JavaConcurrentHashMap
Posted 步尔斯特
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了JavaConcurrentHashMap相关的知识,希望对你有一定的参考价值。
ConcurrentHashMap在JDK8中与之前版本实现方式有很大不同。JDK8对ConcurrentHashMap内部的分段锁机制进行了优化和改进,采用了新的数据结构设计,使得其并发性能更加出色。
数据结构
JDK8中的ConcurrentHashMap内部数据结构主要由Node、TreeNode、ForwardingNode、CounterCell和Table等组成,其中:
Node:表示哈希表中的键值对节点,包含了键、值和下一个节点的引用;
TreeNode:继承自Node,表示红黑树中的节点,可以提高搜索效率;
ForwardingNode:表示转发节点,用于标记某个Segment已被扩容;
CounterCell:表示一个原子变量,用于解决CAS操作的冲突问题;
Table:表示哈希表的数组,其中每个元素都是一个链表或红黑树,在JDK8中,哈希表的默认容量为16,负载因子为0.75。
分段锁
在JDK8中,ConcurrentHashMap的分段锁被替换为了一种称为“Striped64”的新型锁实现。Striped64使用一种类似于CAS的技术来解决冲突,它将整个哈希表划分为一个个独立的小段,每个小段都有对应的锁(称为Stripe),不同的线程访问不同的小段时,可以并发执行。当多个线程同时访问同一个小段时,则会进行锁竞争。
Striped64的锁粒度更细,能够提高并发性能,并且不需要像分段锁那样在扩容时进行复杂的数据迁移操作。此外,JDK8还引入了一种新型的算法(TreeBin),用于优化红黑树的插入、删除和查找操作&#x
javaConcurrentHashMap遍历 --- 弱一致性的迭代器(Iterator)实现原理

1.概述
转载:ConcurrentHashMap遍历 — 弱一致性的迭代器(Iterator)实现原理
在 Java并发编程实战(进阶篇) 中分析了 Vector 在迭代过程中对容器进行修改会抛出 ConcurrentModificationException 异常,但在并发容器中还会出现这种情况吗?
在并发容器中并不会出现这种情况,这是因为,util包中的迭代器实现是fast-failed迭代器(就是一旦由修改就抛异常),而在current包中迭代器是弱一致性迭代器。
那么我们通过 ConcurrentHashMap 源码分析一下这种弱一致性迭代器的工作原理:
测试代码在主线程向容器中预先添加一些元素,然后另外启动一个线程不断向容器中添加元素,同时在主线程使用迭代器遍历容器。此代码运行的结果是,不会抛出 ConcurrentModificationException ,同时添加到hashMap中的部分元素也会被迭代器迭代输出。
1.1 案例1
测试代码:
/**
* 测试点:测试使用 ConcurrentHashMap 的时候,一边添加数据 一边遍历数据
* 添加的数据 能被遍历到吗
*
* 测试结果
*
* 不会抛出 ConcurrentModificationException ,同时添加到hashMap中的部分元素也会被迭代器迭代输出。
* 但是是乱序的
*
*
*/
public void concurrentAddAndItera()
ConcurrentHashMap<String, String> hashMap =
new ConcurrentHashMap<>();
for (int i = 0; i < 100; i++)
hashMap.put("" + i, "" + i);
Thread thread = new Thread(() ->
for (int i = 200; i < 10000000; i++)
hashMap.put("" + i, "" + i);
try
Thread.sleep(50);
catch (InterruptedException e)
e.printStackTrace();
);
thread.start();
Iterator<String> iterator = hashMap.keySet().iterator();
while (iterator.hasNext())
String key = (String) iterator.next();
System.out.println(key);
