Java中CAS详解
Posted LiWang__
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Java中CAS详解相关的知识,希望对你有一定的参考价值。
目录
5、LongAdder 类的 casCellsBusy 方法
九、使用 AtomicStampedReference 解决 ABA 问题
2、AtomicStampReference 的常用的几个方法如下:
一、什么是CAS
CAS,compare and swap的缩写,中文翻译成比较并交换。
CAS 操作包含三个操作数 —— 内存位置(V)、预期原值(A)和新值(B)。 如果内存位置的值与预期原值相匹配,那么处理器会自动将该位置值更新为新值 。否则,处理器不做任何操作。
二、从一个案例引出CAS
案例:
public class Test
public static int count = 0;
private final static int MAX_TREAD=10;
public static AtomicInteger atomicInteger = new AtomicInteger(0);
public static void main(String[] args) throws InterruptedException
/*CountDownLatch能够使一个线程在等待另外一些线程完成各自工作之后,再继续执行。
使用一个计数器进行实现。计数器初始值为线程的数量。当每一个线程完成自己任务后,计数器的值就会减一。
当计数器的值为0时,表示所有的线程都已经完成一些任务,然后在CountDownLatch上等待的线程就可以恢复执行接下来的任务。*/
CountDownLatch latch = new CountDownLatch(MAX_TREAD);
//匿名内部类
Runnable runnable = new Runnable()
@Override
public void run()
for (int i = 0; i < 1000; i++)
count++;
atomicInteger.getAndIncrement();
latch.countDown(); // 当前线程调用此方法,则计数减一
;
//同时启动多个线程
for (int i = 0; i < MAX_TREAD; i++)
new Thread(runnable).start();
latch.await(); // 阻塞当前线程,直到计数器的值为0
System.out.println("理论结果:" + 1000 * MAX_TREAD);
System.out.println("static count: " + count);
System.out.println("AtomicInteger: " + atomicInteger.intValue());
输出:
理论结果:10000
static count: 9994
AtomicInteger: 10000我们发现每次运行,atomicInteger 的结果值都是正确的,count++的结果却不对,下面我们就开始探究原因。
三、Java中的Atomic 原子操作包
JUC 并发包中原子类 , 都存放在 java.util.concurrent.atomic 类路径下: 根据操作的目标数据类型,可以将 JUC 包中的原子类分为 4 类:
根据操作的目标数据类型,可以将 JUC 包中的原子类分为 4 类:
- 基本原子类
- 数组原子类
- 原子引用类型
- 字段更新原子类
1. 基本原子类
基本原子类的功能,是通过原子方式更新 Java 基础类型变量的值。基本原子类主要包括了以下三个:- AtomicInteger:整型原子类。
- AtomicLong:长整型原子类。
- AtomicBoolean :布尔型原子类。
2. 数组原子类
数组原子类的功能,是通过原子方式更数组里的某个元素的值。数组原子类主要包括了以下三个:- AtomicIntegerArray:整型数组原子类。
- AtomicLongArray:长整型数组原子类。
- AtomicReferenceArray :引用类型数组原子类。
3. 引用原子类
引用原子类主要包括了以下三个:- AtomicReference:引用类型原子类。
- AtomicMarkableReference :带有更新标记位的原子引用类型。
- AtomicStampedReference :带有更新版本号的原子引用类型。
4. 字段更新原子类
字段更新原子类主要包括了以下三个:- AtomicIntegerFieldUpdater:原子更新整型字段的更新器。
- AtomicLongFieldUpdater:原子更新长整型字段的更新器。
- AtomicReferenceFieldUpdater:原子更新引用类型里的字段。
五、类 AtomicInteger
1、常用的方法:
| 方法 | 介绍 |
|---|---|
| public final int get() | 获取当前的值 |
| public final int getAndSet(int newValue) | 获取当前的值,然后设置新的值 |
| public final int getAndIncrement() | 获取当前的值,然后自增 |
| public final int getAndDecrement() | 获取当前的值,然后自减 |
