Redis源码解读——跳跃表
Posted WoLannnnn
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Redis源码解读——跳跃表相关的知识,希望对你有一定的参考价值。
文章目录
Redis 中的跳跃表结构
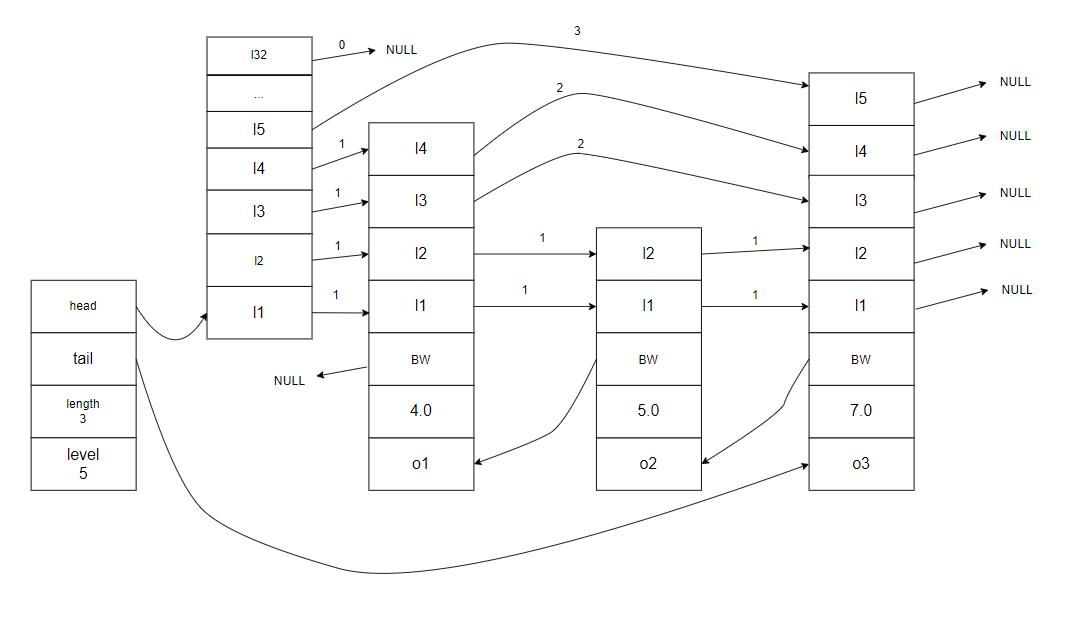
每个节点都有各自的分层,前进节点,后退节点,键以及分值。
- 后退节点即用来从跳跃表尾部从后向前遍历。
- 前进节点有两部分:前进指针,以及前进的步长。这个步长可以用来计算排位,比如在查找某个节点过程中,将中间的跨度加起来,就可以得到它在跳跃表中的排位。
跳跃表节点定义:
typedef struct zskiplistNode
sds ele;
double score;
struct zskiplistNode *backward; // 后退节点
struct zskiplistLevel
struct zskiplistNode *forward; // 前进节点
unsigned long span;
level[];
zskiplistNode;
跳跃表节点内部有一个关于层数的柔性数组,代替了传统的 up、down 指针。
跳跃表定义:
typedef struct zskiplist
struct zskiplistNode *header, *tail; // 首尾节点
unsigned long length; // 元素个数
int level; // 层高
zskiplist;
我们再观察上面的 head 节点,head 节点不存放数据,并且层高固定为 32 层,32 层已经满足对于 2 ^ 64 个元素查找的效率了,所以跳跃表最高也就是 32 层。
创建、释放跳跃表
创建跳跃表节点
创建一个指定层数的跳跃表节点,sds 字符串 ele 将会被该节点引用。sds 字符串即是跳跃表节点的键
zskiplistNode *zslCreateNode(int level, double score, sds ele)
zskiplistNode *zn =
zmalloc(sizeof(*zn)+level*sizeof(struct zskiplistLevel));
zn->score = score;
zn->ele = ele;
return zn;
创建跳跃表
创建跳跃表的时候会将 head 节点设置为 32 层
zskiplist *zslCreate(void)
int j;
zskiplist *zsl;
zsl = zmalloc(sizeof(*zsl));
zsl->level = 1;
zsl->length = 0;
zsl->header = zslCreateNode(ZSKIPLIST_MAXLEVEL,0,NULL);
for (j = 0; j < ZSKIPLIST_MAXLEVEL; j++)
zsl->header->level[j].forward = NULL;
zsl->header->level[j].span = 0;
zsl->header->backward = NULL;
zsl->tail = NULL;
return zsl;
释放跳跃表节点
释放跳跃表节点,同时也释放 sds string
注意:释放 node 即代表该节点的所有层都被释放了
void zslFreeNode(zskiplistNode *node)
sdsfree(node->ele);
zfree(node);
释放跳跃表
/* Free a whole skiplist. */
void zslFree(zskiplist *zsl)
zskiplistNode *node = zsl->header->level[0].forward, *next;
zfree(zsl->header);
while(node)
next = node->level[0].forward;
zslFreeNode(node);
node = next;
zfree(zsl);
增删改
插入节点
插入节点需要先找到插入位置。由于插入时节点会随机上升,所以要从底层开始,一直到上升的最大层做处理。并且上升的层数也是随机的,所以处理时需要格外注意。
zslInsert() 函数在查找插入位置的过程中,用数组记录每一层中,最后一个排在待插入节点前面的那个,并且记录它们在每层中的排名。这样记录完成后,之后对每层的更新都很方便。
查找过程:
从最上面一层开始查找,x 作为遍历节点。当 x->forward 的 score 值大于 待插入节点的 score 值,或者 score 值相等,但键值小于 待插入节点的 ele ,就说明该层最后一个排在待插入节点前面的节点就是 x 了。
否则,x 还不是最后一个符合要求的节点,就需要将 x 的 rank 值加到 rank[i] 中。
更新跳跃表:
查找结束后,所有层的插入位置都找到了,接下来需要确认该次插入实际上需要上升多少层,通过 zslRandomLevel() 得出,记作 level
- 如果 level 大于当前跳跃表的最大层数,则 update 数组中处于(zsl->level, level] 的节点以及 rank 值需要另外处理。高于 zsl->level 的层中,不存在其它节点,所以将这个区间中的 update 设为 head 节点,并将 head 节点在这写层的 span 设置为 zkl->length,这对之后更新待插入节点以及 update 节点的 span 值做铺垫。还有rank 值设为 0。
之后就是实际插入过程了,创建好新的节点 x,遍历 0 - level 层,将 x 插入,修改 forward 指向(backward 指向最后修改,只需要改第一层的即可)。还有一个 span 值我们需要更新:
// rank[0]表示插入节点前一的排名,rank[i]表示第i+1层中,插入节点的前一节点的排名
// rank[0]-rank[i]就表示了update[i]到update[0]的距离
// update[i]->level[i].span - (rank[0] - rank[i]) 就表示原跨度减去前面的距离
x->level[i].span = update[i]->level[i].span - (rank[0] - rank[i]);
// update[i]的跨度即为update[i]到插入节点在该层的跨度
update[i]->level[i].span = (rank[0] - rank[i]) + 1;
这里是笔者认为最难理解的地方(笔者脑子不好使,琢磨了挺久才搞清楚),如果能看懂笔者的注释更好,看不懂的话,我们还有图来帮助理解:
假设现在在第 i 层更新,

所以如果是高于原本跳跃表最高层的层,head 的 span 值设置为 zsl->length
插入完以后,如果 level 是小于原 zkl->level 的,则需要将这些未插入 x 的 update 节点加一个跨度,因为它们的后面多出了一个 x 节点。
最后是处理第一层的 backward 节点。如果 x 是第一个插入的元素,即 update[0] == head,则 x->backward = NULL,否则就等于 update[0]。而 x 的下一个节点,也需要将 backward 指针指向 x。如果 x->forward == NULL,则说明 x 是最后一个节点,不需要处理,但需要将 跳跃表的尾指针指向 x;否则,修改 x->forward 的 backward 指针。
/* Insert a new node in the skiplist. Assumes the element does not already
* exist (up to the caller to enforce that). The skiplist takes ownership
* of the passed SDS string 'ele'. */
zskiplistNode *zslInsert(zskiplist *zsl, double score, sds ele)
zskiplistNode *update[ZSKIPLIST_MAXLEVEL], *x; // update 保存了每一层最后一个排在新节点前面的那个节点
unsigned long rank[ZSKIPLIST_MAXLEVEL]; // rank 记录了这些节点在跳跃表中的排名
int i, level;
serverAssert(!isnan(score));
x = zsl->header;
for (i = zsl->level-1; i >= 0; i--)
/* store rank that is crossed to reach the insert position */
rank[i] = i == (zsl->level-1) ? 0 : rank[i+1];
while (x->level[i].forward &&
(x->level[i].forward->score < score ||
(x->level[i].forward->score == score &&
sdscmp(x->level[i].forward->ele,ele) < 0)))
rank[i] += x->level[i].span;
x = x->level[i].forward;
update[i] = x;
/* we assume the element is not already inside, since we allow duplicated
* scores, reinserting the same element should never happen since the
