Spark-ETL日志数据清洗分析项目(上)--个人学习解析(保姆级)
Posted weixin_53414609
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spark-ETL日志数据清洗分析项目(上)--个人学习解析(保姆级)相关的知识,希望对你有一定的参考价值。
此篇内容仅为1.日志数据清洗
需求:对test.log中的数据进行如下操作
1.日志数据清洗
2.用户留存分析
3.活跃用户分析
4.将各结果导入mysql
使用工具:IDEA,Maven工程下的Scala项目
数据清洗原理解析:
/**此项目清洗数据的内容主要是解析url内的用户行为 1.将初始数据转换成dataFrame型(代码中为orgDF),结构为row(表示一个行的数据),schema(描述dataFrame结构,也可以理解为行的各个属性名称) 2.进行一系列初筛后,得出url解析出来的RDD[ROW](代码中为detailRDD),新的schema(代码中为detailSchema),组成新的dataFrame */
pom.xml依赖设置如下
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.spark</groupId>
<artifactId>stream</artifactId>
<version>1.0-SNAPSHOT</version>
<inceptionYear>2008</inceptionYear>
<properties>
<spark.version>2.4.3</spark.version>
<scala.version>2.12</scala.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_$scala.version</artifactId>
<version>$spark.version</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_$scala.version</artifactId>
<version>$spark.version</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_$scala.version</artifactId>
<version>$spark.version</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_$scala.version</artifactId>
<version>$spark.version</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.spark/spark-streaming-kafka-0-10 -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming-kafka-0-10_$scala.version</artifactId>
<version>$spark.version</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-catalyst_$scala.version</artifactId>
<version>$spark.version</version>
</dependency>
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>14.0.1</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.scalikejdbc/scalikejdbc -->
<dependency>
<groupId>org.scalikejdbc</groupId>
<artifactId>scalikejdbc_$scala.version</artifactId>
<version>3.3.5</version><!-- mysql " mysql-connector-java -->
</dependency>
<!-- https://mvnrepository.com/artifact/mysql/mysql-connector-java -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.17</version>
</dependency>
</dependencies>
</project>一、日志数据清洗
1)分析test.log数据
其由event_time
url
method
status
sip
user_uip
action_prepend
action_client
这八个字段组成,此次清洗内容主要针对url内各用户的不同的响应分析
2)建立spark程序,从本地磁盘读取数据生成rdd(string)
val spark = SparkSession.builder().master("local[1]").appName("DataClear").getOrCreate()
