数据分析之道-基础知识函数
Posted i阿极
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据分析之道-基础知识函数相关的知识,希望对你有一定的参考价值。

文章目录
专栏导读
✍ 作者简介:i阿极,CSDN Python领域新星创作者,专注于分享python领域知识。
✍ 本文录入于《数据分析之道》,本专栏针对大学生、初级数据分析工程师精心打造,对python基础知识点逐一击破,不断学习,提升自我。
✍ 订阅后,可以阅读《数据分析之道》中全部文章内容,包含python基础语法、数据结构和文件操作,科学计算,实现文件内容操作,实现数据可视化等等。
✍ 还可以订阅进阶篇《数据分析之术》,其包含数据分析方法论、数据挖掘算法原理、业务分析实战。
✍ 其他专栏:《数据分析案例》 ,《机器学习案例》
Python函数是一段代码块,可被多次调用,用于完成特定的任务。函数可以带有参数和返回值,使得代码更加模块化和可重用。
1、定义函数
定义一个函数需要使用 def 关键字,后面跟着函数名和一对圆括号。在圆括号中可以列出函数的参数名,多个参数用逗号隔开。函数定义结束后,需要在下一行缩进后编写函数的代码块。函数的代码块可以包含多个语句,可以执行特定的操作,例如计算、打印输出等。
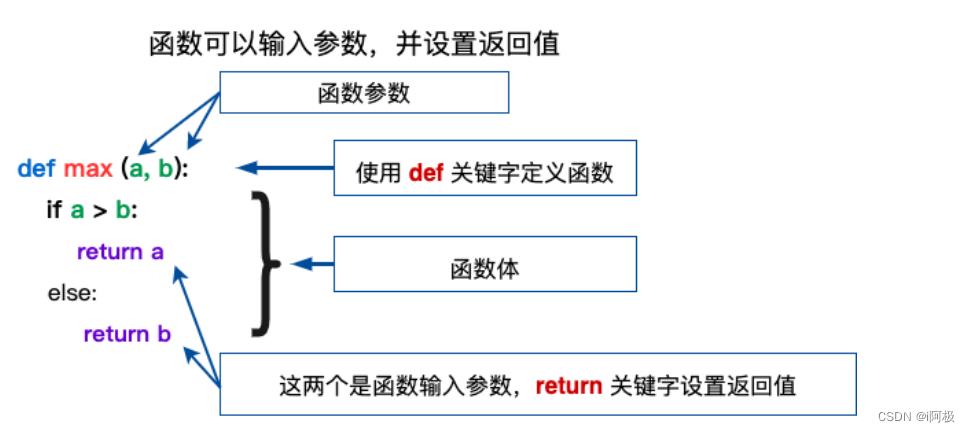
下面是一个简单的示例,定义了一个接收两个参数的函数,用于计算两个数字的和并返回结果:
def add(a, b):
result = a + b
return result
2、调用函数
定义了函数之后,可以通过函数名来调用该函数。调用函数时需要传入参数,根据函数定义的参数个数和顺序传入相应的值。调用函数后,函数会执行其中的代码块,计算出结果并返回。
result = add(1,2)
print(result)

上述代码会输出 3,因为传入的参数为 1 和 2,函数内部计算出这两个数的和并返回了结果。
3、参数传递
在调用函数时,可以通过位置或关键字方式传递参数。位置参数是按照函数定义时的顺序依次传入,而关键字参数则是按照参数名指定的顺序传入。
# 位置参数
result = add(1, 2)
# 关键字参数
result = add(a=1, b=2)
函数还支持默认参数和可变参数。默认参数是在定义函数时给参数指定一个默认值,调用函数时如果不传入该参数,则使用默认值。可变参数则是在函数定义中使用 * 或 ** 来接收可变数量的参数。
# 默认参数
def greeting(name, message="Hello"):
print(f"message, name!")
greeting("Alice") # 输出 "Hello, Alice!"
greeting("Bob", "Hi") # 输出 "Hi, Bob!"
# 可变参数
def print_values(*values):
for value in values:
print(value)
print_values(1, 2, 3)

4、返回值
函数可以通过 return 语句来返回一个值。当函数执行到 return 语句时,会将该值返回给函数的调用者。
def multiply(a, b):
return a * b
result = multiply(3, 4)
print(result)

5、默认参数
在Python中,可以为函数的参数指定默认值。如果在调用函数时没有为这些参数传递值,则会使用默认值。
例如:
def foo(x, y=2, z=3):
print(x, y, z)
foo(1)
foo(1, 4)
foo(1, 4, 5)

