xarray 使用教程 - 未完待续
Posted 可乐要加冰_ice
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了xarray 使用教程 - 未完待续相关的知识,希望对你有一定的参考价值。
目录
12.2 处理xarray中缺测(NaN),将其通过插值补全
前言
之前一直使用netCDF处理.nc格式数据,最近因为插值接触到了xarray,了解了一下发现xarray真的很好用的,个人感觉甩了netCDF几条街(个人观点,不喜勿喷)。有兴趣的可以了解一下
xarray官网API,想详细了解的还是得学官网
下面正式开始讲点xarray中常用的语句
一、安装xarray
conda install xarray
二、创建xarray数据
xarray数据主要包含四个内容,官网介绍如下:
-
values: a numpy.ndarray holding the array’s values -
dims: dimension names for each axis (e.g.,('x', 'y', 'z')) -
coords: a dict-like container of arrays (coordinates) that label each point (e.g., 1-dimensional arrays of numbers, datetime objects or strings) -
attrs: dict to hold arbitrary metadata (attributes)官网
官网提供的两个例子:第一个是普通的数据,第二个是气候数据为例,一个数据集,包含了数据主体(Temperature, Precipitation),维度坐标(latitude,longitude)。
第一个例子:
import numpy as np
import xarray as xr
data = np.random.rand(4, 3)
locs = ["IA", "IL", "IN"]
times = pd.date_range("2000-01-01", periods=4)
foo = xr.DataArray(data, coords=[times, locs], dims=["time", "space"])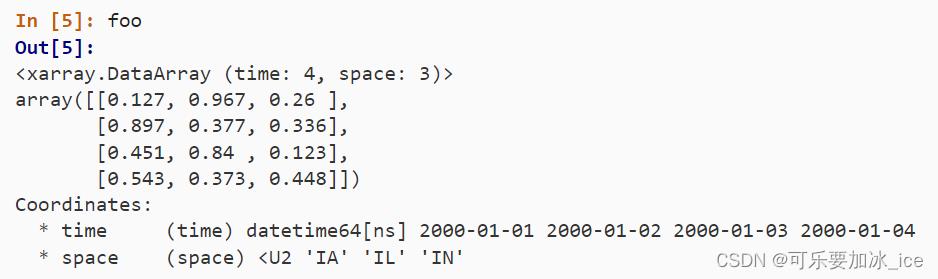
第二个例子:
import numpy as np
import xarray as xr
temp = 15 + 8 * np.random.randn(2, 2, 3)
precip = 10 * np.random.rand(2, 2, 3)
lon = [[-99.83, -99.32], [-99.79, -99.23]]
lat = [[42.25, 42.21], [42.63, 42.59]]
ds = xr.Dataset('temperature': (['x', 'y', 'time'], temp),