import spark.implicits._
val sc = spark.sparkContext
val linesRDD = sc.textFile("D:\\\\CODE\\\\test.log")
//sc.textFile是常用的将文本数据直接转化为rdd的方法3)进行初次清洗数据
test.log中各列属性由 '\\t' 进行分隔,所以可以首先用split将每一列属性切分出来
以及为了最后初次清洗出来数据的统一完整性(保证每一行数据都有八列属性值),我们还要使用filter方法将字段少于8的行过滤
再使用trim将每行的每一列数据的非空白字段的部分截取出来
//按照 \\t 分割数据,过滤字段数(即列数)少于8的
val line1 = linesRDD.map(x => x.split("\\t"))
//取字符串内非空白字段(trim) rdd与row结合即RDD[ROW]
val rdd = line1.filter(x => x.length == 8).map(x => Row(x(0).trim, x(1).trim, x(2).trim, x(3).trim, x(4).trim, x(5).trim, x(6).trim, x(7).trim))创建structType实例后再创建dataFrame,因为我们最终数据是以dataFrame型的数据进行存储
而dataFrame组成结构是(RDD,Schema)即一个RDD[ROW]型和一个StructType型组成
dataFrame结构也可以理解为RDD是一行具体的数据,Schema是每行数据的属性名称
//创建structType实例,设置字段名和类型
val schema = StructType(Array(
StructField("event_time", StringType), //用户浏览时间
StructField("url", StringType), //URL地址
StructField("method", StringType), //GET
StructField("status", StringType), //状态码
StructField("sip", StringType), //IP地址
StructField("user_uip", StringType), //用户UID
StructField("action_prepend", StringType), //用户操作前置
StructField("action_client", StringType) //用户客户端
))
//创建dataFrame
val orgDF = spark.createDataFrame(rdd, schema)
orgDF.show(5)4)具体到主要对url字段进行清洗
*以第一,第二列的数据对所有行数据进行去重
*过滤状态码非200的行
*过滤event_time为空的数据
*将url按照'&'和'='切割
//按照第一列和第二列对数据数据去重,过滤掉状态码非200,过滤掉event_time为空的数据
//orgDF进行sql操作之后变成ds1 dataset[row]类型(也可以叫做dataFrame,只是dataset[row]比dataFrame封装内容更丰富,本质上还是属于dataframe范畴)
val ds1 = orgDF.dropDuplicates("event_time", "url")
.filter(x => x(3) == "200")
.filter(x => StringUtils.isNotEmpty(x(0).toString))
//将url按照"&"以及"="切割,即按照userUID
//userSID//userUIP//actionClient//actionBegin//actionEnd//actionType
//actionPrepend//actionTest//ifEquipment//actionName//id//progress进行切割
val dfDetail = ds1.map(row =>
val urlArray = row.getAs[String]("url").split("\\\\?") //将?前后的内容作切割
var map = Map("params" -> "null")
if (urlArray.length == 2) //此时urlArray分成 (?之前的内容,datacenter....)
map = urlArray(1)
.split("&").map(x => x.split("=")) //&是各属性之间的分隔符,=是各属性值指向什么方法或内容
.filter(_.length == 2).map(x => (x(0), x(1))) //将按照=切分后的数据存入map
.toMap
//.filter(_.length == 2)过滤掉以'='分割之后少于两个元素(即=两边出现的属性不为2个,不符合清洗标准的数据)的Array后再将各属性指向的内容map成规范化的式子
(row.getAs[String]("event_time"), //这里用getAs是因为它所对应的内容是每一行的url中必定有的元素
row.getAs[String]("user_uip"),
