseAfter(SLTNode* pos) {
assert(pos && pos->next);
SLTNode* next = pos->next->next;
free(pos->next);
pos->next = NULL;
pos->next = next;
}
单链表销毁
注意
单链表的销毁需要对结点进行逐个销毁。
为什么???
就凭他是一个一个在堆上开辟出来的,不像动态开辟的顺序表,在内存里是一段连续的内存空间。如果只对链表进行 free(*pphead)操作,是会造成内存泄漏的!!!
void SListDestroy(SLTNode** pphead) {
SLTNode* cur = *pphead;
while (cur) {
SLTNode* next = cur->next;
free(cur);
cur = next;
}
*pphead = NULL;
}
最后…
其实单链表没有那么可怕,可怕的是老师上课讲的稀里糊涂(狗头保命hhh),大家只要想象成火车的一节节车厢就好啦~~~
小汽车,嘟嘟嘟!!!

最后,如果喜欢博主的话,不妨点个关注哦! 码文不易,感恩ღ( ´・ᴗ・` )比心
以上是关于Java初阶Array详解(上)的主要内容,如果未能解决你的问题,请参考以下文章