第七次人口普查数据可视化分析实战——基于pyecharts(含数据和源码)
Posted JoJo的数据分析历险记
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了第七次人口普查数据可视化分析实战——基于pyecharts(含数据和源码)相关的知识,希望对你有一定的参考价值。
第七次人口普查数据可视化分析实战
- 🌸个人主页:JoJo的数据分析历险记
- 📝个人介绍:小编大四统计在读,目前保研到统计学top3高校继续攻读统计研究生
- 💌如果文章对你有帮助,欢迎✌
关注、👍点赞、✌收藏、👍订阅专栏
文章目录
写在前面
| 国家统计局发布的第七次人口普查数据较为宏观,未能较好的体现各地区人口指标的分布情况。本文基于Pyecharts初步分析各地区人口普查数据的分布情况😉。 |
# 导入相关库
import pyecharts
pyecharts.globals._WarningControl.ShowWarning = False
import warnings
warnings.filterwarnings('ignore')
import pandas as pd
from pyecharts.charts import Map
from pyecharts import options as opts
🥝1.数据集导入
df = pd.read_csv(r'C:\\Users\\DELL\\Desktop\\Statistic learning\\数据分析案例\\第七次人口普查\\pop.csv')
df.head()
| province | Total | Male | Female | sex-ratio | Aging-rate | AHP | Edu-level | GDP | CR | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 北京 | 2189.31 | 1120 | 1070 | 104.65 | 13.30 | 2.31 | 11.87 | 36102.55 | 86.20 |
| 1 | 天津 | 1386.60 | 714 | 672 | 106.31 | 14.75 | 2.40 | 10.81 | 14083.73 | 80.43 |
| 2 | 河北 | 7461.02 | 3768 | 3693 | 102.02 | 13.92 | 2.75 | 9.46 | 36206.89 | 45.59 |
| 3 | 山西 | 3491.56 | 1781 | 1711 | 104.06 | 12.90 | 2.52 | 10.02 | 17651.93 | 49.79 |
| 4 | 内蒙古 | 2404.92 | 1228 | 1177 | 104.26 | 13.05 | 2.35 | 9.94 | 17359.82 | 57.04 |
这里是我对第七次人口普查数据进行了基本处理后得到的数据集,感兴趣的小伙伴可以下载👉:数据下载地址
上述数据包含十个指标,分别如下:
province:省份,包含31个省、直辖市和自治区(不包含港澳台)Total:总人口,各地区第七次人口普查总人口(千万)Male:男性人口(千万)Female:女性人口(千万)sex-ratio:性别比(%), 男 性 人 口 女 性 人 口 × 100 % \\frac男性人口女性人口 \\times 100\\% 女性人口男性人口×100%Aging-rate:65岁及以上人口占总人口的比例,用来衡量一个地区的老龄化程度(%)AHP:户均人口。各地区平均每户人口数Edu-level:各地区受教育年限(经过处理后的数据)(年)GDP:各地区GDP数据(亿元)CR:各地区城镇化率(%)