row.getAs[String]("method"),
row.getAs[String]("status"),
row.getAs[String]("sip"),
map.getOrElse("actionBegin", ""), //这里用getOrElse是因为url中不一定有这些元素,如果没有那就用空来替代异常值
map.getOrElse("actionEnd", ""),
map.getOrElse("userUID", ""),
map.getOrElse("userSID", ""),
map.getOrElse("userUIP", ""),
map.getOrElse("actionClient", ""),
map.getOrElse("actionType", ""),
map.getOrElse("actionPrepend", ""),
map.getOrElse("actionTest", ""),
map.getOrElse("ifEquipment", ""),
map.getOrElse("actionName", ""),
map.getOrElse("progress", ""),
map.getOrElse("id", "")
)
).toDF() //将ds1 dataSet[ROW]转成dfDetail 正常的dataFrame型清洗完毕后,"dfDetail"接收的是一组dataFrame数据,但是我们最后新的结构是以url的各个属性为框架的dataFrame
所以我们需要重构schema,即再定义一个新的"detailSchema",用来存放描述新的dataFrame结构的schema
将我们清洗提取出的"dfDetail"这个dataFrame数据用 .rdd 转化成RDD[ROW]格式,最后与以上述所述重构的schema创建detailDF这个新的dataFrame结构
val detailRDD = dfDetail.rdd //.rdd将dataFrame转换成rdd[ROW]类型
val detailSchema = StructType(Array( //重新定义schema结构
StructField("event_time", StringType),
StructField("user_uip", StringType),
StructField("method", StringType),
StructField("status", StringType),
StructField("sip", StringType),
StructField("actionBegin", StringType),
StructField("actionEnd", StringType),
StructField("userUID", StringType),
StructField("userSID", StringType),
StructField("userUIP", StringType),
StructField("actionClient", StringType),
StructField("actionType", StringType),
StructField("actionPrepend", StringType),
StructField("actionTest", StringType),
StructField("ifEquipment", StringType),
StructField("actionName", StringType),
StructField("progress", StringType),
StructField("id", StringType)
))
val detailDF = spark.createDataFrame(detailRDD, detailSchema) //重新创建新的dataFrame结构
detailDF.show(5,false) //truncate为false表示可以显示超过20个字符的数据最后将清洗完毕的数据存入mysql
作者事先在Linux中部署好了 mysql,在终端输入mysql -u root -p,输入mysql密码即可登入mysql
并创建了一个名为spark_dataclear的数据库
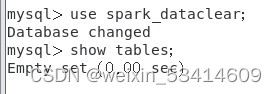
回到IDEA,用JDBC连接mysql将数据存入spark_dataclear数据库中
val url = "jdbc:mysql://hadoop01:3306/spark_dataclear"
val prop = new Properties()
prop.setProperty("user", "root")
prop.setProperty("password", "123456")
prop.setProperty("driver", "com.mysql.jdbc.Driver")
println("开始写入mysql")
detailDF.write.mode(saveMode = "overwrite").jdbc(url, "logDetail", prop) //指定输出到mysql的文件名为logDetail
