Flume学习笔记
Posted BabyMuu
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Flume学习笔记相关的知识,希望对你有一定的参考价值。
Flume日志收集系统
1 概述
-
Flume是Cloudera提供的日志收集系统, 后来贡献给了Apache
-
Flume是分布式的, 可信赖的, 可获取的服务基于搞笑的收集, 集合和移动或者传输大量的日志数据
2 Flume 的基本架构
- Flume是Web服务器上的日志传输到HDFS上, 中间就是Flume需要处理的借款
- 重要概念:
- event 事件: Flume本身是收集日志的, 他讲每一条日志封装成event时间
- event是Flu饿么收集数据的基本单位
- event是从Source流向Channel再到Sink – 本身是一个字节数组
- event 事件: Flume本身是收集日志的, 他讲每一条日志封装成event时间
- 日志的特点是一json的形式体现的 — 键值对( headers 和 body )
- Flume 而言传输利用的是 Agent对象 — Flume 运行的核心(Java进程)
- Source是数据的来源, channel是存储(缓存)数据, sink是向外流出/输出 — 三者合体就是 agent
3 流动方式
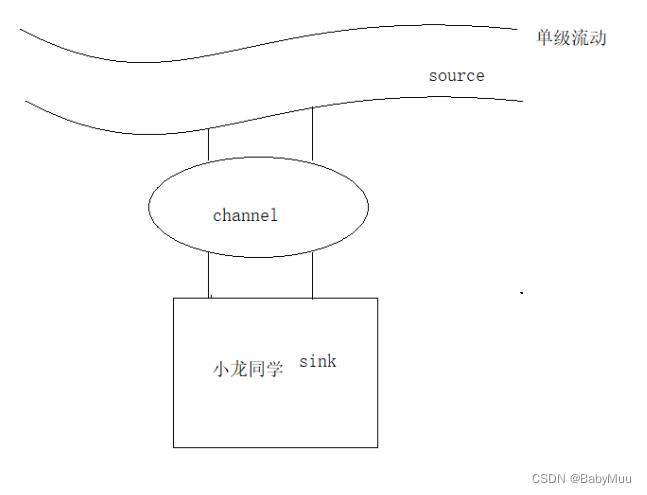
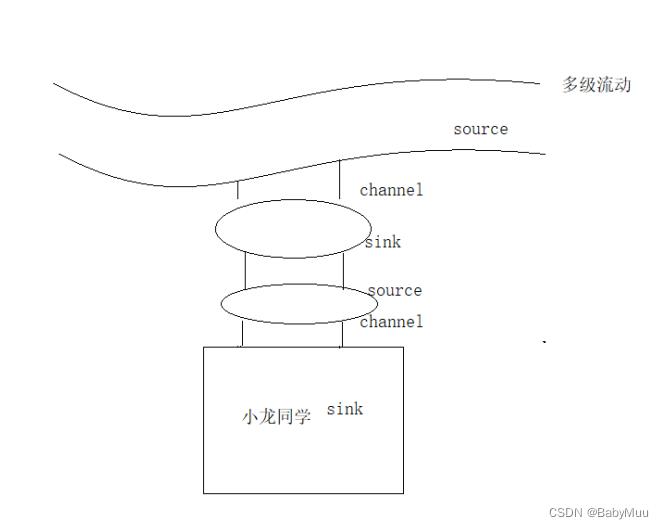
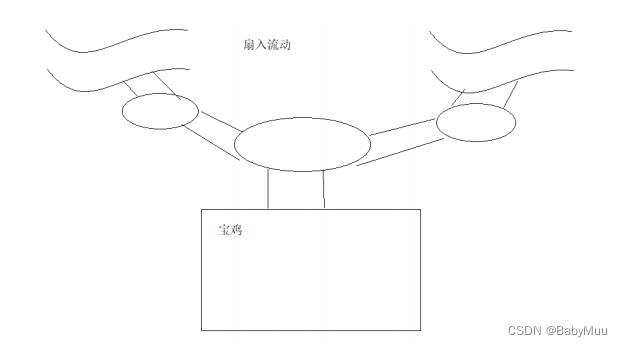
4 Flume 安装
下载安装包,并在指定文件夹路径进行解压, 并根据不同需求进行配置文件的修改
5 常用 Source
- netcat — 数据的形式是通过TCP请求, 接受的职能是字符串形式的数据
- AVRO — 要求接受到的数据必须经过AVRO序列化后的数据之后可以使用AVRO进行反序列化操作之后可以使用
- EXEC — 可以将命令的输出作为源头
- spooling Directory — 监听指定的某一个目录
- 要求指定目录一定要存在
- HTTP — 标识接受HTTP的 GET 和 POST 请求作为FLume的源头
1: netcat
1 新建文件夹 data 并进入
2 创建并编辑 basic.conf文件
# agent起个名称
# 绑定来源,因为来源有可能会有多个
a1.sources=r1
# 绑定通道, 因为有扇出流动
a1.channels=c1
# 绑定目的地, 因为扇出流动有多个目的地
a1.sinks=s1
# 配置Source
# 通过nc发送HTTP请求获取数据
a1.sources.r1.type=netcat
# 表示从本地获取数据
a1.sources.r1.bind=0.0.0.0
# 绑定端口号
a1.sources.r1.port=8090
# 配置Channel
# 表示内存通道
a1.channels.c1.type=memory
# 最多能够存储1000条数据, 对应了1000个Event事件
a1.channels.c1.capacity=1000
# 每次提供100条数据发送给Sink
a1.channels.c1.transactionCapacity=100
# 配置Sink - 表示以日志的方式输出在控制台
a1.sinks.s1.type=logger
# channel 和 Sink 以及 Source 之间的绑定
# 给r1的Source绑定一个通道(可以绑定多个)
a1.sources.r1.channels=c1
# 给s1绑定一个通道
a1.sinks.s1.channel=c1
3 进入bin目录
# 执行命令
sh flume-ng agent --name a1 -c ../conf/ -f ../data/basic.conf -Dflume.root.logger=INFO,console
2 AVRO
1 复制并编辑 basic.conf ==> avrosource.conf
