caffe模型训练与使用(windows平台)
Posted @半岛铁盒@
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了caffe模型训练与使用(windows平台)相关的知识,希望对你有一定的参考价值。
前言
本文训练模型是在 windows 系统上完成的,在训练模型之前,需要在自己的设备上编译好 caffe 。
windows 下编译 caffe 的教程:https://blog.csdn.net/apple_54470279/article/details/124993901
本文做好的项目已打包,以供参考,下载地址:百度网盘下载
为了方便访问文件,建议先建一个文件夹,用来存放本次训练过程中的所有文件。比如,我在桌面上新建了一个名为 caffe-flower 的文件夹,因此在本文中,我的所有文件都是在这个文件夹中进行编写的。
我在训练的过程中参考了很多文章,也遇到了很多问题,但大部分的问题都是因为路径使用不正确而导致的。所以,在学习本文的过程中,如果你也遇到了奇奇怪怪的问题,可以从修改路径的方面入手,进行调整。也可以下载本文现成的项目,看看目录结构是如何安排的。
获取数据集
在训练模型之前,需要准备好相应的数据集,从网上下载 100 张玫瑰花图片和 100 张牵牛花图片,分别保存在 rose 文件夹和 morning glory 文件夹中,当然,文件夹可以根据自己喜好命名。
对下载的图片进行重命名,可以通过 Python 来完成,新建 file_rename.py 文件,复制以下代码:
'''
重命名图片
'''
import os
# 存放两种图片文件夹的路径(更换为自己的路径)
path1 = r"C:\\Users\\CoolTea\\Desktop\\caffe-flower\\rose"
path2 = r"C:\\Users\\CoolTea\\Desktop\\caffe-flower\\morning glory"
# 对 path1 中的图片重命名
img_list = os.listdir(path1)
i = 1
for item in img_list:
os.rename(path1+"\\\\"+item, path1+"\\\\"+'r:0>4.png'.format(i))
i += 1
# 对 path2 中的图片重命名
img_list = os.listdir(path2)
i = 1
for item in img_list:
os.rename(path2+"\\\\"+item, path2+"\\\\"+'m:0>4.png'.format(i))
i += 1
print("重命名完成!")
运行代码,重命名完成后,在当前目录下新建一个 DataSet 文件夹,该文件夹用来存放数据集,在 DataSet 文件夹下新建 train 和 test 文件夹,如下图所示:
train 中存放的是训练集,test 中存放的是测试集。从两种花的中各选取 80 张图片存入 train 文件夹中,再将剩下的图片存入 test 文件夹中,保持训练集与测试集图片的比例为 8:2。
至此,数据集创建完毕!
生成图片标签
这一步可以通过 Python 代码来完成,在当前目录下新建 create_label.py 文件,复制以下代码:
'''
生成图片标签
'''
import os
import re
# 存放数据集的文件夹路径
path = r"C:\\Users\\CoolTea\\Desktop\\caffe-flower\\DataSet"
# 生成训练集文件标签
img_list = os.listdir(path + r"\\train") # 获取训练集图片的名称
print("共获取 张训练图片".format(len(img_list)))
with open(path + r"\\train.txt", "w") as f:
for item in img_list:
if re.match(r'r+', item):
f.writelines(" \\n".format(item, 0)) # 玫瑰花图片标签为 0
if re.match(r'm+', item):
f.writelines(" \\n".format(item, 1)) # 牵牛花图片标签为 1
print("已生成训练集文件标签。")
# 生成测试集文件标签
img_list = os.listdir(path + r"\\test") # 获取测试图片的名称