* caller of zslInsert() should test in the hash table if the element is
* already inside or not. */
level = zslRandomLevel();
if (level > zsl->level)
for (i = zsl->level; i < level; i++)
rank[i] = 0;
update[i] = zsl->header;
update[i]->level[i].span = zsl->length;
zsl->level = level;
x = zslCreateNode(level,score,ele);
for (i = 0; i < level; i++)
x->level[i].forward = update[i]->level[i].forward;
update[i]->level[i].forward = x;
/* update span covered by update[i] as x is inserted here */
// rank[0]表示插入节点前一的排名,rank[i]表示第i+1层中,插入节点的前一节点的排名
// rank[0]-rank[i]就表示了update[i]到update[0]的距离
// update[i]->level[i].span - (rank[0] - rank[i]) 就表示原跨度减去前面的距离
x->level[i].span = update[i]->level[i].span - (rank[0] - rank[i]);
// update[i]的跨度即为update[i]到插入节点在该层的跨度
update[i]->level[i].span = (rank[0] - rank[i]) + 1;
/* increment span for untouched levels */
for (i = level; i < zsl->level; i++)
update[i]->level[i].span++;
x->backward = (update[0] == zsl->header) ? NULL : update[0];
if (x->level[0].forward)
x->level[0].forward->backward = x;
else
zsl->tail = x;
zsl->length++;
return x;
删除节点
先来看一个供其它删除函数调用的一个函数:
先看参数:x 是要删除的节点,update 数组和上面插入的含义是一样的,即每一层的 x 的前一元素。
首先是更新 update 数组中每个节点的属性,然后修改 backward 指针。最后更新跳跃表的 level 和 length。
void zslDeleteNode(zskiplist *zsl, zskiplistNode *x, zskiplistNode **update)
int i;
for (i = 0; i < zsl->level; i++)
if (update[i]->level[i].forward == x)
update[i]->level[i].span += x->level[i].span - 1;
update[i]->level[i].forward = x->level[i].forward;
else
update[i]->level[i].span -= 1;
if (x->level[0].forward)
x->level[0].forward->backward = x->backward;
else
zsl->tail = x->backward;
while(zsl->level > 1 && zsl->header->level[zsl->level-1].forward == NULL)
zsl->level--;
zsl->length--;
然后是真正删除一个节点的函数:
上面有一段注释,意思是:从跳跃表中删除一个分值和键匹配的元素。如果节点被找到并删除了返回1,其它情况返回0.
如果参数 node 为空,则从跳跃表中删除的节点会被释放,否则不会被释放,只是从跳跃表中删除了,并且*node会被设置为被删除节点的指针,因为它还有可能被调用者使用。(包括节点中的 SDS string)
下面是函数的逻辑:
与 zslInsert() 函数一样,用 update 数组保存每一层中最后一个小于 删除节点 的节点,循环结束后,x->forward 就是第一层中第一个大于等于 删除节点 的节点。
所以接下来指向判断 x->forward 是否符合删除要求就可以将元素删除,并将每一层中节点的相关属性通过 zslDeleteNode() 更新。
/* Delete an element with matching score/element from the skiplist.
