Buddy(伙伴)系统分配器之分配page
Posted Loopers
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Buddy(伙伴)系统分配器之分配page相关的知识,希望对你有一定的参考价值。
Buddy分配器是按照页为单位分配和释放物理内存的,在Zone那一节文章中freearea就是通过buddy分配器来管理的。
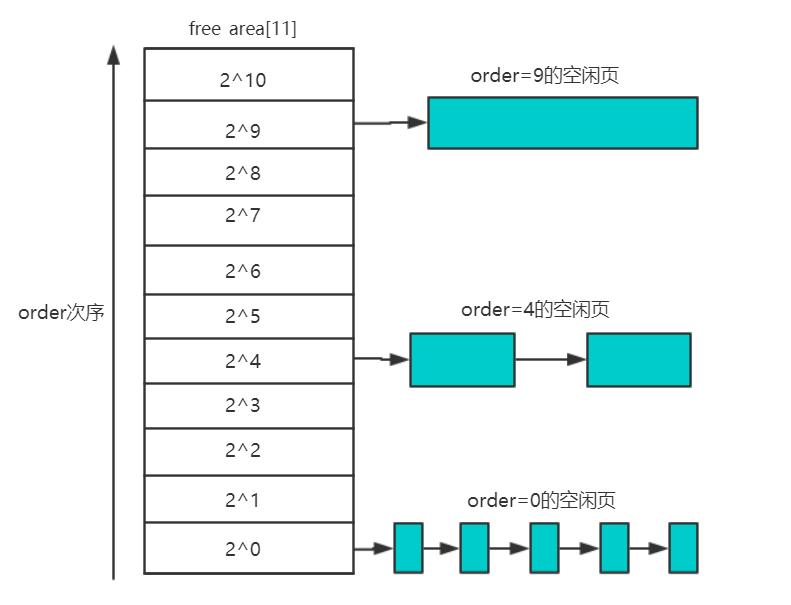
buddy分配器将空闲页面按照order的大小分配挂到不同的order链表中。比如order为0的链表下就挂载着大小为1个page的空闲页,order=4的链表下就挂载着大小为16个page的空闲页面。
buddy分配器的算法是:
- 当分配order=n的页面的时候,首先order=n的freelist链表中去寻找对应的页,如果order=n的freelist中有空闲的页面,则直接分配
- 当order=n的freelist链表中没有可用的页面时,则去order=n+1的freelist中查找是否有对应的空闲页面
- 如果order=n+1的freelist链表中存在空闲页面,则从order=n+1的freelist中取出一个空闲页面,将其分为两个order=n的页面。
- 其中一个分配出去,另外一个挂载到order=n的空闲链表中。
- 其中刚分开的那两个空闲页面称为buddy
举个例子:比如申请order=2的,迁移类型为MIGRATE_MOVABLE为可移动的页面
- 当比如分配order=2的页面时,先去freearea[2].free_list[MIGRATE_MOVABLE]中查找是否有空闲的页面,如果有则返回此页面,同时freearea[2].nr_free减1
- 如果freearea[2].freelist[MIGRATE_MOVABLE]中没有可用的空闲页面,则去freearea[3].freelist[MIGRATE_MOVABLE]去寻找是否有可用的空闲页面
- 如果freearea[3].freelist[MIGRATE_MOVABLE]中存在空闲的页面,则将其一分为二,其中一份直接返回,另外一份挂载到freearea[2].freelist[MIGRATE_MOVABLE]的链表中
- 同时将freearea[3].nr_free减去1,freearea[2].nr_free加上1
- 刚才从freearea[3].freelist[MIGRATE_MOVABLE]拆分的两个空闲页面,这两个空闲页面物理地址是连续的,我们称之为buddy
在真正分析分配代码之前,我们需要看一下ALLOC_开头的一些flag
/* The ALLOC_WMARK bits are used as an index to zone->watermark */
#define ALLOC_WMARK_MIN WMARK_MIN
#define ALLOC_WMARK_LOW WMARK_LOW
#define ALLOC_WMARK_HIGH WMARK_HIGH
#define ALLOC_NO_WATERMARKS 0x04 /* don't check watermarks at all */
/* Mask to get the watermark bits */
#define ALLOC_WMARK_MASK (ALLOC_NO_WATERMARKS-1)- ALLOC_WMARK_MIN: 从最低水位分配或者以上
- ALLOC_WMARK_LOW: 从低水位分配或者以上
- ALLOC_WMARK_HIGH: 从高水位分配或者以上
- ALLOC_NO_WATERMARKS: 分配不检查水位
#ifdef CONFIG_MMU
#define ALLOC_OOM 0x08
#else
#define ALLOC_OOM ALLOC_NO_WATERMARKS
#endif
#define ALLOC_HARDER 0x10 /* try to alloc harder */