'precipitation': (['x', 'y', 'time'], precip),
coords='lon': (['x', 'y'], lon),
'lat': (['x', 'y'], lat),
'time': pd.date_range('2014-09-06', periods=3),
'reference_time': pd.Timestamp('2014-09-05'))三、读取nc数据
通过函数open_dataset `、open_dataarray将nc数据进行读、to_netcdf写
NcDataERA5 = xr.open_dataset('./example.nc')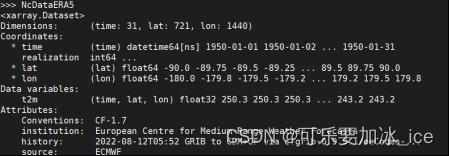
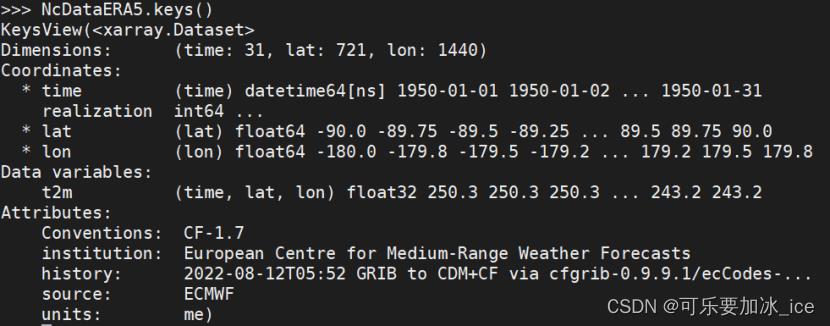
四、看出文件信息
可以直接print或者.key()
五、增加变量属性
一个有用选择是去设置 NcDataERA5.attrs['long_name'] 和 NcDataERA5.attrs['units'],因为 xarray 在绘图时会自动使用他们来进行标记
NcDataERA5. attrs['units'] = 'meters'
六、修改坐标数值:
T2mERA19500101.coords['lon'] = np.arange(0, 359.75, 1)
七、索引和切片
xarray 支持4种索引方式:

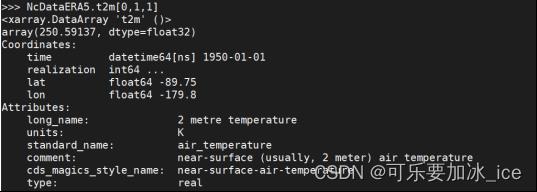
7.1根据位置索引:
NcDataERA5.t2[0,1,1]
7.2根据位置索引:
NcDataERA5.t2m.loc['1950-01-01':'1950-01-03',:,:]
7.3根据维度名索引:
time维度第0个:NcDataERA5.t2m.isel(time = 0)
7.4根据维度名索引:
time维度中是’1950-01-01’的数据:
NcDataERA5.t2m.sel(time = '1950-01-01')
7.5 网上一些补充

八、将变量取array格式
NcDataERA5.t2m.values 或者 NcDataERA5.t2m.data
九、计算
9.1 相加
9.2 平均、求和
NcDataERA5.t2m.mean(axis=0) #[time, lat, lon] 在time维度取平均为[lat, lon], NcDataERA5.t2m.mean() #全部维度取平均
类似的还有求和之类NcDataERA5.t2m.sum(axis=0)
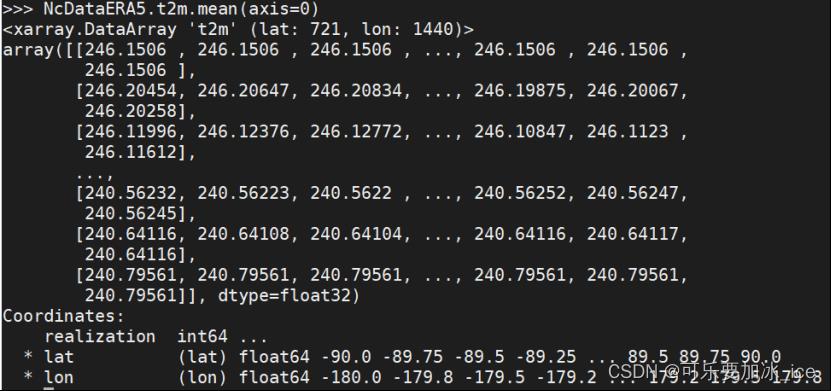
还可以利用.groupby()函数将月份作为键(唯一值)来对原数据进行分类,即把各年某个月的数据放在一个组,用这种方法首先要求time维度格式是datetime,即可以使用time.month,time.year
