spark Scala中dataframe的常用关键字:withColumn
Posted 大数据honry2022
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了spark Scala中dataframe的常用关键字:withColumn相关的知识,希望对你有一定的参考价值。
withColumn关键字:
用于操作dataframe原表某一列的数据,将操作完的每一行数据形成一列,用来替换一个表原有的列或者在原表后面追加新的列!
语法如下:
def withColumn(colName: String, col: Column): DataFrame
withColumn传入两个参数:
先说第二个参数:
该参数传入的是操作dataframe表中指定”列”的数据。他会对dataframe表中的每一行数据进行操作,最后返回一个新的列。如果第一个参数传入的列名和第二个参数传入的列名参数相同的话,就会替换原来的列。如果第一个参数和原列名参数不同,则会追加新增加一列数据在表后面。具体例子如下:
现用withColumn关键字将city字段类似于“成都·双流区” 操作转换成 “成都” ,思路是将city字段数据“·”后面的数据去除,然后替换掉原来列或者新增一列两种情况:
原数据:
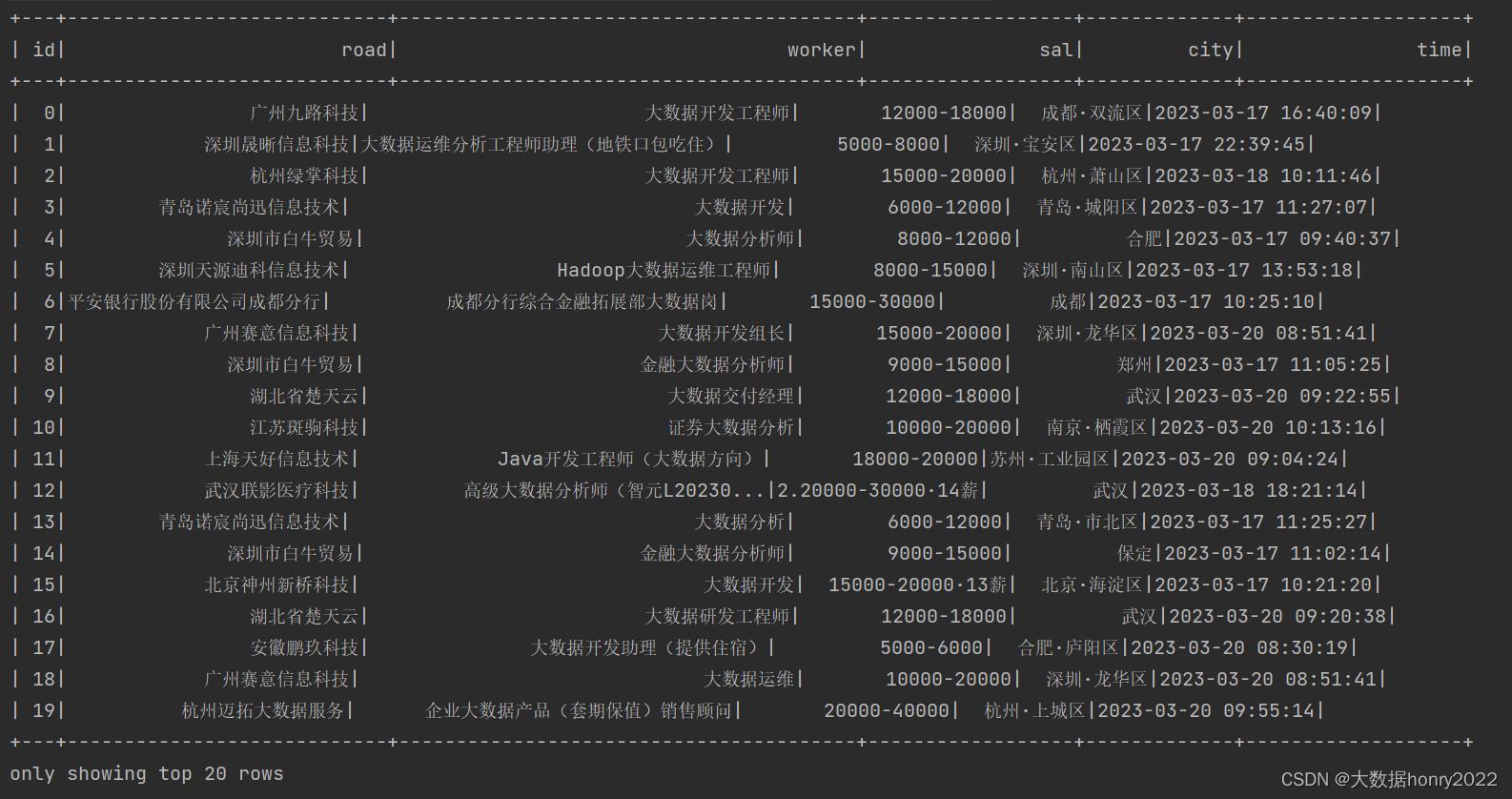
情况一(替换原列):传入的第一个参数和原列名相同:
在withColumn的第二个参数传入正则匹配将“·”后面的数据替换成空。但是第一个参数city和原列名city相同,则替换原列的数据:
df.withColumn("city", regexp_replace(col("city"), "·.*", "")).show替换dataframe表原列city的数据:
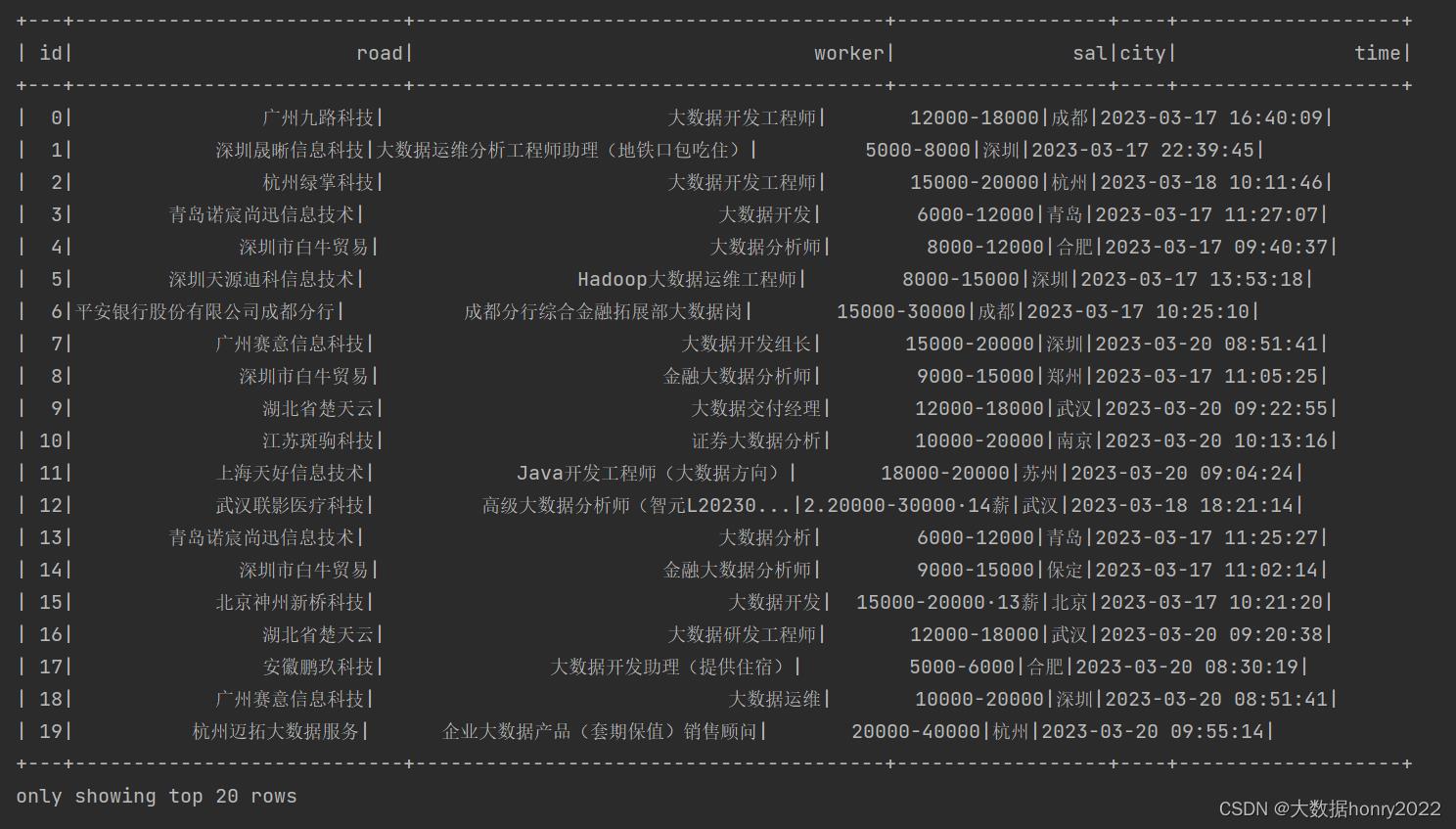
情况二(追加新列):传入的第一个参数和原列名不同
在withColumn的第二个参数传入正则匹配将“·”后面的数据替换成空。但是第一个参数newCity和原列名city不相同,则在dataframe表后面追加新列newCity:
df.withColumn("newCity", regexp_replace(col("city"), "·.*", "")).showdataframe表末尾追加新列newCity:

总结:
该关键字第二个参数可以对表中的指定的字段进行操作,操作完之后会返回一列数据,这列数据是以替换的形式还是以追加的形式存在,要看第一 个参数列名是否与第二个参数列名是否相同,相同则是替换原表的列数据,不相同则在原表中追加新增列。
Spark将DataFrame数据sftp到指定机器(scala)
@羲凡——只为了更好的活着
Spark将DataFrame数据sftp到指定机器(scala)
将处理完的数据sftp到指定的机器上,供下一个服务调用。博主使用spark2.3.2和hadoop2.7.3。直接先上代码
package aarontest
import org.apache.spark.sql.DataFrame, SaveMode, SparkSession
object SparkSftpDemo
def main(args: Array[String]): Unit =
val spark = SparkSession.builder()
.appName("CapCollisionQuerier")
.master("local[*]")// 将此行注释掉,打jar包,放在linux上即可执行
.enableHiveSupport()
.getOrCreate()
val host=args(0) //远程机器的ip
val username=args(1) //登录远程机器的用户名
val password=args(2) //登录远程机器的密码
val outputFile =args(3) //远程机器存放文件的路径
val df: DataFrame = spark.sql("select * from aarontest.t1 limit 10")
df.write
.format("com.springml.spark.sftp") //一定要加
.option("host",host)
.option("username",username)
.option("password",password)
