Python selenium基础用法详解
Posted 醉蕤
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python selenium基础用法详解相关的知识,希望对你有一定的参考价值。

活动地址:CSDN21天学习挑战赛
学习的最大理由是想摆脱平庸,早一天就多一份人生的精彩;迟一天就多一天平庸的困扰。
学习日记
目录
一、Selenium库介绍
1、Selenium简介
Selenium 是一套完整的web应用程序测试系统,包含了测试的录制(Selenium IDE),编写及运行(Selenium Remote Control)和测试的并行处理(Selenium Grid)。Selenium的核心Selenium Core基于JsUnit,完全由javascript编写,因此可以用于任何支持JavaScript的浏览器上。Selenium 支持的语言包括C#,Java,Perl,php,Python 和 Ruby。目前,Selenium Web 驱动程序最受 Python 和 C#欢迎。 Selenium 测试脚本可以使用任何支持的编程语言进行编码,并且可以直接在大多数现代 Web 浏览器中运行。
2、Selenium的安装
打开 cmd,输入下面命令进行安装。
pip install selenium执行后,使用
pip show selenium查看是否安装成功。
3、安装浏览器驱动
针对不同的浏览器,需要安装不同的驱动
Firefox 浏览器驱动:Firefox
Chrome 浏览器驱动:Chrome
Edge 浏览器驱动:Edge
推荐chrome谷歌浏览器作为模拟浏览器,因此还需要chromedriver作为驱动,但 Chrome 在用 selenium 进行自动化测试时还是有部分 bug ,常规使用没什么问题,但如果出现一些很少见的报错,可以使用 Firefox 进行尝试,毕竟是 selenium 官方推荐使用的。
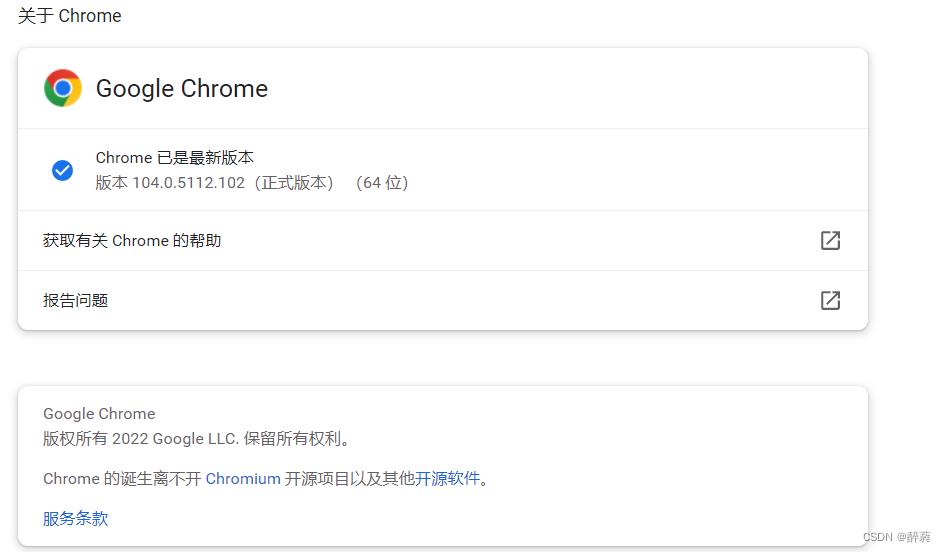
现在,因为相应版本选择需要查看谷歌浏览器版本,在chrome浏览器上方地址栏输入:
chrome://settings/help
4、下载驱动
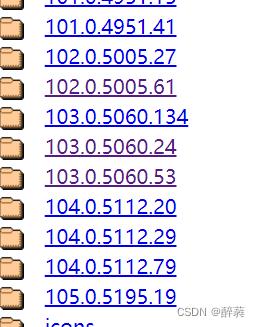
打开 Chrome驱动 。单击对应的版本。
根据自己的操作系统,选择下载
将
chromedriver.exe保存到任意位置,并把当前路径保存到环境变量中(我的电脑>>右键属性>>高级系统设置>>高级>>环境变量>>系统变量>>Path),添加的时候要注意不要把 path 变量给覆盖了,如果覆盖了千万别关机,然后百度。添加成功后使用下面代码进行测试。from selenium import webdriver driver = webdriver.Chrome()
5、定位页面
使用
selenium定位页面元素的前提是你已经了解基本的页面布局及各种标签含义。要定位并获取页面中的信息,首先要使用webdriver打开指定页面,再去定位。from selenium import webdriver # 不自动关闭浏览器 option = webdriver.ChromeOptions() option.add_experimental_option("detach", True) driver = webdriver.Chrome(chrome_options=option) driver.get('https://www.csdn.net/')
6、几种常见的页面元素定位方式
id 定位
标签的 id 具有唯一性,假设有input标签如下。
<input id="toolbar-search-input" autocomplete="off" type="text" value="" placeholder="C++难在哪里?">
driver.find_element_by_id("toolbar-search-input")name 定位
name 指定标签的名称,在页面中可不唯一。假设有meta标签如下
<meta name="keywords" content="CSDN博客,CSDN学院,CSDN论坛,CSDN直播">
driver.find_element_by_name("keywords")class 定位
class 指定标签的类名,在页面中可不唯一。假设有div标签如下
<div class="toolbar-search-container">
driver.find_element_by_class_name("toolbar-search-container")tag 定位
假设有div标签如下
<div class="toolbar-search-container">
driver.find_element_by_tag_name("div")link 定位
link 专门用来定位文本链接
<div class="practice-box" data-v-04f46969="">顶顶顶</div>
driver.find_element_by_link_text("顶顶顶")
7、浏览器控制
修改浏览器窗口大小
from selenium import webdriver # Chrome浏览器 driver = webdriver.Chrome() driver.get('https://www.csdn.net/') # 设置浏览器浏览器的宽高为:500x900 driver.set_window_size(500, 900)显示全屏:
from selenium import webdriver # Chrome浏览器 driver = webdriver.Chrome() driver.get('https://www.csdn.net/') driver.maximize_window()
浏览器前进、后退
from selenium import webdriver from time import sleep driver = webdriver.Chrome() # 访问CSDN首页 driver.get('https://www.csdn.net/') sleep(2) #访问CSDN个人主页 driver.get('https://blog.csdn.net/m0_63794226?spm=3001.5343') sleep(2) #返回(后退)到CSDN首页 driver.back() sleep(2) #前进到个人主页 driver.forward() # 新标签中打开 js = "window.open('https://www.csdn.net/')" driver.execute_script(js)