如果time维度不满足格式,则先用pd.to_datetime转一下格式
DataCollect.coords['time'] = pd.to_datetime(DataCollect.time)
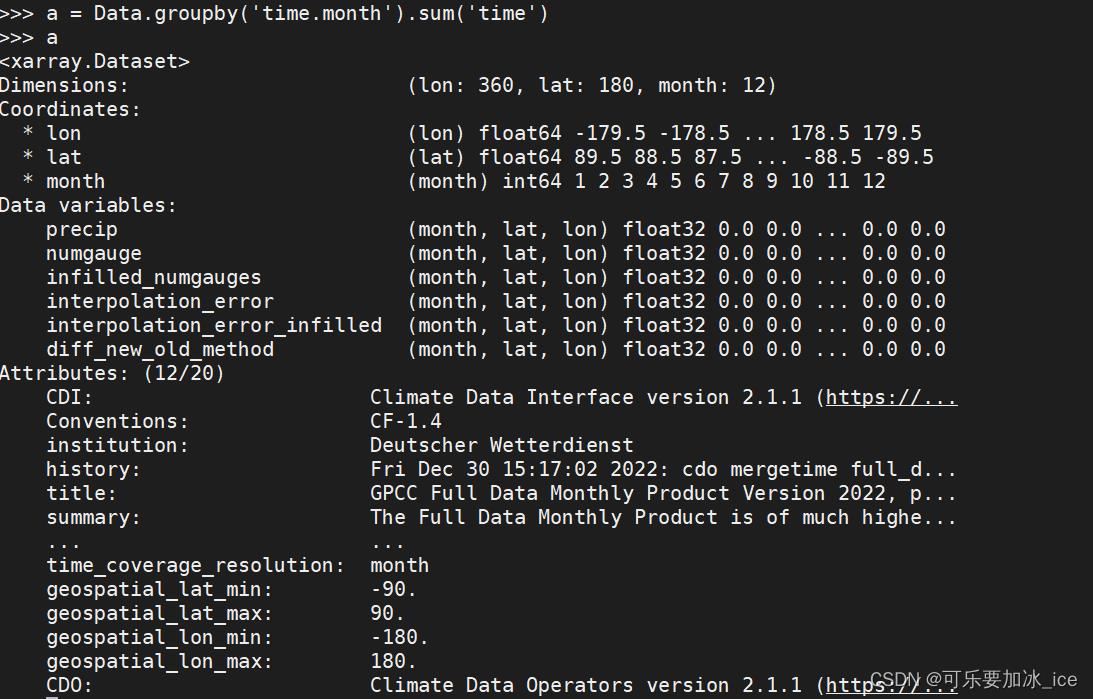
然后使用DataCollect.groupby('time.month').sum('time'):
举个例子:GCPP 降水数据 1951.1-2020.12:

Data.groupby('time.month').sum('time') 之后:
9.3 三角函数、转置
np.sin(NcDataERA5.t2m) 、 NcDataERA5.t2m.T
十、绘图
可以直接.plot()来简单可视化一下,要画漂亮的图还是要自己写代码的
十一、filter_by_attrs:
按要素名字获取某个要素
xarray.Dataset.filter_by_attrs
十二、插值
12.1 将粗分辨率插值到细的分辨率
xarray中插值是真的很方便~入坑第一原因
直接.interp()就行了,简简单单
dsLRlinear2 = ds.ts.interp(lat = LatLR, lon = LonLR, method='linear')
其中,LatLR和LonLR是你想要插值的经纬度数据,1D
method:linear、cubic、nearest可选
12.2 处理xarray中缺测(NaN),将其通过插值补全
对于.nc数据,经常出现的一种情况就是在空间维度上(lats, lons)出现缺测NaN,那通过Xarray读取,该如何通过插值补全这些NaN呢,直接用12.1中.interp是行不通的,因为原数据有测,.interp插值会插值很多缺测出来。解决方法:利用pandas中的.interpolate进行插值
#把xarray.DataArray转成pandas
#DataVariablesEachDay__中有缺测
DataVariablesEachDayPd = DataVariablesEachDay__.to_pandas()
DataVariablesEachDayPd.interpolate(method='linear', limit_direction='both', axis=0, inplace=True)
DataVariablesEachDayPd.interpolate(method='linear', limit_direction='both', axis=1,
inplace=True)
#再将pandas转成xarray.DataArray
DataVariablesEachDay = xr.DataArray(DataVariablesEachDayPd, coords=[LatCESM2, LonCESM2], dims=["lat", "lon"])十三、Bugs 汇总
1.
