头歌Sqoop数据导入 - 详解
Posted 梦想编程家
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了头歌Sqoop数据导入 - 详解相关的知识,希望对你有一定的参考价值。
【提示】点击目录每一关参考答案可以快速复制。
目录
第1关:Sqoop数据导入语法学习
任务描述
本关任务:学习Sqoop 导入( import )的基本参数并配置好环境。
相关知识
为了完成本关任务,你需要掌握: 1、Sqoop 导入( import )的基本参数。 2、配置环境。 注意:本关实训 Sqoop 的安装与配置建立在 Hadoop 、 Hive 、 mysql 已安装配置好的情况下。
Sqoop 的基本参数
Sqoop 能够让 Hadoop 上的 HDFS 和 Hive 跟关系型数据库之间进行数据导入与导出,多亏了import和export这两个工具。本实训主要是针对import(导入)来讲。 现如今我们一直储放数据都是在关系数据库中,但是数据量到达一定的规模后,我们需要数据清理加分析,如果使用关系数据库我们工作量会大大提高,这个时候我们就可以将数据从关系数据库导入(import)到Hadoop平台上进行处理。
我们要学 Sqoop 的导入也必须先知道里面的基本参数。
输入sqoop help import可以查看里面参数含义,但是是英文,接下来选取几个常见的参数来分析:
| 选项 | 含义说明 |
|---|---|
--connect <jdbc-uri> | 指定JDBC连接字符串 |
--driver <class-name> | 指定要使用的JDBC驱动程序类 |
--hadoop-mapred-home <dir> | 指定$HADOOP_MAPRED_HOME路径 |
| -P | 从控制台读取输入的密码 |
--username <username> | 设置认证用户名 |
--password <password> | 设置认证密码 |
| --verbose | 打印详细的运行信息 |
| --as-textfile | 将数据导入到普通文本文件(默认) |
| --delete-target-dir | 如果指定目录存在,则先删除掉 |
| --direct | 使用直接导入模式(优化导入速度) |
--num-mappers <n>(简写:-m) | 使用n个map任务并行导入数据 |
--query <statement>(简写:-e) | 导入的查询语句 |
--split-by <column-name> | 指定按照哪个列去分割数据 |
--table<table-name> | 导入的源表表名 |
--target-dir <dir> | 导入HDFS的目标路径 |
--warehouse-dir <dir> | HDFS存放表的根路径 |
配置环境
注意:如果这个环境不配置的话,可能会造成后续关卡不能正常实现。 1、启动Hadoop。
start-all.sh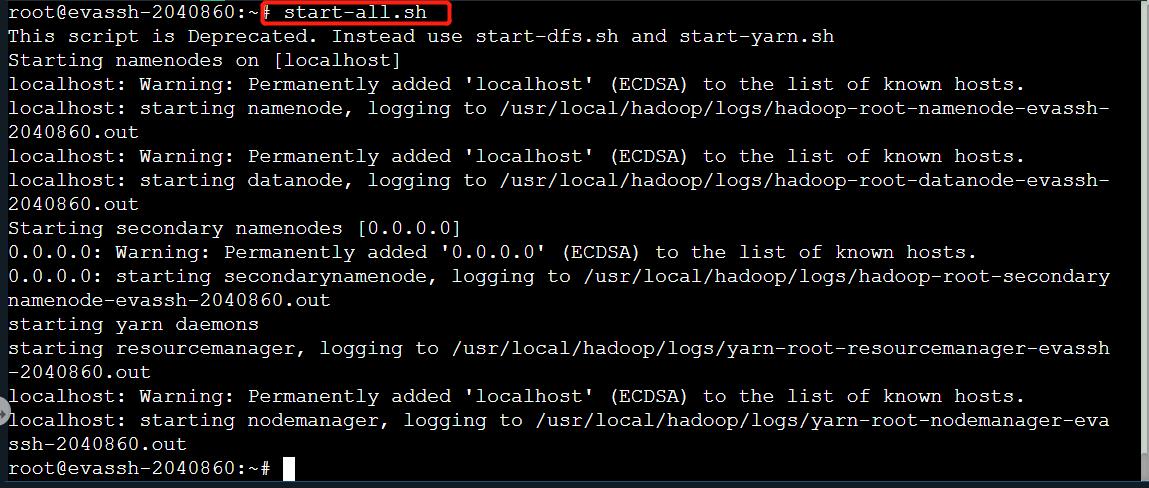
2、Hive 连接 MySQL 初始化。
schematool -dbType mysql -initSchema

编程要求
在右侧命令行进行操作: 1.启动Hadoop服务; 2.Hive 连接 MySQL 初始化。
测试说明
完成操作后点击评测,通关后测试集输出:
Hadoop平台已开启
default参考答案
#以下为命令行
start-all.sh
schematool -dbType mysql -initSchema第2关:Mysql导入数据至HDFS上
任务描述
本关任务:利用 Sqoop 工具将 MySQL 中的数据导入到 HDFS 中来。
相关知识
为了完成本关任务,你需要掌握:
1、数据库( MySQL )建表。
2、Mysql 数据导入至 HDFS 中。
数据库( MySQL )建表
用命令进入 MySQL 客户端。
mysql -uroot -p123123 -h127.0.0.1
创建数据库hdfsdb(格式默认为utf8),并在数据库内建立表student,其表结构如下:
| 名 | 类 | 状态 |
|---|---|---|
| stu_no | int | 主键 |
| stu_name | varchar(20) | 学生姓名 |
| stu_age | int | 学生年龄 |
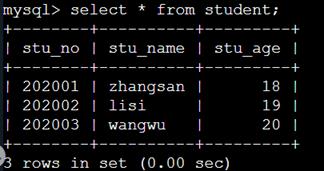
在表内插入数据。
| stu_no | stu_name | stu_age |
|---|---|---|
| 202001 | zhangsan | 18 |
| 202002 | lisi | 19 |
| 202003 | wangwu | 20 |
检查是否成功。
MySQL数据导入至HDFS中
1、简单导入。
sqoop import --connect jdbc:mysql://127.0.0.1:3306/hdfsdb --username root --password 123123 --table student这里没有指定 HDFS 的目录 默认会将数据存到系统当前登录用户下 以表名称命名的文件夹下。

系统默认为逗号隔开,如下图:
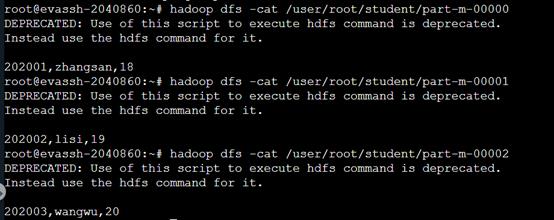
