java集合类
Posted ~无关风月~
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了java集合类相关的知识,希望对你有一定的参考价值。

List接口的实现类

ArrayList
非线程安全,同样使用Fail-Fast机制
允许包括 null 在内的所有元素
其内部实现也是数组。删除元素会将后边位置的元素向前移动一位,最后一个置为null。当被添加的元素超出数组的容纳极限时,ArrayList会对内部数组进行一次“扩容”,从而可以添加新的元素,每次数组容量的增长大约是其原容量的1.5倍, 数组进行扩容时,会将老数组中的元素重新拷贝一份到新的数组中。 应用程序也可以使用ensureCapacity操作来增加ArrayList实例的容量,以减少递增式再分配的数量。
transient Object[] elementData;
transient 用来表示一个域不是该对象序行化的一部分,但是ArrayList又是可序行化的类,elementData 是 ArrayList具体存放元素的成员,为什么用 transient 修饰?
ArrayList 在序列化的时候会调用 writeObject,直接将 size 和 element写入 ObjectOutputStream;反序列化时调用 readObject,从 ObjectInputStream获取 size 和 element,再恢复到 elementData。为什么不直接用 elementData 来序列化,而采用上诉的方式来实现序列化呢?原因在于 elementData 是一个缓存数组,它通常会预留一些容量,等容量不足时再扩充容量,那么有些空间可能就没有实际存储元素,采用上诉的方式来实现序列化时,就可以保证只序列化实际存储的那些元素,而不是整个数组,从而节省空间和时间。
LinkedList
LinkedList 是非同步的。
底层的数据结构是基于双向循环链表。
按下标访问元素—get(i)/set(i,e) 要悲剧的遍历链表将指针移动到位(如果i>数组大小的一半,会从末尾移起)。节点访问的复杂度由O(n)变为O(n/2)。
插入、删除元素时修改前后节点的指针即可,但还是要遍历部分链表的指针才能移动到下标所指的位置,只有在链表两头的操作—add(), addFirst(),removeLast() 或 用iterator()上的 remove()能省掉指针的移动。
public class LinkedList<E>
extends AbstractSequentialList<E>
implements List<E>, Deque<E>, Cloneable, java.io.Serializable
transient int size = 0;
/**
* Pointer to first node.
* Invariant: (first == null && last == null) ||
* (first.prev == null && first.item != null)
*/
transient Node<E> first;
/**
* Pointer to last node.
* Invariant: (first == null && last == null) ||
* (last.next == null && last.item != null)
*/
transient Node<E> last;
...
LinkedList 是一个继承于AbstractSequentialList的 双向循环链表。它也可以被当作栈、队列 或 双端队列 进行操作。
访问和操作链表头尾元素块,随机访问慢,插入删除不需要移动元素,快。
LinkedList 实现 List 接口,能对它进行队列操作。
queue.peek(); 获取头元素,不移除
queue.poll(); 获取头元素,移除
LinkedList 实现 Deque 接口,即能将LinkedList当作双端队列使用。
deque.getFirst();
deque.getLast();
deque.pollLast();
LinkedList 实现了Cloneable接口,即覆盖了函数clone(),能克隆。
LinkedList 实现 java.io.Serializable接口,这意味着 LinkedList支持序列化,能通过序列化去传输。
Vector
Vector是一个线程安全的列表,采用数组实现。线程安全的实现方式是对所有操作都加上了synchronized关键字,这种方式严重影响效率,因此,不再推荐使用Vector。
Set接口的实现类

HashSet
插入性能高,散列法机制,不保证顺序
使用null元素
基于HashMap实现的,HashSet底层使用HashMap来保存所有元素
HashSet中的元素,只是存放在了底层HashMap的key上,value使用一个static final的Object对象标识
正确重写其equals和hashCode方法,以保证放入的对象的唯一性
LinkedHashSet
此链接列表定义了迭代顺序,该迭代顺序可为插入顺序或是访问顺序。
线程不安全
继承自HashSet
基于LinkedHashMap来实现,哈希表和链接列表实现
TreeSet
TreeSet 底层基于 TreeMap实现。
TreeSet 添加元素的时候,如果元素本身不具备自然顺序的特性,那么该元素所属的类必须要实现Comparable接口,把元素的比较规则定义在compareTo(T o)方法上(自然排序),或必须要在创建TreeSet的时候传入一个比较器(定制排序)。
Map接口的实现类