#define ALLOC_HIGH 0x20 /* __GFP_HIGH set */
#define ALLOC_CPUSET 0x40 /* check for correct cpuset */
#define ALLOC_CMA 0x80 /* allow allocations from CMA areas */
#ifdef CONFIG_ZONE_DMA32
#define ALLOC_NOFRAGMENT 0x100 /* avoid mixing pageblock types */
#else
#define ALLOC_NOFRAGMENT 0x0
#endif
#define ALLOC_KSWAPD 0x200 /* allow waking of kswapd */- ALLOC_HARDER: 努力去分配,尽力的去分配
- ALLOC_HIGH:高优先级的分配
- ALLOC_CPUSET: 检查是否正确CPUSET配置
- ALLOC_CMA: 允许从CMA区域分配
- ALLOC_KSWAPD:允许唤醒kswapd
接着再来看下__GFP_开头的一起请求flag, gfp_flag有点太多,先列举点
#define __GFP_DMA ((__force gfp_t)___GFP_DMA)
#define __GFP_HIGHMEM ((__force gfp_t)___GFP_HIGHMEM)
#define __GFP_DMA32 ((__force gfp_t)___GFP_DMA32)
#define __GFP_MOVABLE ((__force gfp_t)___GFP_MOVABLE) /* ZONE_MOVABLE allowed */
#define __GFP_CMA ((__force gfp_t)___GFP_CMA)
#define GFP_ZONEMASK (__GFP_DMA|__GFP_HIGHMEM|__GFP_DMA32|__GFP_MOVABLE)
#define __GFP_NOFAIL ((__force gfp_t)___GFP_NOFAIL)
#define __GFP_NORETRY ((__force gfp_t)___GFP_NORETRY)- __GFP_DMA: 允许从DMA区域分配
- __GFP_HIGHMEM: 允许从highmem区域分配
- __GFP_DMA32: 允许从DMA32区域分配
- __GFP_MOVEABLE: 允许从可移动区域分配
- __GFP_CMA: 允许从CMA区域分配
- __GFP_NOFAIL:分配不允许失败,会一直重试
- __GFP_NORETRY: 分配失败后不允许retry
我们接下来看下buddy分配的核心代码:
/*
* Allocate a page from the given zone. Use pcplists for order-0 allocations.
*/
static inline
struct page *rmqueue(struct zone *preferred_zone, struct zone *zone, unsigned int order, gfp_t gfp_flags, unsigned int alloc_flags,int migratetype)
unsigned long flags;
struct page *page;
if (likely(order == 0))
page = rmqueue_pcplist(preferred_zone, zone, order,
gfp_flags, migratetype, alloc_flags);
goto out;
/*
* We most definitely don't want callers attempting to
* allocate greater than order-1 page units with __GFP_NOFAIL.