// orgDF.write.mode("overwrite").jdbc(url,"",prop)
println("写入mysql结束")最后执行整个代码,部分代码结果如下
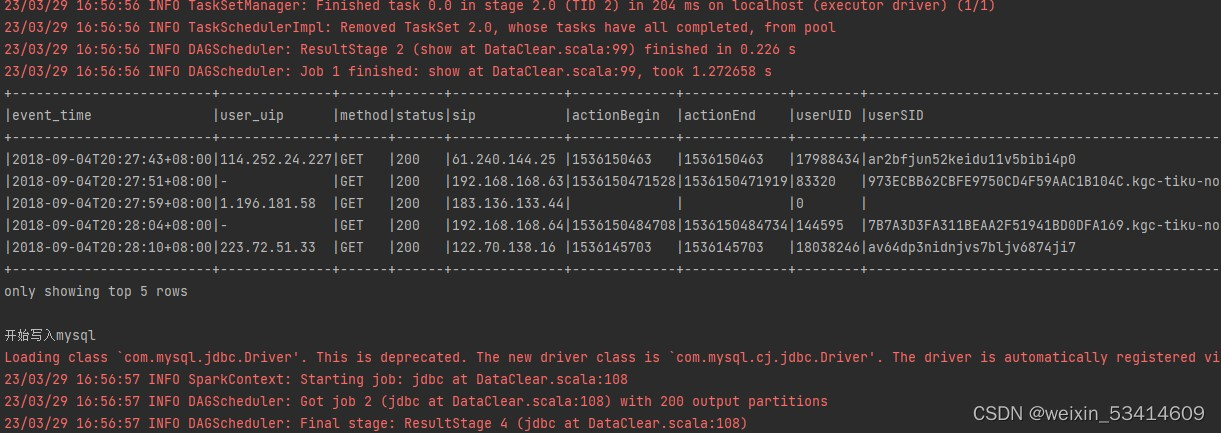
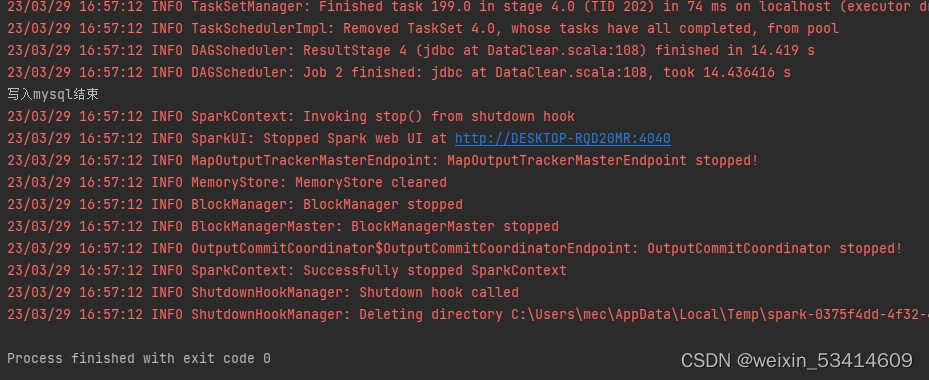
在mysql中查询表也有相应的数据结果

附完整代码:
import org.apache.commons.lang.StringUtils
import org.apache.spark.sql.types.StringType, StructField, StructType
import org.apache.spark.sql.Row, SparkSession
import java.util.Properties
/**原理解释:此项目清洗数据的内容主要是解析url内的用户行为
1.将初始数据转换成dataFrame型(代码中为orgDF),结构为row(表示一个行的数据),schema(描述dataFrame结构,也可以理解为行的各个属性名称)
2.进行一系列初筛后,得出url解析出来的RDD[ROW](代码中为detailRDD),新的schema(代码中为detailSchema),组成新的dataFrame
*/
object DataClear
def main(args: Array[String]): Unit =
val spark = SparkSession.builder().master("local[1]").appName("DataClear").getOrCreate()
import spark.implicits._
val sc = spark.sparkContext
val linesRDD = sc.textFile("D:\\\\CODE\\\\test.log")
//按照 \\t 分割数据,过滤字段数(即列数)少于8的
val line1 = linesRDD.map(x => x.split("\\t"))
//取字符串内非空白字段(trim) rdd与row结合即RDD[ROW]
val rdd = line1.filter(x => x.length == 8).map(x => Row(x(0).trim, x(1).trim, x(2).trim, x(3).trim, x(4).trim, x(5).trim, x(6).trim, x(7).trim))
// rdd.foreach(println)
//创建structType实例,设置字段名和类型
val schema = StructType(Array(
StructField("event_time", StringType), //用户浏览时间
StructField("url", StringType), //URL地址
StructField("method", StringType), //GET
StructField("status", StringType), //状态码
StructField("sip", StringType), //IP地址
StructField("user_uip", StringType), //用户UID
StructField("action_prepend", StringType), //用户操作前置
StructField("action_client", StringType) //用户客户端
))
//创建dataFrame
val orgDF = spark.createDataFrame(rdd, schema)
orgDF.show(5)
//按照第一列和第二列对数据数据去重,过滤掉状态码非200,过滤掉event_time为空的数据
//orgDF进行sql操作之后变成ds1 dataset[row]类型(也可以叫做dataFrame,只是dataset[row]比dataFrame封装内容更丰富,本质上还是属于dataframe范畴)
val ds1 = orgDF.dropDuplicates("event_time", "url")
.filter(x => x(3) == "200")
.filter(x => StringUtils.isNotEmpty(x(0).toString))
//将url按照"&"以及"="切割,即按照userUID
//userSID//userUIP//actionClient//actionBegin//actionEnd//actionType
//actionPrepend//actionTest//ifEquipment//actionName//id//progress进行切割
val dfDetail = ds1.map(row =>
val urlArray = row.getAs[String]("url").split("\\\\?") //将?前后的内容作切割
var map = Map("params" -> "null")
if (urlArray.length == 2) //此时urlArray分成 (?之前的内容,datacenter....)