🍓2.总人口统计
# 总人口统计
df['Total'][df['province']=='全国']
31 141178.0
Name: Total, dtype: float64
根据第七次全国人口普查结果,我国人口达14.1178亿,突破14亿大关。那么各个地区的人口分布情况如何呢?来看看你的家乡属于第几梯队🙋♂️
'''
导入地图和数据
'''
m1=Map()
m1.add("总人口", [list(z) for z in zip(df.province, df.Total)], "china",is_map_symbol_show=False)
'''
自定义间隔
'''
pieces = [
'max': 500, 'label': '500以下',
'min': 500, 'max': 1000, 'label': '500-1000',
'min': 1000, 'max': 2000, 'label': '1000-2000',
'min': 2000, 'max': 5000, 'label': '2000-5000', # 有下限无上限
'min': 5000, 'max': 10000, 'label': '5000-10000',
'min': 10000, 'label': '10000以上'
]
'''
全局设置
'''
m1.set_global_opts(
title_opts=opts.TitleOpts('第七次人口普查各地区人口总量分布图'),#设置图标题
visualmap_opts=opts.VisualMapOpts(is_piecewise=True,pieces=pieces))#热力图相关设置
m1.render_notebook()
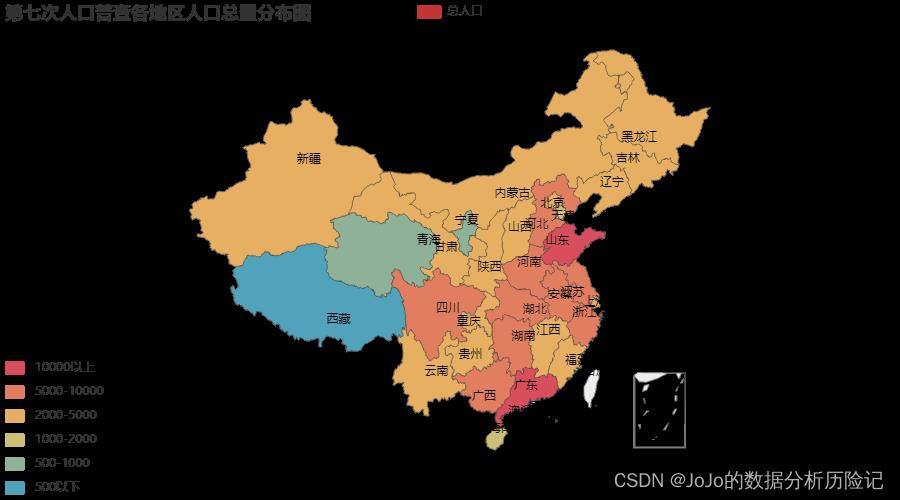
可以看出人口分布的整体趋势是由东南沿海逐渐向西北内陆地区递减
- 人口最高的两个省份是广东和山东,均超过了
1亿,而广东则是达到了1.2亿。北上广深四个一线城市,广东就包含了两个,吸引了大量的外来人口。 - 人口最低的省份是西藏,不足500万。这里有一部分原因是因为西藏有很多环境不适合居住,此外,由于经济发达水平相较较低,地区对人才吸引力较低,很多选择外出工作。
- 这种人口分布情况预计在未来很长一段时间都会保持。
🍅3.性别比统计
这里的性别比为:
男
性
人
口
/
女
性
人
口
×
100
%
男性人口/女性人口\\times100 \\%
男性人口/女性人口×100%
# 全国性别比情况
df['sex-ratio'][df['province']=='全国']
31 105.07
Name: sex-ratio, dtype: float64
可以看出,全国性别比为105.07%,我国已经成为世界上性别比失衡较为严重、持续时间较长的国家。这里一部分原因是受到了传统重男轻女思想的影响,导致男性人口基数较大,可能要在很长时间才有望达到平衡。这也意味着将会有一部分🤦♂️男性较难脱单😥。接下来我们来看看各地区的性别比例吧!
'''
导入地图和数据
'''
m2=Map()
m2.add("性别比例(%)", [list(z) for z in zip(df.province, df['sex-ratio'])], "china",is_map_symbol_show=False)