HashMap
快速查找
基于哈希表的 Map 接口的实现
允许使用 null 值和 null 键
不保证映射的顺序

数组+链表+红黑树(JDK1.8增加了红黑树部分)实现的
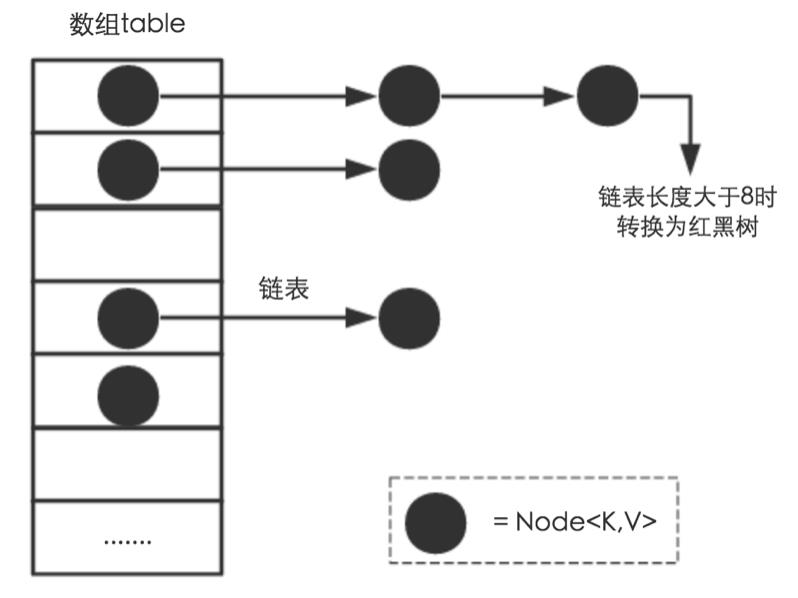
Node[] table,即哈希桶数组
Node这个内部类的属性有 hash值,key,value和指向下一个Node结点的next指针。
/**
* Basic hash bin node, used for most entries. (See below for
* TreeNode subclass, and in LinkedHashMap for its Entry subclass.)
*/
static class Node<K,V> implements Map.Entry<K,V>
final int hash;
final K key;
V value;
Node<K,V> next;
HashMap就是使用哈希表来存储的,采用了链地址法解决冲突。就是数组加链表的结合。
在每个数组元素上都有一个链表结构,当数据被Hash后,与数组长度取模,得到数组下标,把数据放在对应下标元素的链表上。JDK1.7之前是直接将hash冲突的Node插入链表头,如果hash冲突较多,链表过长,会严重影响HashMap的性能。
在JDK1.8版本中,对数据结构做了进一步的优化,引入了红黑树。而当链表长度太长(默认超过8)时,链表就转换为红黑树,利用红黑树快速增删改查的特点提高HashMap的性能。
HashMap有 threshold,loadFactor,modCount,size 等属性。
transient Node<K,V>[] table;
transient Set<Map.Entry<K,V>> entrySet;
transient int size;
transient int modCount;
int threshold;
final float loadFactor;
public HashMap(int initialCapacity, float loadFactor)...
public HashMap(int initialCapacity)...
Node[] table的初始化长度length(默认值是16),Load factor为负载因子(默认值是0.75),threshold = length * Load factor,数据量超过threshold 就重新 2倍resize(扩容)
size这个字段其实就是HashMap中实际存在的键值对数量。
modCount字段主要用来记录HashMap内部结构发生变化的次数,主要用于迭代的快速失败,(添加新元素,某个key对应的value值被覆盖不属于结构变化)。
Fail-Fast 机制:HashMap不是线程安全的,如果在使用迭代器的过程中有其他线程修改了map,那么将抛出ConcurrentModificationException。通过 modCount域,记录修改的次数。迭代器初始化过程中会将这个值赋给迭代器的expectedModCount, 在迭代过程中,判断modCount跟expectedModCount是否相等,如果不相等就表示已经有其他线程修改了Map,就抛出异常。
为什么HashMap底层数组的长度总是2的n次方,如果指定大小不符合条件时,capacity 进行移位运算,到刚好大于指定大小的那个2的N次幂的数?
1、当length总是2的n次方时,h & (length-1)运算等价于对length取模,也就是h % length,用位运算代替取模运算,用空间换了时间,速度更快。
2、扩容为原来2倍时,需要使用一个新的数组代替已有的容量小的数组,不需要像JDK1.7的实现那样重新计算hash,只需要看看原来的hash值对应新数组长度减一的二进制新增的那一位上是1还是0就好了,是0的话索引没变,是1的话索引变成对原位置乘2。
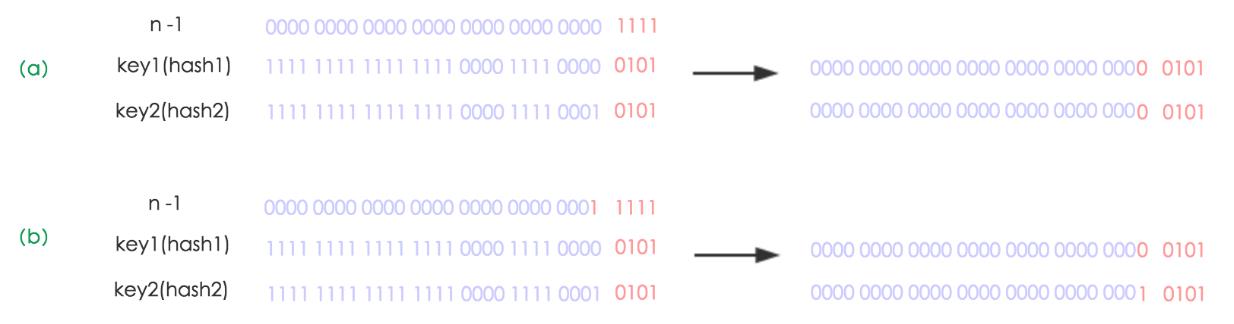
扩容是一个特别耗性能的操作,所以当程序员在使用HashMap的时候,估算map的大小,初始化的时候给一个大致的数值,避免map进行频繁的扩容。
LinkedHashMap
Hashtable
ConcurrentHashMap
TreeMap
以上是关于java集合类的主要内容,如果未能解决你的问题,请参考以下文章