医学图像配准综述之无监督转换模型2019-09-23
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了医学图像配准综述之无监督转换模型2019-09-23相关的知识,希望对你有一定的参考价值。
参考技术A 尽管前几节所述的方法取得了成功,但获得可靠的地面真相的困难性质仍然是一个重大障碍。这促使许多不同的小组探索无监督的方法。对这些工作有用的一个关键创新是空间转换网络(STN)[57]。有几种方法使用STN来执行配准变形任务。本节讨论利用图像相似性度量(第5.1节)和图像数据的特征表示(第5.2节)来训练网络的无监督方法。著名作品的描述见表3。本节首先讨论使用公共相似性度量和公共正则化策略来定义损失函数的方法。本节稍后将讨论使用更复杂的基于相似性度量的策略的方法。图9给出了一种基于标准相似度度量的变换估计可视化方法。
Neylon et al. [94] 在配准CT图像时使用神经网络学习图像相似度度量值与TRE之间的关系。这样做是为了有效地评估配准性能。在95%的情况下,该网络能够实现亚体素的准确性(subvoxel accuracy )。
Balakrishnan等[7,8]提出了一种无监督图像配准的通用框架,理论上可以是单模态配准,也可以是多模态配准。神经网络使用一个选定的、手工定义的图像相似性度量(如NCC、NMI等)进行训练。
Dalca et al. [23] 将变形预测作为变分推断进行了预测。将微分积分与转换层相结合得到速度场。通过对速度场进行平方和重新标定,得到了预测的变形量。MSE作为相似度度量,与正则化项一起定义损失函数。他们的方法优于基于ANT的配准[6]和基于深度学习的方法描述的[7]。
Kuang et al. [68] 使用CNN和STN启发的框架来执行t1加权脑MR的可变形配准。损失函数由一个NCC项和一个正则化项组成。该方法使用Inception模块、低容量模型和残差连接,而不是跳过连接。他们使用LBPA40和Mindboggle 101数据集,将他们的方法与VoxelMorph (Balakrishnan等人提出的方法,如上所述)、[8]和uTIlzReg GeoShoot[128]进行了比较,并证明了两者的优越性能。
Ferrante et al. [35] 采用基于迁移学习的方法对x线和心脏图像进行单峰配准。在这项工作中,网络使用NCC作为主要的损失函数项,对来自源域的数据进行训练,并在目标域中进行测试。他们分别使用类似U-net结构 [103]和STN[57]进行特征提取和变换估计。他们证明了使用域作为源域或目标域的转移学习可以产生有效的结果。该方法优于Elastix配准技术[62]。