# agent起个名称
# 绑定来源,因为来源有可能会有多个
a1.sources=r1
# 绑定通道,因为有扇出流动
a1.channels=c1
# 绑定目的地,因为扇出流动有多个目的地
a1.sinks=s1
# 配置Source
# 通过nc发送HTTP请求获取数据
### 相对于basic.conf 修改
a1.sources.r1.type=avro
### 相对于basic.conf 修改结束
# 表示从本地获取数据
a1.sources.r1.bind=0.0.0.0
# 绑定端口号
a1.sources.r1.port=8090
# 配置Channel
# 表示内存通道
a1.channels.c1.type=memory
# 最多能够存储1000调数据,对应了1000个event事件
a1.channels.c1.capacity=1000
# 每次提供100条数据发给sink
a1.channels.c1.transactionCapacity=100
# 配置sink - 表示以日志的形式输出在控制台
a1.sinks.s1.type=logger
# channel和sink以及Source绑定
# 给R1的source绑定一个通道(可以绑定多个)
a1.sources.r1.channels=c1
# 给s1绑定一个通道
a1.sinks.s1.channel=c1
2 进入bin目录执行
# 执行命令
sh flume-ng agent --name a1 -c ../conf/ -f ../data/avrosource.conf -Dflume.root.logger=INFO,console
# sh flume-ng avro-client --host hadoop01 --port 8090 --filename flume-ng.ps1
sh flume-ng avro-client -H hadoop01 -p 8090 -F flume-ng.ps1
3 EXEC
1 复制并编辑basic.conf ==> execsource.conf
# agent起个名称
# 绑定来源,因为来源有可能会有多个
a1.sources=r1
# 绑定通道,因为有扇出流动
a1.channels=c1
# 绑定目的地,因为扇出流动有多个目的地
a1.sinks=s1
# 配置Source
# 通过nc发送HTTP请求获取数据
### 相对于basic.conf 修改
a1.sources.r1.type=exec
# 执行的命令 # 此处为新增
a1.sources.r1.command=ping baidu.com
### 相对于basic.conf 修改结束
# 表示从本地获取数据
a1.sources.r1.bind=0.0.0.0
# 绑定端口号
a1.sources.r1.port=8090
# 配置Channel
# 表示内存通道
a1.channels.c1.type=memory
# 最多能够存储1000调数据,对应了1000个event事件
a1.channels.c1.capacity=1000
# 每次提供100条数据发给sink
a1.channels.c1.transactionCapacity=100
# 配置sink - 表示以日志的形式输出在控制台
a1.sinks.s1.type=logger
# channel和sink以及Source绑定
# 给R1的source绑定一个通道(可以绑定多个)
a1.sources.r1.channels=c1
# 给s1绑定一个通道
a1.sinks.s1.channel=c1
执行命令
../bin/flume-ng agent -n a1 -c ../conf/ -f execsource.conf -Dflume.root.logger=INFO,console
4 SpoolDir
1 复制并编辑 basic.conf ==> spoolsource.conf