print("共获取 张测试图片".format(len(img_list)))
with open(path + r"\\test.txt", "w") as f:
for item in img_list:
if re.match(r'r+', item):
f.writelines(" \\n".format(item, 0)) # 玫瑰花图片标签为 0
if re.match(r'm+', item):
f.writelines(" \\n".format(item, 1)) # 牵牛花图片标签为 1
print("已生成测试集文件标签。")
运行后,数据集文件夹内会生成一个与 train 、 test 文件夹同名的 【.txt】 文件,如下图所示:
【.txt】文件的内容大致如下:
m0066.png 1
m0067.png 1
m0068.png 1
m0069.png 1
m0070.png 1
r0001.png 0
r0002.png 0
r0003.png 0
r0004.png 0
将图片转换为 lmdb 格式
这一步可以通过 caffe 自带的 convert_imageset.exe 程序来完成,该程序的路径:D:\\caffe-windows\\scripts\\build\\tools\\Release
在当前目录下新建 tolmdb.bat 文件,用记事本或者编辑器打开,写入以下内容:
:: 需要修改的内容以及相关解释
:: D:\\caffe-windows\\scripts\\build\\tools\\Release\\convert_imageset.exe
:: 改为自己本地 convert_imageset.exe 程序的路径
:: --resize_height=100 --resize_width=100 设置图片的大小
:: --shuffle 打乱图片顺序
:: --backend=lmdb 转换为lmdb格式
:: C:\\Users\\CoolTea\\Desktop\\caffe-flower\\DataSet\\train\\
:: 改为自己本地训练集图片的路径(测试集同理)
:: C:\\Users\\CoolTea\\Desktop\\caffe-flower\\DataSet\\train.txt
:: 改为自己本地训练集图片标签文件的路径(测试集同理)
:: C:\\Users\\CoolTea\\Desktop\\caffe-flower\\DataSet\\train_leveldb
:: 在训练集的同级目录下生成lmdb文件(测试集同理)
:: 训练集
D:\\caffe-windows\\scripts\\build\\tools\\Release\\convert_imageset.exe --resize_height=100 --resize_width=100 --shuffle --backend=lmdb C:\\Users\\CoolTea\\Desktop\\caffe-flower\\DataSet\\train\\ C:\\Users\\CoolTea\\Desktop\\caffe-flower\\DataSet\\train.txt C:\\Users\\CoolTea\\Desktop\\caffe-flower\\DataSet\\train_leveldb
:: 测试集
D:\\caffe-windows\\scripts\\build\\tools\\Release\\convert_imageset.exe --resize_height=100 --resize_width=100 --shuffle --backend=lmdb C:\\Users\\CoolTea\\Desktop\\caffe-flower\\DataSet\\test\\ C:\\Users\\CoolTea\\Desktop\\caffe-flower\\DataSet\\test.txt C:\\Users\\CoolTea\\Desktop\\caffe-flower\\DataSet\\test_leveldb
pause
保存后,双击运行,数据集目录下生成两个文件夹,如下图所示:
这一步骤可能会遇到的问题:
1、Check failed: _mkdir(source.c_str()) == 0 (-1 vs. 0) mkdir
解决办法:删除目录下原有的
