python语法教程——def()函数
Posted Anfies
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python语法教程——def()函数相关的知识,希望对你有一定的参考价值。
什么是函数?
我们在编程的过程中往往会发现,实现某一功能的代码块会被频繁地使用。如果每次使用这段代码都得复制粘贴,这会使得代码冗长而又臃肿,增大了代码的阅读难度。为了方便我们实现对代码块的复用,人们提出了函数功能。
如何定义函数?
函数的定义以关键字def开头,后面接函数名称和圆括号。
括号中放入函数需要的参数。
通过冒号和缩进控制函数内容。
函数的结构如下所示:
def 函数名(参数):
函数体
定义第一个函数
在学习一门语言时,我们最先学会的是如何输出Hello world。那么,我们的第一个函数也就从最简单的输出Hello world开始。
def hello():
print('Hello world!')
hello()
输出:
Hello world!
可以看到,我们调用了我们定义的hello函数,函数执行了其中的print语句。
什么是形参实参,什么是返回值?
这里我们定义一个可以计算两个数之和的函数add1,可以先运行一下看看。
def add1(num1, num2):
result = num1 + num2
return result
x1, x2 = 1, 2
y = add1(x1, x2)
print(y)
输出:
3
函数完美地计算出了1加2的值。
同刚才的Hello world函数相比,我在add函数中加入了num1、num2和return。其运作原理如下:
在调用add函数时,我们将x1,x2传入add中,由num1和num2分别接收了来自x1和x2的值,将num1和num2的数值相加后传给result,最后函数输出result的值给y,我们打印出y的值,就是3。
那么这里面的num1、num2就是形参,x1、x2就是实参,return result就是函数的返回语句,其返回的就是result的值,所以result就是返回值。
由此可见,形参就是我们在函数定义过程中定义在括号内的参数。实参就是我们输入函数的参数,返回值就是return后面的语句的计算值。
我比较喜欢通过数学中对函数的定义来理解编程语言中的函数。在数学中函数的定义式是y = f(x)那么这里x就是我们传入的参数,f就是函数体,用来对x进行计算,计算结果y就是函数的返回值。
函数参数的一些额外用法
还是刚才的add1函数,但是我们参数的赋值方式不一样了:
def add1(num1, num2):
result = num1 + num2
return result
y = add1(num1=1, num2=2)
print(y)
输出:
3
我们也可以对函数的形参赋予初始值
def add2(num1=1, num2=1):
result = num1 + num2
return result
y = add2()
print(y)
输出:
2
在形参赋初值的情况下,我们又可以如下进行传参。
def add2(num1=1, num2=2):
result = num1 + num2
return result
y = add2(3)
print(y)
输出:
5
可见3按顺序替换了add2函数的第一个形参,导致num1变为3,result变为5。
那如果我们想不按顺序更改其中的参数呢?
def add2(num1=1, num2=2):
result = num1 + num2
return result
y = add2(num2=3)
print(y)
输出:
4
可以看到,3并没有按顺序替换add2函数的第一个参数,而是传给了num2,这样result的值就是4了。
任意传递实参
当我们传入函数中的参数不固定怎么办呢?
def save(*temp):
return temp
y = save('1', 2, 'abc', True)
print(y)
输出:
('1', 2, 'abc', True)
可以看到,如果形参加上一个星号,它就相当于一个元组,我们传入的参数将以元组的形式保存。
def student(**temp):
return temp
y = student(name='老王', age=20, high=180, is_student=True)
print(y)
输出:
'name': '老王', 'age': 20, 'high': 180, 'is_student': True
当形参前带有两个星号时,它就相当于一个字典了。
附加
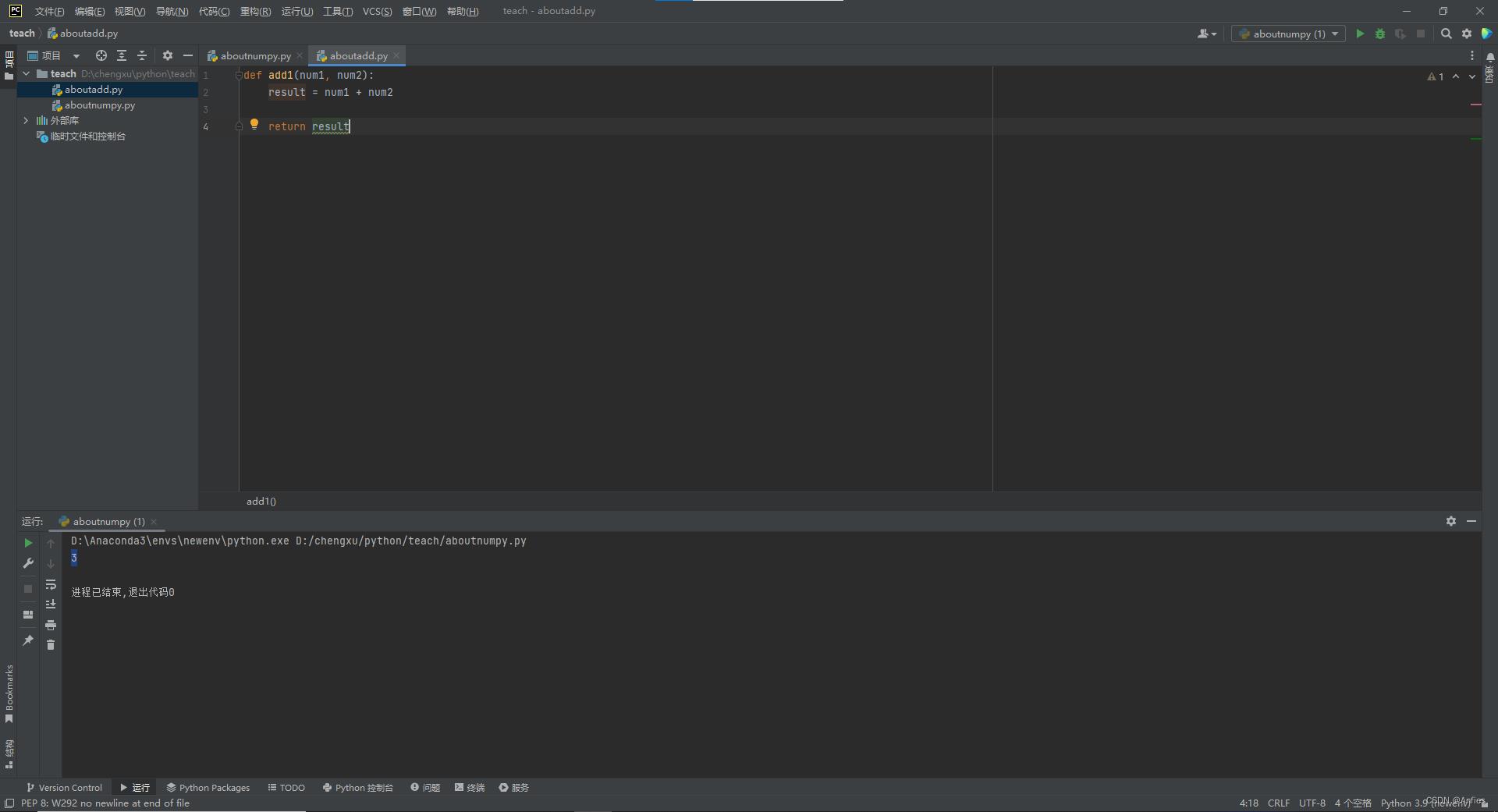
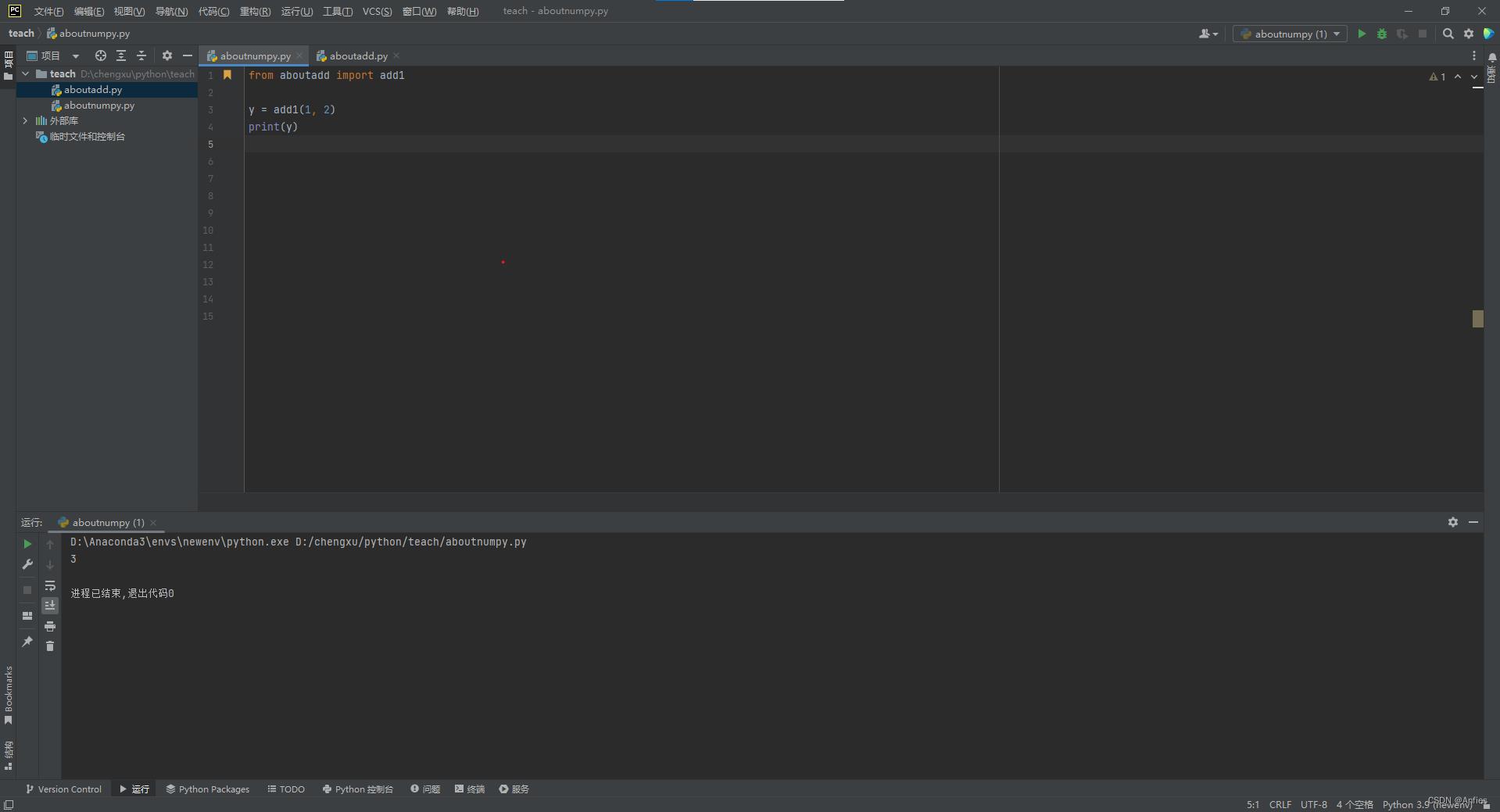
函数也可以写在其他文件里用来调用。这里我们还是用一开始的add1函数。