浏览器刷新
driver.refresh()# 刷新页面二、常见操作


python在selenium中做自动化测试用法详解
一、环境搭建参考:https://blog.csdn.net/efly2333/article/details/80346426
二、selenium用法详解(https://www.cnblogs.com/themost/p/6900852.html)
1 selenium用法详解 2 selenium主要是用来做自动化测试,支持多种浏览器,爬虫中主要用来解决JavaScript渲染问题。 3 模拟浏览器进行网页加载,当requests,urllib无法正常获取网页内容的时候 4 5 一、声明浏览器对象 6 注意点一,Python文件名或者包名不要命名为selenium,会导致无法导入 7 from selenium import webdriver 8 #webdriver可以认为是浏览器的驱动器,要驱动浏览器必须用到webdriver,支持多种浏览器,这里以Chrome为例 9 browser = webdriver.Chrome() 10 11 二、访问页面并获取网页html 12 from selenium import webdriver 13 browser = webdriver.Chrome() 14 browser.get(‘https://www.taobao.com‘) 15 print(browser.page_source)#browser.page_source是获取网页的全部html 16 browser.close() 17 18 三、查找元素 19 单个元素 20 from selenium import webdriver 21 browser = webdriver.Chrome() 22 browser.get(‘https://www.taobao.com‘) 23 input_first = browser.find_element_by_id(‘q‘) 24 input_second = browser.find_element_by_css_selector(‘#q‘) 25 input_third = browser.find_element_by_xpath(‘//*[@id="q"]‘) 26 print(input_first,input_second,input_third) 27 browser.close() 28 常用的查找方法 29 find_element_by_name 30 find_element_by_xpath 31 find_element_by_link_text 32 find_element_by_partial_link_text 33 find_element_by_tag_name 34 find_element_by_class_name 35 find_element_by_css_selector 36 也可以使用通用的方法 37 from selenium import webdriver 38 from selenium.webdriver.common.by import By 39 browser = webdriver.Chrome() 40 browser.get(‘https://www.taobao.com‘) 41 input_first = browser.find_element(BY.ID,‘q‘)#第一个参数传入名称,第二个传入具体的参数 42 print(input_first) 43 browser.close() 44 多个元素,elements多个s 45 input_first = browser.find_elements_by_id(‘q‘) 46 47 四、元素交互操作-搜索框传入关键词进行自动搜索 48 from selenium import webdriver 49 import time 50 browser = webdriver.Chrome() 51 browser.get(‘https://www.taobao.com‘) 52 input = browser.find_element_by_id(‘q‘)#找到搜索框 53 input.send_keys(‘iPhone‘)#传送入关键词 54 time.sleep(5) 55 input.clear()#清空搜索框 56 input.send_keys(‘男士内裤‘) 57 button = browser.find_element_by_class_name(‘btn-search‘)#找到搜索按钮 58 button.click() 59 更多操作: http://selenium-python.readthedocs.io/api.html#module-selenium.webdriver.remote.webelement#可以有属性、截图等等 60 61 五、交互动作,驱动浏览器进行动作,模拟拖拽动作,将动作附加到动作链中串行执行 62 from selenium import webdriver 63 from selenium.webdriver import ActionChains#引入动作链 64 65 browser = webdriver.Chrome() 66 url = ‘http://www.runoob.com/try/try.php?filename=jqueryui-api-droppable‘ 67 browser.get(url) 68 browser.switch_to.frame(‘iframeResult‘)#切换到iframeResult框架 69 source = browser.find_element_by_css_selector(‘#draggable‘)#找到被拖拽对象 70 target = browser.find_element_by_css_selector(‘#droppable‘)#找到目标 71 actions = ActionChains(browser)#声明actions对象 72 actions.drag_and_drop(source, target) 73 actions.perform()#执行动作 74 更多操作: http://selenium-python.readthedocs.io/api.html#module-selenium.webdriver.common.action_chains 