try
Thread.sleep(50);
catch (InterruptedException e)
e.printStackTrace();
1.2 案例2
可以看到确实不是全部遍历出来了。
/**
* 测试点:测试使用 ConcurrentHashMap 的时候,一边添加数据 一边遍历数据
* 添加的数据 能被遍历到吗
*
* 测试能否遍历出来,所有的新加的数据
*
* 测试结果
*
* 线程退出
* 没有了
* 最终剩余:7740
* 最终剩余:2261
*
* 可以看到有很多数据是没有遍历出来的
*/
public void concurrentAddAndItera1() throws Exception,InterruptedException
// 用于检测的hashMap
ConcurrentHashMap<String, String> checkHashMap = new ConcurrentHashMap<>();
for (int i = 0; i <= 10000; i++) checkHashMap.put("" + i, "" + i);
ConcurrentHashMap<String, String> hashMap = new ConcurrentHashMap<>();
for (int i = 0; i < 100; i++) hashMap.put("" + i, "" + i);
Thread thread = new Thread(() ->
for (int i = 101; i <= 9000; i++)
hashMap.put("" + i, "" + i);
sleep(10);
System.out.println("线程退出");
);
thread.start();
int count = 0;
Iterator<String> iterator = hashMap.keySet().iterator();
while (iterator.hasNext())
String key = (String) iterator.next();
// System.out.println(key);
checkHashMap.remove(key);
sleep(50);
count++;
if(!iterator.hasNext()) System.out.println("没有了");
System.out.println("最终剩余:"+checkHashMap.size());
System.out.println("最终剩余:"+count);
private void sleep(int i)
try
Thread.sleep(i);
catch (InterruptedException e)
e.printStackTrace();
2.源码分析
出现这种情况也是我们希望并发容器出现的结果,那么查看源码分析:
2.1 keySet
调用 hashMap.keySet() ,返回了一个KeySetView内部类的实例
public KeySetView<K,V> keySet()
KeySetView<K,V> ks;
return (ks = keySet) != null ? ks : (keySet = new KeySetView<K,V>(this, null));
keySet 是 ConcurrentHashMap 类中的私有变量,存储容器中的键的 Set 集合
2.2 KeySetView
KeySetView 静态内部类,重点分析 iterator 方法,返回 KeyIterator 迭代器实例
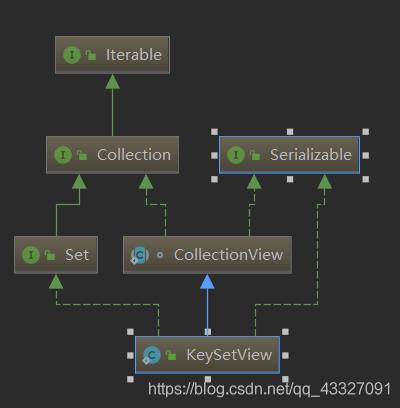
其实简单理解,KeySetView 相当于存放 ConcurrentHashMap 键的一个 Set 集合
public static class KeySetView<K,V> extends CollectionView<K,V,K>
implements Set<K>, java.io.Serializable
private static final long serialVersionUID = 7249069246763182397L;
private final V value;
KeySetView(ConcurrentHashMap<K,V> map, V value) // non-public
super(map);
this.value = value;
