春节不打烊,这份安全应急指南请收好!
Posted 顶象技术
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了春节不打烊,这份安全应急指南请收好!相关的知识,希望对你有一定的参考价值。
春节作为中国的传统节日,不仅是各个企业的营销重点周期,也是黑灰产高发节点之一。尤其是伴随着互联网的兴起,春节红包逐渐成为主流营销节目,从支付宝的集五福到各种各样的红包活动,不断翻新的营销花样让黑灰产们赚的盆满钵满。
以2022年春节档营销活动为例。
2022年各大平台公布的春节红包总金额超过80亿元。据媒体报道,2022年有黑灰产行业人士在春节红包活动中,狠狠薅了13万元“羊毛”,这相当于上班族一年的工资,而和他一样的同行并不在少数,少则几千元,多则超过十万元。
此外,根据顶象防御云业务安全情报中心数据显示,截止2022年12月,通过对线上风险识别拦截的数据进行分析发现,薅羊毛类风险占比最高,占59.2%。其中,在双11和618等热点时间节点上流量最高,相应的整体11月和6月的请求占比最高,11月占27.54%,6月占16.73%。
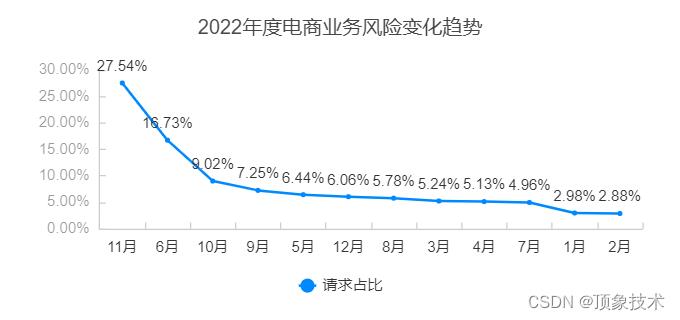
从上述数据中可以看出,节假日是黑灰产的重要“捞金”时刻。
与此同时,随着疫情政策的全面放开,今年春节团圆一定是最大的主题,此时,企业的无人值守便成为了安全隐患之一。
新促销带来新风险。春节假日,电商平台会有很多新优惠措施,如从支付宝的“集五福”到和央视春晚合作派发红包,,再到各种简单粗暴的红包雨、摇一摇抽奖活动,互联网巨头这些年出尽浑身解数争夺节日流量。这也意味着新的促销将会带来新的风险,黑灰产会使用新攻击手段牟利。
很多攻击手段平台可能第一次遭遇,无法及时发现。很多严控规则下线,安全体系防控度降低。相较于网购季,春节假期相较于传统节日相较于购物旺季,业务量会大幅缩减,因此电商平台很多严格安全规则会下线,很多严苛的安全手段会停止,业务安全体系的防控性会降低。
运营人员大幅减少,整体运营能力降低。作为疫情后首个春节,回家团圆会成为打工人第一选择。电商平台安全运营人员会减少,软件自动化将大量替代。然而黑灰产的攻击手段愈加复杂,很多风险欺诈手段软件无法有效辨别。
春节期间,企业可能面临哪些风险?
那么,春节期间,黑灰产会给企业带来哪些风险呢?