注意:如果数据库没有设置主键,语法需要加上--split by指定一个列去分割或用-m 1指定一个 Map 任务。
2、指定 HDFS 目录/user/root/hdfsdb导入,指定一个 MapReduce 任务。
sqoop import --connect jdbc:mysql://127.0.0.1:3306/hdfsdb --usernameroot --password 123123 --table student --target-dir /user/root/hdfsdb -m 1--target-dir:指定 HDFS 目录。-m 1:指定一个 MapReduce 任务。
3、指定查询学生的学号与学生姓名存入到/user/root/hdfsdb2中,指定一个MapReduce 任务,并以|分隔。
sqoop import --connect jdbc:mysql://127.0.0.1:3306/hdfsdb --username root --password 123123 --query 'select stu_no, stu_name from student where $CONDITIONS' --target-dir /user/root/hdfsdb2 --fields-terminated-by '|' -m 1--query:通过用 sql 语句来将数据导入,where $CONDITIONS是query中固定语法,不可删去。--fields-terminated-by:数据通过什么来隔开。

编程要求
根据上述,将 MySQL 数据库hdfsdb中的表数据导入至HDFS中,要求如下:
- 指定 HDFS 目录
/user/root/hdfsdb3。 - 查询学生姓名与年龄。
- 指定一个 Mapreduce 任务。
- 存储以
-来分割。
测试说明
点击测评,当你的结果与预期输出一致时,即为通过。
zhangsan-18
lisi-19
wangwu-20参考答案
#以下为命令行内容
mysql -uroot -p123123 -h127.0.0.1
#以下为MySQL内容
#创建hdfsdb数据库
create database hdfsdb;
#切换hdfsdb数据库
use hdfsdb;
#创建student表
create table student(stu_no int primary key,stu_name varchar(20),stu_age int);
#插入三条数据
insert into `student` values(202001,'zhangsan',18);
insert into `student` values(202002,'lisi',19);
insert into `student` values(202003,'wangwu',20);
exit;#以下为命令行内容
#MySQL数据导入至HDFS中-简单导入
sqoop import --connect jdbc:mysql://127.0.0.1:3306/hdfsdb --username root --password 123123 --table student
#指定 HDFS 目录/user/root/hdfsdb导入,指定一个 MapReduce 任务
sqoop import --connect jdbc:mysql://127.0.0.1:3306/hdfsdb --username root --password 123123 --table student --target-dir /user/root/hdfsdb -m 1
#指定查询学生的学号与学生姓名存入到/user/root/hdfsdb2中,指定一个MapReduce任务,并以“|”分隔
sqoop import --connect jdbc:mysql://127.0.0.1:3306/hdfsdb --username root --password 123123 --query 'select stu_no, stu_name from student where $CONDITIONS' --target-dir /user/root/hdfsdb2 --fields-terminated-by '|' -m 1
#编程实现内容
sqoop import --connect jdbc:mysql://127.0.0.1:3306/hdfsdb --username root --password 123123 --query 'select stu_name,stu_age from student where $CONDITIONS' --target-dir /user/root/hdfsdb3 --fields-terminated-by '-' -m 1
第3关:Mysql导入数据至Hive中
任务描述
本关任务:利用 Sqoop 工具将 MySQL 中的数据导入到 Hive 中来。
相关知识
为了完成本关任务,你需要掌握:MySQL 数据导入至 Hive 中。
MySQL 数据导入至Hive
1、直接导入。 我们可以使用上一关的数据库,如果没有的话,需要重新创建。
sqoop import --connect jdbc:mysql://127.0.0.1:3306/hdfsdb --username root --password 123123 --table student --hive-import -m1 --hive-table test
