MySQL系列之分库分表学习笔记
Posted smileNicky
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MySQL系列之分库分表学习笔记相关的知识,希望对你有一定的参考价值。
1、架构演进和分库分表
1.1、单应用单数据库
这是微服务还没兴起之前,很多项目的架构,随着业务的堆积,项目越来越庞大,数据量也越来越庞大,如果并发一旦上来,就很容易出现一些性能的问题。而且项目太庞大,维护起来也不容易。

1.2、多应用单数据库
多应用单数据库系统是对之前的单体应用系统进行拆分,分成多个服务,也就是一个分布式的系统,但是数据库层面还是用同一个数据库,仅仅对业务进行拆分,数据量多的话,数据库的压力还是那么大。

1.3、多应用多数据库
对数据库性能进行调优,集群提高性能稳定性各种调优之后,如果性能还是有问题,数据量又特别庞大的情况才可以考虑分库了,这样就是一个多应用多数据库的系统。
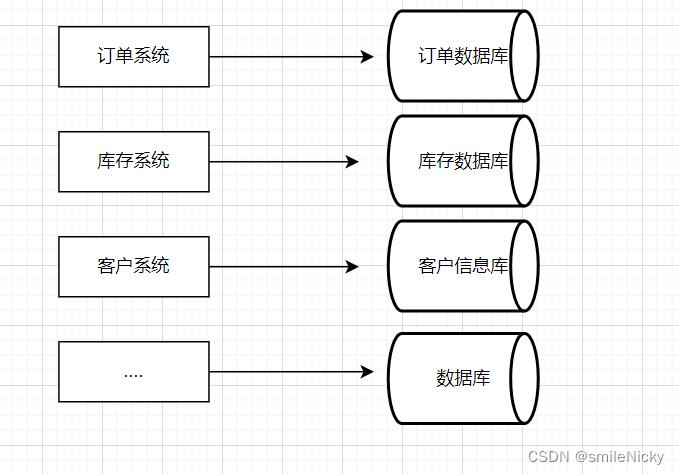
2、单体应用遇到的问题
- 用户量请求量太大 :单服务器tps、内存、io都是有上限的,所以可以将请求分散到多个服务器
- 单个数据库数据量太大:单个数据库磁盘空间,io有上限,处理能力也有上限
- 单表数据量太大:查询、新增、更新等操作都会变慢,在加字段、加索引、机器迁移都会影响效率
3、分库分表的类型
分库分表按照拆分方式可以分为垂直拆分和水平拆分
- 垂直拆分:基于表或字段拆分,表的结构会变,我们有单库的分表,也有多库的分库
- 水平拆分:基于数据拆分,表结构不会变,数据不同。有单库的也有多库的水平拆分
3.1、垂直拆分
-
垂直分表
数据表中包含字段太多且包含大字段的时候,在查询时对数据库的io、内存会受到影响,更新数据时也会很慢,binlog文件会很大,这时候可以考虑对表进行拆分,特别是有一些大字段的表,可以拆分出来到另外的表。如图,对商户的信息表进行拆分,分为比较常用的基本信息表和不是很常见的详情信息表,有时候可以根据业务只查询基本信息就行,需要详情信息再关联查询。

-
垂直分库
前面对一些字段比较多的表进行拆分,但是都是在一个库里,对于数据库来说,查询压力还是那么大,这时候可以根据业务结合现在的微服务架构对业务进行拆分,同时也对数据库进行拆分,如图:

3.2、水平拆分
- 水平分表
前面介绍的是对一些表进行拆分,也有不改变表结构的,仅仅对数据进行拆分,拆分的规则可以是时间或者区划等等,这种不改变表结构的方法称之为水平分表,如图,订单表数据量太多了,根据时间,分为多张表