近几年,春节红包大战已经成为移动互联时代的新民俗。从支付宝的“集五福”到抖音的集福气卡,再到各种简单粗暴的红包雨、摇一摇抽奖活动、盲盒、逛庙会抽红包等等新颖的红包抽奖活动,不断翻新的营销花样成为各大平台抢夺流量的重要手段。从目前已经公布的数据来看,今年电商平台的红包金额已达42亿元。
在巨大的利益面前,黑灰产从不会缺席,毕竟哪里有利益,哪里就有黑灰产。
而随着电商行业的崛起,黑灰产几乎已经渗透到了电商行业的各个环节。比如黑产针对商家和消费者的需求,在店铺日常运营的各个环节提供了相应的作弊服务。而电商常见的黑产威胁有刷单、薅羊毛、恶意差评、恶意下单、数据窃取等。
1)刷单
黑产通过机刷设备批量下单或真人众包任务分发等不合规的方式,帮助商家快速获得大量虚假订单。从而快速获得更多的好评,提升前台展现排名,使得店铺能够获得更多流量,促成更多的成交。
2)薅羊毛
常见的黑产薅羊毛行为指通过作弊的方式,快速、批量的获取网站提供的大额优惠券、现金红包、高价值实物奖励等。再通过其他平台对获得的奖励进行售卖变现。
3)恶意差评/举报
常见的恶意差评出现在同行恶意竞争的情况下,黑产通过真人众包给出差评或机器批量举报等方式,使得店铺遭受损失。
4)恶意攻击
黑产攻击者通过技术手段,短时间内发出大量的攻击请求占有贷款资源,造成页面瘫痪,导致正常用户无法访问。或者通过大规模批量的下单不付款的方式,导致商品无法正常售卖。
5)数据爬取
网络爬虫通过模拟真人浏览网页的行为,对电商网站上的用户和商品信息等进行批量的采集。对于数据进行沉淀和加工后进行售卖。
根据历年黑灰产的行为特征分析,春节期间设备异常行为风险占比最高,为71.67%。其主要风险为同设备短时间内高频发起请求,检测设备存在模拟器等风险。手机号异常聚集风险占13.15%,其主要是因为黑产通过批量购买同号段的手机号用于线上攻击被策略精准识别。

对于用户而言,春节期间,黑灰产的各种抢购工具可能会让用户的账号安全受到影响,一方面是账号密码容易泄露,一方面是抢购工具中可能藏有木马病毒,容易泄露用户的更多信息,如账号密码、收件人地址、联系方式等,对用户造成资金损失。
对整个市场而言,黑灰产大大规模抢购活动会影响市场的正常秩序,影响消费者的消费体验,对企业的后续品牌传播甚至品牌荣誉都会带来负面影响。
做好万全应急策略才能以不变应万变
那么,春节期间,企业业务安全要做好哪些准备,才能确保企业业务安全?
顶象认为,应从以下三方面进行考虑:
1、春节放假前,企业内部应做好相关系统的巡检,提前消除隐患,确保系统集群的健康运行。春节期间,企业业务安全应做好业务数据监控和报警,确保企业业务安全。
任何一种风控策略都不能完全保证可以阻断黑灰产,此时就需要企业需要做好业务数据监控和报警,一旦发现疑似高风险行为,应立即报警给值班人员,及时处理,避免不必要的损失。
比如出现了批量注册、批量下单行为,可以判定其具有风险特征,并做出相应防控策略。
2、春节期间,企业应安排在线值班人员,确保能随时上线,在线对接处理业务安全问题,以备应急。
与黑灰产的对抗归根结底是与安全人员之间的对抗,春节期间,一旦出现了大量薅羊毛事件,仅靠机器识别是无法阻断黑灰产的,还需要安全人员与黑灰产进行“博弈”,因此,春节期间企业应合理安排值班人员,确保企业业务资产安全,一旦出现应急事件,安全人员也可提前做好应急预案,避免更大的损失出现。
3、春节期间,企业业务安全应做好应急预案,确保出现问题能够马上找到应对之法:
针对春节期间可能出现的薅羊毛行为,企业应及时部署验证码、设备指纹等风控产品,对注册、登陆、查询、恶意账号、恶意爬取行为进行实时核验、判定和拦截,保证企业业务安全。
对企业App进行端加固,对移动应用运行时终端设备、运行环境、操作行为进行实时监测,帮助App建立运行时风险的监测、预警、阻断和溯源安全体系。
多业务节点接入,注册、登录、报告查询、下载等业务节点全链路接入风控,各场景基础通用风控维度如识别设备聚集、IP聚集、用户高频等维度识别垃圾注册、批量养号以及爬虫风险。
结合各个场景分别定制不同维度的风控策略,如登录场景同人养号风险,同设备多账号、同IP多账号聚集等;报告查询场景短时间请求量激增、代理IP、同设备高频访问等维度。
建立本地名单动态运营维护机制,基于注册、登录、报告查询等,沉淀并维护对应黑白名单数据,包括用户ID、手机号、设备ID、IP地址等维度的黑名单。
基于以上应急策略,顶象建议各企业可参考以下几种风控产品:
1)顶象无感验证。
顶象无感验证是一个以防御云为核心,集13种验证方式,多种防控策略,以智能验证码服务、验证决策引擎服务、设备指纹服务、人机模型服务为一体的云端交互安全验证系统。其汇集了4380条风险策略、112类风险情报、覆盖24个行业、118种风险类型,防控精准度>99.9%,1天内便可实现从风险到情报的转化,行业风险感知能力实力加强,同时支持安全用户无感通过,实时对抗处置能力更是缩减至60s内。
作为防御云的一部分,顶象智能验证码能够阻挡恶意爬虫盗用、盗取数据行为。并能够在注册、登录、查询时,对恶意账号、恶意爬取行为进行实时的核验、判定和拦截。