这里会发生一个报错,如图:

解决方法 这里缺少了hive-common-3.1.0.jar包,我们在 Hive 的lib目录下,拷贝到 Sqoop 的lib目录下即可。
cp /opt/hive/lib/hive-common-3.1.0.jar /opt/sqoop-1.4.7.bin__hadoop-2.6.0/lib/
这边输出文件经过上次已经创建好了,所以我们要不自己手动删除,要不用sqoop参数: --delete-target-dir:如果输出文件存在,则先删除。
sqoop import --connect jdbc:mysql://127.0.0.1:3306/hdfsdb --username root --password 123123 --table student --hive-import --delete-target-dir -m1 --hive-table test
成功之后我们可以通过hive来查看是否成功传输。

2、通过传输至HDFS上,Hive再从HDFS导入数据。 MySQL数据导入至Hive。
sqoop import --connect jdbc:mysql://127.0.0.1:3306/hdfsdb --username root --password 123123 --table student -m 1
Hive依据格式建表。
hive> create table test1(
> stu_no int,stu_name string,stu_age int)
> row format delimited
> fields terminated by ",";从HDFS导入数据。
load data inpath '/user/root/student/part-m-00000' into table test1;

查看是否成功。
编程要求
将学生年龄大于20的学生信息放入Hive表test2中,要求如下:
- 指定一个Mapreduce任务。
- 指定分隔符为
,。
测试说明
点击测评,当你的结果与预期输出一致时,即为通过。
202003,wangwu,20参考答案
##确认没有重置命令行,没有超时清空,上一关的数据库还在
##如果重置过命令行,请先按顺序重做以下注释内容(粘贴到本地代码编辑器以VSCode为例,将BEGIN到END内容复制到本地编辑器,快捷键Ctrl+/取消一层注释):
##----------------BEGIN----------------
## 命令行
#start-all.sh
#schematool -dbType mysql -initSchema
#mysql -uroot -p123123 -h127.0.0.1
## MYSQL
#create database hdfsdb;
#use hdfsdb;
#create table student(stu_no int primary key,stu_name varchar(20),stu_age int);
#insert into `student` values(202001,'zhangsan',18);
#insert into `student` values(202002,'lisi',19);
#insert into `student` values(202003,'wangwu',20);
#exit;
## 命令行
#sqoop import --connect jdbc:mysql://127.0.0.1:3306/hdfsdb --username root --password 123123 --table student
#sqoop import --connect jdbc:mysql://127.0.0.1:3306/hdfsdb --username root --password 123123 --table student --target-dir /user/root/hdfsdb -m 1
#sqoop import --connect jdbc:mysql://127.0.0.1:3306/hdfsdb --username root --password 123123 --query 'select stu_no, stu_name from student where $CONDITIONS' --target-dir /user/root/hdfsdb2 --fields-terminated-by '|' -m 1
#sqoop import --connect jdbc:mysql://127.0.0.1:3306/hdfsdb --username root --password 123123 --query 'select stu_name,stu_age from student where $CONDITIONS' --target-dir /user/root/hdfsdb3 --fields-terminated-by '-' -m 1
##-----------------END-----------------
#以下为命令行
#MySQL 数据导入至Hive
