爬虫-day1-正则表达式作业
Posted 亲爱的阿瞎
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了爬虫-day1-正则表达式作业相关的知识,希望对你有一定的参考价值。
利用正则表达式完成下面的操作:
一、不定项选择题
-
能够完全匹配字符串"(010)-62661617"和字符串"01062661617"的正则表达式包括(ABD )
A.
r"\\(?\\d3\\)?-?\\d8"
B.r"[0-9()-]+"
C.r"[0-9(-)]*\\d*"
D.r"[(]?\\d*[)-]*\\d*" -
能够完全匹配字符串"back"和"back-end"的正则表达式包括(ABCD )
A.r'\\w4-\\w3|\\w4'
B.r'\\w4|\\w4-\\w3'
C.r'\\S+-\\S+|\\S+'
D.r'\\w*\\b-\\b\\w*|\\w*' -
能够完全匹配字符串"go go"和"kitty kitty",但不能完全匹配“go kitty”的正则表达式包括(AD)
A.r'\\b(\\w+)\\b\\s+\\1\\b'
B.r'\\w2,5\\s*\\1'
C.r'(\\S+) \\s+\\1'
D.r'(\\S2,5)\\s1,\\1' -
能够在字符串中匹配"aab",而不能匹配"aaab"和"aaaab"的正则表达式包括(BC)
A.r"a*?b"
B.r"a,2b"
C.r"aa??b"
D.r"aaa??b"
二、编程题
1.用户名匹配
要求: 1.用户名只能包含数字 字母 下划线
2.不能以数字开头
3.⻓度在 6 到 16 位范围内
user_name = input('请输入用户名:')
result = fullmatch(r'\\D[\\d_a-zA-Z]6,16', user_name)
if result:
print('用户名正确!')
else:
print('用户名错误!')
- 密码匹配
要求: 1.不能包含!@#¥%^&*这些特殊符号
2.必须以字母开头
3.⻓度在 6 到 12 位范围内
password = '!dhjhjh'
result = fullmatch(r'[a-zA-Z][^!@#¥%^&*]6,12', password)
if result:
print('密码正确!')
else:
print('密码错误!')
- ipv4 格式的 ip 地址匹配
提示: IP地址的范围是 0.0.0.0 - 255.255.255.255
- 提取用户输入数据中的数值 (数值包括正负数 还包括整数和小数在内) 并求和
例如:“-3.14good87nice19bye” =====> -3.14 + 87 + 19 = 102.86
-
验证输入内容只能是汉字
str1 = input('请输入内容:') result = fullmatch(r'[\\u4e00-\\u9fa5]*', str1) if result: print('输入正确!') -
匹配整数或者小数(包括正数和负数)
result = fullmatch(r'[+-]?[\\d.]*', '-23') print(result) -
验证输入用户名和QQ号是否有效并给出对应的提示信息
要求:
用户名必须由字母、数字或下划线构成且长度在6~20个字符之间
QQ号是5~12的数字且首位不能为0user_name = input('输入用户名:') qq = input('输入QQ号:') result = fullmatch(r'[a-zA-Z\\d_]*', user_name) if result: print('用户名有效') else: print('用户名无效,请输入字母、数字或下划线构成且长度在6~20个字符之间') result = fullmatch(r'[1-9]\\d5,11', qq) if result: print('QQ号有效') else: print('QQ号无效,请输入5~12的数字且首位不能为0') -