2)顶象端加固。
顶象端加固作为顶象防御云的一部分,顶象端加固支持安卓、ios、H5、小程序等平台,独有云策略、业务安全情报和大数据建模能够力。基于防御云,顶象端加固能够为App提供移动应用运行是进行安全监测,对移动应用运行时终端设备、运行环境、操作行为进行实时监测,帮助App建立运行时风险的监测、预警、阻断和溯源安全体系。
3)顶象设备指纹。
设备指纹作为顶象防御云的一部分,集成了业务安全情报、云策略和数据模型,通过用户上网设备的硬件、网络、环境等特征信息生成设备的唯一标识,覆盖安卓、iOS、H5、小程序,可有效识别模拟器、刷机改机、Root、越狱、劫持注入等风险,做到有效监控和拦截。
4)顶象风控引擎。
根据业务查询场景的请求、客户端采集的设备指纹信息、用户行为数据行为(鼠标的滑动轨迹、键盘的敲击速率、滑动验证码的滑动轨迹、速率、按钮点击等行为轨迹等),实现对恶意“爬虫”行为的有效识别,基于安全防控策略,有效地恶意爬取行为进行识别和拦截。
最后,顶象全体员工在这里提前恭祝各位新春快乐!春节期间,顶象将用更优质的服务和不断创新的技术为企业带来更安全、优质的服务,为企业业务安全保驾护航。
Linux 常见异常分析,请收好这份排查指南
1 常用的 Load 分析方法
CPU高、Load高
- 通过
top命令查找占用CPU最高的进程PID; - 通过
top -Hp PID查找占用CPU最高的线程TID; - 对于
java程序,使用jstack打印线程堆栈信息; - 通过
printf %x tid打印出最消耗CPU线程的十六进制;
CPU低、Load高
产生的原因一句话总结就是:等待磁盘I/O完成的进程过多,导致进程队列长度过大,但是CPU运行的进程却很少,这样就体现到负载过大了,cpu使用率低。
- 通过
top命令查看CPU等待IO时间,即%wa; - 通过
iostat -d -x -m 1 10查看磁盘IO情况;(安装命令 yum install -y sysstat) - 通过
sar -n DEV 1 10查看网络IO情况; - 通过如下命令查找占用IO的程序;
ps -e -L h o state,cmd | awk if($1=="R"||$1=="D")print $0 | sort | uniq -c | sort -k 1nr
2 CPU高、Load高情况分析
- 使用
vmstat查看系统纬度的 CPU 负载; - 使用
top查看进程纬度的 CPU 负载;
2.1 使用 vmstat 查看系统纬度的 CPU 负载
可以通过 vmstat 从系统维度查看 CPU 资源的使用情况
格式:vmstat -n 1 -n 1 表示结果一秒刷新一次
[root@VM-1-14-centos ~]# vmstat -n 1
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
1 0 0 250304 163472 2154300 0 0 1 16 0 4 1 0 98 0 0
0 0 0 250412 163472 2154332 0 0 0 0 937 1439 1 1 99 0 0
0 0 0 250428 163472 2154332 0 0 0 4 980 1329 0 0 100 0 0
0 0 0 250444 163472 2154332 0 0 0 0 854 1227 0 0 99 0 0
0 0 0 250444 163472 2154332 0 0 0 68 832 1284 0 1 99 1 0
0 0 0 250016 163472 2154332 0 0 0 0 929 1389 1 1 99 0 0
返回结果中的主要数据列说明:
- r:表示系统中 CPU 等待处理的线程。由于 CPU 每次只能处理一个线程,所以,该数值越大,通常表示系统运行越慢。
- b:表示阻塞的进程,这个不多说,进程阻塞,大家懂的。
- us:用户CPU时间,我曾经在一个做加密解密很频繁的服务器上,可以看到us接近100,r运行队列达到80(机器在做压力测试,性能表现不佳)。
- sy:系统CPU时间,如果太高,表示系统调用时间长,例如是IO操作频繁。
- wa:IO 等待消耗的 CPU 时间百分比。该值较高时,说明 IO 等待比较严重,这可能磁盘大量作随机访问造成的,也可能是磁盘性能出现了瓶颈。
- id:处于空闲状态的 CPU 时间百分比。如果该值持续为 0,同时 sy 是 us 的两倍,则通常说明系统则面临着 CPU 资源的短缺。
常见问题及解决方法:
- 如果 r 经常大于4,且id经常少于40,表示cpu的负荷很重。
- 如果pi,po长期不等于0,表示内存不足。
- 如果disk经常不等于0,且在b中的队列大于3,表示io性能不好。
2.2 使用 top 查看进程纬度的 CPU 负载
可以通过 top 从进程纬度来查看其 CPU、内存等资源的使用情况。
