clickhouse 列式存储数据库介绍
Posted OkidoGreen
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了clickhouse 列式存储数据库介绍相关的知识,希望对你有一定的参考价值。
ClickHouse介绍
- ClickHouse来自哪里?
俄罗斯最大的搜索公司Yandex,在clickhouse的配置文件中我们也会看到yandex的影子。
- ClickHouse是什么?
ClickHouse是一个开源的列式数据库(DBMS),主要用于在线分析处理查询(OLAP),于2016年开源,采用C++开发。凭借优秀的性能,市场反应非常热烈。
- 什么是列式数据库?
相对行式数据库,像mysql、Oracle、SqlServer等都是行式存储,是把同一行的数据放到相邻同一数据块种,而列式存储是把同一列的数据放到相邻同一数据块种,这样在进行计算类查询时,可以大大减少IO消耗,返回结果更快,采用列式存储后在进行数据记录写入的时候会麻烦一些。
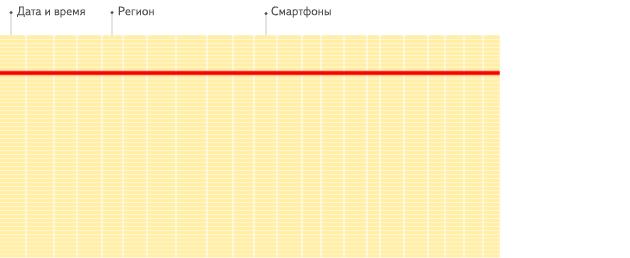
行式存储:
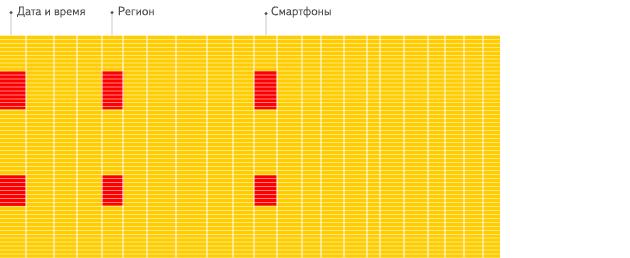
列式存储:
性能测试
- ClickHouse: New Open Source Columnar Database by Percona
- Column Store Database Benchmarks by Percona
- 1.1 Billion Taxi Rides on ClickHouse & an Intel Core i5 by Mark Litwintschik
- 1.1 Billion Taxi Rides: 108-core ClickHouse Cluster by Mark Litwintschik
- ClickHouse vs Amazon RedShift Benchmark by Altinity
- Geospatial processing with Clickhouse by Carto
- ClickHouse and Vertica comparison by zhtsh (machine translation from Chinese)
- ClickHouse and InfiniDB comparison by RamboLau (machine translation from Chinese)
主要特性
- 丰富的表引擎,主要用到以下表引擎
MergeTree引擎家族:ReplicatedMergeTree
Distributed分布式引擎
- 矢量计算:减少调用次数,适用现代CPU的扩展指令集支持SIMD
- 丰富的SQL和函数
- 强有力的数据压缩:相对mysql压缩10倍
- 分布式处理
- 列式存储:降低io消耗
- 数据复制完整性
- 集群式管理
- 可直接读取MYSQL数据
待完善功能:
- 不支持二级索引
- 不支持事物:不适合OLTP
- 低并发:不适合高QPS的KV存储
- 对长文本支持差:建议用ES
架构:采用分布式+高可用集群
- Clickhouse分布式通过配置文件来实现,同一集群配置多个shard,每个shard都配置相同的配置文件;而高可用需要借助zookeeper来实现,表采用ReplicatedMergeTree引擎,共享同一个ZK路径的表,会相互同步数据;
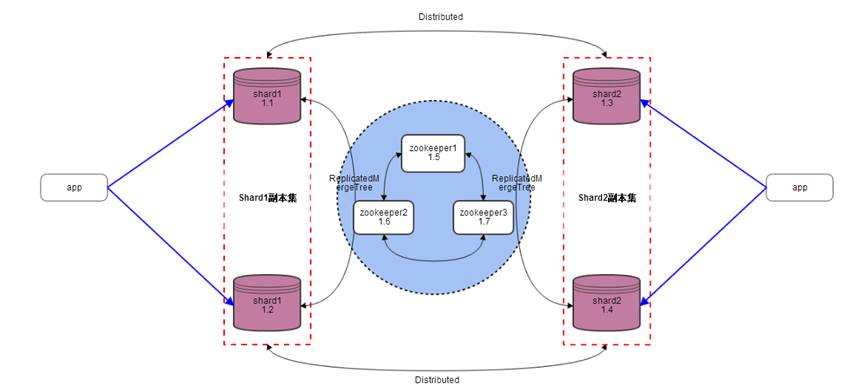
- ReplicatedMergeTree,复制引擎,基于MergeTree,实现数据复制,即高可用;
- Distributed,分布式引擎,本身不存储数据,将数据分发汇总;
- app不管连接哪台shard,通过访问Distributed引擎表,读取的数据都是一致的。
官方网站:
https://clickhouse.yandex/docs/en
以上是关于clickhouse 列式存储数据库介绍的主要内容,如果未能解决你的问题,请参考以下文章