test_leveldb和train_leveldb文件夹后重新运行脚本。
生成均值文件
这一步可以通过 caffe 自带的 compute_image_mean.exe 程序来完成,该程序的位置:D:\\caffe-windows\\scripts\\build\\tools\\Release
在当前目录下新建 tomean.bat 文件,用记事本或者编辑器打开,写入以下内容:
:: 需要修改的内容以及相关解释
:: D:\\caffe-windows\\scripts\\build\\tools\\Release\\compute_image_mean.exe
:: 改为自己本地 compute_image_mean.exe 程序的路径
:: C:\\Users\\CoolTea\\Desktop\\caffe-flower\\DataSet\\train_leveldb
:: 改为自己本地训练集文件的路径
:: C:\\Users\\CoolTea\\Desktop\\caffe-flower\\DataSet\\mean.binaryproto
:: 在数据集目录下生成均值文件
D:\\caffe-windows\\scripts\\build\\tools\\Release\\compute_image_mean.exe C:\\Users\\CoolTea\\Desktop\\caffe-flower\\DataSet\\train_leveldb C:\\Users\\CoolTea\\Desktop\\caffe-flower\\DataSet\\mean.binaryproto
pause
双击运行该脚本,会在数据集文件夹内生成 mean.binaryproto 文件,如下图所示:
配置 train_val.prototxt 文件
本文采用 CaffeNet 网络结构来训练模型,该网络结构是 Caffe 自带的,具体路径如下(根据自己本地 caffe-windows 文件的位置寻找):
D:\\caffe-windows\\models\\bvlc_reference_caffenet\\
复制其中的 deploy.prototxt、solver.prototxt、train_val.prototxt 三个文件到 DataSet 文件夹内,如下图所示:
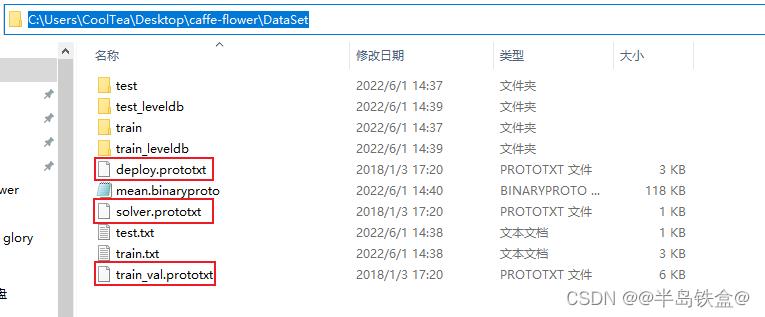
用记事本或者其他编辑器打开并修改 train_val.prototxt 文件,一共需要修改 5 处,具体修改内容如下:
# 第一处(11行左右):
transform_param
mirror: true
# 裁剪图片尺寸
crop_size: 100
# 下面的路径改为自己均值文件的路径
mean_file: "C:/Users/CoolTea/Desktop/caffe-flower/DataSet/mean.binaryproto"
# 第二处(27行左右):
data_param
# 下面的路径改为自己 train_leveldb 文件夹的路径
source: "C:/Users/CoolTea/Desktop/caffe-flower/DataSet/train_leveldb"
# 样本数量(不大于训练集图片)
batch_size: 80
backend: LMDB
# 第三处(44行左右):
transform_param
mirror: false
# 裁剪图片尺寸
crop_size: 100
# 下面的路径改为自己均值文件的路径
mean_file: "C:/Users/CoolTea/Desktop/caffe-flower/DataSet/mean.binaryproto"
# 第四处(60行左右):
data_param
# 下面的路径改为自己 test_leveldb 文件夹的路径
source: "C:/Users/CoolTea/Desktop/caffe-flower/DataSet/test_leveldb"
# 样本数量(不大于测试集图片)
batch_size: 20
backend: LMDB
# 第五处(385行左右):
inner_product_param
# 我们分了两类,这里的数字最好大于自己的分类
num_output: 3
weight_filler
type: "gaussian"
std: 0.01
bias_filler
type: "constant"
value: 0