top - 19:49:59 up 36 days, 23:15, 3 users, load average: 0.11, 0.04, 0.05
Tasks: 133 total, 1 running, 131 sleeping, 0 stopped, 1 zombie
%Cpu(s): 3.1 us, 3.1 sy, 0.0 ni, 93.8 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
KiB Mem : 3880188 total, 241648 free, 1320424 used, 2318116 buff/cache
KiB Swap: 0 total, 0 free, 0 used. 2209356 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
1793 mysql 20 0 1608796 236708 9840 S 6.7 6.1 83:36.23 /usr/sbin/mysqld
1 root 20 0 125636 3920 2444 S 0.0 0.1 4:34.13 /usr/lib/systemd/systemd
2 root 20 0 0 0 0 S 0.0 0.0 0:00.90 [kthreadd]
4 root 0 -20 0 0 0 S 0.0 0.0 0:00.00 [kworker/0:0H]
6 root 20 0 0 0 0 S 0.0 0.0 0:15.46 [ksoftirqd/0]
7 root rt 0 0 0 0 S 0.0 0.0 0:12.02 [migration/0]
默认界面上第三行会显示当前 CPU 资源的总体使用情况,下方会显示各个进程的资源占用情况。
可以直接在界面输入大小字母 P,来使监控结果按 CPU 使用率倒序排列,进而定位系统中占用 CPU 较高的进程。最后,根据系统日志和程序自身相关日志,对相应进程做进一步排查分析,以判断其占用过高 CPU 的原因。
3 CPU低、Load高
问题描述
Linux 系统没有业务程序运行,通过 top 观察,类似如下图所示,CPU 很空闲,但是 load average 却非常高:
问题分析
CPU低而负载高也就是说等待磁盘I/O完成的进程过多,就会导致队列长度过大,这样就体现到负载过大了,但实际是此时CPU被分配去执行别的任务或空闲,具体场景有如下几种:
场景一:磁盘读写请求过多就会导致大量I/O等待
上面说过,cpu的工作效率要高于磁盘,而进程在cpu上面运行需要访问磁盘文件,这个时候cpu会向内核发起调用文件的请求,让内核去磁盘取文件,这个时候会切换到其他进程或者空闲,这个任务就会转换为不可中断睡眠状态。当这种读写请求过多就会导致不可中断睡眠状态的进程过多,从而导致负载高,cpu低的情况。
场景二:MySQL中存在没有索引的语句或存在死锁等情况
我们都知道MySQL的数据是存储在硬盘中,如果需要进行sql查询,需要先把数据从磁盘加载到内存中。当在数据特别大的时候,如果执行的sql语句没有索引,就会造成扫描表的行数过大导致I/O阻塞,或者是语句中存在死锁,也会造成I/O阻塞,从而导致不可中断睡眠进程过多,导致负载过大。具体解决方法可以在MySQL中运行show full processlist命令查看线程等待情况,把其中的语句拿出来进行优化。
场景三:外接硬盘故障,常见有挂了NFS,但是NFS server故障
比如我们的系统挂载了外接硬盘如NFS共享存储,经常会有大量的读写请求去访问NFS存储的文件,如果这个时候NFS Server故障,那么就会导致进程读写请求一直获取不到资源,从而进程一直是不可中断状态,造成负载很高。
处理办法
- load average 是对 CPU 负载的评估,其值越高,说明其任务队列越长,处于等待执行的任务越多。
- 出现此种情况时,可能是由于僵死进程导致的。可以通过指令ps -axjf查看是否存在 D 状态进程。
- D 状态是指不可中断的睡眠状态。该状态的进程无法被 kill,也无法自行退出。只能通过恢复其依赖的资源或者重启系统来解决。
等待 I/O 的进程通过处于 uninterruptible sleep 或 D 状态;通过给出这些信息我们就可以简单的查找出处在wait状态的进程。
ps -e -L h o state,cmd | awk if($1=="R"||$1=="D")print $0 | sort | uniq -c | sort -k 1nr
作者:Honest1y
来源:https://juejin.cn/post/7016127914454286367
以上是关于春节不打烊,这份安全应急指南请收好!的主要内容,如果未能解决你的问题,请参考以下文章
Angular项目实战Angular服务器渲染常遇的坑,这份填坑指南请收好~
金三银四Android面试怎么准备?想进大厂拿高薪?请收好这份进厂指南