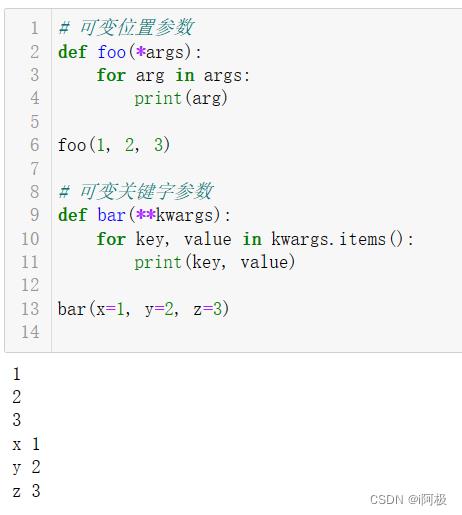
6、可变参数
有时候,我们希望函数可以接受任意数量的参数,这时可以使用可变参数。在Python中,可变参数分为两种:可变位置参数和可变关键字参数。可变位置参数用*args表示,可变关键字参数用**kwargs表示。
例如:
# 可变位置参数
def foo(*args):
for arg in args:
print(arg)
foo(1, 2, 3)
# 可变关键字参数
def bar(**kwargs):
for key, value in kwargs.items():
print(key, value)
bar(x=1, y=2, z=3)
7、匿名函数
在Python中,可以使用lambda关键字创建匿名函数。匿名函数通常用于简单的操作,并且可以作为函数的参数传递。
例如:
# 使用lambda创建匿名函数
add = lambda x, y: x + y
# 作为函数参数传递
result = map(add, [1, 2, 3], [4, 5, 6])
print(list(result)) # [5, 7, 9]

📢文章下方有交流学习区!一起学习进步!💪💪💪
📢创作不易,如果觉得文章不错,可以点赞👍收藏📁评论📒
📢你的支持和鼓励是我创作的动力❗❗❗
Linux运维之道之网络基础学习1.3
网络基础1.3
数据链路层解析:
数据链路层:
位于物理层与网络层之间;
数据链路层的功能:
--数据链路的建立,维护,拆除
--帧包装,帧传输,帧同步
--帧的差错恢复
--流量控制
------------------------------------------------------------------------------------------------------------------
以太网:
什么是以太网:
--我们平常使用的就是以太网;
--以太网工作在数据链路层 ;
以太网MAC地址:
--以太网地址用来识别一个以太网上的一个设备或一组设备;
802.3以太网帧格式;
数据链路层的两个子层:
介质访问控制子层(MAC):
---将上层交下来的数据封装成帧进行发送;
---实现和维护介质访问控制协议;
---比特差错检测;
--MAC地址的寻址;
逻辑链路控制子层(LLC):
---建立和释放数据链路层的逻辑连接;
---提供与上层的接口;
---给帧加上序号;
----------------------------------------------------------------------------------------------------------------------------------
以太网交换机
什么是交换机:
交换机是用来连接局域网的主要设备;
--交换机能够根据以太网帧中目标viao地址智能的转发数据,因此交换机工作在数据链路层;
--交换机分割冲突域,实现全双公通信;
交换机的工作原理:
初始状态
MAC地址学习
广播未知数据帧
接收方回应
交换机实现单波通信
学习:
--MAC地址表是交换机通过学习接收的数据帧的源MAC地址来形成的广播;
广播:
---如果目标地址在MAC地址表中没有,交换机就向除接收到该数据帧的端口外的其他所有端口外的其他所有端口广播该数据帧。
转发:
---交换机根据MAC地址表单波转发数据帧
更新:
--交换机MAC地址表的老化时间是300秒
--交换机如果发现一个帧的入端口和MAC地址表的源MAC地址的所在端口不同,交换机将MAC地址重新学习到新的端口。
------------------------------------------------------------------------------------------------------------------------------
单工,半双工,全双工:
单工:只有一个信道,传输方向只能是单向的;
半双工:只有一个信道,在同一时刻,只能单向传输;
全双工:双信道,同时可以有双向数据传输;
冲突与冲突域:
--如果冲突过多,则传输效率会降低;
--为了提高效率,分割冲突域;
分割冲突域:
交换机背板交换矩阵结构;
--交换机的每一个端口访问另一个端口时,都有一条专有的的线路,不会产生冲突;
------------------------------------------------------------------------------------------------------------------------
广播域:
广播域指接收同样广播消息的节点的集合。
交换机分割冲突域,但是不分割广播域;即交换机的所有端口属于同一个广播域;
交换机内部交换方式:
存储转发:
---是计算机网络领域应用最为广泛的方式;
---对进入交换机的数据包进行错误检测;
---支持不同速度的端口间的转换;
--在数据处理时延时大;
快速转发:
---延迟非常小,交换非常快;
---不能提供错误检测能力;
---由于没有缓存,不能将具有不同速率的端口的输入/输出端口直接接通,而且容易丢包;
分段过滤:
---检查数据包的长度是否够64个字节,如果小于64字节,说明是假包,则丢弃该包;如果大于64字节,则发送该包;
---不提供数据校验,它得数据处理速度比存储转发方式快,但比直通式快;
本文出自 “13391400” 博客,请务必保留此出处http://13401400.blog.51cto.com/13391400/1976120
以上是关于数据分析之道-基础知识函数的主要内容,如果未能解决你的问题,请参考以下文章