found the following matches with the input file in xarray's IO backends: ['netcdf4', 'h5netcdf']. But their dependencies may not be installed
这是由于新装的环境只装了xarray,没有安装netcdf4
pip install netcdf4即可
从零开始手写Tomcat的教程---未完待续
从零开始手写Tomcat的教程
手写Tomcat
介绍
本项目主要是手写精简版的tomcat,力争做到不遗不漏
本项目gitee仓库链接如下:https://gitee.com/DaHuYuXiXi/easy-tomcat.git
本篇文章是梳理每一小节的基本脉络,具体每小节的代码实现,自行参考gitee仓库里面的提交记录
第一节 : 一个简单的Web服务器
本节主要重点在于建立基本的socket通信服务,完成最简单的Http通信
本节主要创建了HttpServer,Request和Response三个类,分别为程序入口点,解析请求的对象和负责响应的对象,IO选择的是最简单的BIO实现
注意点
在BIO中,accept()得到的客户端socket中,如果在使用过程中关闭了通道中的输入流或者输出流,会终止当前通道的连接,这点需要特点注意。 还需要注意,数据写完记得flush一下,否则数据会遗留在缓冲区中,导致浏览器接收不到数据
第二节: 一个简单的servlet容器
创建一个Primitvie类,然后将其生产的字节码文件移动到webroot目录下面,因为类加载器加载的class字节码文件
首先,我们指定一个规则,来负责区分静态资源请求和servlet请求,先简化为如下:
静态资源请求:
http://host:port/xx.html
servlet请求:
http://host:port/servlet/servletClass ---全类名
区分部分对应代码如下:
//区分资源类型
if(request.getUri().startsWith("/servlet/"))
//servlet请求资源处理
ServletProcessor1 processor1=new ServletProcessor1();
processor1.process(request,response);
else
//静态资源请求
StaticResourceProcessor processor=new StaticResourceProcessor();
processor.processor(request,response);
下面需要做的是将Request和Response对象分别继承ServletRequest和ServletResponse对象
需要注意的是ServletResponse对象的getWriter方法重写:
/**
* <p>
* PrintWriter构造函数第二个参数为true,
* 表示是否开启自动刷新,传入true表示对println的任何方法都刷新输出,但是print方法不会
* 当然这个bug后续版本会修改
* </p>
* @return