# agent起个名称
# 绑定来源,因为来源有可能会有多个
a1.sources=r1
# 绑定通道,因为有扇出流动
a1.channels=c1
# 绑定目的地,因为扇出流动有多个目的地
a1.sinks=s1
# 配置Source
# 通过nc发送HTTP请求获取数据
### 相对于basic.conf 修改
a1.sources.r1.type=spooldir
### 相对于basic.conf 修改 结束
# 指定监听的目录
a1.sources.r1.spoolDir=/home/flumedata
# 表示从本地获取数据
a1.sources.r1.bind=0.0.0.0
# 绑定端口号
a1.sources.r1.port=8090
# 配置Channel
# 表示内存通道
a1.channels.c1.type=memory
# 最多能够存储1000调数据,对应了1000个event事件
a1.channels.c1.capacity=1000
# 每次提供100条数据发给sink
a1.channels.c1.transactionCapacity=100
# 配置sink - 表示以日志的形式输出在控制台
a1.sinks.s1.type=logger
# channel和sink以及Source绑定
# 给R1的source绑定一个通道(可以绑定多个)
a1.sources.r1.channels=c1
# 给s1绑定一个通道
a1.sinks.s1.channel=c1
2 执行命令
../bin/flume-ng agent -n a1 -c ../conf/ -f spoolsource.conf -Dflume.root.logger=INFO,console
5 HTTP
1 复制并编辑 basic.conf ==> httpsource.conf
# agent起个名称
# 绑定来源,因为来源有可能会有多个
a1.sources=r1
# 绑定通道,因为有扇出流动
a1.channels=c1
# 绑定目的地,因为扇出流动有多个目的地
a1.sinks=s1
# 配置Source
# 通过nc发送HTTP请求获取数据
### 相对于basic.conf 修改
a1.sources.r1.type=http
# 指定监听的目录
a1.sources.r1.spoolDir=/home/flumedata
### 相对于basic.conf 修改 结束
# 表示从本地获取数据
# a1.sources.r1.bind=0.0.0.0
# 绑定端口号
a1.sources.r1.port=8090
# 配置Channel
# 表示内存通道
a1.channels.c1.type=memory
# 最多能够存储1000调数据,对应了1000个event事件
a1.channels.c1.capacity=1000
# 每次提供100条数据发给sink
a1.channels.c1.transactionCapacity=100
# 配置sink - 表示以日志的形式输出在控制台
a1.sinks.s1.type=logger
# channel和sink以及Source绑定
# 给R1的source绑定一个通道(可以绑定多个)
a1.sources.r1.channels=c1
# 给s1绑定一个通道
a1.sinks.s1.channel=c1
2 执行命令
../bin/flume-ng agent -n a1 -c ../conf/ -f httpsource.conf -Dflume.root.logger=INFO,console
在外部进行提交post请求
curl -X POST -d '["headers":,"body":"tom"]'
# 解释
c: create 创建
url: 统一资源定位符
-X: 指定请求方式
-d: 请求的参数
6 常用Sink
| Sink | 备注 |
|---|---|
| Logger | 表示以日志的形式进行输出, 注意:要求在conf目录下必须有 log4j.properties |