.option("header",true) //如果将df列名一同写出到文件中,此项设置为true
.option("fileType", "csv") //如果将df列名一同写出到文件中,此项设置为csv,不能为txt
.mode(SaveMode.Overwrite)
.save(outputFile)
spark.stop()
pom.xml文件中要添加
<dependency>
<groupId>com.springml</groupId>
<artifactId>spark-sftp_2.11</artifactId>
<version>1.1.3</version>
</dependency>
在用 spark-submit提交的时候一定要加载三个jar包 spark-sftp_2.11-1.1.3.jar 和 sftp.client-1.0.3.jar 以及 jsch-0.1.53.jar。加载jar包的方式很多,只要在spark任务运行时能读取到这三个jar包即可。下面使用 –jars 的方式演示
#!/bin/sh
/usr/local/package/spark-2.3.2-bin-hadoop2.7/bin/spark-submit \\
--master yarn \\
--deploy-mode cluster \\
--class aarontest.SparkSftpDemo \\
--jars hdfs://ns/lib/spark-sftp_2.11-1.1.3.jar,hdfs://ns/lib/sftp.client-1.0.3.jar,hdfs://ns/lib/jsch-0.1.53.jar \\
hdfs://ns/jars/SparkSftpDemo.jar $1 $2 $3 $4
====================================================================
@羲凡——只为了更好的活着
若对博客中有任何问题,欢迎留言交流
以上是关于spark Scala中dataframe的常用关键字:withColumn的主要内容,如果未能解决你的问题,请参考以下文章