关于并发和并行,Go和Erlang之父都弄错了?
Posted OneFlow深度学习框架
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了关于并发和并行,Go和Erlang之父都弄错了?相关的知识,希望对你有一定的参考价值。

作者|Yossi.Kreinin
来源|OSChina网站
翻译|Andy、袁不语、YuanyuanL、姜鹏飞
校对|胡燕君(OneFlow)
根据字面词义,并发(concurrent)是指竞争或对抗,而并行(parallelism)指两条直线永不相交的状态。在计算机中的并行和并发问题上,我与Joe Armstrong(译注:Erlang语言发明者)和Rob Pike(译注:Go语言发明者)这俩人的看法并不一致。
下面我以自动售货机和分礼物为例来说明我的观点。
首先,并行和并发都是非常流行的概念,很多编程语言和工具通常都会重点宣传自己“兼具高度并行性和高度并发性”。但我却认为,并行和并发需要的是不同的工具,而对单个工具来说,并行和并发不可兼得。例如:
-
Erlang、Rust、Go和STM Haskell擅长并发处理
-
Flow、Cilk、checkedthreads和Haskell侧重并行处理
也有像Haskell这样的语言或系统,既能处理并行,也能处理并发,但在Haskell内部,并行和并发分属两套不同的工具集。而且Haskell的官方wiki(http://www.haskell.org/haskellwiki/Parallelism)也解释了两者的使用原则,如果追求并行,那么不应该使用并发工具:
经验总结:优先使用纯并行,然后再考虑并发。
Haskell早就意识到一个工具难以同时解决这两个问题。专门针对并行环境设计的新编程语言ParaSail,也面临同样的难处,虽然它也兼备针对并行和并发的工具集,但它也建议在并行、非并发程序中尽量不要使用并发功能。
这就与很多人的观点大相径庭了,尤其是一些并发功能的铁粉,他们认为自己的并发工具处理起并行任务时也能游刃有余。Rob Pike就说,因为Go是一种并发性语言,所以它也很适合并行(http://talks.golang.org/2012/waza.slide#58)。
并发使得并行变得更容易(提高可扩展性等)。
同样,Joe Armstrong也是这么说Erlang语言的。他甚至还说:现在还想用非并发的思想去解决并行的问题是缘木求鱼。
到底是什么原因导致这种分歧,为什么Haskell和ParaSail的开发者认为并发和并行要用不同的工具,而Go和Erlang的开发者却认为并发语言也能处理并行呢?
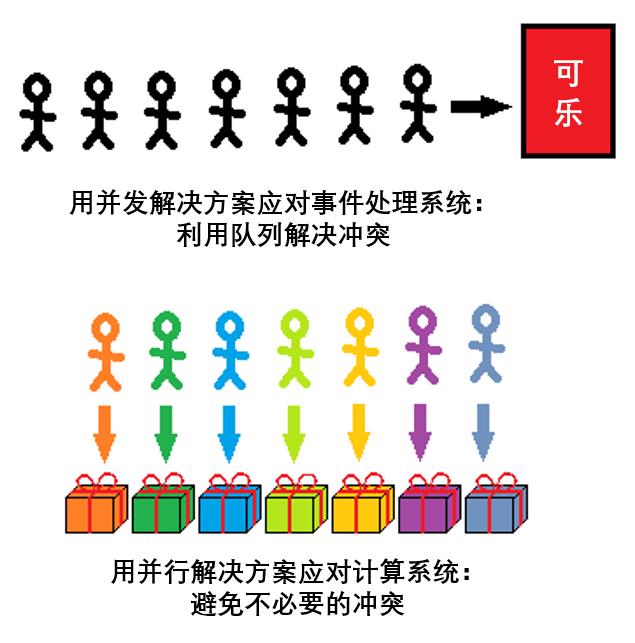
我觉得这是因为大家要解决的问题不同,对并行和并发的区别有不同理解,才导致最终结论不同。Joe Armstrong曾经画过一张图来解释两者的区别,经本人的灵魂画手还原如下:
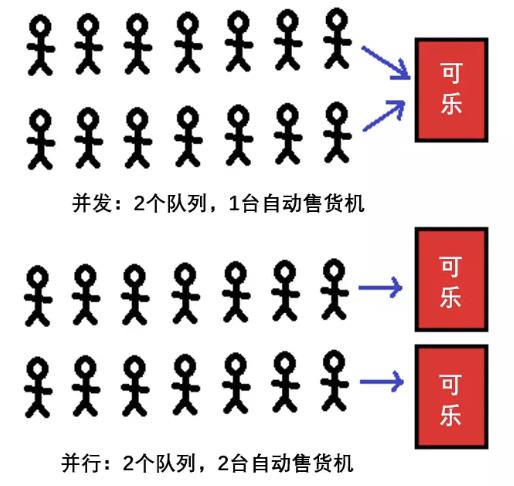
虽然并发在很多时候只涉及单一队列,但我还是按照Joe Armstrong的原图画了2个队列。从图中我们可以看出:
-
“并行”意味着可乐分发速度更快;
-
从局部来看,“并行”本质上还是并发问题 ;
-
先排队者先得到可乐;
-
谁先拿到可乐都没关系,反正最终每个人都会拿到;
-
当然,如果自动售货机里的可乐中途卖完了,后面的人就会拿不到——那也是没有办法,人生就是这样。
以上是用自动售货机举例,如果换一个比喻,假设是给一群孩子分发礼物呢,这两种类比之间有实质性区别吗?