sqoop import --connect jdbc:mysql://127.0.0.1:3306/hdfsdb --username root --password 123123 --table student --hive-import -m1 --hive-table test
#报错缺少了hive-common-3.1.0.jar包,复制到 Sqoop 的lib目录下
cp /opt/hive/lib/hive-common-3.1.0.jar /opt/sqoop-1.4.7.bin__hadoop-2.6.0/lib/
#再次执行导入(上次执行的若存在先删除)
sqoop import --connect jdbc:mysql://127.0.0.1:3306/hdfsdb --username root --password 123123 --table student --hive-import --delete-target-dir -m1 --hive-table test
#成功之后我们可以通过hive来查看是否成功转输
hive--以下为hive
--查看表
show tables;
--出现上一关的数据则成功导入
select * from test;
exit;#以下为命令行
#通过传输至HDFS上,Hive再从HDFS导入数据
sqoop import --connect jdbc:mysql://127.0.0.1:3306/hdfsdb --username root --password 123123 --table student -m 1
hive--以下为hive
create table test1(
stu_no int,stu_name string,stu_age int)
row format delimited
fields terminated by ",";
--从HDFS导入数据
load data inpath '/user/root/student/part-m-00000' into table test1;
--查看是否成功
select * from test1;
--编程要求
#将学生年龄大于20的学生信息放入Hive表test2中,要求如下:
----指定一个Mapreduce任务。
----指定分隔符为‘,’。
--创建test2表
create table test2(
stu_no int,stu_name string,stu_age int)
row format delimited
fields terminated by ",";
exit;
#以下为命令行
sqoop import --connect jdbc:mysql://127.0.0.1:3306/hdfsdb --username root --password 123123 --query 'select stu_no, stu_name,stu_age from student where stu_age>=20 and $CONDITIONS' --target-dir /user/root/hdfsdb6 --fields-terminated-by ',' -m 1
hive--以下为hive
load data inpath '/user/root/hdfsdb6/part-m-00000' into table test2;至此,所有内容都完成辣。如果存在任何问题欢迎大佬指教🥰!
头歌Sqoop数据导出 - 详解
【提示】点击每一关参考答案可以快速复制。
目录
第1关:Sqoop数据导出语法学习
任务描述
本关任务:学习Sqoop 导出( export )的基本语法并配置好环境。
相关知识
为了完成本关任务,你需要掌握: 1、Sqoop 导出( export )的基本参数。 2、配置环境。
Sqoop 导出( export )的基本参数。
Sqoop 能够让 Hadoop 上的 HDFS 和 Hive 跟关系型数据库之间进行数据导入与导出,多亏了import和export这两个工具。本实训主要是针对export(导出)来讲。 数据在Hadoop平台上进行处理后,我们可能需要将结果同步到关系数据库中作为业务的辅助数据,这时候需要将Hadoop平台分析后的数据导出(export)到关系数据库。 我们要学 Sqoop 的导出也必须先知道里面的基本语法。 输入sqoop help export可以查看里面参数含义,导出和导入基本参数都差不多,接下来选取几个常见的参数来分析:
| 选项 | 含义说明 |
|---|---|
--connect <jdbc-uri> | 指定JDBC连接字符串 |
--driver <class-name> | 指定要使用的JDBC驱动程序类 |
--hadoop-mapred-home <dir> | 指定$HADOOP_MAPRED_HOME路径 |
| -P | 从控制台读取输入的密码 |
--username <username> | 设置认证用户名 |
--password <password> | 设置认证密码 |
| --verbose | 打印详细的运行信息 |
--columns <col,col,col…> | 要导出到表格的列 |
| --direct | 使用直接导入模式(优化导入速度 |
--export-dir <dir> | 用于导出的HDFS源路径 |