拆分长字符串:将一首诗的中的每一句话分别取出来
poem = ‘窗前明月光,疑是地上霜。举头望明月,低头思故乡。’
poem = '窗前明月光 for x in spli print(x)提取豆瓣Top250的的以下信息
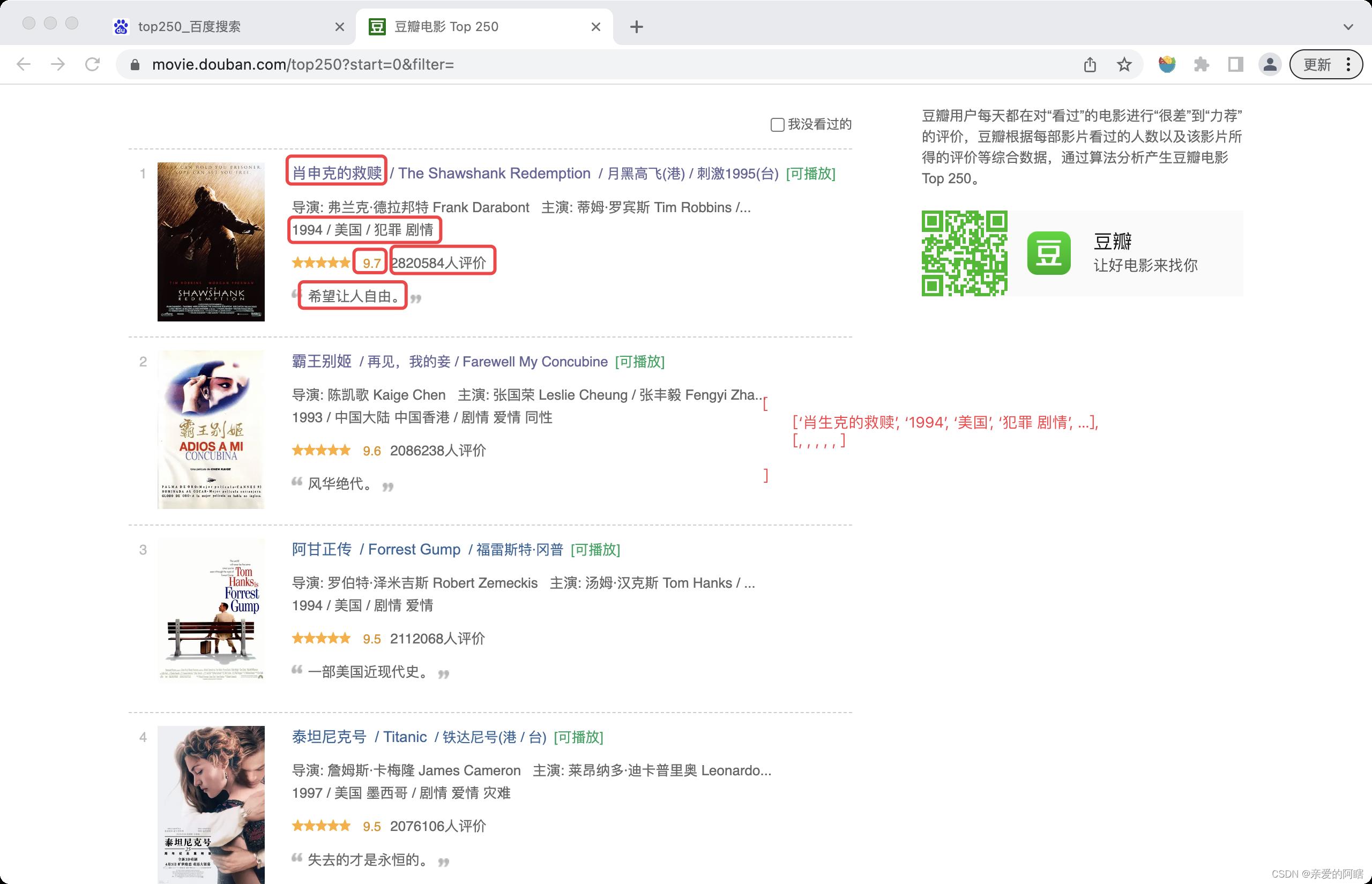
name = findall(r'<span class="title">([\\u4e00-\\u9fa5]*?)</span>|(\\d*) / (.*) / (.*)|<span class="inq">(.+)</span>|property="v:average">(\\d\\.\\d)</span>|<span>(\\d+)人评价</span>', response.text)
# print(name)
list1= []
for i in range(0, len(name)-1, 5):
list1.append(list(set(name[i])|set(name[i+1])|set(name[i+2])|set(name[i+3])|set(name[i+4])))
for x in list1:
del x[0]
print(list1)
python爬虫 Day 6
正则表达式上
正则表达式
1.定义
正则表达式是对字符操作的一种逻辑公式,就是用事先定义好的一些特定字符以及这些特定字符的组合,组成一个“规则字符串”,这个规则字符串用来表达对字符串的一种过滤逻辑
2.作用
(1)表单验证(例如:手机号、邮箱、身份证)
(2)爬虫--从网页源码中提取数据
3.正则表达式对python的支持
(1)普通字符:字母、数字、汉字、下划线、以及没有特殊含义的符号
(2)正则中的普通字符:在匹配的时候只匹配与自身相同的一个字符
4.例子
表达式c,在匹配字符串abcde时
匹配结果:成功
匹配到的内容:c
匹配到的位置:开始于2,结束于3
match()函数
1.模板
match(pattern, string, flags=0)
2.含义
(1)pattern: 是指正则表达式,如果匹配成功,则返回一个match对象,否则返回一个None
(2)string: 是指要匹配的字符串
(3)flags=0: 是标致位,用于控制正则表达式的匹配方式,如是否区分大小写,多行匹配等
元字符
用来表示一些特殊含义或者功能
| 表达式 | 匹配 |
|---|---|
| . | 小数点可以匹配除了换行符\\n以外的任意一个字符 |
| | | 逻辑或字符 |
| [] | 匹配字符集中的任意一个字符 |
| [^] | 对字符集求反,也就是上面的补集。^必须在方括号的最前面 |
| - | 定义[ ]里的一个字符区间,例如a-z |
| \\ | 对紧跟其后的一个字符进行转义 |
| () | 对表达式进行分组,将圆括号内的内容当作一个整体,并获得匹配的值 |
一些无法书写或者具有特殊功能的字符,采用在前面加斜杠进行转义的方法
| 表达式 | 匹配 |
|---|---|
| \\r | 回车 |
| \\n | 换行符 |
\\\\ | 斜杠 |
\\^ | ^ |
\\$ | $ |
\\. | . |
预定义匹配字符集
可以同时匹配某个预定义字符集中的任意一个字符
| 表达式 | 匹配 |
|---|---|
| \\d | 0-9 中的任意一个数字 |
| \\w | A-Z, a-z,_中的任意一个字符 |
| \\s | 空格、制表符、换页符等空白字符的其中一个 |
| \\D | \\d的补集 |
| \\W | \\w的补集 |