尽管将基于相似度度量的方法应用于多模态情况比较困难,Sun et al. [120] 提出了一种无监督的三维MR/US脑配准方法,该方法使用由特征提取器和变形场发生器组成的三维CNN。该网络使用像素强度和梯度信息的相似性度量进行训练。此外,图像强度和梯度信息都被用作CNN的输入。
Cao et al. [12]也将基于相似性度量的训练应用于多模态情况。具体来说,他们使用模内图像相似性来监督三维骨盆CT/MR体积的多模态可变形配准。利用真值变换得到的运动图像与利用预测变换得到的运动图像之间的NCC作为损失函数。这项工作采用“对偶”监督。这不能与前面描述的双重监管策略相混淆。
受典型的无监督方法所估计的非对称变换的局限性的启发,Zhang等人[142]利用他们的网络——逆协调深度网络(network InverseConsistent Deep network, ICNet)来学习排列在同一空间中的每个大脑MR卷的对称的不同形态变换。与其他使用标准正则化策略的作品不同,本文引入了一个反一致正则项和一个反折叠正则项,以确保高度加权平滑约束不会导致折叠。最后,两个图像之间的MSD允许以无监督的方式对网络进行训练。该方法优于基于SyN的配准[5]、基于Demons的配准[80]和几种基于深度学习的方法。
本节描述的后面三种方法采用GAN方法。与前面描述的基于gan的方法不同,这些方法既不使用真实数据,也不使用手工分割。Mahapatra等[85]使用GAN隐式学习密度函数(density function),该函数表示心脏图像和多模态视网膜图像(视网膜彩色眼底图像和荧光素血管造影(FA)图像)的可信变形范围。除了NMI、结构相似度指标测度(SSIM)和特征感知损失项(由VGG输出之间的SSD决定)之外,损失函数还由条件约束和循环约束组成,这些约束是基于最近涉及到对抗性框架实现的进展。该方法优于基于弹性配准和de Vos等人提出的[26]方法。
Fan et al. [33] 使用GAN对三维脑磁共振体积进行无监督的可变形图像配准。与大多数其他使用手工制作的相似性度量来确定损失函数的非监督工作不同,也不像以前使用GAN来确保预测的变形是真实的,这种方法使用一个鉴别器来评估对齐的质量。该方法在除MGH10外的所有数据集上都优于异态恶魔和SyN配准。此外,使用甄别器对注册网络进行监督优于对所有数据集使用地面真值数据、SSD和CC。
Mahapatra等[86]不同于以往描述的工作(不仅仅是基于GAN的工作),提出了使用GAN框架同时分割和配准胸透。该网络有3个输入:参考图像、浮动图像和参考图像的分割掩码,输出变换后图像的分割掩码和变形场。三个鉴别器用于评估生成输出的质量(变形场,翘曲图像,分割)使用周期一致性和骰子度量。此外,生成器还使用NMI、SSIM和一个特征感知丢失项进行训练。