--num-mappers <n>(简写:-m) | 使用n个mapper任务并行导出 |
--table <table-name> | 要填充的表 |
--staging-table <staging-table-name> | 数据在插入目标表之前将在其中展开的表格。 |
| --clear-staging-table | 表示可以删除登台表中的任何数据 |
| --batch | 使用批量模式导出 |
--fields-terminated-by <char> | 设置字段分隔符 |
--lines-terminated-by <char> | 设置行尾字符 |
--optionally-enclosed-by <char> | 设置字段包含字符 |
配置环境
注意:如果这个环境不配置的话,可能会造成后续关卡不能正常实现。 1、启动Hadoop。
start-all.sh
2、Hive连接 MySQL 初始化。
schematool -dbType mysql -initSchema
编程要求
在右侧命令行进行操作: 1.启动Hadoop服务; 2.Hive 连接 MySQL 初始化。
测试说明
完成操作后点击评测,通关后测试集输出:
Hadoop平台已开启
default参考答案
#命令行
#启动Hadoop
start-all.sh
#Hive连接 MySQL 初始化
schematool -dbType mysql -initSchema
第2关:HDFS数据导出至Mysql内
任务描述
本关任务:利用 Sqoop 工具将 HDFS 中的数据导出至 MySQL 中来。
相关知识
为了完成本关任务,你需要掌握: 1、数据库( MySQL )建表。 2、HDFS 数据导出至 MySQL 中。
数据库( MySQL )建表
因为这边 Sqoop 不能够帮关系型数据库创建表,所以需要我们自己来创建表。 用命令进入 MySQL 客户端。
mysql -uroot -p123123 -h127.0.0.1
创建数据库hdfsdb(格式默认为utf8),并在数据库内建立表fruit,其表结构如下:
| 名 | 类 | 状态 |
|---|---|---|
| fru_no | int | 主键 |
| fru_name | varchar(20) | |
| fru_price | int | |
| fru_address | varchar(20) |
HDFS 数据导出至 MySQL 中
将数据放入 HDFS 上 输入vi text.txt,内容如下:
01,apple,6,changsha
02,banana,4,shanghai
03,orange,2,guangzhou将文件上传HDFS
hadoop fs -put text.txt /userHDFS 数据导出至 MySQL中 。
sqoop export --connect jdbc:mysql://127.0.0.1:3306/hdfsdb --username root --password 123123 --table fruit --export-dir /user/text.txt -m 1查看 Mysql 中的表,发现数据已经传输过去了。

编程要求
根据上述,成功用 Sqoop 将 HDFS 上的数据导出 MySQL 成功。
测试说明
点击测评,当你的结果与预期输出一致时,即为通过。
HDFS存在text.txt文件
传输成功!参考答案
#命令行
#进入MySQL
mysql -uroot -p123123 -h127.0.0.1
#以下为MySQL
#创建数据库hdfsdb
create database `hdfsdb`;
#切换数据库hdfsdb
use `hdfsdb`;
#创建数据表fruit
create table `fruit`(
fru_no int primary key,
fru_name varchar(20),
fru_price int,
fru_address varchar(20)
);
quit;
#命令行
#编辑text文本文件
vi text.txt
#以下为在vi编辑器中需要输入的内容。
#使用提示:【i】键进入插入模式,鼠标滚轮可以快速上下滑动光标,执行对应插入操作,最后【Esc】键退出vi插入模式,输入“:wq”保存并退出vi编辑器。
#使用提示:PageUp(PgUp)、PageDown(PgDn)键快速定位光标到文件开始位置和结束位置,Home、End键快速定位光标到当前行的行首和行末。
01,apple,6,changsha
02,banana,4,shanghai
03,orange,2,guangzhou#命令行
#将文件上传HDFS
hadoop fs -put text.txt /user
#HDFS 数据导出至 MySQL中
sqoop export --connect jdbc:mysql://127.0.0.1:3306/hdfsdb --username root --password 123123 --table fruit --export-dir /user/text.txt -m 1
#查看MySQL数据
mysql -uroot -p123123 -h127.0.0.1#以下为MySQL
#查看 Mysql 中的表,发现数据已经传输过去了
use hdfsdb;
select * from `fruit`;