| File Roll Sink | 将日志写到本地的文件中 |
| HDFS Sink | 将日志写到分布式系统 |
| AVRO Sink | 序列化 — 实现多级流动, 扇入流动, 扇出流动(至少需要两个节点) |
File Roll Sink
1 复制并编辑 basic.conf ==> filesink.conf
# agent起个名称
# 绑定来源,因为来源有可能会有多个
a1.sources=r1
# 绑定通道, 因为有扇出流动
a1.channels=c1
# 绑定目的地, 因为扇出流动有多个目的地
a1.sinks=s1
# 配置Source
# 通过nc发送HTTP请求获取数据
a1.sources.r1.type=netcat
# 表示从本地获取数据
a1.sources.r1.bind=0.0.0.0
# 绑定端口号
a1.sources.r1.port=8090
# 配置Channel
# 表示内存通道
a1.channels.c1.type=memory
# 最多能够存储1000条数据, 对应了1000个Event事件
a1.channels.c1.capacity=1000
# 每次提供100条数据发送给Sink
a1.channels.c1.transactionCapacity=100
# 配置Sink - 表示将日志存储到文件中
a1.sinks.s1.type=file_roll
# 表示将存储到该目录下
a1.sinks.s1.sink.diretory=/home/flumelog
# 每个一个小时产生一个新的文件
# 单位 s
a1.sinks.s1.sink.rollInterval=3600
# channel 和 Sink 以及 Source 之间的绑定
# 给r1的Source绑定一个通道(可以绑定多个)
a1.sources.r1.channels=c1
# 给s1绑定一个通道
a1.sinks.s1.channel=c1
2 执行命令
../bin/flume-ng agent -n a1 -c ../conf/ -f filesink.conf -Dflume.root.logger=INFO,console
HDFS Sink
1 复制并编辑 basic.conf ==> hdfssink.conf
# agent起个名称
# 绑定来源,因为来源有可能会有多个
a1.sources=r1
# 绑定通道, 因为有扇出流动
a1.channels=c1
# 绑定目的地, 因为扇出流动有多个目的地
a1.sinks=s1
# 配置Source
# 通过nc发送HTTP请求获取数据
a1.sources.r1.type=netcat
# 表示从本地获取数据
a1.sources.r1.bind=0.0.0.0
# 绑定端口号
a1.sources.r1.port=8090
# 配置Channel
# 表示内存通道
a1.channels.c1.type=memory
# 最多能够存储1000条数据, 对应了1000个Event事件
a1.channels.c1.capacity=1000
# 每次提供100条数据发送给Sink
a1.channels.c1.transactionCapacity=100
# 配置Sink - 表示以日志的方式输出在控制台
a1.sinks.s1.type=hdfs
# HDFS 的路径(数据目的地)
a1.sinks.s1.hdfs.path=hdfs://hadoop01:9000/flume
# 利用流的形式将数据写到分布式文件系统
a1.sinks.s1.hdfs.fileType=DataStream
# channel 和 Sink 以及 Source 之间的绑定
# 给r1的Source绑定一个通道(可以绑定多个)
a1.sources.r1.channels=c1
# 给s1绑定一个通道
a1.sinks.s1.channel=c1
2 执行命令
../bin/flume-ng agent -n a1 -c ../conf/ -f hdfssink.conf -Dflume.root.logger=INFO,console