map = urlArray(1)
.split("&").map(x => x.split("=")) //&是各属性之间的分隔符,=是各属性值指向什么方法或内容
.filter(_.length == 2).map(x => (x(0), x(1))) //将按照=切分后的数据存入map
.toMap
//.filter(_.length == 2)过滤掉分割之后还有两个元素(即两个&内的属性有多个,不符合清洗标准的数据)的Array后再将各属性指向的内容map成规范化的式子
(row.getAs[String]("event_time"), //这里用getAs是因为它所对应的内容是每一行的url中必定有的元素
row.getAs[String]("user_uip"),
row.getAs[String]("method"),
row.getAs[String]("status"),
row.getAs[String]("sip"),
map.getOrElse("actionBegin", ""), //这里用getOrElse是因为url中不一定有这些元素,如果没有那就用空来替代异常值
map.getOrElse("actionEnd", ""),
map.getOrElse("userUID", ""),
map.getOrElse("userSID", ""),
map.getOrElse("userUIP", ""),
map.getOrElse("actionClient", ""),
map.getOrElse("actionType", ""),
map.getOrElse("actionPrepend", ""),
map.getOrElse("actionTest", ""),
map.getOrElse("ifEquipment", ""),
map.getOrElse("actionName", ""),
map.getOrElse("progress", ""),
map.getOrElse("id", "")
)
).toDF() //将ds1 dataSet[ROW]转成dfDetail 正常的dataFrame型
val detailRDD = dfDetail.rdd //.rdd将dataFrame转换成rdd[ROW]类型
val detailSchema = StructType(Array( //重新定义schema结构
StructField("event_time", StringType),
StructField("user_uip", StringType),
StructField("method", StringType),
StructField("status", StringType),
StructField("sip", StringType),
StructField("actionBegin", StringType),
StructField("actionEnd", StringType),
StructField("userUID", StringType),
StructField("userSID", StringType),
StructField("userUIP", StringType),
StructField("actionClient", StringType),
StructField("actionType", StringType),
StructField("actionPrepend", StringType),
StructField("actionTest", StringType),
StructField("ifEquipment", StringType),
StructField("actionName", StringType),
StructField("progress", StringType),
StructField("id", StringType)
))
val detailDF = spark.createDataFrame(detailRDD, detailSchema) //重新创建新的dataFrame结构
detailDF.show(5,false) //truncate为false表示可以显示超过20个字符的数据
val url = "jdbc:mysql://hadoop01:3306/spark_dataclear"
val prop = new Properties()
prop.setProperty("user", "root")
prop.setProperty("password", "123456")
prop.setProperty("driver", "com.mysql.jdbc.Driver")
println("开始写入mysql")
detailDF.write.mode(saveMode = "overwrite").jdbc(url, "logDetail", prop)
// orgDF.write.mode("overwrite").jdbc(url,"",prop)
println("写入mysql结束")
hive网站日志数据分析
一、说在前面的话
上一篇,楼主介绍了使用flume集群来模拟网站产生的日志数据收集到hdfs。但我们所采集的日志数据是不规则的,同时也包含了许多无用的日志。当需要分析一些核心指标来满足系统业务决策的时候,对日志的数据清洗在所难免,楼主本篇将介绍如何使用mapreduce程序对日志数据进行清洗,将清洗后的结构化数据存储到hive,并进行相关指标的提取。
先明白几个概念:
1)PV(Page View)。页面浏览量即为PV,是指所有用户浏览页面的总和,一个独立用户每打开一个页面就被记录1 次。计算方式为:记录计数
2)注册用户数。对注册页面访问的次数。计算方式:对访问member.php?mod=register的url,计数