有区别。自动售货机是一个事件处理系统:人们不定时地到来,并且从机器中取不定数量的可乐。而分礼物是一个计算系统:你知道每个孩子想要什么,你知道你买了什么礼物,并且你要决定哪个礼物分给哪个孩子。
在分礼物的场景中,“并发”与“并行”有不同的意义:
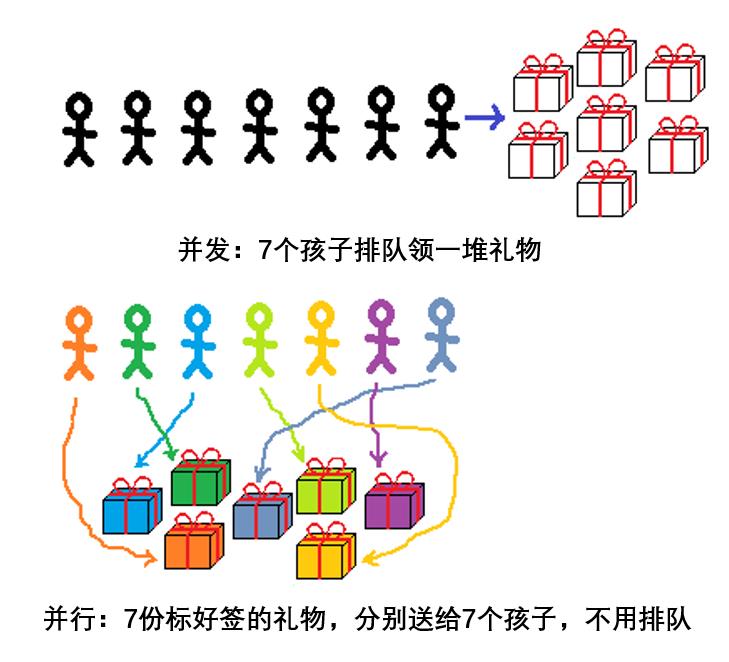
从上面的例子中,可以看出“并行”和“并发”有如下区别:
-
和自动售货机一样,“并发”也遵循“先到先得”的规则;
-
“并行”则不一样:礼物已有标签,每个孩子拿到什么都是确定的;
-
“并发”必须靠队列来维持秩序,避免两个孩子同时抢一个礼物——就像系统要防止多个任务争先访问共享的数据,避免系统瘫痪一样;
-
“并行”模式下,就不需要队列了,不管谁先谁后,每个人都会拿到属于自己的礼物。
在俄语中,“concurrent(并发,读作kon-koo-rent)”和“competitor(竞争对手)”是同义词。这种含义正好契合了分礼物中的“并发”情景的竞争属性:每个人都希望自己最早到,这样就能挑到最好的礼物。
但“并行”场景则不同,每个礼物盒都写上了对应小朋友的名字。在逻辑上,孩子和礼物之间一一对应,互不交叉,互不干扰。(但为什么我在图中画的连线却相交呢?一会儿我会解释这个问题。我们可以先这么想:每个孩子奔向自己的礼物时路线会有相交,就像不同处理器寻找自己想要的数据时路径会相撞,但这并不影响到谁最终拿到什么礼物。)
1
计算和事件处理
我们可以联想电话客服、Web服务器、银行柜台等应用场景,它们和自动售货机是类似的事件处理系统,都要处理并发任务,都必须解决不可预知的请求带来的不可避免的冲突。并行设计可以在一定程度上提高处理速度,但其问题的根源还是在于并发中的冲突。
而在计算系统中,例如分礼物、图形处理、计算机视觉、科学计算等中,则不会出现并发冲突。输入是确定的,只需根据输入进行计算,然后输出,不会有意外干扰。这时,并行的方法可以提高计算速度,但也容易出现bug。
接下来我们将继续讨论计算系统和事件处理系统的差别。
2
确定性:理想VS妄想
在计算系统中,我们需要更多的确定性,因为这可以使编程人员轻松很多----如果程序的输出结果是可确定的,那我们就可以放心地去测试优化或者重构代码,只要输出结果没变,就说明我们没做错。