| public final int getAndAdd(int delta) | 获取当前的值,并加上预期的值 |
| boolean compareAndSet(int expect, int update) | 通过 CAS 方式设置整数值 |
AtomicInteger 案例:
private static void out(int oldValue,int newValue)
System.out.println("旧值:"+oldValue+",新值:"+newValue);
public static void main(String[] args)
int value = 0;
AtomicInteger atomicInteger= new AtomicInteger(0);
//取值,然后设置一个新值
value = atomicInteger.getAndSet(3);
//旧值:0,新值:3
out(value,atomicInteger.get());
//取值,然后自增
value = atomicInteger.getAndIncrement();
//旧值:3,新值:4
out(value,atomicInteger.get());
//取值,然后增加 5
value = atomicInteger.getAndAdd(5);
//旧值:4,新值:9
out(value,atomicInteger.get());
//CAS 交换
boolean flag = atomicInteger.compareAndSet(9, 100);
//旧值:4,新值:100
out(value,atomicInteger.get());
2、AtomicInteger 源码解析:
public class AtomicInteger extends Number implements java.io.Serializable
// 设置使用Unsafe.compareAndSwapInt进行更新
private static final Unsafe unsafe = Unsafe.getUnsafe();
private static final long valueOffset;
static
try
valueOffset = unsafe.objectFieldOffset
(AtomicInteger.class.getDeclaredField("value"));
catch (Exception ex)
throw new Error(ex);
...省略
private volatile int value;
//自动设置为给定值并返回旧值。
public final int getAndSet(int newValue)
return unsafe.getAndSetInt(this, valueOffset, newValue);
//以原子方式将当前值加1并返回旧值。
public final int getAndIncrement()
return unsafe.getAndAddInt(this, valueOffset, 1);
//以原子方式将当前值减1并返回旧值。
public final int getAndDecrement()
return unsafe.getAndAddInt(this, valueOffset, -1);
//原子地将给定值添加到当前值并返回旧值。
public final int getAndAdd(int delta)
return unsafe.getAndAddInt(this, valueOffset, delta);
...省略
通过源码我们发现AtomicInteger的增减操作都调用了Unsafe 实例的方法,下面我们对Unsafe类做介绍:
六、Unsafe类
Unsafe 是位于 sun.misc 包下的一个类,Unsafe 提供了CAS 方法,直接通过native 方式(封装 C++代码)调用了底层的 CPU 指令 cmpxchg。 Unsafe类,翻译为中文:危险的,Unsafe全限定名是sun.misc.Unsafe,从名字中我们可以看出来这个类对普通程序员来说是“危险”的,一般应用开发者不会用到这个类。
1、Unsafe 提供的 CAS 方法
主要如下: 定义在 Unsafe 类中的三个 “比较并交换”原子方法
/*
@param o 包含要修改的字段的对象
@param offset 字段在对象内的偏移量
@param expected 期望值(旧的值)
@param update 更新值(新的值)
@return true 更新成功 | false 更新失败
*/
public final native boolean compareAndSwapObject(Object o, long offset, Object expected, Object update);
public final native boolean compareAndSwapInt( Object o, long offset, int expected,int update);
public final native boolean compareAndSwapLong( Object o, long offset, long expected, long update);2、获取属性偏移量
Unsafe 提供的获取字段(属性)偏移量的相关操作,主要如下:
/**
* @param o 需要操作属性的反射
* @return 属性的偏移量
*/