crop_size:
在 caffe 中,如果定义了 crop_size,那么在train时会对大于 crop_size 的图片进行随机裁剪,而在test时只是截取中间部分。
batch_size:
若 batch_size= m(训练集样本数量),相当于直接抓取整个数据集,训练时间长。但梯度准确,不适用于大样本训练,只适用于小样本训练,但小样本训练一般会导致过拟合现象,因此不建议如此设置。
配置 solver.prototxt 文件
修改数据集目录下的 solver.prototxt 文件,该文件为超参数文件,如下图所示:
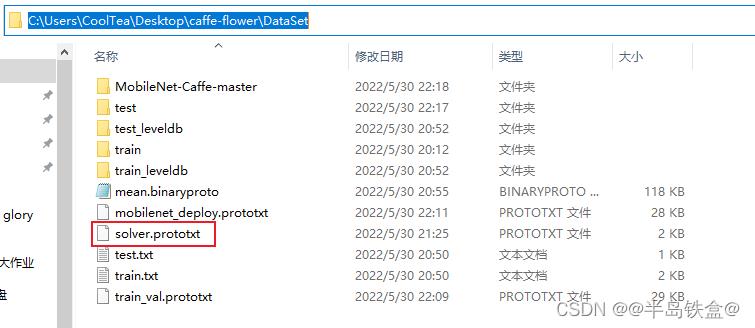
用记事本或者编辑器打开该文件,并写入以下内容(替换原始数据即可):
# 改为自己本地 train_val.prototxt 文件的路径
net: "C:/Users/CoolTea/Desktop/caffe-flower/DataSet/train_val.prototxt"
# 测试数据的迭代次数,根据测试图片的数量决定,本文测试数据比较少,可以调小数值
test_iter: 2
# 测试间隔,每训练多少次进行一次测试。
test_interval: 100
# 这个参数代表的是此网络最开始的学习速率
base_lr: 0.01
# 学习率调整策略
lr_policy: "step"
# 这个参数就是和学习率相关的
gamma: 0.1
# 这个参数表示我们应该多长时间(在某个迭代次数)进入下一个训练“步骤”。该值是一个正整数。
stepsize: 100
# 训练多少次对在屏幕上显示一次
display: 20
# 最大迭代次数,这个数值告诉网络何时停止训练,太小会达不到收敛,太大会导致震荡,为正整数。
max_iter: 300
# 上一次梯度更新的权重
momentum: 0.9
# 权重衰减项,用于防止过拟合。
weight_decay: 0.0005
# 训练多少次后保存一次model和solverstate
snapshot: 100
# 在数据集下新建 model 文件夹,用来存放模型
snapshot_prefix: "C:/Users/CoolTea/Desktop/caffe-flower/DataSet/models/"
# 使用 CPU 还是 GPU 训练
solver_mode: CPU
关于配置参数的详细解释,请跳转至本文最后的参考文章小节,选择第四篇文章进行跳转。
训练模型
创建训练脚本文件 train.bat ,写入以下内容:
:: D:\\caffe-windows\\scripts\\build\\tools\\Release\\caffe.exe
:: 改为本地 caffe.exe 文件所在路径
:: train -solver=C:\\Users\\CoolTea\\Desktop\\caffe-flower\\DataSet\\solver.prototxt
:: 改为本地 solver.prototxt 文件所在路径
D:\\caffe-windows\\scripts\\build\\tools\\Release\\caffe.exe train -solver=C:\\Users\\CoolTea\\Desktop\\caffe-flower\\DataSet\\solver.prototxt
pause
保存后双击运行,等待训练完成即可,训练过程会花费一定的时间,最终结果如下:
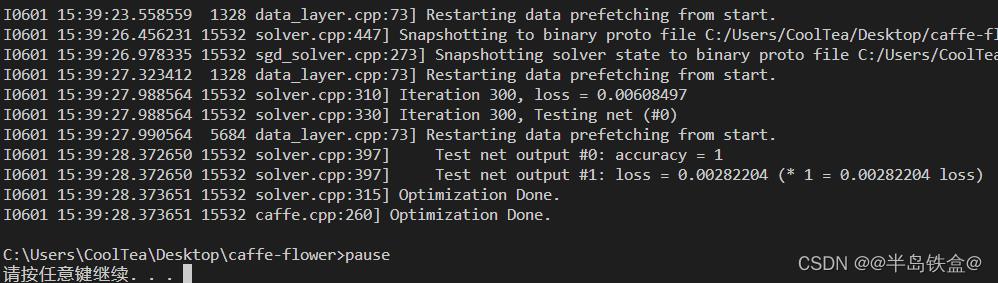
accuracy 表示训练的准确率,这里的值为 1 代表准确率是 100%
这一步骤可能会遇到的问题:
1、Error parsing text-format caffe.SolverParameter: 2:10: Invalid escape sequence in string literal.
解决办法:将 prototxt 配置文件中的
\\符号全部换为/,caffe 对该符号的使用要求比较严格。2、accuracy 值太低
解决办法:修改 solver.prototxt(超参数文件)中的值,重新训练,调参这一块比较麻烦,可以参考其他文章。如果只是训练 100 张图片,我的这个参数可以直接使用。
3、Cannot write to snapshot prefix 'C:/Users/Admin/Desktop/caffe-animal/DataSet/models/ '.