quit;第3关:Hive数据导出至MySQL中
任务描述
本关任务:利用 Sqoop 工具将 Hive 中的数据导出至 MySQL 中。
相关知识
为了完成本关任务,你需要掌握:Hive 数据导出至 MySQL 中。
Hive 数据导入 MySQL 中
MySQL建表
因为之前已经创建过数据库了,我们直接使用之前的数据库hdfsdb,在数据库中建表project,表结构如下:
| 名 | 类 | 状态 |
|---|---|---|
| pro_no | int | 主键,序号 |
| pro_name | varchar(20) | 课程名 |
| pro_teacher | varchar(20) | 课程老师 |
# 首先进入MySQL
mysql -uroot -p123123 -h127.0.0.1
# 进入MySQL后使用数据库 hdfsdb
use hdfsdb;
# 创建表 project
create table project(pro_no int,pro_name varchar(20),pro_teacher varchar(20), primary key (pro_no));Hive中建表添加数据
新建并编辑文本project.txt,添加以下内容:
01,bigdata,wang
02,javaweb,yang
03,python,xiang输入pwd,获取当前路径。
进入Hive,在Hive内创建表project。
create table project (pro_no int,pro_name string, pro_teacher string) row format delimited fields terminated by ',' stored as textfile;在表中插入刚刚创建的数据,位置为刚刚路径下的project.txt。
load data local inpath './project.txt' into table project;
查看是否添加成功。
Hive 数据导出至 MySQL。
sqoop export --connect jdbc:mysql://127.0.0.1:3306/hdfsdb --username root --password 123123 --table project --export-dir /opt/hive/warehouse/project -m 1 --input-fields-terminated-by ','我们查看 MySQL 中,发现数据已经传输过去了。
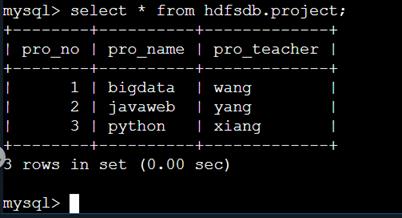
编程要求
根据上述,将Hive表中数据导出到mysql中。
测试说明
点击测评,当你的结果与预期输出一致时,即为通过。
hive建表成功
传输成功!参考答案
#命令行
#进入mysql
mysql -uroot -p123123 -h127.0.0.1
#以下为MySQL
#切换数据库
use hdfsdb;
#创建表 project
create table project(pro_no int,pro_name varchar(20),pro_teacher varchar(20), primary key (pro_no));
quit;#命令行
#新建并编辑文本project.txt
vi project.txt
#以下为在vi编辑器中需要输入的内容。
#使用提示:【i】键进入插入模式,鼠标滚轮可以快速上下滑动光标,执行对应插入操作,最后【Esc】键退出vi插入模式,输入“:wq”保存并退出vi编辑器。
#使用提示:PageUp(PgUp)、PageDown(PgDn)键快速定位光标到文件开始位置和结束位置,Home、End键快速定位光标到当前行的行首和行末。
01,bigdata,wang
02,javaweb,yang
03,python,xiang#命令行
#输入pwd,获取当前路径
pwd
#进入Hive,在Hive内创建表project
hive--以下为Hive
--创建表project
create table project (pro_no int,pro_name string, pro_teacher string) row format delimited fields terminated by ',' stored as textfile;
--在表中插入刚刚创建的数据,位置为刚刚路径下的project.txt
load data local inpath './project.txt' into table project;
--查看是否添加成功
select * from project;
quit;#命令行
#Hive 数据导出至 MySQL
sqoop export --connect jdbc:mysql://127.0.0.1:3306/hdfsdb --username root --password 123123 --table project --export-dir /opt/hive/warehouse/project -m 1 --input-fields-terminated-by ','至此,所有内容都完成辣。如果存在任何问题欢迎大佬指教🥰!
以上是关于头歌Sqoop数据导入 - 详解的主要内容,如果未能解决你的问题,请参考以下文章