数据湖常用查询优化技术
Posted 咬定青松
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据湖常用查询优化技术相关的知识,希望对你有一定的参考价值。
经济发展有周期,人的思想活动也是有周期的,是时候进行一场文化领域的整风运动了,尤其是那些空谈误国,乱教误人子弟的,就是缺少了对其思想改造的过程,严重脱离群众,是时候要常态化地下放了。
本文首发微信公众号:码上观世界
1
MinMax
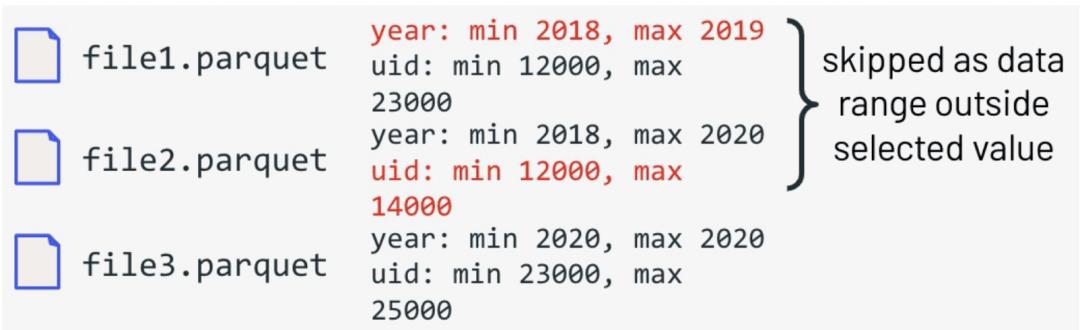
开放式数据格式文件的的元数据信息部分通常都包含当前文件每个列的最大、最小值,比如下图中的parquet文件包含两个字段:year和uid,并且
file1.parquet中列year的最大和最小值分别是2019和2018,列uid的最大和最小值分别是23000和12000,file2.parquet中列year的最大和最小值分别是2020和2018,列uid的最大和最小值分别是14000和12000,file3.parquet中列year的最大和最小值分别是2020和2020,列uid的最大和最小值分别是25000和23000:
当我们进行查询
select * from event where year=2019 and uid=20000因为这些元数据信息在数据写入文件时最终收集,因此在查询时候,很容易利用这些统计信息过滤掉不符合条件的数据文件。示例中,根据year=2020和uid=20000查询到符合条件的数据文件为file1.parquet,另外两个数据文件直接过滤掉了,减少了不必须的文件读取。
为了获取更好的过滤效果,MinMax通常进行全局排序,但是适合排序字段较少的情况,比如1个字段,当排序字段多于1个,依据索引的最左匹配规则,只有查询字段覆盖所有所有索引字段才能获得最好的查询效果,否则过滤效果将大打折扣,为此需要更合适的索引,比如Z-Order。
2
Z-Order
因为MinMax索引包括多个字段时,不能保证数据的聚集性,而利用Z-Order索引能够获得比MinMax平均更好的数据聚集性。Z-Order原理是把天然没有有序性的多维数据以某种方式映射成一维数据进行比较。映射后的一维数据,能够保证各个原始维度按照同种程度去保证其聚集性。如下图所示:
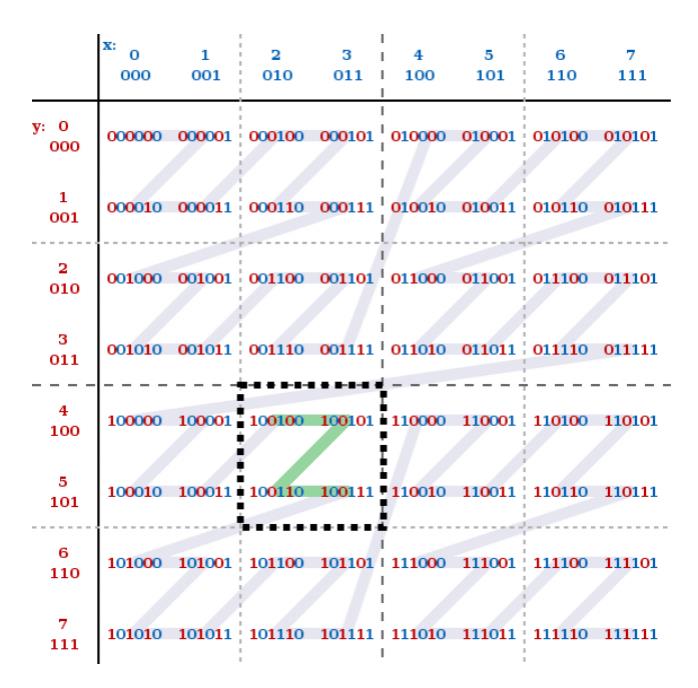
对X,Y这两个维度进行比特位的交叉组值,形成了Interleave Index进而得出一个新的值,这个值被称作Z-Value。从图中,可以看到针对X,Y这两个字段的数据,生成的z-value会呈现出一个Z形嵌套。按照这样的一个结构,在按照Z-Value排序时,能够同时保证X,Y两个字段的聚集性。
实现Z-Order 的一个前提是需要保证数据以保序的方式映射成一个正整型,但参与排序的字段类型很多,如String、Long、DateTime、Double等,如何将这些不同类型的值映射为正整型就是个问题。实践中,虽然可以将String类型取固定的前几位字符转为二进制来进行映射,但也带来了信息损失。另外,即使是正整型数据,由于其数据分布不同,可能导致映射的结果不符合Z-Order曲线的嵌套分布。比如,X的取值是0,1,2,3,4,5,6,7,Y的取值是8,16,24,32这种,计算出来的z-value排序效果实际上和数据按照order by y,x的效果是一样的。也就是说这种排序并没有带来额外的好处,对于X的聚集性无法保证。
为了获取更好的过滤效果,Z-Order也需要进行全局排序,但是Z-Order排序字段越多,排序效果也会越差。建议2-4个。
3
Bloom Flilter
Bloom Flilter是一种空间节约型的概率数据结构,通过一个长度为M的位数组来存储元素,可以添加元素但不能删除元素。每个元素使用k个哈希函数生成k个数值,大小位于区间[0,数组长度-1]中,添加元素到Bloom Flilter时,将相应位置置为1。当查询是否存在相应元素时,只需要判断k个位置的值是否全为1,如果不全是1,说明不存在该元素,如果全是1,则不一定说明存在该元素。k是一个远小于m的常数,m是跟添加到Bloom Flilter的元素个数成正比。两者的具体取值由Bloom Flilter的误判(false positive)比例决定。示例见下图:
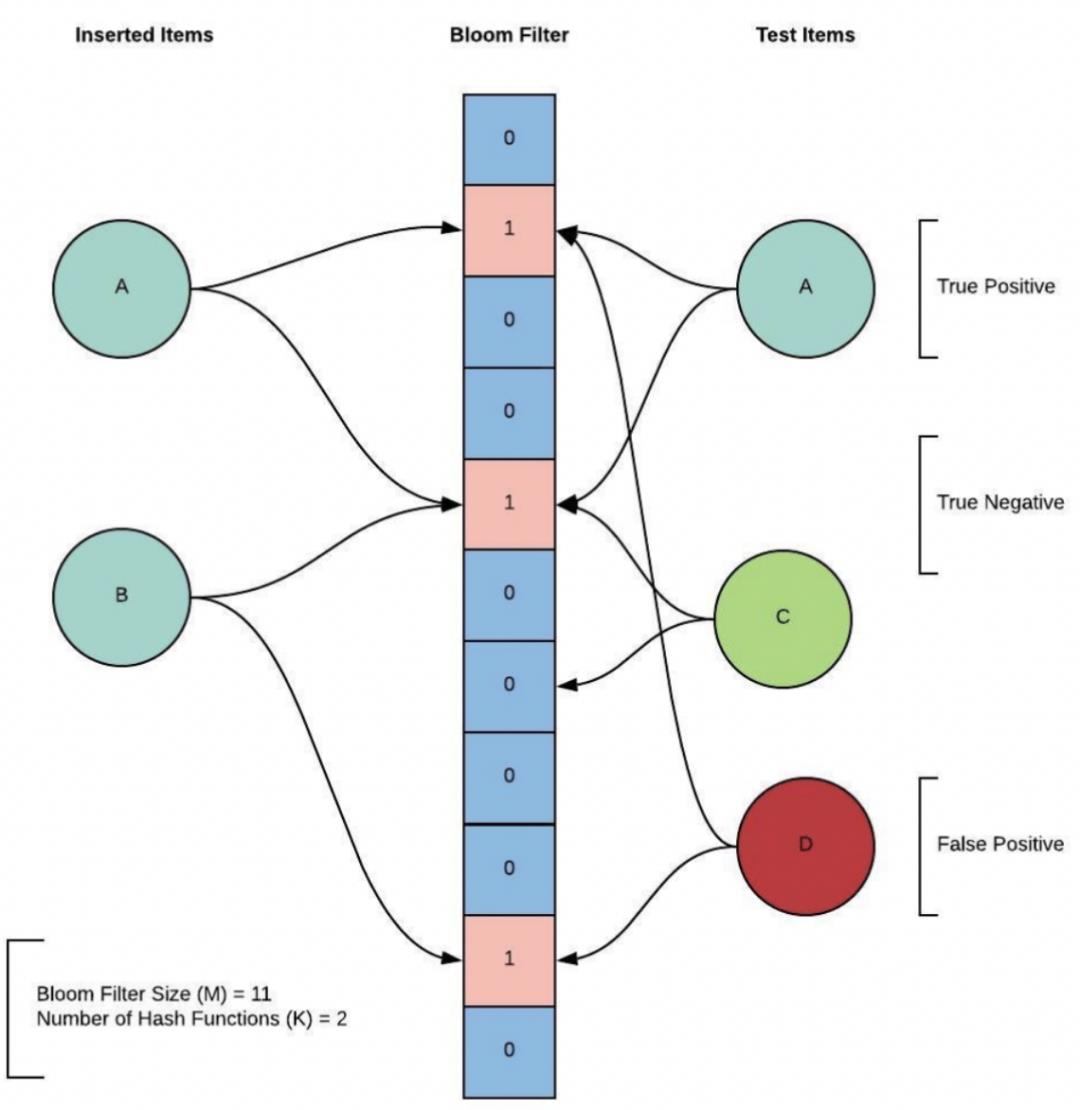
图中,Bloom Flilter长度m为11,哈希函数个数k为2,添加两个元素A和B,现在查询元素A、C、D,因为元素A哈希映射的两个位置都为1,且的确是A的哈希映射结果,所以能检索到A存在。元素C因为不满足所有哈希位置都为1,所以可以断定C不存在(True Negative)。但是因为D的哈希映射位置并非是D的哈希映射结果,即使其对应的哈希位置都为1,也不能断定D的存在,这对D来讲,就是误判(false positive)。
Bloom Filter利用少量哈希位来存储和定位元素,无论存储还是查询,其时间复杂度都是常量级:O(k),只跟哈希函数的个数有关。其代价是有一定的冲突概率,数组长度同添加的元素数量成正比,当数组长度越长,哈希函数越多,冲突概率越小,反之,冲突概率越高。因此,在使用中,需要确定数组长度和冲突概率。Bloom Flilter使用内存维护,且不存储元素本身,相比其他数据结构,能获得较高的空间和查询效率。缺点是只能确定元素是否存在,不能确定元素的具体位置,且不支持范围查询和删除操作。
4
bitmap indices
位图索引(bitmap indices)是一种专为多个键的简单查询而设计的。bitmap索引将每个被索引的列的值作为KEY,使用每个BIT表示一行,当这行中包含这个值时,设置为1,否则设置为0。应用位图索引的前提是记录必须被按顺序编号,一般从0开始。给出编号n,必须能够很容易的找到对应的记录,如果记录被存放在连续的块,可以将编号n转换成块编号+块内偏移的表示以快速定位记录位置。
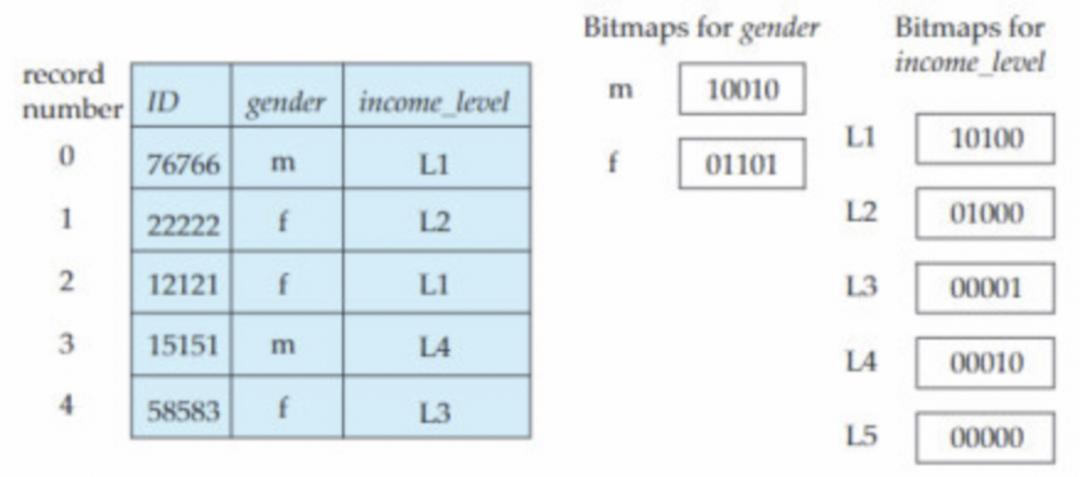
位图索引用一个位来对应一条记录,这便是记录需要被编号的原因。instructor_info表如上图,性别的值有男、女两种,收入等级则划分为5级,既有5种值。在给性别属性建立位图索引时,就会分别为male和female建立,对于male位图来说,如果一条记录的性别为male,则位图上对应的位会置1,female、收入等级位图也采用相同的做法。
位图索引的优势体现在根据多个键的查询的时候,比如查询:
where gender=’f’ and income_level='L2'只需将gender=’f’的位图索引和income_level='L2'的位图索引取位与运算即可:

除此之外,范围查询也是进行数据统计时候常见操作,基于位图索引的位或运算很容易实现范围查询,比如下面的查询:
where gender=’f’ and income_level>=’L2’我们只需要将income_level='L1'和income_level='L2'的位图索引位或运算,然后再跟gender=’f’的位图索引位与运算即可:

从上面示例中可见,bitmap索引就是用位图表示的索引,对列的每个键值建立一个位图。所以相对于b-tree索引,占用的存储空间非常小,创建和使用非常快。相比BloomFilter索引,bitmap索引不仅支持等值过滤,还支持范围过滤。经过良好编码的位图索引,还能够获得比BloomFilter索引更少的存储空间和更精准的匹配。但bitmap索引使用也有限制,比如适合建在值重复度高的列上,建议在100到100,000之间,如:职业、地市等。重复度过高则对比其他类型索引没有明显优势;重复度过低,则空间效率和性能会大大降低。对于经常更新的列,也不适合使用bitmap索引。
5
小文件合并与去重
流式数据入湖伴随着大量小文件的产生,根据文件产生的更新方式分为可追加的方式和非追加的方式两种:
可追加的方式:以只读事件日志的方式写入,如IoT事件
非追加的方式:以可更新的方式写入,如CDC事件
在高频的流处理场景,每天都可能产生成百上千的新文件,基于Flink实时计算引擎,事务提交的间隔越短,产生的文件大小越小,数量越多。在有些数据湖系统的实现中,即使没有可提交的数据,也可能会生成空文件(但存在文件元数据)。
这些文件随后被写入对象存储系统,如AWS S3、阿里云OSS等,然后再通过查询引擎,如Athena 、Trino等查询数据。大量的小文件将严重拖慢系统响应速度,因为读取每个文件,系统都要完成由下面三个基本步骤组成的动作:
打开文件
查找元数据
关闭文件