from aboutadd import add1
y = add1(1, 2)
print(y)
输出:
3
通过图片可以看到文件间的关系。

python入门到放弃-函数专题
一、函数的定义
函数是对代码块和功能的封装和定义
#函数的语法:def是define的意思,定义
最基本的语法: def 函数名(): 函数体 函数名() #调用函数
带有参数的语法 def 函数名(形参列表): 函数体(代码块,return) 函数名(实参列表) :调用
#例子:函数执行过程
# def wan(): #定义函数 # print("今天一起去玩") # print("去哪里玩呢") # print("我不知道") # wan() #调用函数 ‘‘‘讲解执行的过程 1.定义函数wan() 2.调用函数wan() 3.准备开始执行函数 4.打印,今天一起去玩 5.打印,去哪里完 6.打印,我不知道 7.函数执行完毕,本次调用完毕,wan()函数调用完毕 ‘‘‘
二.return返回值的相关操作


return:在函数执行的时候,如果遇到return,则直接返回,和while循环中break一样 1、如果函数什么都不写,不写return,没有返回值,得到的是Nano 2、在函数中间或者末尾写return,返回的是None 3、在函数中写 return 值,返回的是一个值 4、在函数中有返回多个返回值,return 值1、值2、值3... 返回接收到的是元组 #例子: #1、函数什么都不写,不写return,返回的是None def wan(): print("今天一起去玩") print("去哪里玩呢") print("我不知道") ret = wan() print(ret) #None #2、在函数中间或者末尾写return,返回的是None def wan(): print("今天一起去玩") return print("去哪里玩呢") print("我不知道") ret = wan() print(ret) #在执行完第一个print的时候就返回None,就结束了 #3、在函数中写一个return 值,返回的是一个值 def wan(): print("今天一起去玩") return "锅盖" print("去哪里玩呢") print("我不知道") ret = wan() print(ret) #今天一起去玩 #锅盖 #会看到返回锅盖就结束了 #4、函数中有返回多个返回值,那么返回的是一个元组 def wan(): print("今天一起去玩") return "锅盖","番薯","大块" print("去哪里玩呢") print("我不知道") ret = wan() print(ret) ##(‘锅盖‘, ‘番薯‘, ‘大块‘)
三.函数的参数
函数在调用的时候指定具体的一个变量的值,就是参数
#参数包括:形参,实参,传参
形参:函数声明的位置的变量
实参:函数调用的时候给的具体的值
传参:把实参交给形参的过程
#相关参数具体位置例子
#形参和实参的位置 # def wan(形参): #在函数声明的位置的变量就是形参 # print(好玩) # # wan(实参) :#在函数调用的地方给的具体的值就是实参 #例子 # def wan(what): # print("手机") # print("去哪里"+what) # wan("广西") #在调用wan的时候给what一个值,然后执行函数体
#实参的相关操作
#包括 1.位置参数:按照形参的参数位置,给形参传值 2.关键字参数:按照形参的名字给形参传值 3.混合参数:即用位置参数,也用关键字参数
#实参操作的例子:
# 1、位置参数,按照形参的位置,给形参传值 #例子 # def chi(moning,after,night): # print(moning,after,night) # chi("玉米饺","米饭","面条") #玉米饺 米饭 面条 #2.关键字参数: 按照形参的名字给形参传值 # def chi(moning,after,night): # # print(moning,after,night) # # chi(after="米饭",moning="饺子",night="面条") #饺子 米饭 面条 # 3.混合参数:即用位置参数,也用关键字参数 # def chi(moning,after,night): # print(moning,after,night) # chi("饺子","米饭",night="面条") #饺子 米饭 面条 #注意: #顺序位置:要先写位置后再写关键字,要不然会报错 #例子 # chi("饺子",night="面条","米饭") #会报红色 #SyntaxError: positional argument follows keyword argument #语法错误:关键字参数后面跟了位置参数
#形参的相关操作