'''
自定义间隔
'''
pieces = [
'max': 100, 'label': '100以下',#有上限无下限
'min': 100, 'max': 105, 'label': '100-105',
'min': 105, 'max': 110, 'label': '105-110',
'min': 110, 'label': '110以上'# 有下限无上限
]
'''
全局设置
'''
m2.set_global_opts(
title_opts=opts.TitleOpts('第七次人口普查各地区性别比分布图'),#设置图标题
visualmap_opts=opts.VisualMapOpts(is_piecewise=True,pieces=pieces))#热力图相关设置
m2.render_notebook()
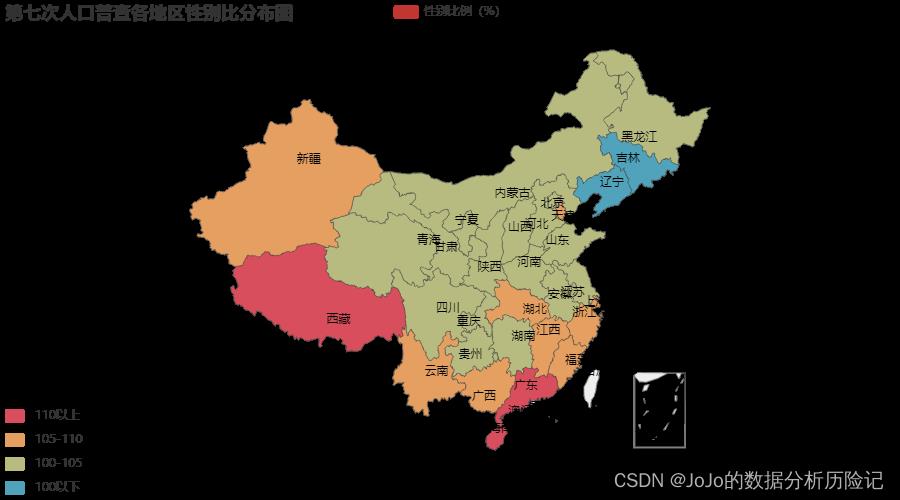
从上面这个性别比热力图,我们发现一个有意思的规律。
- 从全局来看,性别比呈现由北向南逐渐上升的情况。也就是说南方地区,男性比例要更高。
- 其中吉林和辽宁两地区性别比居然还小于100%,广大男性朋友想要脱单的建议去试试!😂
- 而广东、海南、西藏的男性朋友们就比较惨了,性别比超过了110%。😰
🍒4.老龄化率
根据国际标准,65岁以上人口占比7-14%为轻度老龄化,14-20%为中度老龄化,21-40%为重度老龄化。👵
# 全国老龄化程度情况
df['Aging-rate'][df['province']=='全国']
31 13.5
Name: Aging-rate, dtype: float64
此次人口普查结果显示我国65岁以上人口占比已经达到13.5%,这意味着中国已经处于中度老龄化的边缘,面对老龄化程度不断上升,国家也在不断推进“三胎”政策来缓解老龄化程度。接下来我们来看看各地区的老龄化情况
'''
导入地图和数据
'''
m3=Map()
m3.add("65岁及以上人口比例", [list(z) for z in zip(df.province, df['Aging-rate'])], "china",is_map_symbol_show=False)
'''
自定义间隔
'''
pieces = [
'max': 7, 'label': '非老龄化',#有上限无下限
'min': 7, 'max': 14, 'label': '轻度老龄化',
'min': 14, 'max': 20, 'label': '中度老龄化',
'min': 20, 'label': '重度老龄化',
]
'''
全局设置
'''
m3.set_global_opts(
title_opts=opts.TitleOpts('第七次人口普查各地区老龄化程度分布图'),#设置图标题
visualmap_opts=opts.VisualMapOpts(is_piecewise=True,pieces=pieces))#热力图相关设置
m3.render_notebook()
 #pic_center
#pic_center
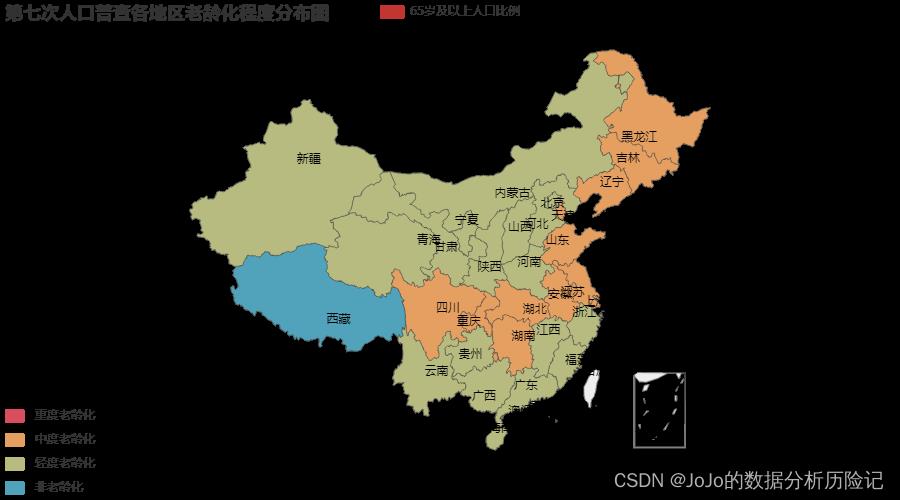
从上面这个热力图可以看出:
- 目前我国各地区均面临老龄化问题(西藏除外)👦
- 中部地区和和东北地区面临着中度老龄化问题🧓
- 目前我国还没有面临到重度老龄化的程度👵
🍑5.人均受教育年限