public native long staticFieldOffset(Field field);
public native long objectFieldOffset(Field field);3、根据属性的偏移量获取属性的最新值:
/**
* @param o 字段所属于的对象实例
* @param fieldOffset 字段的偏移量
* @return 字段的最新值
*/
public native int getIntVolatile(Object o, long fieldOffset);七、CAS的缺点
1. ABA问题。因为CAS需要在操作值的时候检查下值有没有发生变化,如果没有发生变化则更新,但是如果一个值原来是A,变成了B,又变成了A,那么使用CAS进行检查时会发现它的值没有发生变化,但是实际上却变化了。
JDK 提供了两个类 AtomicStampedReference、AtomicMarkableReference 来解决 ABA 问题。
2. 只能保证一个共享变量的原子操作。一个比较简单的规避方法为:把多个共享变量合并成一个共享变量来操作。 JDK 提供了 AtomicReference 类来保证引用对象之间的原子性,可以把多个变量放在一个 AtomicReference 实例后再进行 CAS 操作。比如有两个共享变量 i=1、j=2,可以将二者合并成一个对象,然后用 CAS 来操作该合并对象的 AtomicReference 引用。
3. 循环时间长开销大。高并发下N多线程同时去操作一个变量,会造成大量线程CAS失败,然后处于自旋状态,导致严重浪费CPU资源,降低了并发性。
解决 CAS 恶性空自旋的较为常见的方案为:- 分散操作热点,使用 LongAdder 替代基础原子类 AtomicLong。
- 使用队列削峰,将发生 CAS 争用的线程加入一个队列中排队,降低 CAS 争用的激烈程度。JUC 中非常重要的基础类 AQS(抽象队列同步器)就是这么做的。
八、以空间换时间:LongAdder
1、LongAdder 的原理
LongAdder 的基本思路就是分散热点, 如果有竞争的话,内部维护了多个Cell变量,每个Cell里面有一个初始值为0的long型变量, 不同线程会命中到数组的不同Cell (槽 )中,各个线程只对自己Cell(槽) 中的那个值进行 CAS 操作。这样热点就被分散了,冲突的概率就小很多。 在没有竞争的情况下,要累加的数通过 CAS 累加到 base 上。 如果要获得完整的 LongAdder 存储的值,只要将各个槽中的变量值累加,后的值即可。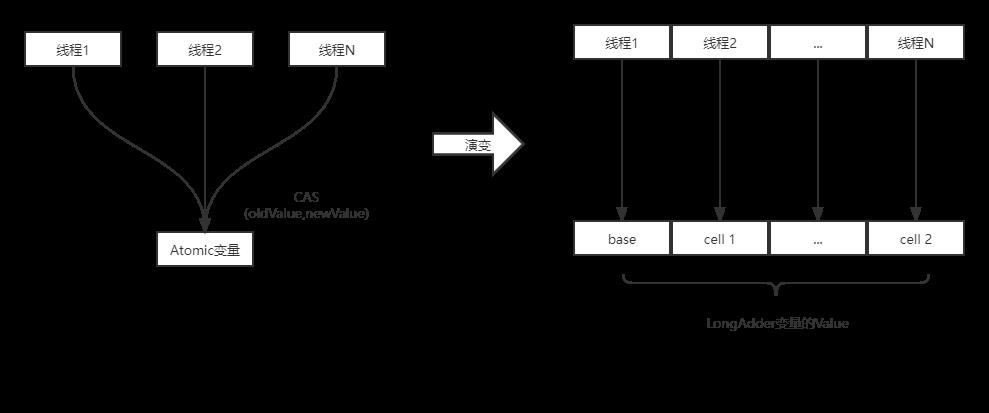
2、longAddr内部结构

Striped64类的重要成员属性:
/**
* cell表,当非空时,大小是2的幂。
*/
transient volatile Cell[] cells;
/**
* 基础值,主要在没有争用时使用
* 在没有争用时使用CAS更新这个值
*/
transient volatile long base;
/**
* 自旋锁(通过CAS锁定) 在调整大小和/或创建cell时使用,
* 为 0 表示 cells 数组没有处于创建、扩容阶段,反之为1
*/
transient volatile int cellsBusy;public long longValue()
return sum();
public long sum()
Striped64.Cell[] as = cells; Striped64.Cell a;
long sum = base;
if (as != null)
for (int i = 0; i < as.length; ++i)
if ((a = as[i]) != null)
sum += a.value;
return sum;
4、LongAdder 类的 add 方法
自增
public void increment()
add(1L);
自减
public void decrement()
add(-1L);
add方法
public void add(long x)
//as: 表示cells引用
//b: base值
//v: 表示当前线程命中的cell的期望值
//m: 表示cells数组长度
//a: 表示当前线程命中的cell
Striped64.Cell[] as; long b, v; int m; Striped64.Cell a;
/*
stop 1:true -> 说明存在竞争,并且cells数组已经初始化了,当前线程需要将数据写入到对应的cell中
false -> 表示cells未初始化,当前所有线程应该将数据写到base中
stop 2:true -> 表示发生竞争了,可能需要重试或者扩容
false -> 表示当前线程cas替换数据成功
*/
if (
(as = cells) != null //stop 1
||
!casBase(b = base, b + x) //stop 2
)
/*
进入的条件:
1.cells数组已经初始化了,当前线程需要将数据写入到对应的cell中
2.表示发生竞争了,可能需要重试或者扩容
*/
/*
是否有竞争:true -> 没有竞争
false -> 有竞争*/
boolean uncontended = true;
/*
stop 3:as == null || (m = as.length - 1)<0 代表 cells 没有初始化
stop 4:表示当前线程命中的cell为空,意思是还没有其他线程在同一个位置做过累加操作。