AVRO Sink / 多级流动
复制并编辑 basic.conf ==> avrosink.conf
cp basic.conf avrosink.conf
分发Flume文件夹
scp -r flume-1.6.0/ root@hadoop02:/home/software/
scp -r flume-1.6.0/ root@hadoop03:/home/software/
Hadoop01
# agent起个名称
# 绑定来源,因为来源有可能会有多个
a1.sources=r1
# 绑定通道, 因为有扇出流动
a1.channels=c1
# 绑定目的地, 因为扇出流动有多个目的地
a1.sinks=s1
# 配置Source
# 通过nc发送HTTP请求获取数据
a1.sources.r1.type=netcat
# 表示从本地获取数据
a1.sources.r1.bind=0.0.0.0
# 绑定端口号
a1.sources.r1.port=8090
# 配置Channel
# 表示内存通道
a1.channels.c1.type=memory
# 最多能够存储1000条数据, 对应了1000个Event事件
a1.channels.c1.capacity=1000
# 每次提供100条数据发送给Sink
a1.channels.c1.transactionCapacity=100
# 配置Sink
a1.sinks.s1.type=avro
a1.sinks.s1.hostname=hadoop02
a1.sinks.s1.port=8080
# channel 和 Sink 以及 Source 之间的绑定
# 给r1的Source绑定一个通道(可以绑定多个)
a1.sources.r1.channels=c1
# 给s1绑定一个通道
a1.sinks.s1.channel=c1
hadoop02
# agent起个名称
# 绑定来源,因为来源有可能会有多个
a1.sources=r1
# 绑定通道, 因为有扇出流动
a1.channels=c1
# 绑定目的地, 因为扇出流动有多个目的地
a1.sinks=s1
# 配置Source
# 通过nc发送HTTP请求获取数据
a1.sources.r1.type=avro
# 表示从本地获取数据
a1.sources.r1.bind=0.0.0.0
# 绑定端口号
a1.sources.r1.port=8080
# 配置Channel
# 表示内存通道
a1.channels.c1.type=memory
# 最多能够存储1000条数据, 对应了1000个Event事件
a1.channels.c1.capacity=1000
# 每次提供100条数据发送给Sink
a1.channels.c1.transactionCapacity=100
# 配置Sink
a1.sinks.s1.type=avro
a1.sinks.s1.hostname=hadoop03
a1.sinks.s1.port=8070
# channel 和 Sink 以及 Source 之间的绑定
# 给r1的Source绑定一个通道(可以绑定多个)
a1.sources.r1.channels=c1
# 给s1绑定一个通道
a1.sinks.s1.channel=c1
Hadoop03
# agent起个名称
# 绑定来源,因为来源有可能会有多个
a1.sources=r1
# 绑定通道, 因为有扇出流动
a1.channels=c1
# 绑定目的地, 因为扇出流动有多个目的地
a1.sinks=s1
# 配置Source
# 通过nc发送HTTP请求获取数据
a1.sources.r1.type=avro
# 表示从本地获取数据
a1.sources.r1.bind=0.0.0.0
# 绑定端口号
a1.sources.r1.port=8070
# 配置Channel
# 表示内存通道
a1.channels.c1.type=memory