#包括 1.位置参数 2.默认值参数,要先写位置参数之后才能写默认值参数 3.动态参数
包括:位置参数动态传参 *args,关键字参数动态传参**kwargs
无敌传参方法:def func(*args,**kwargs):
#形参操作的例子:
#1.位置参数,按照位置来进行赋值 # def chi(moning,after,night): # print(moning) # print(after) # print(night) # chi("饺子","米饭","面条") #2.默认值参数 #例子:比如一个班上要录入学生信息,有大部分都是男生,就可以设置一个默认值是男 # def stu_inf(name,age,sex=‘男‘): # print("录入学生信息") # print(name,age,sex) # print("录入完毕") # stu_inf("蒋小鱼",18) # stu_inf("张冲",22) # stu_inf("沈搁",22,sex="女") #如果不想使用默认值也可以自己设定 #注意点: #必须先声明位置参数,才能声明默认值参数,否则会有问题 #例子 # def stu_inf(name,sex=‘男‘,age): #很明显这种写法是错误的 #3.位置参数的动态传参 # * 在这里表示接收位置参数的动态传参,接收到的是元组 # def chi(*foot): #参数名是food, * 表示动态传参 # print(foot) # chi("米饭","面条","饺子") #(‘米饭‘, ‘面条‘, ‘饺子‘) # chi("馒头") # chi() # def chi(name,*food,location="河北"): # print(location) # print(name+"要吃",food) # chi("张三","饺子","面条") #要注意参数的书写顺序 #顺序: 位置参数 -> 位置参数动态传参 -> 默认值参数 #错误写法 # def chi(name,location="河北",*food): # print(location) # print(name+"要吃",food) # chi("张三","饺子","面条") #这样写的话饺子就成了默认值 # 饺子 # 张三要吃 (‘面条‘,) ‘‘‘ #关键字的动态传参 ‘‘‘ # def chi(**food): # print(food) # # chi(good_food="大米",no_good_food="面条",dirnk="水") #前面得是变量,如果写数字或者字符串这种就会报错,如:"大海" = "虾" # def chi(*food2,**food): #这样是无敌传参 # print(food) # # chi(good_food="大米",no_good_food="面条",dirnk="水") #提示: # 位置参数,*args(位置关键字动态传参) 默认值参数 **kwargs 关键字动态传参 # 以上参数可以任意搭配使用,但是要注意顺序问题,要不然会有问题
#参数的位置顺序排列
位置参数->位置参数动态传参*args->默认值参数->关键字参数动态传参**kwargs
四.函数的注释
在函数里面用三个单引号或三个双引号引起来的就是函数的注释
#例子:写好注释让别人能看明白,能省去很多事情
# def chi(food,drink): # """ # 这里是函数的注释,先写一下当前这个函数是干什么的,不如我这个函数就是一个吃 # :param food: 参数food是什么意思 # :param drink: 参数drink是什么意思 # :return: 返回的是什么东西 # """ # print(food,drink) # return "good" # print(chi.__doc__) #document 文档 # print(str.__doc__) #查看字符串的文档注释
#关于参数的聚合和打散
#形参:聚合 # def func(*food): # print(food) # lst = ["大麻花","饺子","面条","土豆"] # func(lst) #这样调用的话是一个列表在里面的 # # 实参: 打散 # func(lst[0],lst[1],lst[2],lst[3]) #将上面的大三, 把list,tuple,set,str进行迭代打散 # func(*lst) #上面的打散写不方便,写*号更方便简单 # #但是上面的打散都是一个一个的,那么字典呢? #字典的打散方式 #聚合成关键字参数 # def func(**kwargs): # print(kwargs) # dic = {"name":"sir","age":"18"} # func(**dic) #打散成关键字参数
五.函数名
函数名也是一个变量,但是一个特殊的变量,与括号配合可以执行函数的变量
#函数名的相关操作