stop 5:表示当前线程命中的cell不为空, 然后在该Cell对象上进行CAS设置其值为v+x(x为该 Cell 需要累加的值),如果CAS操作失败,表示存在争用。
*/
if (as == null || (m = as.length - 1) < 0 || //stop 3
(a = as[getProbe() & m]) == null || //stop 4
!(uncontended = a.cas(v = a.value, v + x))) //stop 5
/*
进入的条件:
1.cells 未初始化
2.当前线程对应下标的cell为空
3.当前线程对应的cell有竞争并且cas失败
*/
longAccumulate(x, null, uncontended);
longAccumulate方法
final void longAccumulate(long x, LongBinaryOperator fn,
boolean wasUncontended)
int h;
//条件成立: 说明当前线程还未分配hash值
if ((h = getProbe()) == 0)
//1.给当前线程分配hash值
ThreadLocalRandom.current(); // force initialization
//2.提取当前线程的hash值
h = getProbe();
//3.因为上一步提取了重新分配的新的hash值,所以会重新分配cells数组的位置给当前线程写入,先假设它能找到一个元素不冲突的数组下标。
wasUncontended = true;
//扩容意向,collide=true 可以扩容,collide=false 不可扩容
boolean collide = false; // True if last slot nonempty
//自旋,一直到操作成功
for (;;)
//as: 表示cells引用
//a: 当前线程命中的cell
//n: cells数组长度
//a: 表示当前线程命中的cell的期望值
Striped64.Cell[] as; Striped64.Cell a; int n; long v;
//CASE1: cells数组已经初始化了,当前线程将数据写入到对应的cell中
if ((as = cells) != null && (n = as.length) > 0)
//CASE1.1: true 表示下标位置的 cell 为 null,需要创建 new Cell
if ((a = as[(n - 1) & h]) == null)
// cells 数组没有处于创建、扩容阶段
if (cellsBusy == 0) // Try to attach new Cell
Striped64.Cell r = new Striped64.Cell(x); // Optimistically create
if (cellsBusy == 0 && casCellsBusy())
boolean created = false;
try // Recheck under lock
Striped64.Cell[] rs; int m, j;
if ((rs = cells) != null &&
(m = rs.length) > 0 &&
rs[j = (m - 1) & h] == null)
rs[j] = r;
created = true;
finally
cellsBusy = 0;
if (created)//创建、扩容成功,退出自旋
break;
continue; // Slot is now non-empty
collide = false;
// CASE1.2:当前线程竞争修改cell失败
else if (!wasUncontended) // CAS already known to fail
wasUncontended = true; // Continue after rehash
// CASE 1.3:当前线程 rehash 过 hash 值,CAS 更新 Cell
else if (a.cas(v = a.value, ((fn == null) ? v + x :
fn.applyAsLong(v, x))))
break;
// CASE1.4:判断是否可以扩容
// CASE1.4.1:n >= NCPU
// true -> cells数组长度已经 >= cpu核数,不可进行扩容,把扩容意向改为false
// false -> 可扩容
// CASE1.4.2:cells != as
// true -> 其它线程已经扩容过了,当前线程rehash之后重试即可
// false -> 未有线程对cells进行修改
else if (n >= NCPU || cells != as)
collide = false; // 把扩容意向改为false
// CASE 1.5:设置扩容意向为 true,但是不一定真的发生扩容
else if (!collide)
collide = true;
//CASE1.6:真正扩容的逻辑
// CASE1.6.1:cellsBusy == 0
// true -> 表示cells没有被其它线程占用,当前线程可以去竞争锁
// false -> 表示有其它线程正在操作cells
// CASE1.6.2:casCellsBusy()
// true -> 表示当前线程获取锁成功,可以进行扩容操作
// false -> 表示当前线程获取锁失败,当前时刻有其它线程在做扩容相关的操作