最后,与本节的其他方法不同,Jiang et al. [59] 没有预测给定固定参数的变形场,而是使用CNN学习图像变形的最优参数化,使用多网格b样条方法和L1-norm正则化。他们使用这种方法来参数化4D CT胸部图像体积的可变形配准。这里,SSD用作相似性度量,L-BFGS-B用作优化器。利用该方法得到的参数化变形模型的收敛速度比传统的l1 -范数正则化多网格参数化变形模型速度快。
基于图像相似度的无监督图像配准技术由于克服了对任何类型的专家标签的需求,近年来受到了研究领域的广泛关注。这意味着模型的性能将不依赖于从业者的专业知识。此外,扩展了原有的基于相似度度量的方法,引入了更复杂的相似度度量(如GAN的判别器)和/或正则化策略已经产生了有希望的结果。然而,对于多模态配准应用,图像相似度的量化仍然是一个难点。因此,基于图像相似性的无监督作品的范围很大程度上局限于单模态情况。鉴于在许多临床应用中经常需要多模态配准,我们希望在不久的将来看到更多的论文来解决这个具有挑战性的问题。
在本节中,研究了利用学习特征表示训练神经网络的方法。与前一节中研究的方法一样,本节中调查的方法不需要ground truth数据。在本节中,首先介绍创建单模态配准的方法。然后,讨论了一种解决多模态图像配准问题的方法。基于特征的变换估计大致结构如图10所示
Yoo et al. [140] 使用STN来配准连续切片电子显微镜图像(ssEMs)。训练一个自编码器对固定图像进行重构,利用重构后的固定图像与相应的运动图像之间的L2距离和几个正则化项构造损失函数。该方法优于bUnwarpJ配准技术[4]和弹性配准技术[105]。
Liu et al. [78] 提出了一种基于张量思想的单模态和多模态配准方法。实验验证了该方法的有效性,采用了吸气-呼气对胸CT容积和多模态对脑MR图像。基于MI和剩余复杂度(RC)的方法[92],原始的基于意识MIND的[44]配准技术采用该方法之后更优。。
Krebs et al. [65, 66]用随机潜在空间学习方法对二维脑和心脏MR进行配准,绕过了空间正则化的需要。采用条件变分自编码器[28]来保证参数空间服从规定的概率分布。利用给定潜表示的固定图像的负对数似然性,以及潜分布与先验分布的弯曲体积和KL散度来定义损失。
与本节所述的其他方法不同,Kori等人使用预训练网络,在无监督容量下对二维T1和T2加权脑MR进行多模态配准特征提取和仿射变换参数回归[63]。首先对图像进行二值化,然后利用移动图像和固定图像之间的 Dice score作为代价函数。由于这两种模式的外观差异不显著,这些预训练模型可的使用可以起到相当的效果。
以无监督的方式进行多模态图像配准比进行单模图像配准更困难,因为使用手工制作的相似性指标量化两幅图像之间的相似性的困难性,并使用上面描述的无监督技术建立/检测voxel-to-voxel对应方法。最近引起了研究领域的极大兴趣是使用无监督学习来学习特征表示来求得最优转换。前面讨论的无监督图像配准方法,我们希望基于特征的无监督配准能够继续引起研究领域的极大兴趣。此外,对多模态情况的扩展(特别是对于使用具有显著外观差异的图像的应用)可能是未来几年的一个突出研究重点。