# 最多能够存储1000条数据, 对应了1000个Event事件
a1.channels.c1.capacity=1000
# 每次提供100条数据发送给Sink
a1.channels.c1.transactionCapacity=100
# 配置Sink
a1.sinks.s1.type=logger
# channel 和 Sink 以及 Source 之间的绑定
# 给r1的Source绑定一个通道(可以绑定多个)
a1.sources.r1.channels=c1
# 给s1绑定一个通道
a1.sinks.s1.channel=c1
执行命令
# 三节点执行命令 顺序为 03 -> 02 -> 01
../bin/flume-ng agent -n a1 -c ../conf/ -f avrosink.conf -Dflume.root.logger=INFO,console
扇入流动
复制并编辑 shanru.conf
cp avrosink.conf shanru.conf
Hadoop01
# agent起个名称
# 绑定来源,因为来源有可能会有多个
a1.sources=r1
# 绑定通道,因为有扇出流动
a1.channels=c1
# 绑定目的地,因为扇出流动有多个目的地
a1.sinks=s1
# 配置Source
# 通过nc发送HTTP请求获取数据
a1.sources.r1.type=avro
# 表示从本地获取数据
a1.sources.r1.bind=0.0.0.0
# 绑定端口号
a1.sources.r1.port=8090
# 配置Channel
# 表示内存通道
a1.channels.c1.type=memory
# 最多能够存储1000调数据,对应了1000个event事件
a1.channels.c1.capacity=1000
# 每次提供100条数据发给sink
a1.channels.c1.transactionCapacity=100
# 配置sink - 表示以日志的形式输出在控制台
a1.sinks.s1.type=avro
a1.sinks.s1.hostname=hadoop03
a1.sinks.s1.port=8070
#channel和sink以及Source绑定
# 给R1的source绑定一个通道(可以绑定多个)
a1.sources.r1.channels=c1
# 给s1绑定一个通道
a1.sinks.s1.channel=c1
Hadoop02
# agent起个名称
# 绑定来源,因为来源有可能会有多个
a1.sources=r1
# 绑定通道,因为有扇出流动
a1.channels=c1
# 绑定目的地,因为扇出流动有多个目的地
a1.sinks=s1
# 配置Source
# 通过nc发送HTTP请求获取数据
a1.sources.r1.type=avro
# 表示从本地获取数据
a1.sources.r1.bind=0.0.0.0
# 绑定端口号
a1.sources.r1.port=8090
# 配置Channel
# 表示内存通道
a1.channels.c1.type=memory
# 最多能够存储1000调数据,对应了1000个event事件
a1.channels.c1.capacity=1000
# 每次提供100条数据发给sink
a1.channels.c1.transactionCapacity=100
# 配置sink - 表示以日志的形式输出在控制台
a1.sinks.s1.type=avro
a1.sinks.s1.hostname=hadoop03
a1.sinks.s1.port=8070
#channel和sink以及Source绑定
# 给R1的source绑定一个通道(可以绑定多个)
a1.sources.r1.channels=c1 c2
# 给s1绑定一个通道
a1.sinks.s1.channel=c1
a1.sinks.s2.channel=c2
Hadoop03
# agent起个名称
# 绑定来源,因为来源有可能会有多个
a1.sources=r1