比如对ceberg来说,读取一个文件的数据,首先要打开快照文件,从快照中获取Manifenst文件,然后从Manifenst获取数据文件,最后从数据文件中读取数据。虽然打开一个文件可能只需要数毫秒的时间,但是当文件数量规模足够大,这个时间开销就会达到无法忍受的程度。当使用云上对象存储服务时,考虑到访问频次限制和调用预算,读取大量的文件有是无法接受的。
对于非追加的方式,有两种处理方式:
COW(Copy-on-Write):每次更新事件,会以该事件所在文件为副本,创建新的文件,最新的数据由当前最新的副本文件数据组成。COW会导致”写放大“和并发提交冲突问题,适合于写少读多的场景。
MOR(Merge-on-Read):每次创建增量更新的文件,最新的数据是由前一次提交的快照数据和当前增量更新数据组成。MOR会导致查询效率低,适合于写多读少的场景。MOR通常实现为一个持续性地合并并提交增量更新的后台进程。
当前三大数据湖技术中,Delta Lake 和 Iceberg仅支持 Copy-on-Write,因此它们不适合写负载重的场合,而Hudi同时支持Copy-on-Write和Merge-on-Read。Iceberg实现了 一种 Copy-on-Write 变体:每个快照只存储增量数据,最新全量数据由最新的快照通过引用的Manifest包含的所有数据文件组成。为了尽可能保证写入的效率,Iceberg将非追加的事件转换为可追加的Insert事件和Delete事件,分别存储在普通数据文件(data file)和删除数据文件(delete file)这两种类型的文件中。而删除数据文件存储的内容根据删除方式分为文件路径(position-delete)删除和等值删除(equality-delete)两种,前者为解决在当前快照周期内反复增加和删除相同主键记录的问题而引入,后者因为Iceberg缺少主键索引,为了避免更新记录去查询历史数据带来的开销,直接在删除文件中记录等值删除,它适用于跨快照周期数据更新和删除的场景。数据更新或删除的方式虽然保证了写入的高吞吐,但也带来了新的问题:
每条更新事件都会涉及到两个文件(追加数据文件和删除数据文件),相比可追加存储的方式,多了一份数据文件
在查询时需要将追加数据文件与删除数据文件关联,排除掉删除数据记录,特别是等值删除方式因为没有记录事件在追加数据文件中的位置,需要遍历所有的追加数据文件,在没有数据索引的情况下,该过程会很漫长