3)IP数。一天之内,访问网站的不同独立IP 个数加和。其中同一IP无论访问了几个页面,独立IP 数均为1。这是我们最熟悉的一个概念,无论同一个IP上有多少台主机,或者其他用户,从某种程度上来说,独立IP的多少,是衡量网站推广活动好坏最直接的数据。计算方式:对不同ip,计数
4)跳出率。只浏览了一个页面便离开了网站的访问次数占总的访问次数的百分比,即只浏览了一个页面的访问次数 / 全部的访问次数汇总。跳出率是非常重要的访客黏性指标,它显示了访客对网站的兴趣程度。跳出率越低说明流量质量越好,访客对网站的内容越感兴趣,这些访客越可能是网站的有效用户、忠实用户。该指标也可以衡量网络营销的效果,指出有多少访客被网络营销吸引到宣传产品页或网站上之后,又流失掉了,可以说就是煮熟的鸭子飞了。比如,网站在某媒体上打广告推广,分析从这个推广来源进入的访客指标,其跳出率可以反映出选择这个媒体是否合适,广告语的撰写是否优秀,以及网站入口页的设计是否用户体验良好。
计算方式:(1)统计一天内只出现一条记录的ip,称为跳出数
(2)跳出数/PV
本次楼主只做以上几项简单指标的分析,各个网站的作用领域不一样,所涉及的分析指标也有很大差别,各位同学可以根据自己的需求尽情拓展。废话不多说,上干货。
二、环境准备
1)hadoop集群。楼主用的6个节点的hadoop2.7.3集群,各位同学可以根据自己的实际情况进行搭建,但至少需要1台伪分布式的。(参考http://www.cnblogs.com/qq503665965/p/6790580.html)
2)hive。用于对各项核心指标进行分析(安装楼主不再介绍了)
3)mysql。存储分析后的数据指标。
4)sqoop。从hive到mysql的数据导入。
三、数据清洗
我们先看看从flume收集到hdfs中的源日志数据格式:
1 27.19.74.143 - - [30/4/2017:17:38:20 +0800] "GET /static/image/common/faq.gif HTTP/1.1" 200 1127 2 211.97.15.179 - - [30/4/2017:17:38:22 +0800] "GET /home.php?mod=misc&ac=sendmail&rand=1369906181 HTTP/1.1" 200 -
上面包含条个静态资源日志和一条正常链接日志(楼主这里不做静态资源日志的分析),需要将以 /static 开头的日志文件过滤掉;时间格式需要转换为时间戳;去掉IP与时间之间的无用符号;过滤掉请求方式;“/”分隔符、http协议、请求状态及当次流量。效果如下:
1 211.97.15.179 20170430173820 home.php?mod=misc&ac=sendmail&rand=1369906181
先写个日志解析类,测试是否能解析成功,我们再写mapreduce程序:
1 package mapreduce; 2 3 import java.text.ParseException; 4 import java.text.SimpleDateFormat; 5 import java.util.Date; 6 import java.util.Locale; 7 8 9 public class LogParser { 10 public static final SimpleDateFormat FORMAT = new SimpleDateFormat("d/MM/yyyy:HH:mm:ss", Locale.ENGLISH); 11 public static final SimpleDateFormat dateformat1=new SimpleDateFormat("yyyyMMddHHmmss"); 12 public static void main(String[] args) throws ParseException { 13 final String S1 = "27.19.74.143 - - [30/04/2017:17:38:20 +0800] \\"GET /static/image/common/faq.gif HTTP/1.1\\" 200 1127"; 14 LogParser parser = new LogParser(); 15 final String[] array = parser.parse(S1); 16 System.out.println("源数据: "+S1); 17 System.out.format("清洗结果数据: ip=%s, time=%s, url=%s, status=%s, traffic=%s", array[0], array[1], array[2], array[3], array[4]); 18 } 19 /** 20 * 解析英文时间字符串 21 * @param string 22 * @return 23 * @throws ParseException 24 */ 25 private Date parseDateFormat(String string){ 26 Date parse = null; 27 try { 28 parse = FORMAT.parse(string); 29 } catch (ParseException e) { 30 e.printStackTrace(); 31 } 32 return parse; 33 } 34 /** 35 * 解析日志的行记录 36 * @param line 37 * @return 数组含有5个元素,分别是ip、时间、url、状态、流量 38 */ 39 public String[] parse(String line){ 40 String ip = parseIP(line); 41 String time = parseTime(line); 42 String url = parseURL(line); 43 String status = parseStatus(line); 44 String