* @throws IOException
*/
@Override
public PrintWriter getWriter() throws IOException
writer = new PrintWriter(bufferedOutputStream, true);
return writer;
创建两个处理器对象,分别处理静态资源和sevlet请求资源
/**
* <p>
* 静态资源处理器
* </p>
* @author 大忽悠
* @create 2022/3/5 23:09
*/
public class StaticResourceProcessor
public void processor(Request request, Response response)
response.sendStaticResource();
/**
* <p>
* servlet请求处理器
* </p>
* @author 大忽悠
* @create 2022/3/5 23:11
*/
public class ServletProcessor1
public void process(Request request, Response response)
try
//1.获取servlet的名字
String uri = request.getUri();
String serveltName = uri.substring(uri.lastIndexOf("/") + 1);
System.out.println("servelt的名字为: "+serveltName);
//2.创建类加载器
URLClassLoader loader=null;
URL[] urls = new URL[1];
URLStreamHandler urlStreamHandler=null;
//类路径
File classPath=new File(Constants.WEB_ROOT);
//资源仓库地址
//file.getCanonicalPath: 返回标准的文件绝对路径
//URL : 参数一: 资源协议--file,https,ftp等 参数二:主机名,http是需要 参数三:资源路径,这里填文件路径
String respository=(new URL("file",null,classPath.getCanonicalPath()+File.separator)).toString();
System.out.println("仓库地址为: "+respository);
// urlStreamHandler通过资源不同的来源来决定处理的逻辑--->不同前缀来识别。比如:"file :"、"http :"、"jar :"
urls[0] = new URL(null, respository, urlStreamHandler);
//加载指定路径下的class
loader=new URLClassLoader(urls);
//负责加载当前访问的servlet
Class myclass=null;
//这里可以直接填类名,而非全类名的条件是,类文件放在java目录下
