特定场景查询需求难题,GaussDB(for Influx)用hint查询“统统拿下”
Posted 华为云开发者联盟
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了特定场景查询需求难题,GaussDB(for Influx)用hint查询“统统拿下”相关的知识,希望对你有一定的参考价值。
摘要:GaussDB(for Influx)通过提供hint功能,在单时间线的查询场景下,性能有大幅度的提升,能有效满足客户某些特定场景的查询需求。
本文分享自华为云社区《华为云GaussDB(for Influx)揭秘第十期:最佳实践之hint查询》,作者:高斯Influx官方博客。
“怎么感觉查询越来越慢了?”随着业务数据量的不断增大,很多客户都反馈同样的查询语句变得越来越慢。接到客户的反馈后,我们分析了客户的查询执行各个阶段的耗时,发现随着数据量的增加,耗在倒排索引阶段的时间越来越长,那么倒排索引到底是干什么用的呢?能不能跳过倒排索引呢?
倒排索引,顾名思义,是一种索引结构,该索引避免了多维查询时进行大量的数据扫描。其本身就是用于提高查询性能的,显然不能简单地跳过倒排索引。但是随着数据量的不断增大,确实引起了查询的时延变大。那么倒排索引的原理是什么?适合于哪种业务场景?有没有可能跳过倒排索引,来进一步降低查询时延呢?本文基于GaussDB(for Influx)的实现,给您一一解答上述问题。
1. 为什么要使用倒排索引?
用以下数据作为示例进行说明,其中
Tag:region,service,host;
Field:cpu,mem;
数据源(SeriesKey):region+service+host;
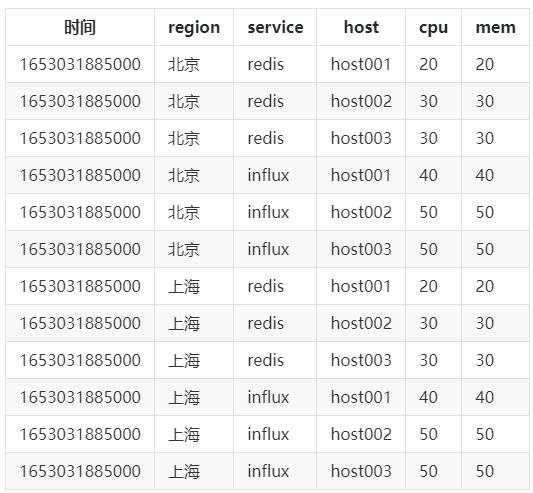
一般涉及的查询有两种:
1)要查询某个数据源在某个时间点的cpu使用情况,例如:
select max(cpu) from mst where region=’北京’ and service=’influx’ and host=’host001’ and time>now()-30s所有的tag都指定了相应的值。
2)给定部分维度,查询某些信息:例如要查询北京(region)的Influx(service)服务的cpu使用情况:
select max(cpu) from mst where region=’北京’ and service=’influx’ and time>now()-30s只指定了部分tag值。
对于第一种查询方案,可以直接根据tag值来确定数据源,但是对于第二种场景,查询没有直接给出具体的数据源,仅指定了两个维度(region和service)以及查询的指标cpu,这种查询就需要根据部分维度组合(region=北京,service=influx)找到所有对应的数据源,例如在数据中北京的Influx服务有3台主机(host001, host002, host003),就需要查找到这3台主机数据源,这就需要倒排索引,否则就需要进行大量的数据扫描。
有了倒排索引,Influx的查询能力得到了很大的提升,但是随着数据量的不断增长,消耗在倒排索引的时间也越来越长;倒排索引的作用就是通过部分维度来找到对应所有的数据源,那么如果我们可以通过其他方式更快地找到数据源,就可以跳过倒排索引了。数据源是由tag set的value组成的,即由region,service,host三个tag的值组成,例如region=“北京”,service=“influx”,host=“host001”三个tag值就组成一个数据源。那么当业务要查询的查询里带了所有tag的值时,我们就可以根据查询语句来确定数据源,例如:
select max(cpu) from mst where region=’北京’ and service=’influx’ and host=’host001’ and time>now()-30s该语句查询过去30s内北京region,Influx服务,host001主机的CPU的最大值。上面的查询带了需要确定数据源的所有tag的值,因此我们在这种查询中就可以跳过倒排索引的阶段,类似的查询我们也叫做单时间线查询。
2. GaussDB(for Influx)的实现方案
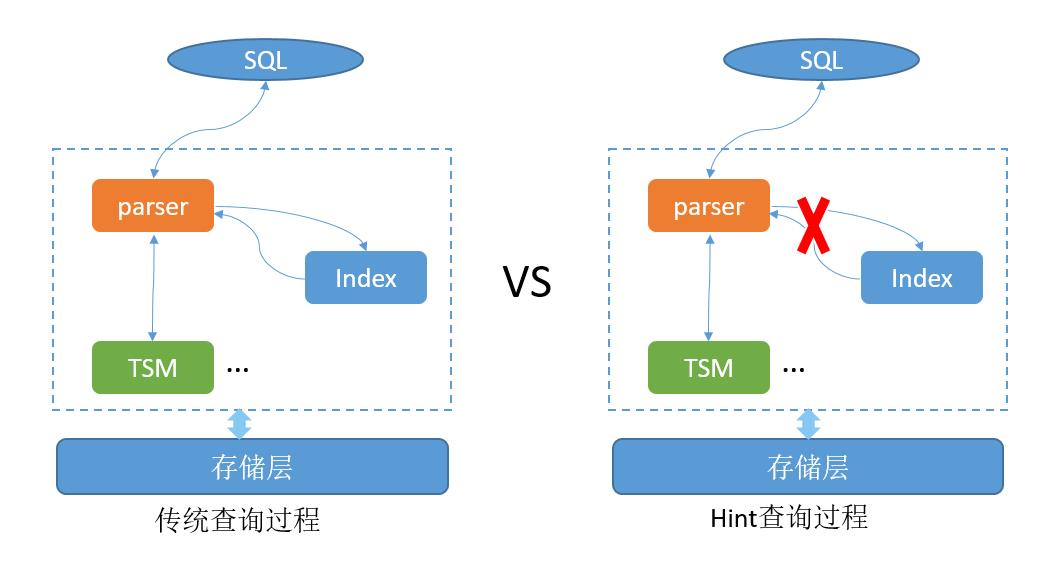
上一章节讲到,如果业务的查询是单时间线查询,我们就可以根据查询语句来确认数据源,而不用再去倒排索引中找。基于这个思路,GaussDB(for Influx)实现了hint特性,hint特性允许客户指定查询跳过倒排索引模块,直接去查找数据,从而进一步提高查询性能。
GaussDB(for Influx)通过定义特殊的hint语法来识别查询语句是否走倒排索引,系统解析业务查询语句时,如果识别到查询带有hint语法,就会跳过倒排索引查找的步骤,直接根据查询语句中tagset信息,找到数据源,去存储层查找对应的数据,其逻辑对比如下图:
3. Hint查询的性能
针对单时间线查询的场景下,我们测试了使用hint功能和不适用hint功能之间的性能。
测试条件为:300万时间线,单时间线查询;执行查询1000次取平均时延。下图为hint查询和非hint查询的测试结果对比:
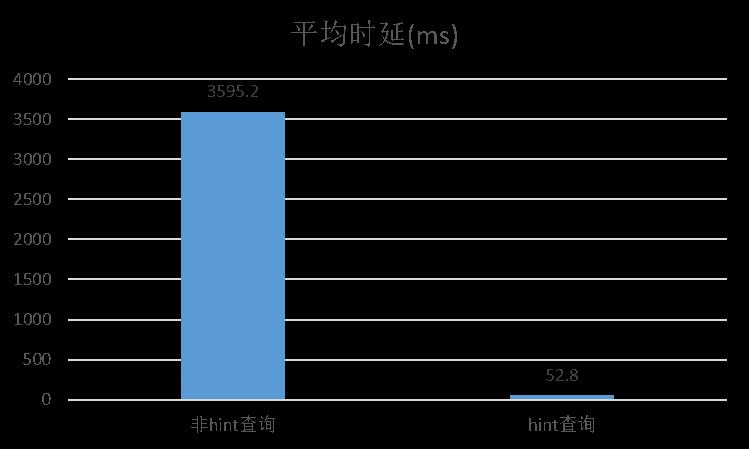
从图中可以看出,在相同的查询语句和测试环境下,hint查询时延明显优于非hint查询。
4. Hint查询的使用
使用hint查询的方法也很简单,业务只需要少量的改动即可,在查询时添加hint查询标识/*+ full_series */。例如,常规查询语句为:
select max(cpu) from mst where region=’北京’ and service=’influx’ and host=’host001’ and time>now()-30s改为用hint的方式,查询语句为:
select /*+ full_series */ max(cpu) from mst where region=’北京’ and service=’influx’ and host=’host001’ and time>now()-30s在使用hint方式查询时,一定要确定是单时间线的查询,否则可能会出现查不出来数据的问题。
5. 总结
GaussDB(for Influx)通过提供hint功能,在单时间线的查询场景下,性能有大幅度的提升,能有效满足客户某些特定场景的查询需求。
除了以上优势外,GaussDB(for Influx)还在集群化、冷热分级存储、高可用方面也做了深度优化,能更好地满足时序应用的各种场景。
6. 结束
本文作者:华为 云数据库创新Lab & 华为云时空数据库团队
更多技术文章,关注GaussDB(for Influx)官方博客:
高斯Influx官方博客的博客_云社区-华为云
Lab官网:云数据库创新Lab-主页-华为云
产品首页:时序数据库_GaussDB for Influx_数据库-华为云
华为伙伴暨开发者大会2022火热来袭,重磅内容不容错过!
【精彩活动】
勇往直前·做全能开发者→12场技术直播前瞻,8大技术宝典高能输出,还有代码密室、知识竞赛等多轮神秘任务等你来挑战。即刻闯关,开启终极大奖!点击踏上全能开发者晋级之路吧!
【技术专题】
未来已来,2022技术探秘→华为各领域的前沿技术、重磅开源项目、创新的应用实践,站在智能世界的入口,探索未来如何照进现实,干货满满点击了解
以上是关于特定场景查询需求难题,GaussDB(for Influx)用hint查询“统统拿下”的主要内容,如果未能解决你的问题,请参考以下文章
华为云PB级数据库GaussDB(for Redis)揭秘第13期:如何搞定推荐系统存储难题
复杂查询so easy ,GaussDB(for Cassandra)推Lucene引擎全新解决方案