* The function returns 1 if the node was found and deleted, otherwise
* 0 is returned.
*
* If 'node' is NULL the deleted node is freed by zslFreeNode(), otherwise
* it is not freed (but just unlinked) and *node is set to the node pointer,
* so that it is possible for the caller to reuse the node (including the
* referenced SDS string at node->ele). */
int zslDelete(zskiplist *zsl, double score, sds ele, zskiplistNode **node)
zskiplistNode *update[ZSKIPLIST_MAXLEVEL], *x;
int i;
x = zsl->header;
for (i = zsl->level-1; i >= 0; i--)
while (x->level[i].forward &&
(x->level[i].forward->score < score ||
(x->level[i].forward->score == score &&
sdscmp(x->level[i].forward->ele,ele) < 0)))
x = x->level[i].forward;
update[i] = x;
/* We may have multiple elements with the same score, what we need
* is to find the element with both the right score and object. */
x = x->level[0].forward;
if (x && score == x->score && sdscmp(x->ele,ele) == 0)
zslDeleteNode(zsl, x, update);
if (!node)
zslFreeNode(x);
else
*node = x;
return 1;
return 0; /* not found */
更新节点 score 值
该函数试图在 curscore 和 ele 匹配的节点处更新该节点的 score,并且更新后节点还在原位置。如果无法保证更新后节点位置不变,则会删除该节点,再将含有新 score 值的节点插入跳跃表
前面还是一样,找到所有层中的 update 节点,然后 serverAssert() 断言假设 x 当前是匹配 curscore 和 ele 的。之后进行判断,看新的 score 值能否在放在 x 位置并使跳跃表仍然保持有序性。如果可以,则直接更新 x 的 score 值,然后返回。
如果不可以,则需要从跳跃表删掉 x,然后再以新的 score 值与原来的 ele 创建一个新节点并插入跳跃表中。
/* Update the score of an element inside the sorted set skiplist.
* Note that the element must exist and must match 'score'.
* This function does not update the score in the hash table side, the
* caller should take care of it.
*
* Note that this function attempts to just update the node, in case after
* the score update, the node would be exactly at the same position.
* Otherwise the skiplist is modified by removing and re-adding a new
* element, which is more costly.
*
* The function returns the updated element skiplist node pointer. */
zskiplistNode *zslUpdateScore(zskiplist *zsl, double curscore, sds ele, double newscore)
zskiplistNode *update[ZSKIPLIST_MAXLEVEL], *x;
int i;
/* We need to seek to element to update to start: this is useful anyway,
* we'll have to update or remove it. */
x = zsl->header;
for (i = zsl->level-1; i >= 0; i--)
while (x->level[i].forward &&
(x->level[i].forward->score < curscore ||
(x->level[i].forward->score == curscore &&
sdscmp(x->level[i].forward->ele,ele) < 0)))
x = x->level[i].forward;
update[i] = x;
/* Jump to our element: note that this function assumes that the
* element with the matching score exists. */
x = x->level[0].forward;
serverAssert(x && curscore == x->score && sdscmp(x->ele,ele) == 0);
/* If the node, after the score update, would be still exactly
* at the same position, we can just update the score without
* actually removing and re-inserting the element in the skiplist. */
if ((x->backward == NULL || x->backward->score < newscore) &&
(x->level[0].forward == NULL || x->level[0].forward->score > newscore))
x->score = newscore;
return x;
/* No way to reuse the old node: we need to remove and insert a new
* one at a different place. */
zslDeleteNode(zsl, x, update);
zskiplistNode *newnode = zslInsert(zsl,newscore,x->ele);
/* We reused the old node x->ele SDS string, free the node now
* since zslInsert created a new one. */
x->ele = NULL;
zslFreeNode(x);
return newnode;
至于 zskiplist 的“查”笔者没有研究,有兴趣的读者可以自行研究。
以上是关于Redis源码解读——跳跃表的主要内容,如果未能解决你的问题,请参考以下文章