1.函数名可以赋值给其他变量 2.函数名可以作为参数列表中的元素进行存储,作容器类的元素 3.函数名可以作为参数传递给函数 4.函数名可以作为函数的返回值
#函数名相关操作例子:
# 1、函数名的内存地址 # def func(): # print("哈哈") # print(func) #因为还没有进行调用 #结果:<function func at 0x0000025A9344C1E0> # 2.函数名可以赋值给其他变量 # def func(): # print("哈哈") # # print(func) # a = func #把函数当成一个变量赋值给另一个变量 # a() #函数调用func() #打印哈哈 # 3.函数名可以当作容器类的元素 # def func1(): # print("哈哈") # # def func2(): # print("哈哈") # # def func3(): # print("哈哈") # # lst = [func1,func2,func3] # for i in lst: # i() # 4.函数名可以作为参数传递给函数 # def my(): # print("我是my") # # def proxy(fn): # fn() #执行传递过来的my # proxy(my) #过程:首先调用proxy函数,将my参数传递给proxy,然后变成proxy(my),然后调用my() #接着打印"我是my" #函数名可以作为参数进行传递(多层嵌套) # def func(): # print("我是func") # def func1(): # print("我是func1") # # def func2(fn): # print("我是func2") # fn() # func2(func1) #结果:我是func2,我是func1 #解释:首先执行func2函数,然后有个实参传递给形参,打印我是func2,然后执行func1()函数打印我是func1 #例二: # def func(): # print("我是func") # def func1(): # print("我是func1") # # def func2(fn,gn): # print("我是func2") # fn() # gn() # print("hahaha") # func2(func1,func) # 我是func2 # 我是func1 # 我是func # hahaha #解释:首先执行func2函数,有两个实参传递给形参,打印我是func2,接着执行func1函数打印我是func1, #接着执行funch函数打印我是func,在打印hahaha # 5.函数名可以作为函数的返回值 # def func(): # print("我是func") # a = 10 # 变量 # def inner(): # print("我是inner") # return inner #得出inner,然后使用inner()调用 # print(func) # ret = func() # ret() # func()() #先运行func() 然后再返回值上加()
六.函数的嵌套
1.主要遇见()就是函数被调用了,如果没有()就不是函数的调用
2.函数的执行顺序
#函数嵌套例子
#例子: # def fun(): # print(111) # def fun1(): # print(222) # fun() # fun1() # print(111) #结果是222,111,111 #解释:定义函数,然后最先调用的是fun1这个函数,所以先的打印fun1中的内容, #接着再调用fun()函数,再打印111,接着再打印111 #例二 # def fun1(): # print("蒋小雨") # def fun2(): # print("鲁炎") # def fun3(): # print("张冲") # def fun4(): # print("龙大队") # fun2() # fun4() # fun3() # def fun5(): # print("二哈") # fun1() # fun5() #二哈,蒋小雨,张冲,龙大队,鲁炎 #分析:首先调用fun5,打印二哈,接着调用fun1,打印蒋小雨,然后调用fun3的函数,打印张冲 #接着执行下面函数体代码块,调用fun4,打印龙大队,接着调用fun2打印鲁炎
七.命名空间
把存放名字和值的关系的空间叫做命名空间
#命名空间分类
1.全局命名空间:在py文件中,函数外声明的变量都属于全局命名空间 2.局部命名空间:在函数中声明的变量会放在局部命名空i教案 3.内置命名空间:存放python解释器为我们提供的名字 如:list,tuple,str,int这些就是内置命名空间
#取值顺序
1.局部命名空间 2.全局命名空间 3.内置命名空间 #取值顺序例子: a = 10 #全局命名空间 def func(): a = 20 #局部命名空间 print(a) func() #20