traffic = parseTraffic(line); 45 46 return new String[]{ip, time ,url, status, traffic}; 47 } 48 49 private String parseTraffic(String line) { 50 final String trim = line.substring(line.lastIndexOf("\\"")+1).trim(); 51 String traffic = trim.split(" ")[1]; 52 return traffic; 53 } 54 private String parseStatus(String line) { 55 final String trim = line.substring(line.lastIndexOf("\\"")+1).trim(); 56 String status = trim.split(" ")[0]; 57 return status; 58 } 59 private String parseURL(String line) { 60 final int first = line.indexOf("\\""); 61 final int last = line.lastIndexOf("\\""); 62 String url = line.substring(first+1, last); 63 return url; 64 } 65 private String parseTime(String line) { 66 final int first = line.indexOf("["); 67 final int last = line.indexOf("+0800]"); 68 String time = line.substring(first+1,last).trim(); 69 Date date = parseDateFormat(time); 70 return dateformat1.format(date); 71 } 72 private String parseIP(String line) { 73 String ip = line.split("- -")[0].trim(); 74 return ip; 75 } 76 }
输出结果:
1 源数据: 27.19.74.143 - - [30/04/2017:17:38:20 +0800] "GET /static/image/common/faq.gif HTTP/1.1" 200 1127 2 清洗结果数据: ip=27.19.74.143, time=20170430173820, url=GET /static/image/common/faq.gif HTTP/1.1, status=200, traffic=1127
再看mapreduce业务逻辑,在map中,我们需要拿出ip、time、url这三个属性的值,同时过滤掉静态资源日志。map的k1用默认的LongWritable就OK,v1不用说Text,k2、v2与k1、v1类型对应就行:
1 static class MyMapper extends Mapper<LongWritable, Text, LongWritable, Text>{ 2 LogParser logParser = new LogParser(); 3 Text v2 = new Text(); 4 @Override 5 protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, LongWritable, Text>.Context context) 6 throws IOException, InterruptedException { 7 final String[] parsed = logParser.parse(value.toString()); 8 9 //过滤掉静态信息 10 if(parsed[2].startsWith("GET /static/") || parsed[2].startsWith("GET /uc_server")){ 11 return; 12 } 13 //过掉开头的特定格式字符串 14 if(parsed[2].startsWith("GET /")){ 15 parsed[2] = parsed[2].substring("GET /".length()); 16 } 17 else if(parsed[2].startsWith("POST /")){ 18 parsed[2] = parsed[2].substring("POST /".length()); 19 } 20 //过滤结尾的特定格式字符串 21 if(parsed[2].endsWith(" HTTP/1.1")){ 22 parsed[2] = parsed[2].substring(0, parsed[2].length()-" HTTP/1.1".length()); 23 } 24 v2.set(parsed[0]+"\\t"+parsed[1]+"\\t"+parsed[2]); 25 context.write(key, v2); 26 }
reduce相对来说就比较简单了,我们只需再讲map的输出写到一个文件中就OK:
1 static class MyReducer extends Reducer<LongWritable, Text, Text, NullWritable>{ 2 @Override 3 protected void reduce(LongWritable arg0, Iterable<Text> arg1, 4 Reducer<LongWritable, Text, Text, NullWritable>.Context context) throws IOException, InterruptedException { 5 for (Text v2 : arg1) { 6 context.write(v2, NullWritable.get()); 7 } 8 } 9 }