而且这种确定性要求的只是一种大概的确定,并不需要100%相同----例如,在计算机视觉训练中,你并不要求机器每次找到的100张图片都是同一组,只要上面都有小猫就行;你也不要求机器每次都求出一模一样的圆周率近似值,只要它是在3和4之间就可以了。
在计算系统中,拥有确定性是理想情况,而且是可以达到的。
但是在事件处理系统中,一切都是不确定的。如果事件发生顺序不同,产生的结果也不同。譬如,如果我比你来得早,那罐仅剩的可乐就是我的;如果咱俩的银行联名账户只剩一块钱,而我的取款操作比你晚了0.001秒,钱就会打给你。
但如果再给我一次机会,那么钱属谁手就不一定了。这就是事件处理系统的不确定性。同样的程序运行多次,结果可以南辕北辙。而所有可能的结果数将随冲突的数量指数式增长。还有比这更让人头疼的事吗?
3
如何判断并行安全:确定性VS正确性
当程序以不同的顺序处理事件时,你怎么确定其中没有bug?
在计算系统中,只要你每次运行程序都能得到相同的结果,即使是错误的结果,你也可以基本断定程序是并行安全的。就像运行一个搜索小猫的程序,你每次都搜出了同一品种的小狗,那说明你的程序有问题,但是不存在并行方面的问题。
但是在事件处理系统中,情况就复杂了一些,只有当系统每次都能得到正确的结果,你才能确定系统是并行安全的。
比如程序要模拟两个人同时取钱,不可能要求每次都是同一个人取到最后的一块钱,那如何判断这个程序没有bug?我们只能从侧面来看,例如账户有没有出现的负余额,会不会连续两次取空一个账户,会不会凭空增加账户金额等等。如果上述这些异常情况都没有发生,你就可以认为你的模拟程序没有问题。
对电话服务来说也是这样,你需要先定义出一系列“正确的结果”,然后用这些“正确的结果”验证你的电话服务是否正常。
但很遗憾,如果一个系统的结果不能体现时序相关的问题,那你就无法知道系统的时序有没有bug。这也是个头疼的问题。
4
并行错误:易定位VS难定义
对于标好名字的礼物来说,如果出现并行错误,是很容易发现的--即使礼物上的名字是用外语写的,孩子看不懂,这都没关系,为什么?请看下图:

所以对并行系统来说,系统不认识这些“标记”没关系,只要有标记就行。如果发现两个孩子争夺同一份礼物,就可以找认识标记的人来解决冲突。
这就好像一个自动化的测试工具,不需要知道哪个任务分别访问什么数据,只要知道一个任务不能访问被别的任务修改过的数据就行了。如果发生了这种冲突访问,那就当做bug报告给程序员来处理。