水平分表的规则
- RANGE:
- 时间:按年、月、日去拆分。例如order_2016、order_201701
- 地域:按照省或市去拆分。例如order_beijing、order_shanghai
- 大小:从0到1000000一个表,1000001~2000000放一个表
- HASH:例如根据用户ID取模
不同的业务场景水平分表规则是不一样的,就上面提到的规则,举例如下:
- 站内信:站内信是很多系统都会有的功能,用户只能看到发送给自己的信息,其他用户的看不到,这种情况可以根据用户ID hash分库分表
- 流水表:可以按照时间维度,可以按照年份、月份甚至日期分库
- 用户登录:用户输入手机号登录,要去查找对应用户ID,但是用户信息分布到多个库里,这种情况可以设计一张关联表,关联表保存用户ID和手机的关联,直接通过关联表找到对应用户ID,再去查找对应用户信息
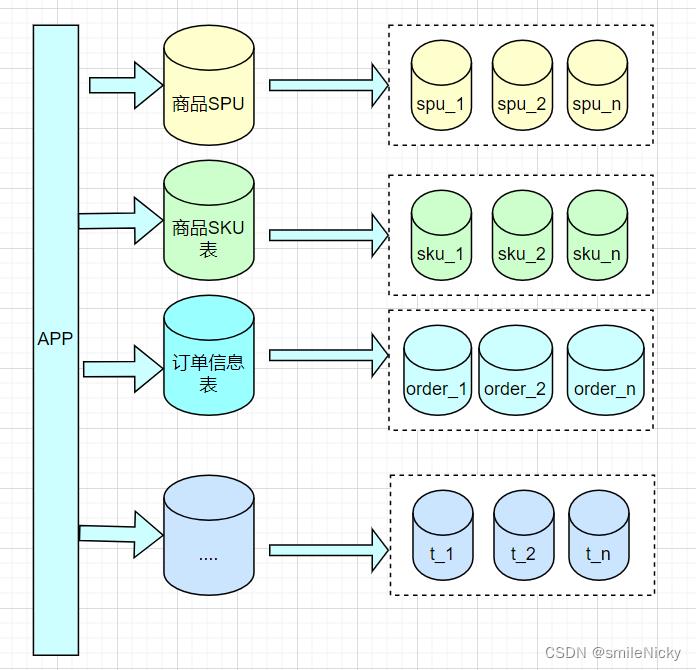
- 水平分库
前面按照一些范围或者规则进行拆分了,但是数据量还是疯狂增长,这时候可以进行分库,多张按时间分出来的子表,比如order_1,order_2,order_3,...,order_n分到多个库里,如图:
4、什么时候需要分库分表?
随着业务数量的快速增长,一些常用业务表数据量达到了几千万,或者上亿的数据量,这个时候如果SQL没注意,可能导致一些慢SQL的出现。
所以什么时候需要分表?500万,1000万?这个其实也没特定的规定,不过可以参考《阿里巴巴Java开发手册》里面的建议:推荐500万行或者单表容量超过2GB时候才需要分表

当然数据达到500万就需要分表?这个没有确定的,手册里也只是建议,如果数据表设计合理,索引建立也合理,系统也是可以支持500万或者上千万数据,分库分表虽然可以减缓数据库压力,但是分库分表也意味着业务处理起来更麻烦了。比如要查询数据,有时候需要跨几个库或者多张表。如何保证高效查询又是一个问题。所以分库分表要根据业务或者实际情况出发,合理设计。
分库分表带来的问题:
- 跨库关联查询:假如要查询用户的订单信息,要通过订单表,再进行关联查询,但是又分库了,肯定不能直接通过SQL查出来,这时候可以分别查出来,然后再通过代码进行封装。当然有时候也可以冗余字段的方式,在一些加上另外一张表的字段,虽然不遵循数据库范式。
- 分布式事务:进行分库分表也会带来分布式事务的问题,因为涉及到两个库,一些业务操作要保证事务一致性,就需要一些分布式事务的处理方案,比如补偿机制等等,可以借助一些中间件,比如阿里的seata做好分布式事务处理
- 复杂业务问题:业务比较简单还好,如果业务复杂起来,排序、翻页、函数计算等等肯定都需要使用的,但是有时候表又分为多张、又跨库,处理起来肯定是很麻烦的
- 全局主键问题:分库分表之后,要保证主键的唯一性,就需要更多的处理方案,比如uuid、雪花算法等等的使用
以上是关于MySQL系列之分库分表学习笔记的主要内容,如果未能解决你的问题,请参考以下文章