*/
WARN_ON_ONCE((gfp_flags & __GFP_NOFAIL) && (order > 1));
spin_lock_irqsave(&zone->lock, flags);
do
page = NULL;
if (alloc_flags & ALLOC_HARDER)
page = __rmqueue_smallest(zone, order, MIGRATE_HIGHATOMIC);
if (page)
trace_mm_page_alloc_zone_locked(page, order, migratetype);
if (!page && migratetype == MIGRATE_MOVABLE &&
gfp_flags & __GFP_CMA)
page = __rmqueue_cma(zone, order);
if (!page)
page = __rmqueue(zone, order, migratetype, alloc_flags);
while (page && check_new_pages(page, order));
spin_unlock(&zone->lock);
if (!page)
goto failed;
__mod_zone_freepage_state(zone, -(1 << order),
get_pcppage_migratetype(page));
__count_zid_vm_events(PGALLOC, page_zonenum(page), 1 << order);
zone_statistics(preferred_zone, zone);
local_irq_restore(flags);
out:
/* Separate test+clear to avoid unnecessary atomics */
if (test_bit(ZONE_BOOSTED_WATERMARK, &zone->flags))
clear_bit(ZONE_BOOSTED_WATERMARK, &zone->flags);
wakeup_kswapd(zone, 0, 0, zone_idx(zone));
VM_BUG_ON_PAGE(page && bad_range(zone, page), page);
return page;
failed:
local_irq_restore(flags);
return NULL;
- 当order等于0时,会直接从per-cpu的列表中获取page
- 当分配的order大于1时,而且设置的flag是__GFP_NOFAIL,则会发生警告
- 当分配的flag是需要ALLOC_HARDER分配时,则优先从MIGRATE_HIGHATOMIC(高阶原子分配)
- 如果分配失败,当迁移类型是MIGRATE_MOVABLE的,而且分配标志是从CMA分配,则优先从CMA区域分配
- 如果CMA区域分配失败,则直接调用__rmqueue根据参数从freelist中分配一个空闲页

申请一页的时候会经历上述的4个步骤,最终这4个步骤会全部调用到第五步__rmqueue_smallest函数中。
/*
* Go through the free lists for the given migratetype and remove
* the smallest available page from the freelists
*/
static __always_inline
struct page *__rmqueue_smallest(struct zone *zone, unsigned int order,
int migratetype)
unsigned int current_order;
struct free_area *area;
struct page *page;
/* Find a page of the appropriate size in the preferred list */
for (current_order = order; current_order < MAX_ORDER; ++current_order)
area = &(zone->free_area[current_order]);
page = list_first_entry_or_null(&area->free_list[migratetype],
struct page, lru);
if (!page)
continue;
list_del(&page->lru);
rmv_page_order(page);
area->nr_free--;
expand(zone, page, order, current_order, area, migratetype);
set_pcppage_migratetype(page, migratetype);
return page;
return NULL;
- 这个函数有三个参数zone代表从哪个zone分配,order代表分配的大小,migratetype:代表分配时的迁移类型
- 获取一个空闲页的算法是:
- 获取当前order的free_area, free_area[current_order]
- 根据参数迁移类型,从当前的freelist中获取一个page, freelist[migratetype]
- 如果当前freelist中存在可用的page
- 将此page从page的lru链表中删除
- 设置此page的private为0, ((page)->private = (0))
- 将此order去的可用page页数减1, area->nr_free–;
- 设置此page的迁移类型: page->index = migratetype;
- 如果当前freelist中无可用的page
- 则从下一个order继续找是否有可用的page,比如current_order=5,则第一次没找到可用的page时,current_order=6
- 假设从current_order=6的freelist链表中找到可用的page。
- 将此page从page链表中删除
- 设置此page的private为0, ((page)->private = (0))
- 将此order去的可用page页数减1, area->nr_free–;
- 调用expand函数,会将order=6的页拆分为两个order=5的页,一个页返回,另外一个order=5的页加入到order=5的freelist链表中
继续看下expand的函数实现
static inline void expand(struct zone *zone, struct page *page, int low, int high, struct free_area *area, int migratetype)
unsigned long size = 1 << high;
while (high > low)
area--;
high--;
size >>= 1;
VM_BUG_ON_PAGE(bad_range(zone, &page[size]), &page[size]);
/*
* Mark as guard pages (or page), that will allow to
* merge back to allocator when buddy will be freed.
* Corresponding page table entries will not be touched,
* pages will stay not present in virtual address space
*/
if (set_page_guard(zone, &page[size], high, migratetype))
continue;
list_add(&page[size].lru, &area->free_list[migratetype]);
area->nr_free++;
set_page_order(&page[size], high);
- 当从希望获得order获取到可用的page时,不会进入此函数,举例:希望从order=5获取,order=5有可用的页,直接返回,则不进此函数
- 当最终获得页的order大于希望获得页的order,则会进入到此函数,举例:希望从order=5获取,order=5无可用的页,从order=6获取到了也,则会进入到此函数
- 此函数实现的算法是:假如high=6 low=5
- 将area减去1,则当前area会指向order=5的area_free[5]的链表上
- 将area→freelist[migratetype]的添加到page的lru链表上,此page就是Order=6的页分裂开的
- 将area的nr_free加一
- 设置此page的page->private=order数
 开发者涨薪指南
开发者涨薪指南
 48位大咖的思考法则、工作方式、逻辑体系
48位大咖的思考法则、工作方式、逻辑体系
以上是关于Buddy(伙伴)系统分配器之分配page的主要内容,如果未能解决你的问题,请参考以下文章