这样的工具现在已经有很多了,Cilk语言有,Checkedthreads也带有一个基于Valgrind的类似工具。(注:Checkedthreads,一个C++并行框架https://github.com/yosefk/checkedthreads;Valgrind,一套支持动态分析的工具http://valgrind.org)
但Haskell不用这么干,因为首先它不存在副作用(side effect),这就保证了并行处理不会出现冲突。但即便没有这种静态保证,Haskell的动态冲突检测机制也能避免冲突。
造成的意外结果就是,在计算系统中,你不需要准确标记出bug所在,也不需要指出bug导致的问题是什么。
而在事件处理系统中,必须有一个知识丰富、责任感强的“大人”来掌控全局,维持秩序。
此外,事件处理系统还隐含了一个通用的规则:别人正在处理的进程,你就不能插手了,必须乖乖地在队列里等候。在“分礼物”场景中,“大人”的存在可以保证这条规则得到遵守,让分礼物的任务更顺利,但还是难以避免其他可能的冲突。
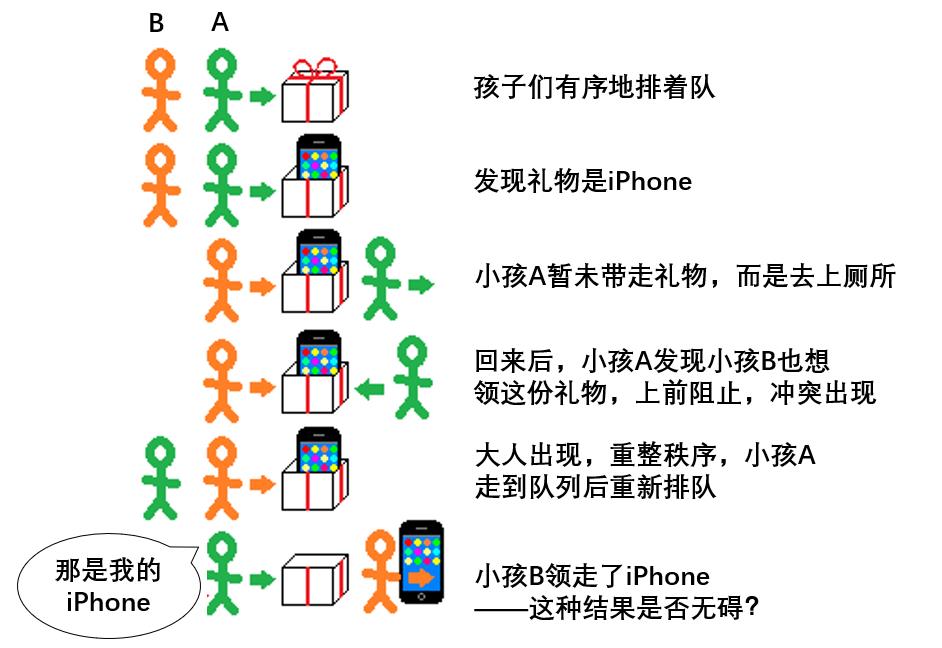
在上图中,小孩A中途离开,回来后没有经过排队就接触礼物,违反规则,于是被系统检测为bug,大人出现,重整秩序。
但纵观全程,小孩A先拆开了礼物,但又中途离开队列,回来后发现礼物被后面的小孩B领了——这种结果符合系统的要求吗?一方面,小孩B没有插队,也没有阻挠小孩A领礼物,并未违反系统规则;但另一方面,小孩B领到本属于小孩A的礼物,这并不符合系统的预设。
上述情况体现在具体代码中是这样的:以下是一个错误的汇款操作,可以轻易被自动调试工具检测出“有bug”:
src.balance -= amount
dst.balance += amount此处没有任何同步操作。src.balance可能被两个进程同时修改,导致其中的一次修改是无效的。好在,Helgrind等数据争用检测工具可以通过监控内存访问发现这样的同步问题,Cilk和checkedthreads内部也有相似的工具。
但下列代码中的bug,上述工具可能就检测不出来了:
atomic src.balance -= amount
atomic dst.balance += amount 上面代码中的“atomic”表示原子操作,意思是对账户余额的修改必须依次进行。这样一来,检测工具就可以少操些心了——但这样就意味着没有bug了?