解决办法:在 DataSet 目录下新建 models 文件夹后重新执行脚本。
使用模型
模型训练完成后,接下来学习如何使用我们训练好的模型,训练好的模型保存在之前新建的 models 文件夹中,我们会用到训练次数最大的模型,本文最大训练了300次,模型后缀名为 .caffemodel。
在根目录下新建一个 test_res 文件夹,如下图所示:
在 test_res 文件夹内新建一个文本文件 labels.txt ,向该文件写入识别标签,如下图所示:

在开始的地方,我们将玫瑰花的标签设置为 0,将牵牛花的标签设置为 1,这里的识别标签与之对应!
使用记事本或者编辑器打开 deploy.prototxt 文件,并对该文件进行两处修改:
# 第一处(8行左右)
layer
name: "data"
type: "Input"
top: "data"
# 对以下内容进行修改:
input_param shape: dim: 1 dim: 3 dim: 100 dim: 100
# 第二处(209行左右)
layer
name: "fc8"
type: "InnerProduct"
bottom: "fc7"
top: "fc8"
inner_product_param
# 改为 train_val.prototxt 文件最后 num_output 相同的值。
num_output: 3
dim: 1
对待识别样本进行数据增广的数量,可自行定义。一般会进行 5 次 crop ,之后分别 flip 。如果该值为 10 则表示一个样本会变成10个,之后输入到网络进行识别。如果不进行数据增广,可以设置成 1 。
dim: 3
通道数,表示RGB三个通道
dim: 100
图像的长和宽,通过 crop_size 获取,本文中我们定义为 100 。
我们使用 Python 接口来识别图片,这里需要用到【均值文件】,但需要将 .binaryproto 格式的均值文件转换为 .npy 格式,以便 Python 接口使用。在 test_res 目录下新建 tonpy.py 文件,复制以下代码:
import caffe
import numpy as np
# .binaryproto 格式均值文件路径
path1 = r'C:\\Users\\CoolTea\\Desktop\\caffe-flower\\DataSet\\mean.binaryproto'
# .npy 格式均值文件的生成路径
path2 = r'C:\\Users\\CoolTea\\Desktop\\caffe-flower\\DataSet\\mean.npy'
blob = caffe.proto.caffe_pb2.BlobProto()
data = open(path1, 'rb' ).read()
blob.ParseFromString(data)
array = np.array(caffe.io.blobproto_to_array(blob))
mean_npy = array[0]
np.save(path2 ,mean_npy)
print("转换完成!")
转换完成后,会在数据集目录下生成 mean.npy 文件,如下图所示:
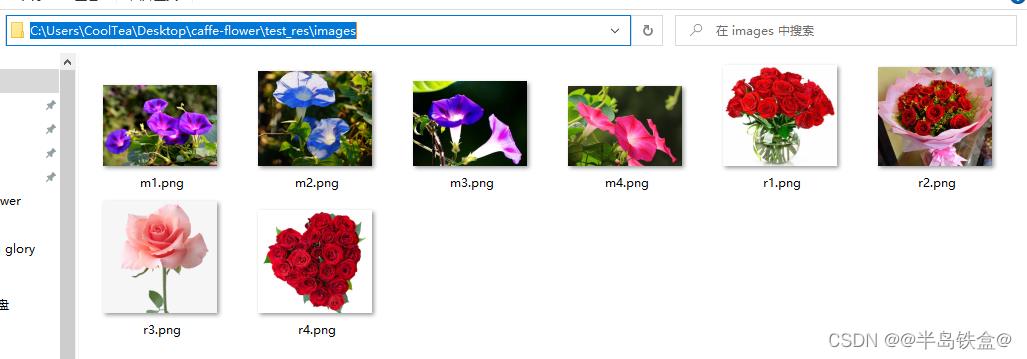
接下来准备几张高难度的图片用于识别,在 test_res 文件夹下新建 images 文件夹,下载几张玫瑰花和牵牛花的图片,标识一下图片名,如下图所示:
编写 Python 识别代码,在 test_res 文件夹下新建 distinguish.py 文件,复制以下代码:
import os
import caffe
import numpy as np
# deploy 文件所在目录(数据集目录下)
deploy_path = r"C:\\Users\\CoolTea\\Desktop\\caffe-flower\\DataSet\\deploy.prototxt"
# 训练好的模型所在目录(选数字最大的那个,后缀 .caffemodel)
model_path = r"C:\\Users\\CoolTea\\Desktop\\caffe-flower\\DataSet\\models\\_iter_300.caffemodel"