# 绑定通道,因为有扇出流动
a1.channels=c1
# 绑定目的地,因为扇出流动有多个目的地
a1.sinks=s1
# 配置Source
# 通过nc发送HTTP请求获取数据
a1.sources.r1.type=avro
# 表示从本地获取数据
a1.sources.r1.bind=0.0.0.0
# 绑定端口号
a1.sources.r1.port=8070
# 配置Channel
# 表示内存通道
a1.channels.c1.type=memory
# 最多能够存储1000调数据,对应了1000个event事件
a1.channels.c1.capacity=1000
# 每次提供100条数据发给sink
a1.channels.c1.transactionCapacity=100
# 配置sink - 表示以日志的形式输出在控制台
a1.sinks.s1.type=logger
#channel和sink以及Source绑定
# 给R1的source绑定一个通道(可以绑定多个)
a1.sources.r1.channels=c1
# 给s1绑定一个通道
a1.sinks.s1.channel=c1
执行命令
# 三节点执行命令 顺序为 03 -> 02 == 01
../bin/flume-ng agent -n a1 -c ../conf/ -f shanru.conf -Dflume.root.logger=INFO,console
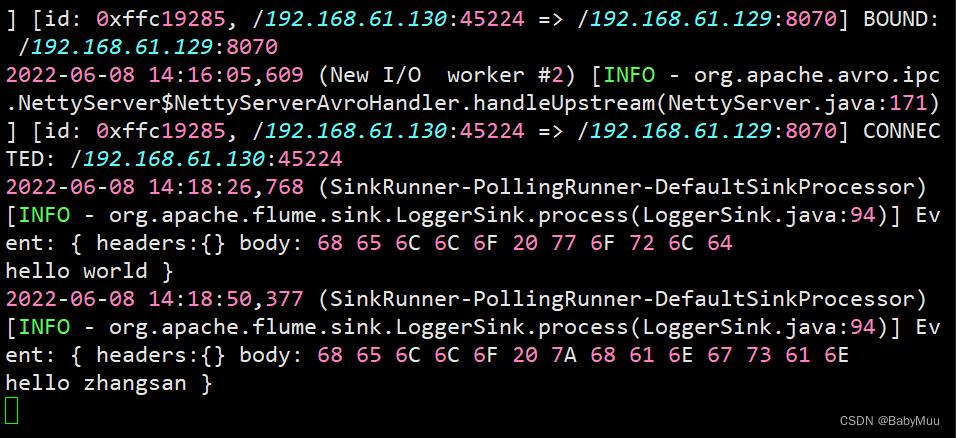
测试
# 分别新启动一个 hadoop01 hadoop02
# 在hadoop01 上执行命令
nc hadoop01 8090
# 随意输入一些字符 返回ok
# 在 hadoop02 上执行命令
nc hadoop02 8080
# 随意输入一些字符 返回ok
测试结果


扇出流动
复制并编辑 shanchu.conf
cp basic.conf shanchu.conf
Hadoop01
# agent起个名称
# 绑定来源,因为来源有可能会有多个
a1.sources=r1
# 绑定通道, 因为有扇出流动
a1.channels=c1 c2
# 绑定目的地, 因为扇出流动有多个目的地
a1.sinks=s1 s2
# 配置Source
# 通过nc发送HTTP请求获取数据
a1.sources.r1.type=netcat
# 表示从本地获取数据
a1.sources.r1.bind=0.0.0.0
# 绑定端口号
a1.sources.r1.port=8090
# 配置Channel --- 表示内存通道
# 配置 c1
a1.channels.c1.type=memory
# 最多能够存储1000条数据, 对应了1000个Event事件
a1.channels.c1.capacity=1000
# 每次提供100条数据发送给Sink
a1.channels.c1.transactionCapacity=100
# 配置 c2
a1.channels.c2.type=memory
#最多能够存储1000调数据,对应了1000个event事件
a1.channels.c2.capacity=1000
#每次提供100条数据发给sink
a1.channels.c2.transactionCapacity=100
# 配置Sink - 表示以日志的方式输出在控制台
# 配置s1
a1.sinks.s1.type=avro
a1.sinks.s1.hostname=hadoop02
a1.sinks.s1.port=9999
# 配置s2
a1.sinks.s2.type=avro
a1.sinks.s2.hostname=hadoop03
a1.sinks.s2.port=9999
# channel 和 Sink 以及 Source 之间的绑定
# 给r1的Source绑定一个通道(可以绑定多个)
a1.sources.r1.channels=c1
# 给s1绑定一个通道
a1.sinks.s1.channel=c1