人均受教育年限是衡量一个地区文化水平的重要指标,在第七次人口普查数据中,统计了大专及以上、高中、初中和小学的人数,这里做如下处理后得到人均受教育年限
大专及以上:16年高中:12年初中:9年小学:6年
# 全国受教育情况
df['Edu-level'][df['province']=='全国']
31 8.88
Name: Edu-level, dtype: float64
可以看出我国平均受教育年限为8.88,这说明我国九年义务教育基本完成保障(上个世纪一部分人受教育程度较低)。下面我们来看一下各地区的受教育年限分布情况
'''
导入地图和数据
'''
m4=Map()
m4.add("人均教育年限", [list(z) for z in zip(df.province, df['Edu-level'])], "china",is_map_symbol_show=False)
'''
自定义间隔
'''
m4.set_series_opts(label_opts=opts.LabelOpts(is_show=True))
pieces = [
'max': 8, 'label': '8年以下',#有上限无下限
'min': 8, 'max': 9, 'label': '8-9年',
'min': 9, 'max': 10, 'label': '9-10年',
'min': 10, 'label': '12年以上'
]
'''
全局设置
'''
m4.set_global_opts(
title_opts=opts.TitleOpts('第七次人口普查各地区人均受教育年限分布图'),#设置图标题
visualmap_opts=opts.VisualMapOpts(is_piecewise=True,pieces=pieces))#热力图相关设置
m4.render_notebook()
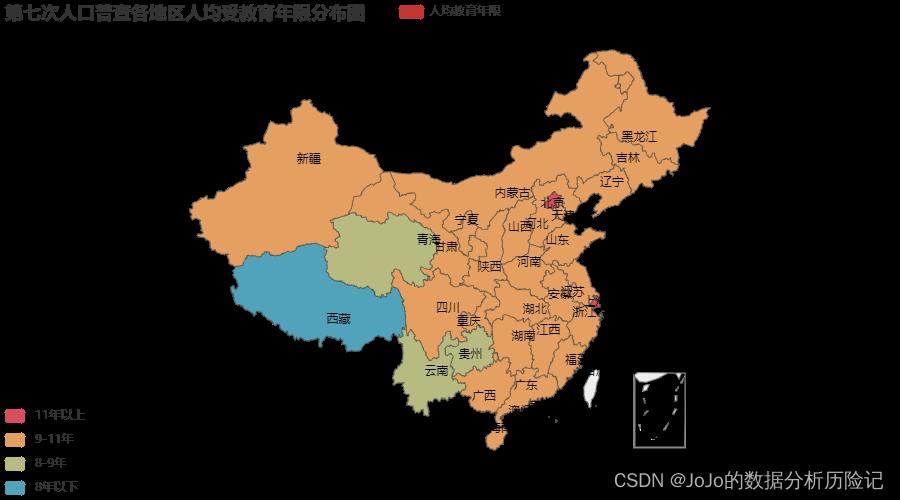
从上述热力图可以看出:
- 整体而言,随着大家对教育的重视,各个地区的受教育程度差距逐渐缩小。但
东部地区整体受教育程度要高于西部地区,这也和地区经济发展水平存在一定关系🙋♂️ 西藏、云南、贵州、青海几个地区的人均受教育年限较低。这也反应了这些地区的教育水平相较于其他地区有所落后🤷♀️- 而
北京、上海最高,平均受教育年限超过了11年,北京上海作为我国最发达的城市,教育水平也是全国最领先的地位,另一方面也反映了其对教育的重视程度👊
🍎6. 城镇化率
df['CR'][df['province']=='全国']
31 63.89
Name: CR, dtype: float64
根据第七次人口普查结果可以看出,我国城镇化率达到63.89%,新型城镇化和城乡融合发展工作取得新成效,农业转移人口市民化加快推进,城市群和都市圈承载能力得到增强。根据联合国的估测,世界发达国家的城市化率在2050年将达到86%,我国离这个数字还有一定的距离。下面我们来看看各地区城镇化率分布情况
'''
导入地图和数据
'''
m5=Map()
m5.add("城镇化(%)", [list(z) for z in zip(df.province, df['CR'])], "china",is_map_symbol_show=False)
'''
自定义间隔
'''
pieces = [
'max': 30, 'label': '30以下',#有上限无下限
'min': 30, 'max': 50, 'label': '30-50',
'min': 50, 'max': 60, 'label': '50-60',