八.作用域
定义:作用域就是作用的范围,按照生效范围分为:全局作用域和局部作用域
全局作用域:包含内置命名空间和全局命名空间,在整个文件都可以使用
可以通过globals()函数来查看全局作用域中的内容
局部作用域:在函数内部可以使用
可以通过locals()函数来查看局部作用域中的变量和函数信息
#例子:
#例子 # a = 10 # def func(): # a = 40 # b = 20 # def abc(): # print("哈哈") # print(a,b) #这里使用的是局部作用域 # print(globals()) #打印全局作用域中的内容 # print(locals()) #打印局部作用域中的内容 # func()
#关键字global和nonlocal讲解
global:更改全局变量中的值 理解:在局部中定义一个局部变量,然后加了global,就会将全局中定义的变量的值改成局部的那个变量的值 #global的应用 #例子 # a = 10 # def func(): # global a # a += 10 # print(a) # func() #20 ,加了global就可以改变外部的值了,如果不加是不能更改的 #例如:不加global更改全局参数的时候就会报错 # a = 10 # def func1(): # a += 10 # print(a) # func1() #总结点:全局变量本身就是不安全的,不能随意修改 nonlocal:寻找外层函数中离他最近的那个变量 #例子: # a = 10 # def func1(): # a = 20 # def func2(): # nonlocal a # a = 30 # print(a) # func2() # print(a) # func1() # print(a) #30,30,10 #nonlocal是更改离他最近的那个变量,所以,将上一个a=20,改为30 #所以打印是30,30,10,因为nonlocal将20改成了30
九.闭包
定义:在内层函数中访问外层函数的变量 闭包的作用: 1.可以保护变量不受侵害 2.可以让一个变量常驻内存
#例子:
#作用例子: #1、保护变量不受侵害 #首先举一个全局变量不安全的例子 # a = 10 # def outer(): # global a # a = 20 # print(a) # # def outer_2(): # global a # a = 30 # print(a) # # # outer() # outer_2() #得出结果是20,30 #解释:首先调用outer()函数更改为20,然后再调用outer_2函数打印30 # 这样就会出现哪个先调用就执行那个,所以改来改去是很混乱的 # def outer(): # a = 10 #这个变量对外界是不开放的 # def func(): # nonlocal a #寻找外层函数中离他最近的那个进行修改 # a = 20 # print(a) # func() # outer() # # def outer_2(): #这个函数不能对a = 10进行修改 # pass #2、让一个变量常驻内存 # def outer(): # a = 10 #常驻内存,为了inner执行的时候有值,因为你不知什么时候调用 # def inner(): # print(a) # return inner # fn = outer() # print("大大大") # print("笑笑笑") # # fn() #相当于inner(),调用inner函数 #使用 _closure_ 查看函数是不是闭包 #例子:不是闭包的检测 # def outer(): # def func(): # print("我不是闭包") # print(func.__closure__) #None # outer() #例二:是闭包 # def outer(): # a = 10 # def func(): # print(a) # print(func.__closure__) # outer() #(<cell at 0x000001B7B3E7D978: int object at 0x00007FF97124B470>,) #结论:如果打印的是None,不是闭包,如果不是None,就是闭包
十.迭代器