| \\S | \\s的补集 |
重复匹配
| 表达式 | 匹配 |
|---|---|
| {n} | 表达式至少重复n次 |
| {m,n} | 表达式至少重复m次,至多重复n次 |
| {m,} | 表达式至少重复m次 |
| ? | 表达式出现0或者1次 |
| + | 表达式至少出现1次 |
| * | 表达式出现0到任意次 |
代码
(1)代码re_match
import re
# s就是待匹配的数据
s = \'python and java\'
# ptn就是匹配的模板
ptn = \'python\'
result = re.match(ptn, s)
# print(result)
if result:
print(result.group())
else:
print(\'匹配失败!\')(2)代码re_examples--元字符
import re
# 元字符
# . 匹配除了换行符之外的任意一个字符
# a.c 匹配以a开头 c结尾 中间任意一个除换行以外的字符
e1 = re.match(\'a.c\', \'abc\').group()
print(e1)
e2 = re.match(\'a.c\', \'a我c\').group()
print(e2)
e3 = re.match(\'a.c\', \'a\\nc\').group()
print(e3) # 报错
# r 原生字符串 不需要进行转义了 原本python解释器和正则都将会进行转义
print(\'\\\\\\\\\')
print(r\'\\\\\\\\\')
# | 逻辑或操作符
a|b用来匹配a或者是b
print(re.match(\'a|b\', \'a\').group())
print(re.match(\'a|c\', \'c\').group())
print(re.match(\'a|b|c|d\', \'cd\').group()) # 只有一个c哦
# match是从头开始匹配的 一旦匹配失败就结束了 返回第一个匹配结果
e1 = re.match(\'a|b\', \'ba\').group()
print(e1)
e2 = re.match(\'a|c\', \'ba\').group()
print(e2) # 报错
e3 = re.search(\'a|c\', \'cba\').group()
print(e3) # search 和 match 之间的区别
# []匹配字符集中的一个字符
f1 = re.match(\'[abc]\', \'cba\').group()
print(f1)
f2 = re.match(\'[abc]\', \'zba\').group()
print(f2) # 报错
f3 = re.match(\'[abc]2\', \'a\').group()
print(f3) # 报错
f3 = re.match(\'[abc]2\', \'a2\').group()
print(f3) # 可以用来匹配a2 b2 c2
# [^] 对字符集求反,也就是反操作 尖号必须在方括号的最前面
g1 = re.match(\'[^abc]3\', \'a3\').group()
print(g1) # 报错
g2 = re.match(\'[^abc]3\', \'g3\').group()
print(g2)
# \\ 对紧跟其后的一个字符进行转义(如果没有r的话)
h1 = re.match(r\'5.6\', \'5.6\').group()
print(h1)
h2 = re.match(r\'5.6\', \'596\').group()
print(h2)
h3 = re.match(r\'5\\.6\', \'596\').group()
print(h3) # 报错 \\. 表示.