实际上,一个进程从src.balance里拨出一笔钱之后,转入dst.balance之前,可能因为某种原因被暂停,从而进入暂时丢失(temporarily lost)状态,那么逻辑上这笔钱就“暂时失踪”了。这样算不算一个bug?我不太了解银行业务,无法判断,估计Helgrind也不能。
下面是一个错误更明显的代码:
if src.balance - amount > 0:
atomic src.balance -= amount
atomic dst.balance += amount 在上面的程序中,一个进程会先检查原始账户src.balance里有没有足够的余额可供转账,检查完毕,临时有事又先挂起了,这时另外一个进程到达了,也执行了同样的检测,发现没问题,然后就把钱转走了。然后第一个进程恢复了,进入队列等待执行转账操作。问题就出现了----等轮到它的时候,账户里的钱已经被转空了。
就像小孩A回来的时候发现自己的iPhone居然在小孩B手里。这是一种竞态条件(race condition),而不是数据竞争(data race),因为每个人都在文明排队,但bug还是发生了。
什么是竞态条件?这和具体的应用有关,显然,上述的第三段代码有问题,但我不能确定第二段代码是否有问题,因为我不了解银行业务。如果我们不了解程序要做什么,就无法准确定义这个应用中的“竞态条件”,更不能指望一些自动化工具可以检测到了。
当然,你也可以避开竞态条件,只要把整个转账操作原子化即可,所有的并发方法都能让你做到这一点。
与空指针异常不同,竞态条件带来的问题没那么容易被发现。如果程序的输出结果具有不确定性,那么当你给程序提供有问题的输入,就可能只有千万分之一的概率会发生bug,因此程序每次的输出结果都不同。而如果是输出结果可以确定的程序,情况就会好很多,每一次给它提供有问题的输入,bug都会产生,自动调试工具也都能检测出bug来。
但很可惜,事件处理系统并不是输出结果可确定的系统。这又是让人头疼的地方!
5
两种队列:实现细节VS部分接口
对于有标签的礼物,不需要排队,每个人都可以直接找到自己的礼物。或许并非如此,想象一下,如果是数千个孩子同时去找礼物会是什么境况?这时如果不排队,肯定会乱成一团糟。所以这种情况下,我们也需要排成一个或几个队列,但这里的排队方式的选择只会在效率上有所不同,并不会影响孩子最终拿到手的礼物。
这就是在我上面的图中每个孩子和礼物的连线有交叉的原因。这些连线在逻辑上是并行的,虽然看似有交叉,但是不会产生实际冲突。(为了提供准确的解释,我对喻体的选择和插图的表达都非常谨慎。)
当四个不同的处理器通过相同的内存总线去访问互不相关的数据时,“逻辑上的平行在技术上交叉”,实际上,这些处理器必须在硬件层面上排队,才能顺利完成访问。同样,假如有1000个逻辑上独立的进程通过负载调度器分配到4个处理器上时,这些进程也需要排队等候被分配。
即便在一个无冲突的并行系统中,也会有大量的队列在运行,但它们只是操作层面的队列,不会影响最终结果。无论哪个进程在哪个队列,位置靠不靠前,程序的最终运行结果都是一样的。如下图所示:
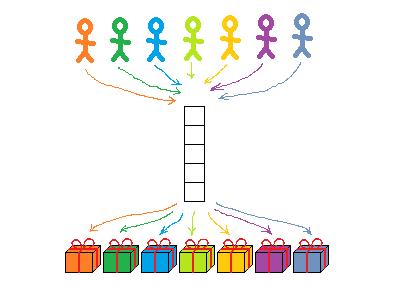
与之相反,在并发系统中,队列贯穿系统开始和结束的两端,例如:
-
一个信号量(semaphore)会对应一个等待锁定它的队列,谁在前面谁就能先锁定这个信号量;
-
Erlang的进程会有一个消息队列,谁先发出消息谁就会先影响到结果;
-
Go中的goroutine(协程)会监听一个通道,数据写入的顺序会影响执行的结果;
-
在事务内存的模型下,提交事务失败的进程都要进入队列;
-
在无锁容器内,更新失败的进程也要进入队列。
在事件处理系统中,队列或简单或复杂,但队列的顺序始终会影响最终的执行结果。这种影响可能会带来问题,也可能不会——这取决于系统的目的。
在并行的无冲突计算系统中,队列执行顺序不会影响结果,不过你需要工具来验证这个系统确实是无冲突的。
Rob Pike曾做过一个演示,展示了用Go语言构建负载均衡器有多么方便,那的确很强大也很易用。Go语言就是为并发环境设计的,并发就意味着排队,排队就会带来负载均衡的问题。当然,这并不是说别的语言里构建负载均衡就有多难,只是强调在有并发特性的语言里显得特别容易而已。
但这只是并行故事的一部分,接下来你想要的是无冲突的静态保证(static guarantees)或动态检查,Go语言也的确可以做到这一点。计算系统不能没有静态保证或动态检查,但当你真正在计算系统下工作时,你就会发现,计算系统所需要的静态保证和动态检查是一组不同于goroutines和通道的接口和工具,尽管这些功能底层也是用goroutines和通道实现的。
6
抢占式进程的重要性
因此,计算系统所需要的冲突预防和检测,并发工具并没有提供。那有没有并发工具提供,但计算系统不需要的特性呢?