'min': 60, 'max': 80, 'label': '60-80',
'min': 80, 'label': '80以上'
]
'''
全局设置
'''
m5.set_global_opts(
title_opts=opts.TitleOpts('第七次人口普查各地区城镇化率分布图'),#设置图标题
visualmap_opts=opts.VisualMapOpts(is_piecewise=True,pieces=pieces))#热力图相关设置
m5.render_notebook()
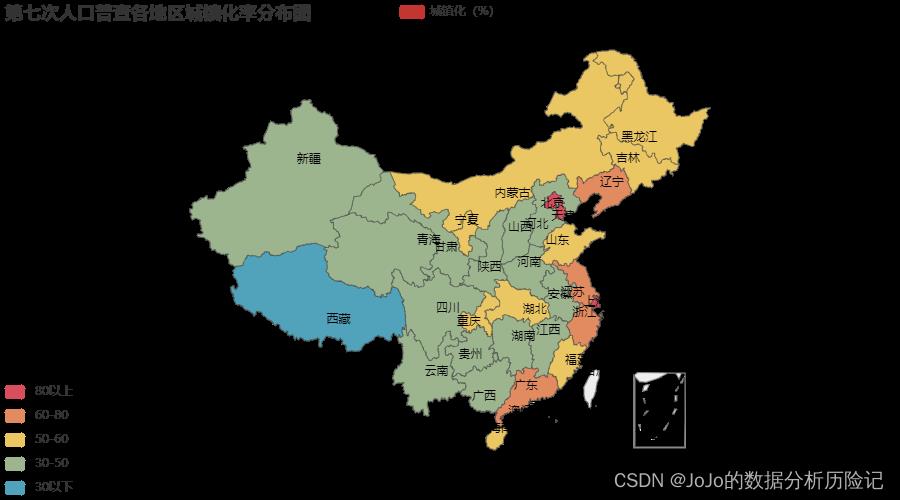
从热力图来看,城镇化率也基本呈现由东部沿海向西部递减的趋势。不同地区的城镇化率差距明显:
- 可以看出北京、天津、上海三个地区的城镇化率已经超过了
80% 西藏的城镇化率却不足30%
🥭7.GDP
上述是第七次人口普查的基本分析情况,下面我们来看看大家特别关注的一个指标,GDP
df['GDP'][df['province']=='全国']
31 1013567.0
Name: GDP, dtype: float64
可以看出2020年,我国GDP总额超过100万亿。这是一个里程碑的数字。那么各个地区的GDP分布情况如何呢,来看看你的家乡属于哪一档的。
'''
导入地图和数据
'''
m6=Map()
m6.add("GDP(亿元)", [list(z) for z in zip(df.province, df['GDP'])], "china",is_map_symbol_show=False)
'''
自定义间隔
'''
pieces = [
'max': 10000, 'label': '10000以下',#有上限无下限
'min': 10000, 'max': 20000, 'label': '10000-20000',
'min': 20000, 'max': 50000, 'label': '20000-50000',
'min': 50000, 'max': 100000, 'label': '50000-100000',
'min': 100000, 'label': '100000以上'
]
'''
全局设置
'''
m6.set_global_opts(
title_opts=opts.TitleOpts('第七次人口普查各地区生产总值分布图'),#设置图标题
visualmap_opts=opts.VisualMapOpts(is_piecewise=True,pieces=pieces))#热力图相关设置
m6.render_notebook()
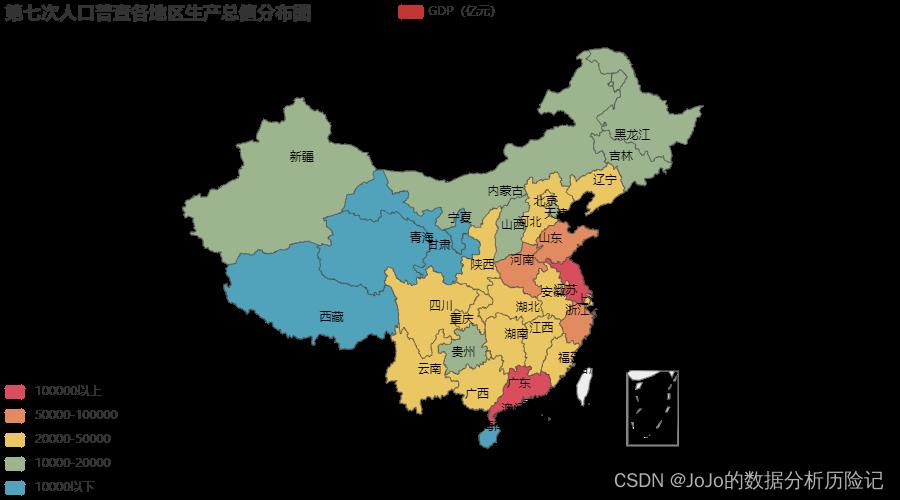
从上图发现:东南地区GDP要远高于其他地区,其次是中部地区。西部地区和东北地区GDP总值相对较低
- 其中
江苏省和广东省最高,均超过了10亿元 - 相反,海南作为自由贸易港建设试验区,GDP还不到万亿,在十四五期间,海南省力图超过万亿大关
🍍总结
文章对第七次人口普查数据进行了初步分析,主要是运用可视化技术,分析各地区的各项人口指标总体情况。并进行一定总结,后续将进一步做各个指标的结构分析、时间序列分析等,敬请期待!
本章的介绍到此介绍,如果文章对你有帮助,请多多点赞、收藏、评论、关注支持!!
以上是关于第七次人口普查数据可视化分析实战——基于pyecharts(含数据和源码)的主要内容,如果未能解决你的问题,请参考以下文章