75 76 六、执行JavaScript 77 有些动作可能没有提供api,比如进度条下拉,这时,我们可以通过代码执行JavaScript 78 from selenium import webdriver 79 browser = webdriver.Chrome() 80 browser.get(‘https://www.zhihu.com/explore‘) 81 browser.execute_script(‘window.scrollTo(0, document.body.scrollHeight)‘) 82 browser.execute_script(‘alert("To Bottom")‘) 83 84 七、获取元素信息 85 获取属性 86 from selenium import webdriver 87 from selenium.webdriver import ActionChains 88 89 browser = webdriver.Chrome() 90 url = ‘https://www.zhihu.com/explore‘ 91 browser.get(url) 92 logo = browser.find_element_by_id(‘zh-top-link-logo‘)#获取网站logo 93 print(logo) 94 print(logo.get_attribute(‘class‘)) 95 browser.close() 96 97 获取文本值 98 from selenium import webdriver 99 browser = webdriver.Chrome() 100 url = ‘https://www.zhihu.com/explore‘ 101 browser.get(url) 102 input = browser.find_element_by_class_name(‘zu-top-add-question‘) 103 print(input.text)#input.text文本值 104 browser.close() 105 106 # 获取Id,位置,标签名,大小 107 from selenium import webdriver 108 browser = webdriver.Chrome() 109 url = ‘https://www.zhihu.com/explore‘ 110 browser.get(url) 111 input = browser.find_element_by_class_name(‘zu-top-add-question‘) 112 print(input.id)#获取id 113 print(input.location)#获取位置 114 print(input.tag_name)#获取标签名 115 print(input.size)#获取大小 116 browser.close() 117 118 八、Frame操作 119 frame相当于独立的网页,如果在父类网frame查找子类的,则必须切换到子类的frame,子类如果查找父类也需要先切换 120 121 from selenium import webdriver 122 from selenium.common.exceptions import NoSuchElementException 123 124 browser = webdriver.Chrome() 125 url = ‘http://www.runoob.com/try/try.php?filename=jqueryui-api-droppable‘ 126 browser.get(url) 127 browser.switch_to.frame(‘iframeResult‘) 128 source = browser.find_element_by_css_selector(‘#draggable‘) 129 print(source) 130 try: 131 logo = browser.find_element_by_class_name(‘logo‘) 132 except NoSuchElementException: 133 print(‘NO LOGO‘) 134 browser.switch_to.parent_frame() 135 logo = browser.find_element_by_class_name(‘logo‘) 136 print(logo) 137 print(logo.text) 138 139 九、等待 140 141 隐式等待 142 当使用了隐式等待执行测试的时候,如果 WebDriver没有在 DOM中找到元素,将继续等待,超出设定时间后则抛出找不到元素的异常, 143 换句话说,当查找元素或元素并没有立即出现的时候,隐式等待将等待一段时间再查找 DOM,默认的时间是0 144 145 from selenium import webdriver 146 147 browser = webdriver.Chrome() 148 browser.implicitly_wait(10)#等待十秒加载不出来就会抛出异常,10秒内加载出来正常返回 149 browser.get(‘https://www.zhihu.com/explore‘) 150 input = browser.find_element_by_class_name(‘zu-top-add-question‘) 151 print(input) 152 153 显式等待 154 指定一个等待条件,和一个最长等待时间,程序会判断在等待时间内条件是否满足,如果满足则返回,如果不满足会继续等待,超过时间就会抛出异常 155 from selenium import webdriver 156 from selenium.webdriver.common.by import By 157 from selenium.webdriver.support.ui import WebDriverWait 158 from selenium.webdriver.support import expected_conditions as EC 159 160 browser = webdriver.Chrome() 161 browser.get(‘https://www.taobao.com/‘) 162 wait = WebDriverWait(browser, 10) 163 input = wait.until(EC.presence_of_element_located((By.ID, ‘q‘))) 164 button = wait.until(EC.element_to_be_clickable((By.CSS_SELECTOR, ‘.btn-search‘))) 165 print(input, button) 166 167 title_is 标题是某内容 168 title_contains 标题包含某内容 169 presence_of_element_located 元素加载出,传入定位元组,如(By.ID, ‘p‘) 170 visibility_of_element_located 元素可见,传入定位元组 171 visibility_of 可见,传入元素对象 172 presence_of_all_elements_located 所有元素加载出 173 text_to_be_present_in_element 某个元素文本包含某文字 174 text_to_be_present_in_element_value 某个元素值包含某文字 175 frame_to_be_available_and_switch_to_it frame加载并切换 176 invisibility_of_element_located 元素不可见 177 element_to_be_clickable 元素可点击 178 staleness_of 判断一个元素是否仍在DOM,可判断页面是否已经刷新 179 element_to_be_selected 元素可选择,传元素对象 180 element_located_to_be_selected 元素可选择,传入定位元组 181 element_selection_state_to_be 传入元素对象以及状态,相等返回True,否则返回False 182 element_located_selection_state_to_be 传入定位元组以及状态,相等返回True,否则返回False 183 alert_is_present 是否出现Alert 184 185 详细内容:http://selenium-python.readthedocs.io/api.html#module-selenium.webdriver.support.expected_conditions 186 187 十一、前进后退-实现浏览器的前进后退以浏览不同的网页 188 import time 189 from selenium import webdriver 190 191 browser = webdriver.Chrome() 192 browser.get(‘https://www.baidu.com/‘) 193 browser.get(‘https://www.taobao.com/‘) 194 browser.get(‘https://www.python.org/‘) 195 browser.back() 196 time.sleep(1) 197 browser.forward() 198 browser.close() 199 200 十二、Cookies 201 from selenium import webdriver 202 203 browser = webdriver.Chrome() 204 browser.get(‘https://www.zhihu.com/explore‘) 205 print(browser.get_cookies()) 206 browser.add_cookie({‘name‘: ‘name‘, ‘domain‘: ‘www.zhihu.com‘, ‘value‘: ‘germey‘}) 207 print(browser.get_cookies()) 208 browser.delete_all_cookies() 209 print(browser.get_cookies()) 210 211 选项卡管理 增加浏览器窗口 212 import time 213 from selenium import webdriver 214 215 browser = webdriver.Chrome() 216 browser.get(‘https://www.baidu.com‘) 217 browser.execute_script(‘window.open()‘) 218 print(browser.window_handles) 219 browser.switch_to_window(browser.window_handles[1]) 220 browser.get(‘https://www.taobao.com‘) 221 time.sleep(1) 222 browser.switch_to_window(browser.window_handles[0]) 223 browser.get(‘http://www.fishc.com‘) 224 225 十三、异常处理 226 from selenium import webdriver 227 228 browser = webdriver.Chrome() 229 browser.get(‘https://www.baidu.com‘) 230 browser.find_element_by_id(‘hello‘) 231 232 from selenium import webdriver 233 from selenium.common.exceptions import TimeoutException, NoSuchElementException 234 235 browser = webdriver.Chrome() 236 try: 237 browser.get(‘https://www.baidu.com‘) 238 except TimeoutException: 239 print(‘Time Out‘) 240 try: 241 browser.find_element_by_id(‘hello‘) 242 except NoSuchElementException: 243 print(‘No Element‘) 244 finally: 245 browser.close() 246 # 详细文档:http://selenium-python.readthedocs.io/api.html#module-selenium.common.exceptions
以上是关于Python selenium基础用法详解的主要内容,如果未能解决你的问题,请参考以下文章