有,比如显式的队列(即顺序会影响结果的队列),不仅不需要,而且它会成为计算系统的障碍。因为我们知道,计算系统中队列会导致竞态条件而非数据竞争,而且你没法精确定位冲突位置。
另一个计算型系统不需要的特性就是低成本的抢占式进程/线程。
对于事件处理系统,你希望尽可能快地处理大量不同的事件,这里就会出现很多抢占式进程,你希望在10000个进程在运行时,还可以立即应对第10001个进程产生的事件。这种情况必须要有非常低成本的抢占式进程,否则无法工作。
对于计算系统,可以用低成本的任务来映射到相对高成本的OS线程——但任务没有线程那么强大。你不能通过事件来激活任务,任务只能在队列中等着,当工作线程空闲时才会用来运行它们。不像goroutines或类似的情景,你不能让超过操作系统线程数量的任务同时处于运行状态——你也不需要这么做。
比起通过成熟的低成本进程、goroutines等其他方式,用比较传统的运行时(runtime)可以很好地完成任务。当然,在我看来这需要在底层运行时系统中做更多的工作。
可以看出,以并发为目标的平台一方面对计算系统的服务不足,提供不了它需要的功能,一方面却又服务过度,提供了不少它不需要的特性。
(公平地说,在计算系统中通过抢占来获取优先级在理论上是可行的——换句话说,如果它让新创建的任务(属于关键路径的一部分)抢占正在运行中的任务(不是关键路径的一部分),就可以提高吞吐量。然而,在我漫长且令人沮丧的经历中,要让调度器知道关键路径是什么,这只是理论上可行,实际上很难做到。一个愚蠢的、贪婪的调度器对抢占没什么用处。)
7
同类工具的不同
针对并发性事件处理系统的工具并不都是一样的,针对并行性计算系统的工具也如此。虽然它们都是同一类工具,但有实质性的区别。
-
Erlang 完全不允许进程共享内存。这意味着不存在数据竞争,这并不会特别打动我,因为数据竞争可以很容易被自动检测工具发现,而不允许进程共享内存却不能消除竞态条件。但好的一面是,你可以无缝扩展到多个节点,而不仅仅是扩展到同一个芯片上的多个核。
-
Rust 不允许共享内存,除非它是不可改变的。没有简单的多节点扩展,但是在单节点上有更好的性能,不需要数据竞争检测,可能会由于测试覆盖率不高导致出现竞争检测漏报(实际并不完全是这样,Rust也声称有计划引入并行工具)。
-
Go 允许共享任何东西。我认为,它在验证负担可接受的范围内做出了最优的性能。Go有一个数据竞争检测器,无论如何,竞态条件在事件处理系统中还是会发生。
-
STM Haskell 允许自由地共享不可改变的数据,以及在显式要求时也可以共享可变数据。它也提供了事务内存接口,这是一个很酷的东西,有时候很难用其它方法模拟。Haskell也有其它的并发工具——有通道,如果你想要Erlang式的多节点可扩展性,显然Cloud Haskell是个不错的选择。
当然,最大的区别是你得分别用Erlang、Rust、Go和Haskell写代码。现在看看计算系统:
-
Parallel Haskell 仅仅并行纯代码。这是一种没有并行bug的静态保证,但却以没有副作用为代价。
-
ParaSail 有副作用,但是不允许出现指针等,因此,只有当不共享可变数据时,它才会并行计算(例如,如果编译器确信两个数组片不重叠,则可以并行处理这两个数组片)。与Haskell类似,ParaSail也有一些并发支持——也就是可以被共享和可变的“并发对象”——而且ParaSail的文档强调了在你仅仅需要并行时不使用并发工具的好处。
-
Flow 依赖纯功能性核心,这进一步限制了让编译器充分理解程序中的数据流,允许它对准Hadoop和CUDA等目标平台。语法上看起来像是副作用,并行规约(parallel reduction)等被认为是核心上的一层糖衣。我承认我不能完全理解它的产品宣言(“如果一个态射(morphism)是满射(surjective)和内射(injective),那么它是一个双射(bijection),因此它是可逆的”这对我们再明显不过)
-
Cilk 是加上了并行循环和函数调用的C语言。它允许你共享可变数据,搬石头砸自己的脚,但如果那些bug发生在你的测试输入中,它有工具可以确定性地找到那些bug。当你不搬石头砸自己的脚时,使用不受禁止的共享可变数据就很有用——当并行循环计算任务局部基于副作用优化的事物,然后循环结束,大家都可以使用这些事物时。像孩子打开他们的乐高积木,它们一起去构建和玩乐高。