else if (cellsBusy == 0 && casCellsBusy())
try
//重复判断一下当前线程的临时cells数组是否与原cells数组一致(防止有其它线程提前修改了cells数组,因为cells是volatile的全局变量)
if (cells == as) // Expand table unless stale
//n << 1 表示数组长度翻一倍
Striped64.Cell[] rs = new Striped64.Cell[n << 1];
for (int i = 0; i < n; ++i)
rs[i] = as[i];
cells = rs;
finally
cellsBusy = 0;
//扩容后,将扩容意向置为false
collide = false;
continue; // Retry with expanded table
//重置当前线程hash值
h = advanceProbe(h);
//CASE2:cells 还未初始化(as 为 null),并且 cellsBusy 加锁成功
// CASE2.1:判断锁是否被占用
// true -> 表示当前未加锁
// false -> 表示当前已加锁
// CASE2.2:因为其它线程可能会在当前线程给as赋值之后修改了cells
// true -> cells没有被其它线程修改
// false -> cells已经被其它线程修改
// CASE2.3:获取锁
// true -> 获取锁成功 会把cellsBusy = 1
// false -> 表示其它线程正在持有这把锁
else if (cellsBusy == 0 && cells == as && casCellsBusy())
boolean init = false;
try
//双重检查,防止其它线程已经初始化,当前线程再次初始化,会导致数据丢失
// Initialize table
if (cells == as)
Striped64.Cell[] rs = new Striped64.Cell[2];
rs[h & 1] = new Striped64.Cell(x);
cells = rs;
init = true;
finally
cellsBusy = 0;
if (init)
break;
//CASE3:当前线程 cellsBusy 加锁失败,表示其他线程正在初始化 cells
//所以当前线程将值累加到 base,注意 add(…)方法调用此方法时 fn 为 null
else if (casBase(v = base, ((fn == null) ? v + x :
fn.applyAsLong(v, x))))
break; // Fall back on using base
5、LongAdder 类的 casCellsBusy 方法
casCellsBusy 方法的代码很简单,就是将 cellsBusy 成员的值改为 1 ,表示目前的 cells 数组在 初始化或扩容中: final boolean casCellsBusy()
return UNSAFE.compareAndSwapInt(this, CELLSBUSY, 0, 1);
九、使用 AtomicStampedReference 解决 ABA 问题
JDK 的提供了一个类似 AtomicStampedReference 类来解决 ABA 问题。
AtomicStampReference 在 CAS 的基础上增加了一个 Stamp 整型 印戳(或标记),使用这个印戳可以来觉察数据是否发生变化,给数据带上了一种实效性的检验。 AtomicStampReference 的 compareAndSet 方法首先检查当前的对象引用值是否等于预期引用, 并且当前印戳( Stamp )标志是否等于预期标志,如果全部相等,则以原子方式将引用值和印戳 ( Stamp )标志的值更新为给定的更新值。1、AtomicStampReference 的构造器:
/**
* @param initialRef初始引用
* @param initialStamp初始戳记
*\\
AtomicStampedReference(V initialRef, int initialStamp)2、AtomicStampReference 的常用的几个方法如下:
| 方法 | 介绍 |
| public V getRerference() | 引用的当前值 |
| public int getStamp() | 返回当前的"戳记" |
public boolean weakCompareAndSet(V expectedReference,
V newReference,
int expectedStamp,
int newStamp)
| expectedReference 引用的旧值 newReference 引用的新值 expectedStamp 旧的戳记 newStamp 新的戳记 |
3、案例
public static void main(String[] args)
boolean success = false;
AtomicStampedReference<Integer> atomicStampedReference = new AtomicStampedReference<Integer>(1, 0);
int stamp = atomicStampedReference.getStamp();