解决浙这些问题的方式就是合并:将小文件合并成大文件,在合并小文件的过程中过滤掉删除的数据记录,从而提升查询效率。这是目前最有效的方式,通文件合并让计算引擎花费更多时间在读取数据内容,而不是将时间花在频繁地打开文件、查找文件和关闭文件上面。
实现文件合并常见的方式是定时启动Spark 或者 Hadoop离线作业合并小文件,该过程通常较长,具体时长视合并文件的大小而定。企业应用通常启动独立的集群运行,比如基于自建集群服务或者EMR云服务。在实践中,合并小文件会出现很多问题,比较突出的是合并效率低和内存溢出。为什么会有这种问题呢?我们通过流程图来看数据合并的过程:
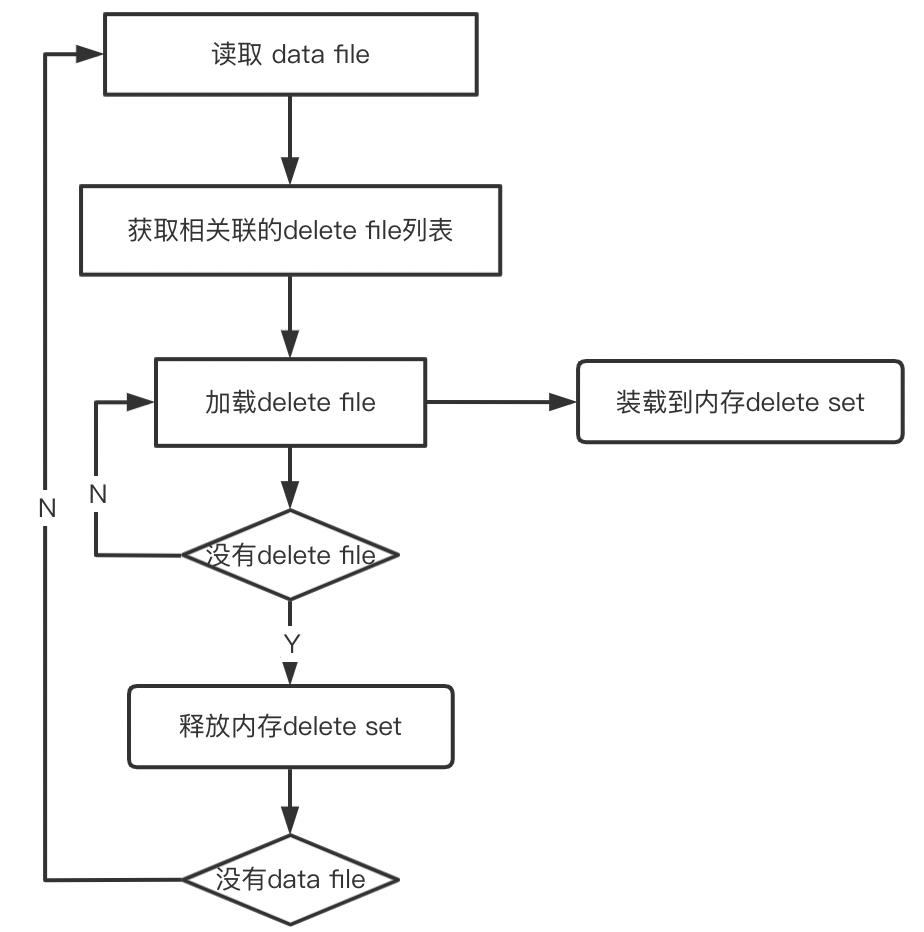
如图所示,合并数据文件时候,首先获取待合并的数据文件列表,然后迭代读取每个数据文件并将相关联的删除数据文件的数据加载到内存中的删除数据集合(delete set)。迭代读取数据文件的过程,类似数据库中一个大表和一个小表进行join的过程,大表是流式表,小表是构建表,遍历数据文件的每一条数据时,在删除文件数据集合中检查是否存在,如果存在,当前数据记录就不会被保留。要知道每个数据文件可能关联多个删除数据文件,这些文件都是压缩存储的,比如parquet或avro,一旦删除数据集加载到内存,只有当数据文件迭代结束之后才会释放,因此很容易导致内存溢出。
另外,当前的Iceberg实现只合并了普通数据文件,对删除数据文件并没有合并,在更新数据频繁的情况下,删除数据文件数量也很可观,不得不对其合并,这个也是在实践中不得不考虑的问题。
这里介绍了在合并文件过程常见的问题,实际上还有很多细节问题需要考虑,这里简单汇总下,做个小结:
确定何时进行文件合并,考虑因素可以是文件数量、文件大小。如果存在分区,还要考虑到分区的变更。
为节约存储空间和费用,确保删除未合并的文件。
尽可能调大合并文件的大小,同时解压后内存能够容得下。
尽可能避免文件合并作业和流作业提交时的锁争用和冲突。
以上是关于数据湖常用查询优化技术的主要内容,如果未能解决你的问题,请参考以下文章