论文笔记图像分割和图像配准联合学习模型——DeepAtlas
本文是论文《DeepAtlas: Joint Semi-Supervised Learning of Image Registration and Segmentation》的阅读笔记。
文章第一个提出了一个图像配准和图像分割联合学习的网络模型 DeepAtlas,该模型实现了弱监督的图像配准和半监督的图像分割。在图像配准时使用图像的分割标签作为监督数据,如果没有分割标签,则通过分割网络产生;而经过配准后的图像增加了在图像分割时可利用的训练数据的量,相当于是一种数据增强。该模型不仅在分割和配准的精度上有所提升,并且还可以在训练数据有限的情况下实现较好的效果。
一、记号
- I m I_m Im:浮动图像(moving image)
- I t I_t It:目标图像(target image)
- F R \\mathcalF_R FR:配准网络
- θ r \\theta_r θr:配准网络的参数
- F S \\mathcalF_S FS:分割网络
- θ s \\theta_s θs:分割网络的参数
- u = F R ( I m , I t ; θ r ) u=\\mathcalF_R(I_m,I_t;\\theta_r) u=FR(Im,It;θr):形变场
- ϕ − 1 = u + i d \\phi^-1=u+id ϕ−1=u+id:形变图,其中 i d id id 是恒等变换
- I m w = I m ∘ ϕ − 1 I_m^w=I_m\\circ\\phi^-1 Imw=Im∘ϕ−1:配准后的图像
- S t S_t St:目标图像分割标签
- S m w = S m ∘ ϕ − 1 S_m^w=S_m\\circ\\phi^-1 Smw=Sm∘ϕ−1:配准后图像分割标签
二、网络结构
DeepAtlas 的目的是当数据集中只有少量的分割标签可用时,通过联合训练来让分割和配准实现较高的精度。
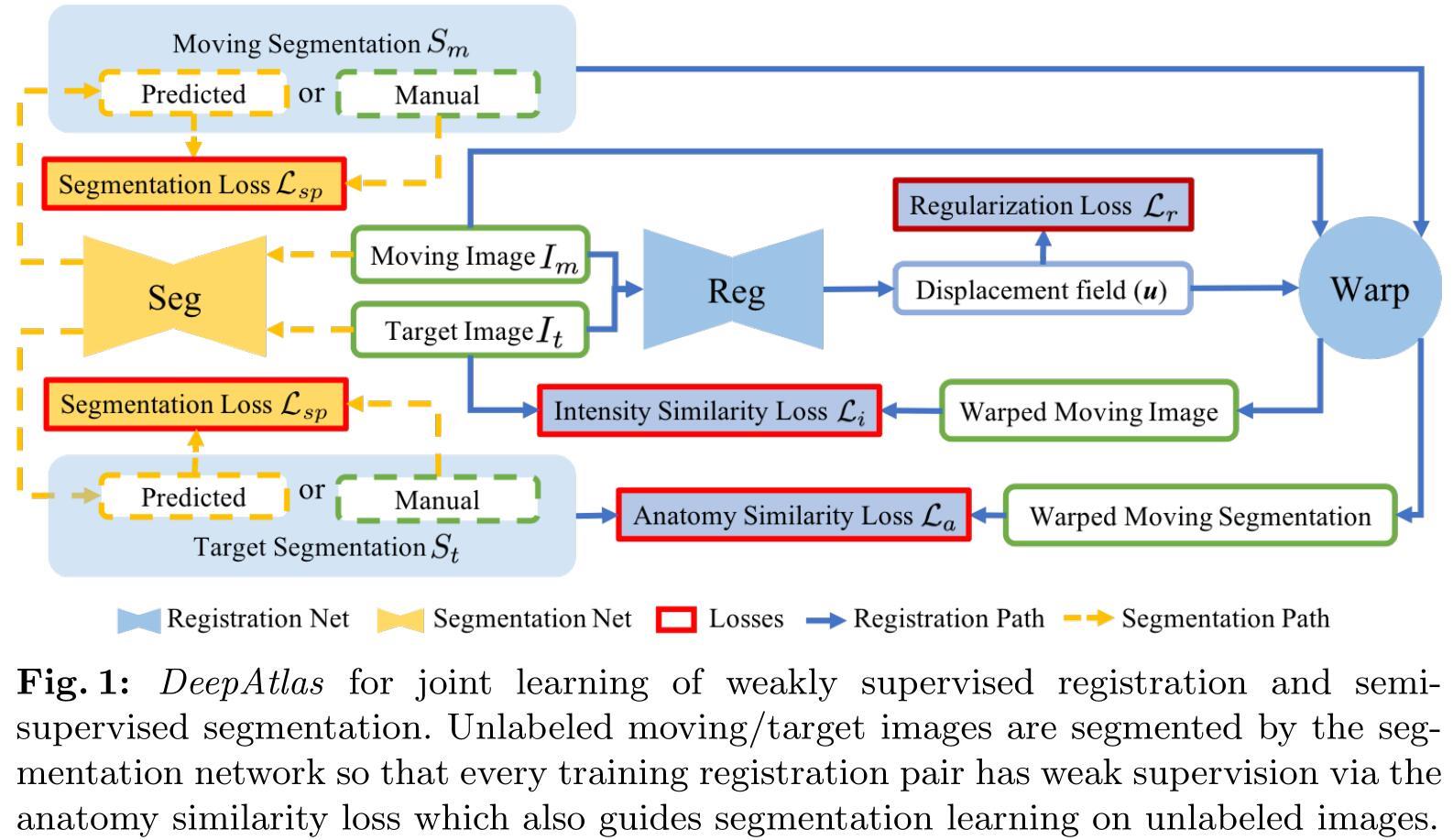
网络的结构如上图所示,蓝色的实线表示弱监督的配准,黄色虚线表示半监督的分割。
文章在附件中给出了分割网络和配准网络的具体结构,如下图左右两图所示:
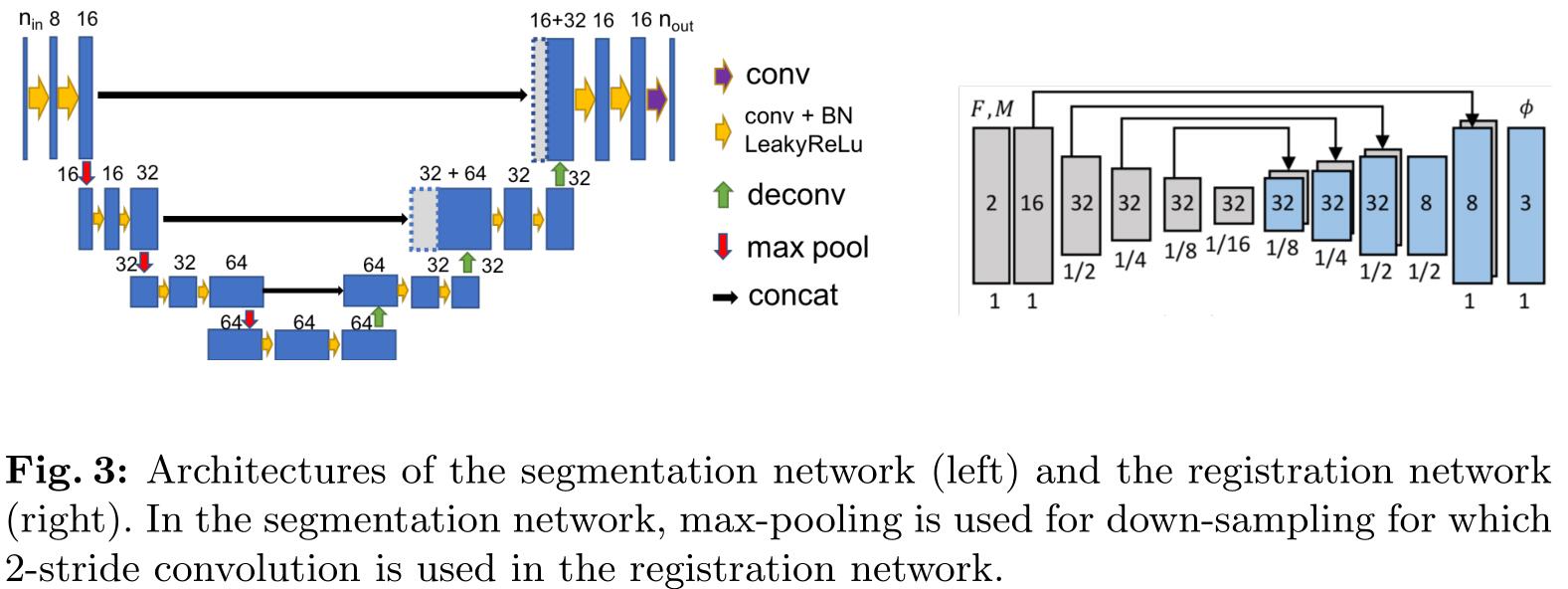
1. 配准网络