success = atomicStampedReference.compareAndSet(1, 0, stamp, stamp + 1);
System.out.println("success:" + success + ";reference:" + "" + atomicStampedReference.getReference() + ";stamp:" + atomicStampedReference.getStamp());
//修改印戳,更新失败
stamp = 0;
success = atomicStampedReference.compareAndSet(0, 1, stamp, stamp + 1);
System.out.println("success:" + success + ";reference:" + "" + atomicStampedReference.getReference() + ";stamp:" + atomicStampedReference.getStamp());
输出:
success:true;reference:0;stamp:1
success:false;reference:0;stamp:1
并发编程的灵魂:CAS机制详解
Java中提供了很多原子操作类来保证共享变量操作的原子性。这些原子操作的底层原理都是使用了CAS机制。在使用一门技术之前,了解这个技术的底层原理是非常重要的,所以本篇文章就先来讲讲什么是CAS机制,CAS机制存在的一些问题以及在Java中怎么使用CAS机制。其实Java并发框架的基石一共有两块,一块是本文介绍的CAS,另一块就是AQS,后续也会写文章介绍。
什么是CAS机制
CAS机制是一种数据更新的方式。在具体讲什么是CAS机制之前,我们先来聊下在多线程环境下,对共享变量进行数据更新的两种模式:悲观锁模式和乐观锁模式。
悲观锁更新的方式认为:在更新数据的时候大概率会有其他线程去争夺共享资源,所以悲观锁的做法是:第一个获取资源的线程会将资源锁定起来,其他没争夺到资源的线程只能进入阻塞队列,等第一个获取资源的线程释放锁之后,这些线程才能有机会重新争夺资源。synchronized就是java中悲观锁的典型实现,synchronized使用起来非常简单方便,但是会使没争抢到资源的线程进入阻塞状态,线程在阻塞状态和Runnable状态之间切换效率较低(比较慢)。比如你的更新操作其实是非常快的,这种情况下你还用synchronized将其他线程都锁住了,线程从Blocked状态切换回Runnable华的时间可能比你的更新操作的时间还要长。
乐观锁更新方式认为:在更新数据的时候其他线程争抢这个共享变量的概率非常小,所以更新数据的时候不会对共享数据加锁。但是在正式更新数据之前会检查数据是否被其他线程改变过,如果未被其他线程改变过就将共享变量更新成最新值,如果发现共享变量已经被其他线程更新过了,就重试,直到成功为止。CAS机制就是乐观锁的典型实现。
CAS,是Compare and Swap的简称,在这个机制中有三个核心的参数:
- 主内存中存放的共享变量的值:V(一般情况下这个V是内存的地址值,通过这个地址可以获得内存中的值)
- 工作内存中共享变量的副本值,也叫预期值:A
- 需要将共享变量更新到的最新值:B
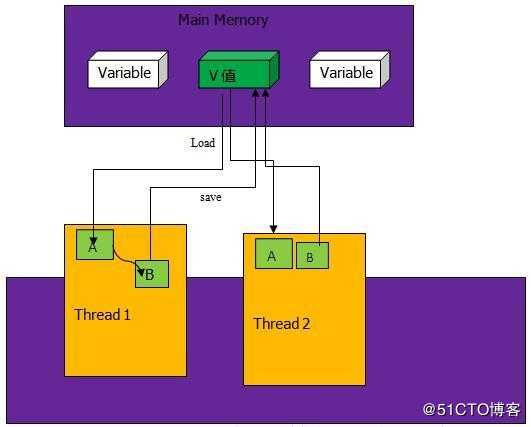
如上图中,主存中保存V值,线程中要使用V值要先从主存中读取V值到线程的工作内存A中,然后计算后变成B值,最后再把B值写回到内存V值中。多个线程共用V值都是如此操作。CAS的核心是在将B值写入到V之前要比较A值和V值是否相同,如果不相同证明此时V值已经被其他线程改变,重新将V值赋给A,并重新计算得到B,如果相同,则将B值赋给V。
值得注意的是CAS机制中的这步步骤是原子性的(从指令层面提供的原子操作),所以CAS机制可以解决多线程并发编程对共享变量读写的原子性问题。
CAS机制优缺点
缺点
1. ABA问题
ABA问题:CAS在操作的时候会检查变量的值是否被更改过,如果没有则更新值,但是带来一个问题,最开始的值是A,接着变成B,最后又变成了A。经过检查这个值确实没有修改过,因为最后的值还是A,但是实际上这个值确实已经被修改过了。为了解决这个问题,在每次进行操作的时候加上一个版本号,每次操作的就是两个值,一个版本号和某个值,A——>B——>A问题就变成了1A——>2B——>3A。在jdk中提供了AtomicStampedReference类解决ABA问题,用Pair这个内部类实现,包含两个属性,分别代表版本号和引用,在compareAndSet中先对当前引用进行检查,再对版本号标志进行检查,只有全部相等才更新值。
2. 可能会消耗较高的CPU
看起来CAS比锁的效率高,从阻塞机制变成了非阻塞机制,减少了线程之间等待的时间。每个方法不能绝对的比另一个好,在线程之间竞争程度大的时候,如果使用CAS,每次都有很多的线程在竞争,也就是说CAS机制不能更新成功。这种情况下CAS机制会一直重试,这样就会比较耗费CPU。因此可以看出,如果线程之间竞争程度小,使用CAS是一个很好的选择;但是如果竞争很大,使用锁可能是个更好的选择。在并发量非常高的环境中,如果仍然想通过原子类来更新的话,可以使用AtomicLong的替代类:LongAdder。
3. 不能保证代码块的原子性
Java中的CAS机制只能保证共享变量操作的原子性,而不能保证代码块的原子性。
优点
- 可以保证变量操作的原子性;
- 并发量不是很高的情况下,使用CAS机制比使用锁机制效率更高;
- 在线程对共享资源占用时间较短的情况下,使用CAS机制效率也会较高。