#迭代器 # 可以简单理解为:通用的去遍历某个对象的方式 #有些数据类型是可迭代的,有些是不可迭代的,如果使用不可迭代的来进行循环就会报错 #例子:使用不可迭代对象来进行循环就会报错 # s = 123 # for i in s: # print(i) #这样打印会报错: TypeError: ‘int‘ object is not iterable:数字不是一个可迭代对象 #那么问题就来了,怎么知道是不是一个可迭代对象呢? #可以通过dir查看xx类型的数据可以执行哪些方法 # print(dir(str)) #__iter__ iterable(可迭代) # print(dir(list)) #__iter__ # print(dir(int)) #如果没有__iter__,说明不是可迭代对象,不是可迭代对象那么相对应的就不能进行循环 #结论:所有的带__iter__是可以使用for循环的,是可迭代对象 #可迭代对象就可以使用__iter__()来获取到迭代器 #迭代器里面有__next__() # s = "我喜欢看火蓝刀锋" # it = s.__iter__() #获取迭代器 # print(dir(it)) #迭代器里有__iter__ 还有__next__
#迭代器的特点
1.只能向前取,下一个下一个,不能往回 2.几乎不占用内存,可以有效节省内存 3.for循环 4.惰性机制 #例子: 1.只能向前拿 #print(it.__next__()) #我 # print(it.__next__()) #喜 # print(it.__next__()) #欢 # print(it.__next__()) #看 # print(it.__next__()) #火 2.迭代器模拟for循环 # lst = ["蒋小雨","张冲","鲁炎","龙大队"] # for el in lst: #底层使用的是迭代器 # print(el)
#判断数据是否可迭代
#例子: # lst = ["张冲","鲁炎","蒋小雨"] #it = lst.__iter__() # print("__iter__" in dir(it)) #True # print("__next__" in dir(it)) #True # print(list(it)) #通过dir来判断数据是否可迭代的,以及数据是否是迭代器 # # #官方方案 # from collections.abc import Iterable #可迭代对象 # from collections.abc import Iterator #迭代器 # # print(isinstance(lst,Iterable)) #True # print(isinstance(lst,Iterator)) #False lst列表本身不是迭代器
十一.生成器
1.生成器的本质就是迭代器,和迭代器的特点一样,取值方式和迭代器一样(__next__(),send() 2.在python种有三种方式来获生成器 1.通过生成器函数 2.通过各种推导式来实现生成器 3.通过数据的转换也可以获取生成器
生成器函数
1.函数中如果由yield函数就是生成器函数 2.生成器函数在执行的时候,默认不会执行函数体,会返回生成器 3.yield:相当于return可以返回数据,但是yield不会彻底中断函数,会分段执行函数 #例子:不执行函数体,拿到的是生成器 # def func(): # print(‘哈哈‘) # yield 1 # print(‘呵呵呵‘) # gen = func() #这样子你就会发现不会执行你的函数,拿到的是生成器,如果是return的话就会执行函数了 # print(gen.__next__()) #这样子就会执行函数,执行到下一个yield,就是说执行看到yield就结束
#生成器应用
#应用场景 # 比如你喜欢吃鸡蛋,设想你去市场可以一下子就买一万个,这样也是可以,但是有个问题就是鸡蛋久了就会烂,存放是个问题,这样就会很浪费,但是如果你买了个鸡回来,就可以解决掉存放空间问题,想什么时候吃就拿一个 #例子:一下子买一万个浪费 # def egg(): # lst = [] # for i in range(10000): # lst.append(‘鸡蛋‘+str(i)) # return lst # ll = egg() #一下子买10000个就会很占用内存 #例二:买只鸡,生鸡蛋,想吃一个就拿一个 # def egg(): # for i in range(10000): # yield ‘鸡蛋‘+str(i) # g = egg() #获取生成器 # sir = g.__next__() # print(sir) #鸡蛋0 # sir1 = g.__next__() # print(sir1) #鸡蛋1 #这样子就是想吃一个就拿一个 #这样子也验证了生成器的3个特点 # 1.惰性机制,拿一个才给你取一个 # 2.省内存 # 3.只能向前拿
#send()方法
send()和__next__()是一样的,可以执行到下一个yield,可以给上一个yield位置传值 #send和__next__()区别: 1.send和next()都是让生成器走下一次 2.send可以给上一个yield的位置传递值,不能给最后一个yield发送值,在第一次执行生成器代码的时候不能使用send()
#使用send给上一个yield传值例子:
#例子:使用send给上一个yield传值 def func(): print("我吃什么啊") a = yield "玉米" #这里的a和后面的yield是没关联的,会把传进来的值交给print执行 print("a=",a) b = yield "饺子" print("b=",b) c = yield "包子" print("c=",c) yield "OVER" #最后收尾的一定是yield,不然会有报错 g = func() #获取生成器,记住有yield的是生成器函数,只会给你获取到生成器,不会执行函数体 ret1 = g.__next__() #没有上一个yield,所以不能使用send(),开头必须__next__() print(ret1) ret2 = g.send("大饼") print(ret2) #a=大饼 ret3 = g.send("粥") print(ret3) #b=粥 ret4 = g.send("冰淇淋") print(ret4) #c=冰淇淋 #解析:执行时候首先我吃什么啊,然后打印玉米,接着ret2使用send上一个yield传值,所以就变成a=大饼,接着打印a=大饼 # 要注意变量和右边的yield是两段来的,互不相干,接着打印饺子,ret3使用send给上一个yield传值,变成b=粥,接着继续执行
#生成器可以使用for循环来获取内部的元素
#为什么生成器可以使用for循环呢,因为生成器实质就是迭代器 #例子: def func(): print(111) yield 222 print(333) yield4444 print(555) yield 666 for i in func(): print(i)
十二.推导式
1.推导式:就是使用一句话来生成 2.包括:列表推导式,字典推导式,集合推导式, 3.注意点:没有元组推导式 4.3种推导式的语法: 1.列表推导式:[结果 for循环 条件判断] 2.字典推导式:{k:v for循环 条件判断} 3.集合推导式:{k for循环 条件判断}
#3种推导式的应用
#1.列表推导式 语法: [结果 for循环 判断语句] #例子:首先我们先来一个打印一年级到12年级,我们可能想到的是定义一个空列表,然后把元素追加到列表里面 # lst = [] # for i in range(1,13): # lst.append("年级"+str(i)) # print(lst) #如果使用推导式的话,那么就是使用一句话来生成一个列表 # lst = ["年级"+str(i) for i in range(1,13)] # print(lst) #和上面列表追加一样的效果 #例二:使用推导式取1-100的奇数 # lst = [i for i in range(100) if i%2 == 1] # print(lst) #例三:寻找名字中带有两个e的人的名字 # names = [[‘Tom‘,‘tomi‘,‘findall‘,‘Wesley‘,‘Steven‘,‘Jon‘],[‘Alice‘,‘Ana‘,‘Jennifer‘,‘Eva‘]] #逻辑:首先打开第一层列表,拿到下列表,然后再到小列表里面拿元素,再进行统计判断 #使用推导式写 # lst = [name for line in names for name in line if name.count(‘e‘) ==2] # print(lst) #[‘Wesley‘, ‘Steven‘, ‘Jennifer‘] #使用常规算法写 # lst = [] # for line in names: # for name in line: # if name.count(‘e‘) == 2: # lst.append(name) # print(lst) #[‘Wesley‘, ‘Steven‘, ‘Jennifer‘] #2.字典推导式 语法:{key:value for循环 条件判断} #例子:将列表的元素转换成字典,转换形式:[11,22,33,44] => {0:11,1:22,2:33} # lst = [11,22,33,44] # dic = {i:lst[i] for i in range(len(lst))} # print(dic) #{0: 11, 1: 22, 2: 33, 3: 44} #例二:将字典的key和value进行调换 # 思路:首先先拿到key和value,然后在推导式的结果那里掉不同位置就可以了 # dic = {"zs":"赵四","ln":"刘能","zc":"张冲","ly":"鲁炎"} # d = {v:k for k,v in dic.items()} # print(d) #{‘赵四‘: ‘zs‘, ‘刘能‘: ‘ln‘, ‘张冲‘: ‘zc‘, ‘鲁炎‘: ‘ly‘} #3.集合推导式 #要记住集合的特点:去重,无序,元素必须式可哈希不可变的数据类型 #例1:使用集合推导式去重复 # s = {i for i in range(100)} # print(s) #例二:去重复 # lst= [1,2,3,4,2,1,3,4,6,7] # s = {el for el in lst} # print(s) #{1, 2, 3, 4, 6, 7}