h4 = re.match(r\'5\\.6\', \'5.6\').group()
print(h4) # 可以运行(3)代码re_examples--预定义匹配字符
# 预定义匹配字符集:可以同时匹配某个预定义字符集中的任意一个字符
# \\d 匹配0-9中的任意一个字符
k1 = re.match(r\'123\', \'123\').group()
print(k1)
k2 = re.match(r\'\\d\', \'123\').group()
print(k2)
k3 = re.match(r\'\\d\\d\\d\', \'123\').group()
print(k3)
# \\w 匹配字母或数字或下划线的任意一个字符
m1 = re.match(r\'\\w\', \'b123\').group()
print(m1)
m2 = re.match(r\'\\w\', \'S123\').group()
print(m2)
m3 = re.match(r\'\\w\', \'123\').group()
print(m3)
m4 = re.match(r\'\\w\', \'_123\').group()
print(m4)
# \\s 匹配空格、制表符、换行符、空白等(1个)
n1 = re.match(r\'\\s1\', \' 1\').group()
print(n1)
n2 = re.match(r\'\\s2\', \'\\t2\').group()
print(n2)
n3 = re.match(r\'\\s3\', \'\\n3\').group()
print(n3)(4)代码re_examples--重复匹配
# 重复匹配
# # {n} 表示表达式重复的匹配n次
p1 = re.match(r\'\\d{4}\', \'1231\').group()
print(p1)
# {m, n}表示表达式至少重复m次, 至多重复n次
q1 = re.match(r\'\\d{3,4}-\\d{7,8}\', \'1234-1234567\').group()
print(q1)
print(re.match(r\'\\d{3,4}-\\d{7,9}\', \'12345-1234567\').group())
print(re.match(r\'\\d{3,4}-\\d{7,9}\', \'1234-1234567\').group())
print(re.match(r\'\\d{3,4}-\\d{6,7}\', \'1234-123456789\').group())
# {m,) 表示至少匹配m次 没有上限
ptn1 = r\'\\d{3,4}-\\d{6,}\'
s1 = re.match(ptn1, \'1234-123456789111111111111111111111111111111\').group()
print(s1)
# + 表示至少匹配1次 相当于{1,} a+b ab/aab/aaab
print(re.match(r\'w[a-z]\', \'wa\').group())
print(re.match(r\'w[a-z]+\', \'wa\').group())
print(re.match(r\'w[a-z]+\', \'wee\').group())
print(re.match(r\'w[a-z]+\', \'w\').group()) # 报错
# * 表示表达式出现0到任意次数
print(re.match(r\'w[a-z]*\', \'w\').group())
print(re.match(r\'w[a-z]*\', \'weeeeeeeee\').group())
print(re.match(r\'w[a-z]*\', \'1\').group()) # 报错以上是关于爬虫-day1-正则表达式作业的主要内容,如果未能解决你的问题,请参考以下文章