# 识别标签文件所在路径(test 文件夹下)
labels_path = r"C:\\Users\\CoolTea\\Desktop\\caffe-flower\\test_res\\labels.txt"
# npy 格式均值文件所在位置
npy_path = r"C:\\Users\\CoolTea\\Desktop\\caffe-flower\\DataSet\\mean.npy"
# 测试图片所在目录
images_path = r"C:\\Users\\CoolTea\\Desktop\\caffe-flower\\test_res\\images"
# 加载 model 和 network
net = caffe.Net(deploy_path, model_path, caffe.TEST)
# 设定图片的 shape 格式 (1,3,28,28)
transformer = caffe.io.Transformer('data': net.blobs['data'].data.shape)
# 改变维度的顺序,由原始图片 (28,28,3) 变为 (3,28,28)
transformer.set_transpose('data', (2,0,1))
# 减去均值
transformer.set_mean('data', np.load(npy_path).mean(1).mean(1))
# 缩放到 (0, 100) 之间
transformer.set_raw_scale('data', 100)
# 交换通道,将图片由 RGB 变为 BGR
transformer.set_channel_swap('data', (2,1,0))
# 获取所有图片名,存入列表
image_list = os.listdir(images_path)
# 获取标签
lable = []
with open(labels_path, 'r') as f:
lines = f.readlines()
for item in lines:
lable.append(item.replace('\\n', '').split(' '))
# 创建空列表存放每个图片的预测值
value_pre = []
for item in image_list:
img = caffe.io.load_image(images_path+"\\\\"+item)
net.blobs['data'].data[...] = transformer.preprocess('data', img)
out = net.forward()
prob = net.blobs['prob'].data[0].flatten()
order = prob.argsort()[-1]
for item in lable:
if str(order) in item:
value_pre.append(item[1])
# 创建空列表存放每个图片的真实标记
train = []
for item in image_list:
train.append(os.path.basename(item))
for i in range(0,len(value_pre)):
print(" ===> ".format(train[i] , value_pre[i]))
运行代码,结果如下:
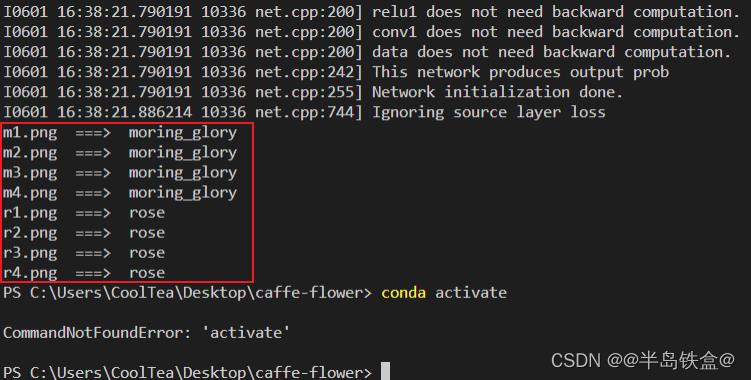
可以看到,准确率高达 100% !
参考文章
caffe训练与测试全过程(附代码)(超详细)_m.n.m的博客-CSDN博客_caffe训练
Caffe学习系列(12):训练和测试自己的图片–linux平台 - leoking01 - 博客园 (cnblogs.com)
深度学习caffe平台–train_val.prototxt文件中数据层及参数详解_白话先生的博客-CSDN博客
caffe基础篇—solver及其配置_poppy_MCT的博客-CSDN博客
以上是关于caffe模型训练与使用(windows平台)的主要内容,如果未能解决你的问题,请参考以下文章
从零到一:caffe-windows(CPU)配置与利用mnist数据集训练第一个caffemodel
工具 | Facebook 开源产业级深度学习框架 Caffe2,带来跨平台机器学习工具