-
Checkedthreads 很像 Cilk;它不依赖语言扩展,整个都是免费和开放的——不仅是接口和运行时,bug查找工具也是。
Checkedthreads是我写的,它在主流语言C和C++中是可移植的、自由的、安全的和可用的,不像很多系统需要新语言或者语言扩展。
人们想要用C++1y或者其它类似的规范标准化Cilk,但是Cilk想要添加关键字,而C++开发者不想添加关键字。Cilk在GCC和LLVM的分支是可用的,但它不能在所有平台运行(它扩展了ABI),而且它没有合并回主线。有些新的Cilk特性被申请专利了,并不是全部都是自由可用的。
但Cilk拥有一个巨大优势——它有Intel的支持,然而Checkedthreads只有鄙人支持。如果你读了Checkedthreads相关的博客后,认为Cilk更适合你,决定使用它,那我也算是实现我的另一个目标了,那就是为自动化调试并行程序工具赢得更多它应得的关注。
不是所有的并发工具都是一样的,不同的并行工具也不同——我甚至没有在我的例子中指出最大的不同。不过它们毕竟是两个不同类别,而我们首要事情就是选择正确的类别。
8
总结
我们已经讨论了并行的计算系统和并发的事件处理系统的不同点,包括:
-
确定性:理想VS妄想
-
如何判断并行安全:确定性VS正确性
-
并行错误:易定位VS难定义
-
队列:实现细节VS部分接口
-
抢占:几乎没用VS必不可少
对于事件处理系统,并发是本质,并行是部分解决方案——通常来说是好的解决方案(两个自动售货机比一个好)。对于计算系统,并行是本质,并发是部分解决方案——通常来说是不好的解决方案(一堆混杂的礼物通常比贴了标签的礼物糟糕)。
通过总结“并行/并发”和“计算/事件处理”,我希望可以表述得更清晰。我也希望没有给事件处理系统抹太多黑——可能有一些我不知道的自动验证策略。我并不保证我的观点和术语使用是正确的。
有人对事件处理系统更感兴趣,他们的观点很有价值——“并发是一次处理(dealing with)几件事情,并行是一次做(doing)几件事情”。从这个角度,并行是实现细节,并发是程序的结构。
我相信我的观点也有价值——也就是说,“并发处理的是不可避免的与时间相关的冲突,并行则避免不必要的冲突。”——“自动售货机vs贴了标签的礼物”。两者的逻辑看起来就像这样:
最重要的是,相对于事件处理系统的代码,计算系统的代码可以通过使用自动调试工具和静态保证相当容易地做到几乎没有bug。
使用自己的工具处理并行不是什么新鲜事儿。Rob Pike在Sawzall上的工作早于在并发语言Go上的工作,Sawzall是一个专门的并行语言,它的代码可以做到总是没有并行bug。
即便如此,现在并发工具的声量要比并行工具响亮——并发工具可以处理并行,尽管效果相对比较差。“雷声大雨点小”的并发工具往往让我们忽略了“低调却有料”的并行工具,希望大家能给予后者同样的关注。
Armstrong说,“并行化串行代码是在解决错误的问题。”对此,我的回应是,“为计算系统的代码使用‘裸’并发工具就是在解决错误的问题。”一个简单的事实是,用正确的工具进行并行化的C语言比Erlang更快、更安全。因此,我们要“使用正确的工具”,而不是让任何人拿走你的“iPhone”。
(本文源自OSChina网站,该翻译工作遵照CC协议。原译文:https://www.oschina.net/translate/parallelism-and-concurrency-need-different-tools?lang=chs&p=3;原文:http://www.yosefk.com/blog/parallelism-and-concurrency-need-different-tools.html)
其他人都在看
欢迎下载体验OneFlow v0.7.0:GitHub - Oneflow-Inc/oneflow: OneFlow is a performance-centered and open-source deep learning framework. https://github.com/Oneflow-Inc/oneflow/
https://github.com/Oneflow-Inc/oneflow/
以上是关于关于并发和并行,Go和Erlang之父都弄错了?的主要内容,如果未能解决你的问题,请参考以下文章