最后,组装JOB:
1 public static void main(String[] args) throws IllegalArgumentException, IOException, ClassNotFoundException, InterruptedException { 2 Job job = Job.getInstance(new Configuration()); 3 job.setJarByClass(LogParser.class); 4 job.setMapperClass(MyMapper.class); 5 job.setMapOutputKeyClass(LongWritable.class); 6 job.setMapOutputValueClass(Text.class); 7 FileInputFormat.setInputPaths(job, new Path("/logs/20170430.log")); 8 job.setReducerClass(MyReducer.class); 9 job.setOutputKeyClass(Text.class); 10 job.setOutputValueClass(NullWritable.class); 11 FileOutputFormat.setOutputPath(job, new Path("/20170430")); 12 job.waitForCompletion(true); 13 }
mapreduce完成后就是运行job了:
1)打包,mapreduce程序为loger.jar
2)上传jar包。运行loger.jar hadoop jar loger.jar
运行结果:
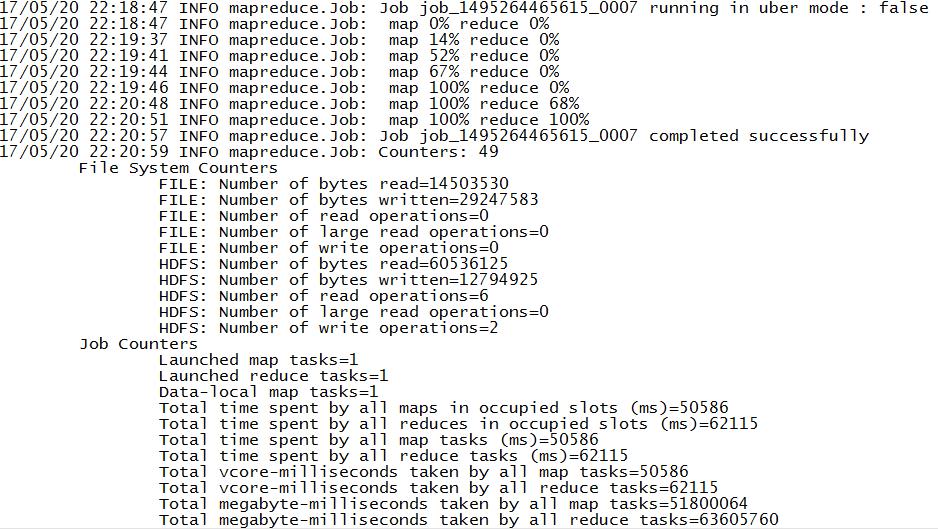
hdfs多了20170430目录:


我们下载下来看看清洗后的数据是否符合要求:
日志数据的清洗到此就完成了,接下来我们要在此之上使用hive提取核心指标数据。
四、核心指标分析
1)构建一个外部分区表,sql脚本如下:
1 CREATE EXTERNAL TABLE sitelog(ip string, atime string, url string) PARTITIONED BY (logdate string) ROW FORMAT DELIMITED FIELDS TERMINATED BY \'\\t\' LOCATION \'/20170430\';
2)增加分区,sql脚本如下:
ALTER TABLE sitelog ADD PARTITION(logdate=\'20170430\') LOCATION \'/sitelog_cleaned/20170430\';
3)统计每日PV,sql脚本如下:
1 CREATE TABLE sitelog_pv_20170430 AS SELECT COUNT(1) AS PV FROM sitelog WHERE logdate=\'20170430\';
4)统计每日注册用户数,sql脚本如下:
1 CREATE TABLE sitelog_reguser_20170430 AS SELECT COUNT(1) AS REGUSER FROM sitelog WHERE logdate=20170430\' AND INSTR(url,\'member.php?mod=register\')>0;
5)统计每日独立IP,sql脚本如下:
1 CREATE TABLE site_ip_20170430 AS SELECT COUNT(DISTINCT ip) AS IP FROM sitelog WHERE logdate=\'20170430\';
6)统计每日跳出的用户数,sql脚本如下:
CREATE TABLE sitelog_jumper_20170430 AS SELECT COUNT(1) AS jumper FROM (SELECT COUNT(ip) AS times FROM sitelog WHERE logdate=\'20170430\' GROUP BY ip HAVING times=1) e;
7)把每天统计的数据放入一张表中,sql脚本如下:
1 CREATE TABLE sitelog_20170430 AS SELECT \'20170430\', a.pv, b.reguser, c.ip, d.jumper FROM sitelog_pv_20170430 a JOIN sitelog_reguser_20170430 b ON 1=1 JOIN sitelog_ip_20170430 c ON 1=1 JOIN sitelog_jumper_20170430 d ON 1=1 ;
8)使用sqoop把数据导出到mysql中:
sqoop export --connect jdbc:mysql://hadoop02:3306/sitelog --username root --password root --table sitelog-result --fields-terminated-by \'\\001\' --export-dir \'/user/hive/warehouse/sitelog_20170430\'
结果如下:

2017年4月30日日志分析结果:PV数为:169857;当日注册用户数:28;独立IP数:10411;跳出数:3749.
到此,一个简单的网站日志分析楼主就介绍完了,后面可视化的展示楼主就不写了,比较简单。相关代码地址:https://github.com/LJunChina/hadoop
以上是关于Spark-ETL日志数据清洗分析项目(上)--个人学习解析(保姆级)的主要内容,如果未能解决你的问题,请参考以下文章