public Iterator<K> iterator()
Node<K,V>[] t;
ConcurrentHashMap<K,V> m = map;
int f = (t = m.table) == null ? 0 : t.length;
return new KeyIterator<K,V>(t, f, 0, f, m);
public Spliterator<K> spliterator()
Node<K,V>[] t;
ConcurrentHashMap<K,V> m = map;
long n = m.sumCount();
int f = (t = m.table) == null ? 0 : t.length;
return new KeySpliterator<K,V>(t, f, 0, f, n < 0L ? 0L : n);
map 是 CollectionView 类中成员变量,在调用 hashMap.keySet() 方法时,会将当前 ConcurrentHashMap 传入构造方法参数中(代码见上)。
2.3 KeyIterator
KeyIterator 类继承 BaseIterator 类,而 BaseIterator 类继承 Traverser 类

下面贴出 KeyIterator 类、BaseIterator 类、 Traverser 类代码,可以看出重要实现都在 Traverser 类中,后面主要关注 Traverser 类。
KeyIterator 类:
static final class KeyIterator<K,V> extends BaseIterator<K,V>
implements Iterator<K>, Enumeration<K>
KeyIterator(Node<K,V>[] tab, int index, int size, int limit,
ConcurrentHashMap<K,V> map)
super(tab, index, size, limit, map);
public final K next()
Node<K,V> p;
if ((p = next) == null)
throw new NoSuchElementException();
K k = p.key;
lastReturned = p;
advance();
return k;
public final K nextElement() return next();
KeyIterator 构造方法中调用 super(tab, index, size, limit, map) 父类 BaseIterator 构造方法。
2.4 BaseIterator
static class BaseIterator<K,V> extends Traverser<K,V>
final ConcurrentHashMap<K,V> map;
Node<K,V> lastReturned;
BaseIterator(Node<K,V>[] tab, int size, int index, int limit,
ConcurrentHashMap<K,V> map)
super(tab, size, index, limit);
this.map = map;
advance();
public final boolean hasNext() return next != null;
public final boolean hasMoreElements() return next != null;
public final void remove()
Node<K,V> p;
if ((p = lastReturned) == null)
throw new IllegalStateException();
lastReturned = null;
map.replaceNode(p.key, null, null);
BaseIterator 构造方法还是调用父类 Traverser 的构造方法,并且调用父类 advance 方法,先获取下一个遍历的有效结点。
2.5 Traverser
static class Traverser<K,V>
Node<K,V>[] tab; // current table; updated if resized
// 下一个要访问的entry
Node<K,V> next; // the next entry to use
// 发现forwardingNode时,stack保存当前栈顶 table 相关信息