配准网络的损失主要有三个损失函数组成:配准正则损失 L r \\mathcalL_r Lr,图像相似度损失 L i \\mathcalL_i Li 和解剖损失(分割相似度损失) L a \\mathcalL_a La。配准正则损失 L r \\mathcalL_r Lr 可以让形变场 ϕ \\phi ϕ 变得光滑,图像相似度损失 L i \\mathcalL_i Li 用来评价浮动图像 I m I_m Im 和配准后图像 I m w I_m^w Imw 之间的相似度,解剖损失(分割相似度损失) L a \\mathcalL_a La 是目标图像分割标签 S t S_t St 和配准后图像分割标签 S m w S_m^w Smw 之间的相似度损失。
如此一来,配准学习的过程可以由下式表示:
θ
r
⋆
=
argmin
θ
r
L
i
(
I
m
∘
Φ
−
1
,
I
t
)
+
λ
r
L
r
(
Φ
−
1
)
+
λ
a
L
a
(
S
m
∘
Φ
−
1
,
S
t
)
\\theta_r^\\star=\\underset\\theta_r\\operatornameargmin\\left\\\\mathcalL_i\\left(I_m \\circ \\Phi^-1, I_t\\right)+\\lambda_r \\mathcalL_r\\left(\\Phi^-1\\right)+\\lambda_a \\mathcalL_a\\left(S_m \\circ \\Phi^-1, S_t\\right)\\right\\
θr⋆=θrargminLi(Im∘Φ−1,It)+λrLr(Φ−1)+λaLa(Sm∘Φ−1,St)
其中
λ
r
,
λ
a
≥
0
\\lambda_r,\\lambda_a\\geq0
λr,λa≥0。
2. 分割网络
分割网络的输入是一张图像
I
I
I,输出相应的分割结果
S
^
=
F
S
(
I
;
θ
s
)
\\hatS=\\mathcalF_S(I;\\theta_s)
S^=FS(I;θs),分割网络的损失主要有两个损失函数组成:解剖损失
L
a
\\mathcalL_a
La 和有监督分割损失
L
s
p
\\mathcalL_sp
Lsp。解剖损失和配准网络中的相同,有监督的分割损失
L
s
p
(
S
^
,
S
)
\\mathcalL_sp(\\hatS,S)
Lsp(S^,S) 是分割网络的分割结果
S
^
\\hatS
S^ 和人工分割结果
S
S
S 之间的相似度损失。但是浮动图像
I
m
I_m
Im 和目标图像
I
t
I_t
It 的分割标签的存在情况有多种可能,所以相应的损失函数也存在以下四种情况: 以上是关于医学图像配准综述之无监督转换模型2019-09-23的主要内容,如果未能解决你的问题,请参考以下文章
L
a
=
L
a
(
S
m
∘
Φ
−
1
,
F
S
(
I
t
)
)
and
L
s
p
=
L
s
p
(
F
S
(
I
m
)
,
S
m
)
,
if
I
t
is unlabeled;
L
a
=
L
a
(
F
S
(
I
m
)
∘
Φ
−
1
,
S
t
)