十三.生成器表达式
1.生成器表达式可以直接获取到生成器对象,生成器对象可以直接进行for循环,生成器具有惰性机制 2.生成器表达式语法: (结果 for 变量 in 可迭代对象 if 条件判断)
#生成器表达式应用
#下面将演示生成器的最大点特,惰性机制,要拿才给你拿一个,拿走了就没有值了 # def func(): # print(111) # yield 222 # yield 333 # # a = func() #获取到生成器 # a1 = (i for i in a) #生成器 # a2 = (i for i in a1) #生成器 # print(list(a)) #[222, 333] # print(list(a1)) #[] # print(list(a2)) #[] #分析:为什么前面的a有值,后面的都没有值了? #解:因为a是源头,他从源头把数据给拿走了,所以后面再从前面拿的话就不会有值了,这就验证了生成器的惰性机制,你拿一个才给你一个,拿走了就没有了 #那么后面还能不能获取到值? 答案是可以的,可以再做一个源头,再拿数据 #例如:再定义一个a3获取生成器,再进行调用,这样子a2就有值了 # def func(): # print(111) # yield 222 # yield 333 # # a = func() #获取到生成器 # a1 = (i for i in a) #生成器 # a3 = func() # a2 = (i for i in a3) #生成器 # print(list(a)) #[222, 333] # print(list(a1)) #[] # print(list(a2)) #[222, 333] #
#面试题
#题目:计算拿到的值是多少 #求和函数 # def add(a,b): # return a + b #生成器函数 # def test(): # for r_i in range(0,4): # yield r_i # # g = test() #获取到生成器 # # for n in [2,10]: # g = (add(n,i) for i in g) #上的for可以看成循环量词 # for n in [2]: # g = (add(n,i) for i in g) # for n in [10]: # g = (add(n,i) for i in g) #因为是2还没取值,所以是叠加进去,将g换成上面 # g = (add(n,i) for i in (add(n,i) for i in 0,1,2,3) # print(list(g)) #20,21,22,23 #分析:第一个函数是来求和得,第二个函数是生成器函数,没有打印值,然后到for循环,可以想象是2和10都执行了一次,但是因为生成器得惰性机制,然后执行2是没有值,所以是不关2的事情,执行10得时候才会执行,将10带进去算 #最后的执行是这样:g = (add(10,i) for i in (add(10,i) for i in 0,1,2,3),所以就成10+10,10+11,10+12,10+13 #提示:惰性机制,不到最后是不会拿值得 #下面接着演示列表有多个值,但是它只会看最后面的那个,前面的会相加 # def add(a,b): # return a + b #生成器函数 # def test(): # for r_i in range(0,4): # yield r_i # g = test() #获取到生成器 # # for n in [1,3,7]: # g = (add(n,i) for i in g) #这个就是相当于叠加了3次 # g = (add(7,i) for i in (add(7,i) for i in (add(7,i) for i in 0,1,2,3) # print(list(g)) #21,22,23,24 #最后的运算是:(add(7,i) for i in (add(7,i) for i in (add(7,i) for i in 0,1,2,3) #将7带进去运算,把最后那个带进去算 #首先是0+7,1+7,2+7,3+7,接着7+7,7+8,7+9,7+10,然后7+14,7+15,7+16,7+17
#生成器表达和列表推导式的区别
1.生成器表达式比较省内存,列表推导式比较耗内存
2.得到的值不一样,列表推导式得到的是一个列表,生成器表达式获取的是生成器
以上是关于python语法教程——def()函数的主要内容,如果未能解决你的问题,请参考以下文章