// spare 按照 stack 的出栈顺序保存table,栈顶保存最后一个出栈的table
TableStack<K,V> stack, spare; // to save/restore on ForwardingNodes
// 下一个要访问的hash桶索引
int index; // index of bin to use next
// 当前正在访问的初始table的hash桶索引
int baseIndex; // current index of initial table
// 初始table的hash桶索引边界
int baseLimit; // index bound for initial table
// 初始table的长度
final int baseSize; // initial table size
/**
* 如果有可能,返回下一个有效节点,否则返回null。
*/
final Node<K,V> advance()
Node<K,V> e;
//获取Node链表的下一个元素e
if ((e = next) != null)
e = e.next;
for (;;)
Node<K,V>[] t; int i, n; // must use locals in checks
// e不为空,返回e
if (e != null)
return next = e;
// e为空,说明此链表已经遍历完成,准备遍历下一个hash桶
if (baseIndex >= baseLimit || (t = tab) == null ||
(n = t.length) <= (i = index) || i < 0)
// table 遍历完成,到达边界,返回null
return next = null;
// e = tabAt(t, i) 获取下一个hash桶对应的node链表的头节点
if ((e = tabAt(t, i)) != null && e.hash < 0)
// 扩容节点,说明此hash桶中的节点已经迁移到了nextTable
if (e instanceof ForwardingNode)
// 当前遍历 table 换做 nextTable
tab = ((ForwardingNode<K,V>)e).nextTable;
e = null;
// 保存当前table的遍历状态
pushState(t, i, n);
continue;
//红黑树
else if (e instanceof TreeBin)
e = ((TreeBin<K,V>)e).first;
else
e = null;
if (stack != null)
// 此时遍历的是迁移目标nextTable
// 尝试回退到源table,继续遍历源table中的节点
recoverState(n);
else if ((index = i + baseSize) >= n)
// 初始table的hash桶索引+1 ,即遍历下一个hash桶
index = ++baseIndex; // visit upper slots if present
/**
* 在遇到扩容节点时保存遍历状态。
*/
private void pushState(Node<K,V>[] t, int i, int n)
// s 指向上一个出栈的 table 状态
TableStack<K,V> s = spare; // reuse if possible
if (s != null)
// 如果存在上一个出栈 table 的引用
// 那么spare指向上上一个出栈 table
spare = s.next;
else
s = new TableStack<K,V>();
// 保存当前 table 的遍历状态
s.tab = t;
s.length = n;
s.index = i;
s.next = stack;
stack = s;
/**
* 可能会弹出遍历状态。
* @param n length of current table
*/
private void recoverState(int n)
TableStack<K,V> s; int len;
/**
(s = stack) != null :
stack不空,说明此时遍历的是nextTable
(index += (len = s.length)) >= n :
确保了按照index,index+table.length的顺序遍历nextTable,
