中文字体反爬,易易易易易易Python脱敏车车车车车车车车
Posted 梦想橡皮擦
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了中文字体反爬,易易易易易易Python脱敏车车车车车车车车相关的知识,希望对你有一定的参考价值。
文章目录
⛳️ 易 实战场景 车
本次字体反爬案例对应的是【易Python脱敏车】点评频道,该站点使用了字体反爬技术,并且是中文字符反爬,可以重点研究下。
站点地址如下所示(全角字符)
https://dianping.yiche.com/
打开目标站点任意链接之后,可以通过开发者工具发现,其文字部分存在大量的混淆字符。

既然已经发现了字体混淆,那接下来我们再夯实一下字符矢量图相关知识,下载易车的一个字体文件。

字体文件是通过 unicode 编码,然后对应字体文件。
浏览器实现原理是通过传递字符的字节码,转换成 unicode 编号,然后在字体文件中找到字体矢量图,如果没有字体文件,会在系统自带的字体中寻找矢量图。
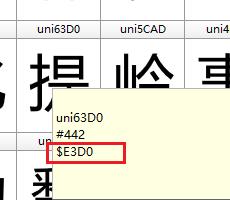
上图中 uni6211 对应的就是汉字 我 的编码。
⛳️ 易 实战编码 车
有了多篇字体反爬的经验,我们很容易发现本次的目标站点使用了固定的字体文件,名称为 yc-ft.woff,其中包含了 473 个特殊汉字。
接下来只需要将字体文件编码和汉字的对一个关系读取出来即可。
from fontTools.ttLib import TTFont
font = TTFont('fonts/yc-ft.woff')
print(font)
font_map = font['cmap'].getBestCmap()
print(font_map)
网页响应的源码格式如下所示:
<em class="iconfont"></em>车也
其中  就是对应的字符,然后 e3d0 对应到字体矢量图中,对应的是 提 字。
📢📢📢📢📢📢
💗 你正在阅读 【梦想橡皮擦】 的博客
👍 阅读完毕,可以点点小手赞一下
🌻 发现错误,直接评论区中指正吧
📆 橡皮擦的第 673 篇原创博客
从订购之日起,案例 5 年内保证更新
以上是关于中文字体反爬,易易易易易易Python脱敏车车车车车车车车的主要内容,如果未能解决你的问题,请参考以下文章