myclass = loader.loadClass(serveltName);
Servlet servlet=null;
servlet = (Servlet) myclass.newInstance();
//执行指定servlet的方法
servlet.service((ServletRequest) request,(ServletResponse) response);
catch (IOException e)
e.printStackTrace();
catch (ClassNotFoundException e)
e.printStackTrace();
catch (InstantiationException e)
e.printStackTrace();
catch (IllegalAccessException e)
e.printStackTrace();
catch (ServletException e)
e.printStackTrace();
这里提两点:
- 如果一个URL以"/"结尾,则表明它指向的是一个目录,否则,URL默认指向一个JAR文件,根据需要载入器会下载并打开这个JAR文件
- 在servlet容器中,类加载器查询servlet类的目录称为仓库
这里对URLClassLoader不清楚的,自己去查资料
到此为止,大致思路和代码就完工了,但是完美了吗? 不不不,还有很大的问题
public void process(Request request, Response response)
.....
//执行指定servlet的方法
servlet.service((ServletRequest) request,(ServletResponse) response);
有没有看出来问题,直接将Request对象和Response传给用户,这意味着,用户可以调用Request的parse方法和Response的sendStaticResource方法。
显然,这样是非常不安全的,但是还不能将parse方法和sendStaticResource方法设置为私有的,因为其他类还需要调用。
下面有两种解决方法:
- Request和Response类都设置为默认的访问修饰符,这样就不能从他们所在包外访问了
- 外观模式
这里主要讲一下外观模式的使用,因为第一种方法存在局限性
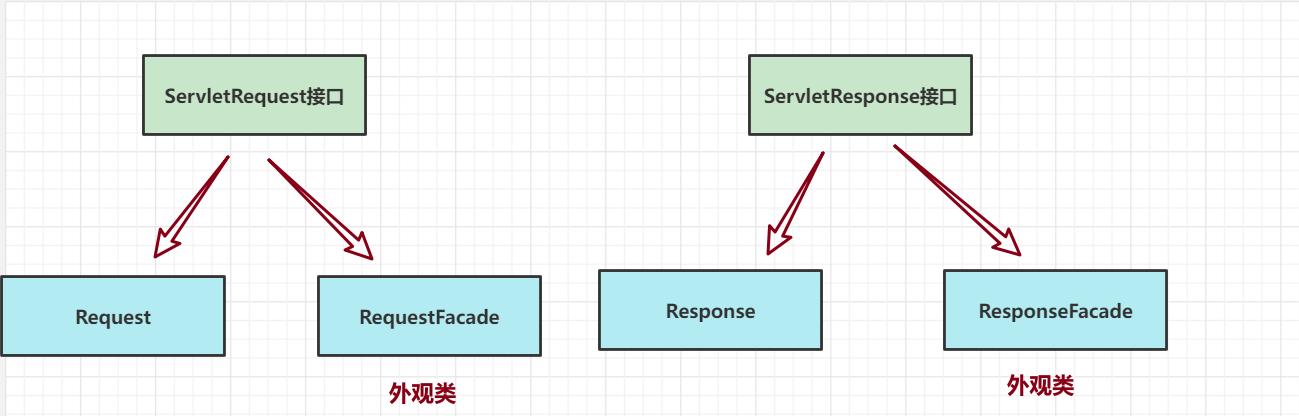
外观模式在此处使用的作用不是屏蔽系统使用的复杂性,主要是为了向用户隐蔽一些内部方法
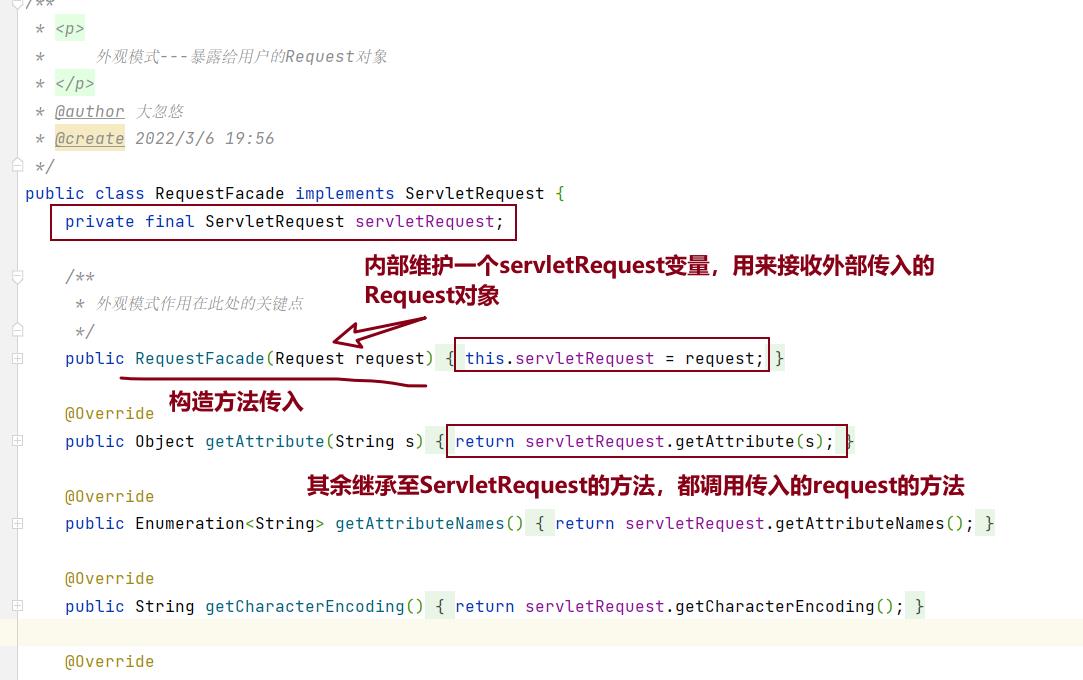
虽然此时程序员仍然可以将servletRequest对象向下转型RequestFacade对象,但是只能访问ServletRequest对象中提供的方法,保证了Request对象中的parse方法的安全性。
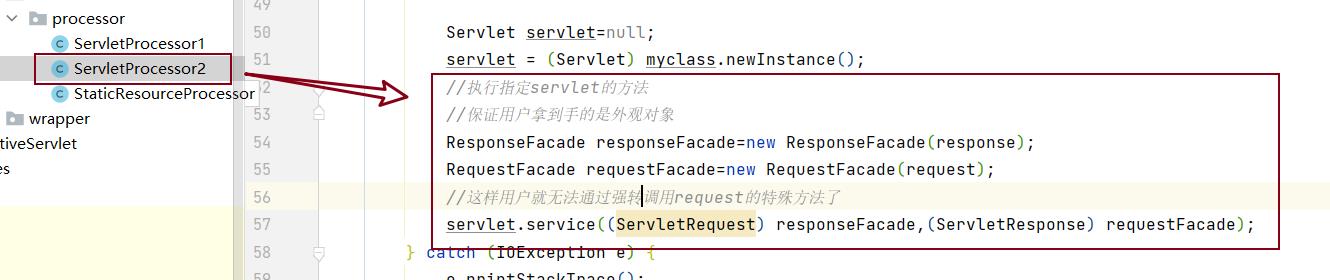
在将Request和Response对象传给用户的时候,将其转换为外观对象,传入。
争取每天一节的更新速度
以上是关于xarray 使用教程 - 未完待续的主要内容,如果未能解决你的问题,请参考以下文章