条件成立表示nextTable已经遍历完毕
*/
// 如果进入循环,nextTable中的桶遍历完毕
while ((s = stack) != null
&& (index += (len = s.length)) >= n)
// 弹出table,获取table的遍历状态,开始遍历table中的桶
n = len;
index = s.index;
tab = s.tab;
s.tab = null;
// 下面是简单的链栈操作
// 弹出 table,存入到 spare中
TableStack<K,V> next = s.next;
s.next = spare; // save for reuse
stack = next;
spare = s;
// 和 advance 方法最后一段代码作用相似
// table的index桶链表遍历完,遍历下一个 hash桶
// index记录下一次访问索引(当前访问索引 baseIndex++)
if (s == null && (index += baseSize) >= n)
index = ++baseIndex;
在 Traverser 类中,最重要的就是 advance 方法,那么了解一下这个方法的整体思路(其中的 table 表示源table,nextTable 表示扩容之后的 table):
当迭代器创建或者调用 next 方法是,都会调用 Traverser 中的 advance 方法来获取下一个有效结点。这个方法会根据当前 table 中 index 桶的状态来返回有效结点,如果桶是处于正常状态,那么就返回桶中的结点;如果 index 桶处于扩容状态,那么就根据 nextTable 中的 index 和 index+table.length 桶的状态来返回有效结点。在 nextTable 中访问完目标结点之后,返回到 table 再次向 ++index 桶的状态进行判断并返回,直到 table 中的桶被遍历完。
那么知道了大致的实现过程,下面使用图解的方式再次理解,加深印象:
1.当遍历到 pwd 结点的时候,说明正在扩容,此结点的数据已经被迁移到 nextTable
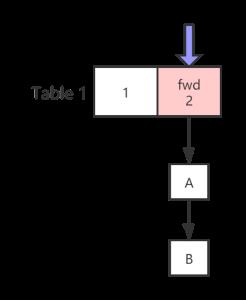
2.将 table1 的遍历状态压栈stack,遍历迁移到 nextTable(table2)的 hash 桶
-
由于扩容时,会将 table(table1) 中索引为 index 桶,迁移到 nextTable(table2) 中索引为index和索引为 index+table.length 的2个桶中。因此在 nextTable(table2) 中的遍历顺序为:index,index+table.length (table2中的桶2,和桶4 )
-
如果 桶2 和 桶4 都是正常的节点,遍历完 桶2 和 桶4 后,就会将 stack 中的table(tab1) 弹出,继续遍历 table(tab1) 中的桶
-
桶2 是 fwd 节点,说明 table2 也被扩容,此节点的 node 被迁移到了 nextTable(table3) 中
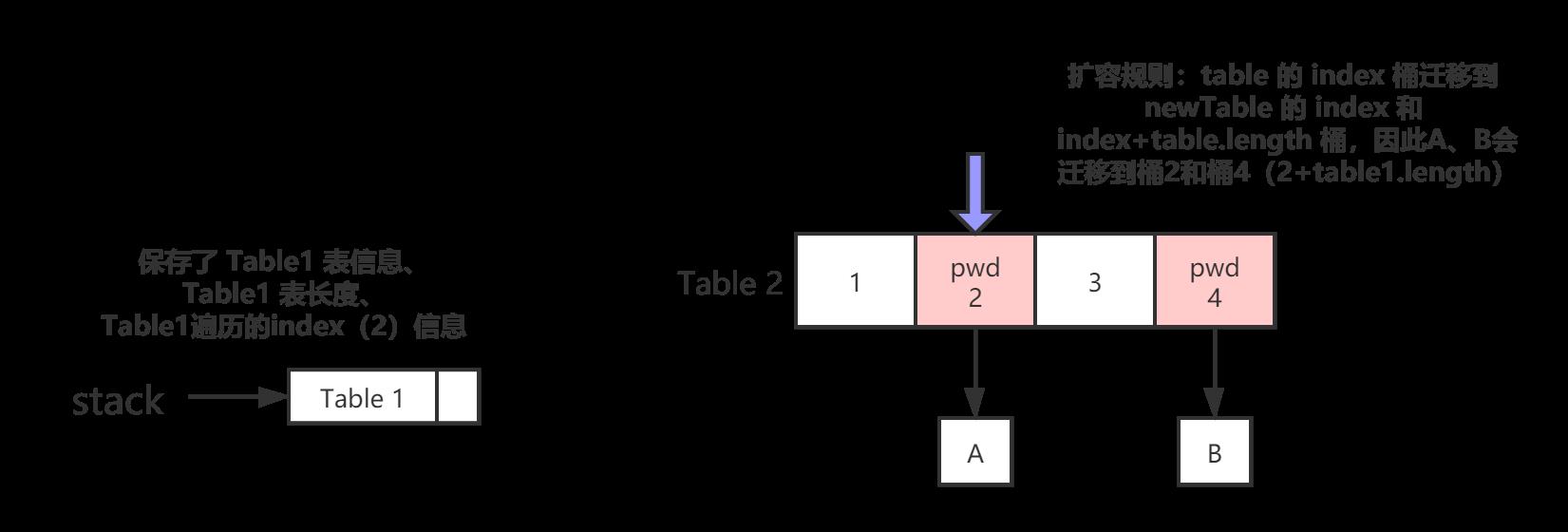
3.将 table2 的遍历状态压栈stack,遍历迁移到 nextTable(table3)的 hash 桶
因为在 table2 中 桶2 中只有 A。根据扩容规则:在 table3 中,A 就可能在 桶2 中,也可能在 桶6 (2+table2.length)中
根据扩容迁移规则:先遍历 index = 2 的 hash 桶
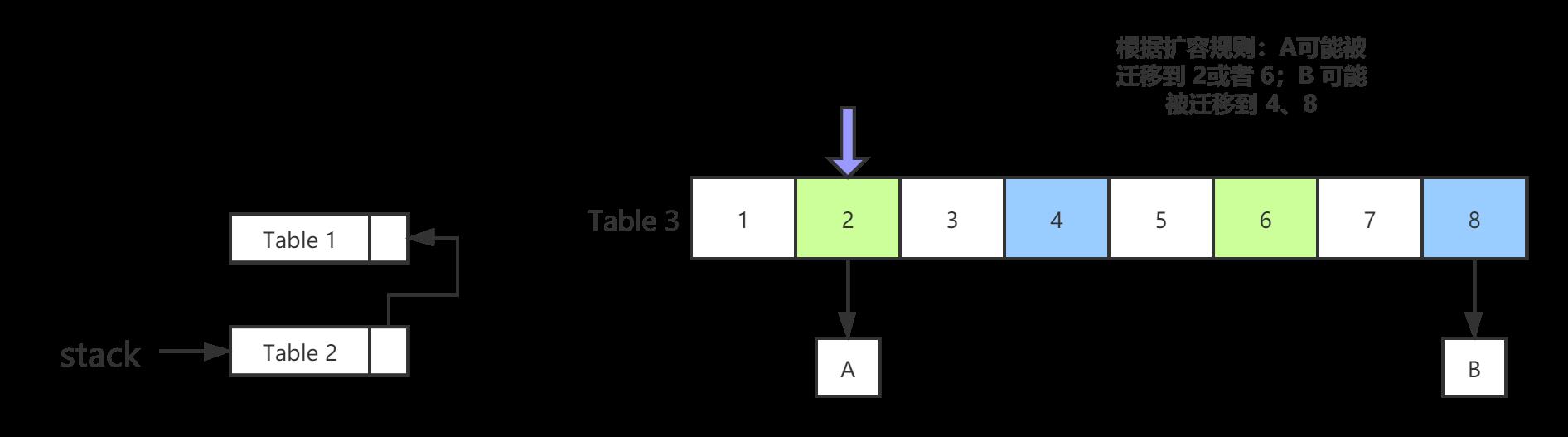
接着遍历 index = 6 的 hash 桶(为什么要遍历 桶6 可见源码 recoverState 方法)

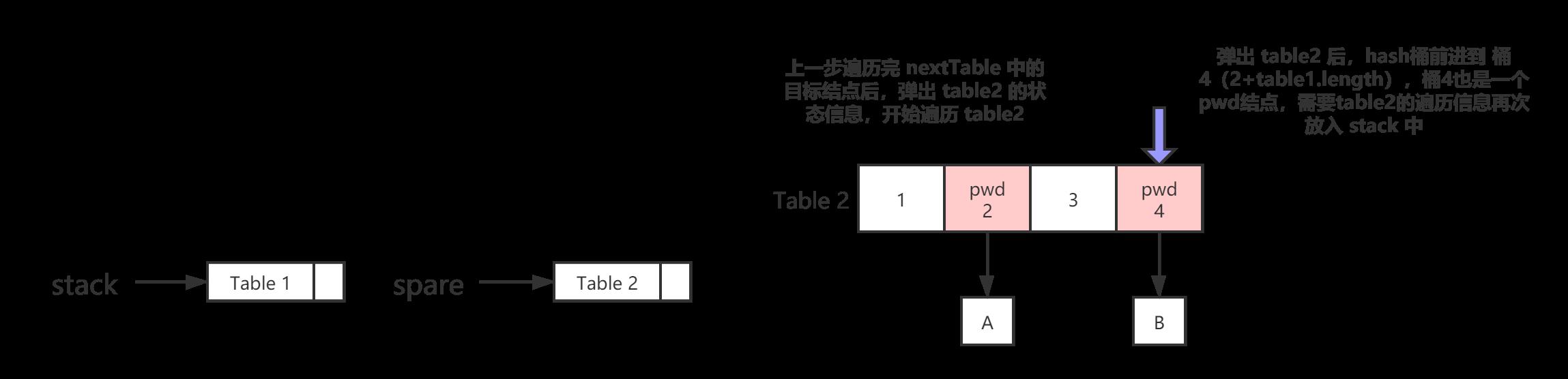
4.遍历完 table3 后,table2 出栈,根据遍历状态信息,继续遍历 table2
table2 弹出栈stack,进入了栈 spare(对象重利用,减少内存开销)
table2 记录当前 index = 2,那么接着遍历下一个 index=4(2+table1.length) 的 hash 桶
桶4 是一个 pws 结点,那么 table2 压栈stack(index = 4),直接复用 spare 指向的 table2 引用
5.遍历 nextTable(table3)中的 桶4、桶8(4+table2.length)