Java提供的CAS操作类--Unsafe类
从Java5开始引入了对CAS机制的底层的支持,在这之前需要开发人员编写相关的代码才可以实现CAS。在原子变量类Atomic中(例如AtomicInteger、AtomicLong)可以看到CAS操作的代码,在这里的代码都是调用了底层(核心代码调用native修饰的方法)的实现方法。在AtomicInteger源码中可以看getAndSet方法和compareAndSet方法之间的关系,compareAndSet方法调用了底层的实现,该方法可以实现与一个volatile变量的读取和写入相同的效果。在前面说到了volatile不支持例如i++这样的复合操作,在Atomic中提供了实现该操作的方法。JVM对CAS的支持通过这些原子类(Atomic***)暴露出来,供我们使用。
而Atomic系类的类底层调用的是Unsafe类的API,Unsafe类提供了一系列的compareAndSwap*方法,下面就简单介绍下Unsafe类的API:
- long objectFieldOffset(Field field)方法:返回指定的变量在所属类中的内存偏移地址,该偏移地址仅仅在该Unsafe函数中访问指定字段时使用。如下代码使用Unsafe类获取变量value在AtomicLong对象中的内存偏移。
static { try { valueOffset = unsafe.objectFieldOffset (AtomicInteger.class.getDeclaredField("value")); } catch (Exception ex) { throw new Error(ex); } } - int arrayBaseOffset(Class arrayClass)方法:获取数组中第一个元素的地址。
- int arrayIndexScale(Class arrayClass)方法:获取数组中一个元素占用的字节。
- boolean compareAndSwapLong(Object obj, long offset, long expect, long update)方法:比较对象obj中偏移量为offset的变量的值是否与expect相等,相等则使用update值更新,然后返回true,否则返回false。
- public native long getLongvolatile(Object obj, long offset)方法:获取对象obj中偏移量为offset的变量对应volatile语义的值。
- void putLongvolatile(Object obj, long offset, long value)方法:设置obj对象中offset偏移的类型为long的field的值为value,支持volatile语义。
- void putOrderedLong(Object obj, long offset, long value)方法:设置obj对象中offset偏移地址对应的long型field的值为value。这是一个有延迟的putLongvolatile方法,并且不保证值修改对其他线程立刻可见。只有在变量使用volatile修饰并且预计会被意外修改时才使用该方法。
- void park(boolean isAbsolute, long time)方法:阻塞当前线程,其中参数isAbsolute等于false且time等于0表示一直阻塞。time大于0表示等待指定的time后阻塞线程会被唤醒,这个time是个相对值,是个增量值,也就是相对当前时间累加time后当前线程就会被唤醒。如果isAbsolute等于true,并且time大于0,则表示阻塞的线程到指定的时间点后会被唤醒,这里time是个绝对时间,是将某个时间点换算为ms后的值。另外,当其他线程调用了当前阻塞线程的interrupt方法而中断了当前线程时,当前线程也会返回,而当其他线程调用了unPark方法并且把当前线程作为参数时当前线程也会返回。
- void unpark(Object thread)方法:唤醒调用park后阻塞的线程。
下面是JDK8新增的函数,这里只列出Long类型操作。
-
long getAndSetLong(Object obj, long offset, long update)方法:获取对象obj中偏移量为offset的变量volatile语义的当前值,并设置变量volatile语义的值为update。
//这个方法只是封装了compareAndSwapLong的使用,不需要自己写重试机制 public final long getAndSetLong(Object var1, long var2, long var4) { long var6; do { var6 = this.getLongVolatile(var1, var2); } while(!this.compareAndSwapLong(var1, var2, var6, var4)); return var6; } - long getAndAddLong(Object obj, long offset, long addValue)方法:获取对象obj中偏移量为offset的变量volatile语义的当前值,并设置变量值为原始值+addValue,原理和上面的方法类似。
CAS使用场景
- 使用一个变量统计网站的访问量;
- Atomic类操作;
- 数据库乐观锁更新。
以上是关于Java中CAS详解的主要内容,如果未能解决你的问题,请参考以下文章