Hadoop02
# agent起个名称
# 绑定来源,因为来源有可能会有多个
a1.sources=r1
# 绑定通道,因为有扇出流动
a1.channels=c1
# 绑定目的地,因为扇出流动有多个目的地
a1.sinks=s1
# 配置Source
# 通过nc发送HTTP请求获取数据
a1.sources.r1.type=avro
# 表示从本地获取数据
a1.sources.r1.bind=0.0.0.0
# 绑定端口号
a1.sources.r1.port=9999
# 配置Channel
# 表示内存通道
a1.channels.c1.type=memory
# 最多能够存储1000调数据,对应了1000个event事件
a1.channels.c1.capacity=1000
# 每次提供100条数据发给sink
a1.channels.c1.transactionCapacity=100
# 配置sink - 表示以日志的形式输出在控制台
a1.sinks.s1.type=logger
#channel和sink以及Source绑定
# 给R1的source绑定一个通道(可以绑定多个)
a1.sources.r1.channels=c1 c2
# 给s1绑定一个通道
a1.sinks.s1.channel=c1
a1.sinks.s2.channel=c2
Hadoop03
# agent起个名称
# 绑定来源,因为来源有可能会有多个
a1.sources=r1
# 绑定通道,因为有扇出流动
a1.channels=c1
# 绑定目的地,因为扇出流动有多个目的地
a1.sinks=s1
# 配置Source
# 通过nc发送HTTP请求获取数据
a1.sources.r1.type=avro
# 表示从本地获取数据
a1.sources.r1.bind=0.0.0.0
# 绑定端口号
a1.sources.r1.port=9999
# 配置Channel
# 表示内存通道
a1.channels.c1.type=memory
# 最多能够存储1000调数据,对应了1000个event事件
a1.channels.c1.capacity=1000
# 每次提供100条数据发给sink
a1.channels.c1.transactionCapacity=100
# 配置sink - 表示以日志的形式输出在控制台
a1.sinks.s1.type=logger
#channel和sink以及Source绑定
# 给R1的source绑定一个通道(可以绑定多个)
a1.sources.r1.channels=c1
# 给s1绑定一个通道
a1.sinks.s1.channel=c1
执行命令
# 三节点执行命令 顺序为 03 == 02 -> 01
../bin/flume-ng agent -n a1 -c ../conf/ -f shanchu.conf -Dflume.root.logger=INFO,console
测试
# 新启动一个 hadoop01
# 执行命令
nc hadoop01 8090
# 随意输入一些字符

测试结果
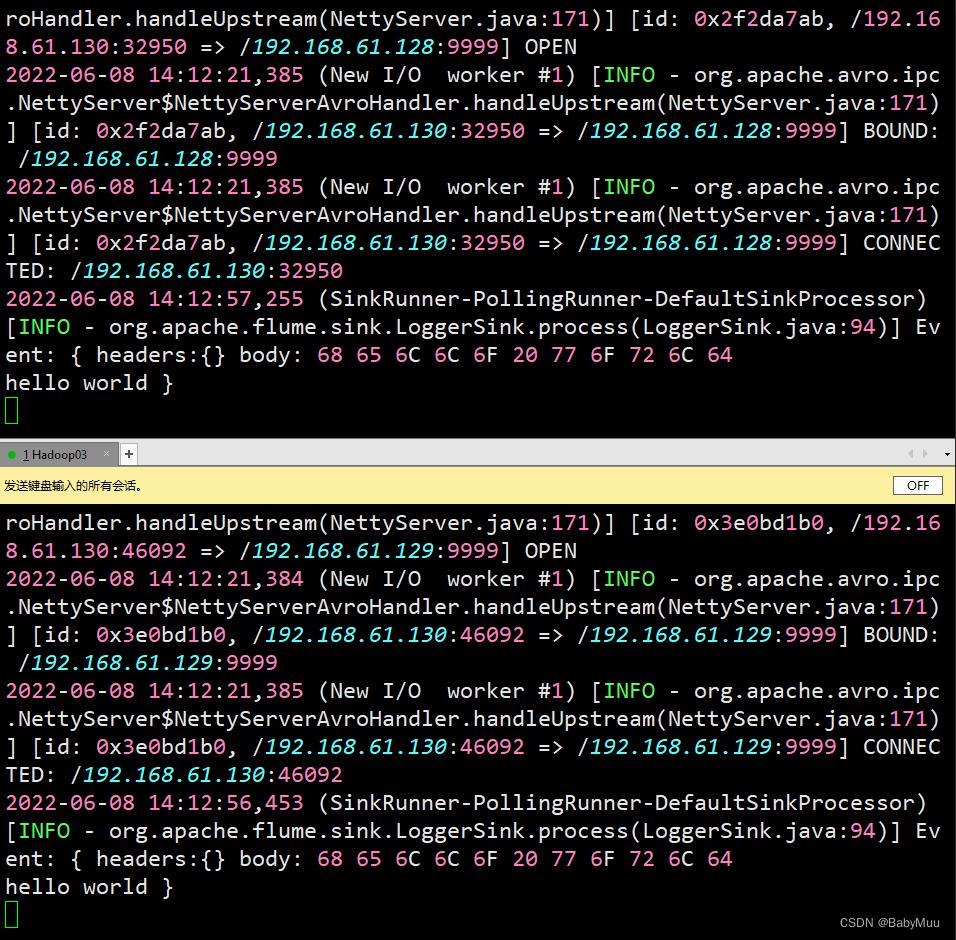
7 常用Channel
- Memory Channel — 内存通道
- capacity: 表示这个Channel能够存储多少条数据, 在实际开发中简易调节为10w左右
- transactionCapacity: 傲视给Sink多少条数据, 即意味着一次性传输多少条数据, 根据实际开发一般调节为1000-3000左右
- JDBC Channel — 表示将数据存储在数据库中 — 尽在测试环境中使用
- Flume 到目前为止支持的数据库有且仅有一个: Derby
- File Channel — 文件通道 — IO读写 — 性能低
- 内存溢出通道 — 官方未正式推出(测试阶段)
8 轮播机制
9 监听机制
10 消费者组
以上是关于Flume学习笔记的主要内容,如果未能解决你的问题,请参考以下文章