pandas入门
Posted 派大星先生c
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了pandas入门相关的知识,希望对你有一定的参考价值。
目录
pandas两个常用的工具数据结构:Series和DataFrame
一、Series
Series是一种类似于一维数组的对象,它由一组数据(各种NumPy数据类型)以及 一组与之相关的数据标签(即索引)组成。仅由一组数据即可产生最简单的
Series:
obj = pd.Series([4, 7, -5, 3])
obj

在索引过程中 可以有很多种形式
obj2 = pd.Series([4, 7, -5, 3], index=['d', 'b', 'a', 'c'])
obj2
obj2.index
sdata = 'Ohio': 35000, 'Texas': 71000, 'Oregon': 16000, 'Utah': 5000
obj3 = pd.Series(sdata)
obj3
states = ['California', 'Ohio', 'Oregon', 'Texas']
obj4 = pd.Series(sdata, index=states)
obj4
二、DataFrame
建DataFrame的办法有很多,最常用的一种是直接传入一个由等长列表或NumPy数组组成的字典:
data = 'state': ['Ohio', 'Ohio', 'Ohio', 'Nevada', 'Nevada', 'Nevada'],
'year': [2000, 2001, 2002, 2001, 2002, 2003],
'pop': [1.5, 1.7, 3.6, 2.4, 2.9, 3.2]
frame = pd.DataFrame(data)
如果你使用的是Jupyter notebook,pandas DataFrame对象会以对浏览器友好的html表格的方式呈现。

如果指定了列序列,则DataFrame的列就会按照指定顺序进行排列:
pd.DataFrame(data, columns=['year', 'state', 'pop'])
索引、添加值和删除值
#索引 也可以用series中的索引方法
frame2.loc['three']
#添加值
frame2['debt'] = np.arange(6.)
val = pd.Series([-1.2, -1.5, -1.7], index=['two', 'four', 'five'])
frame2['debt'] = val
#添加bool值
frame2['eastern'] = frame2.state == 'Ohio'
frame2
#删除
del frame2['eastern']
frame2.columns
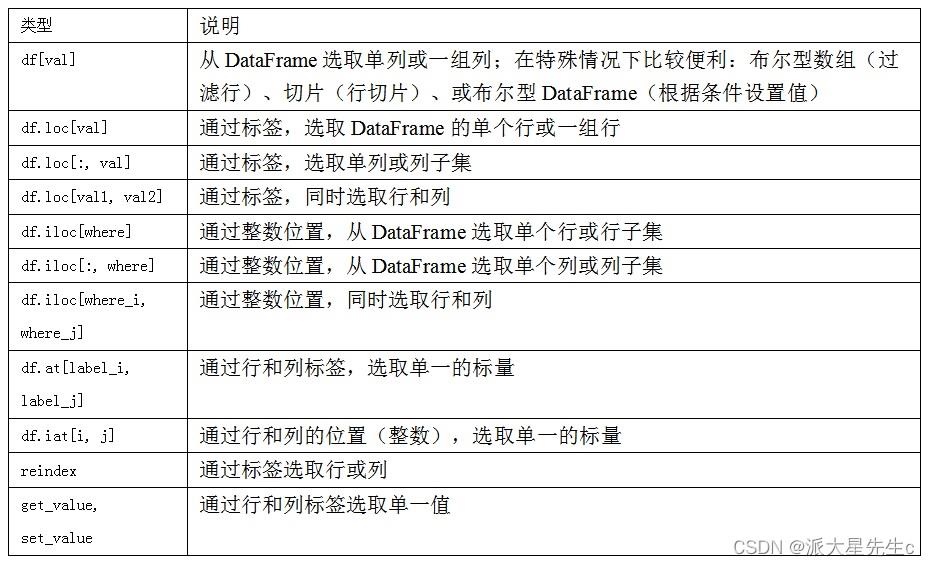
下表给出了DataFrame构造函数所能接受的各种数据

索引对象
用到index这个函数
obj = pd.Series(range(3), index=['a', 'b', 'c'])
index = obj.index
index
index[1:]
# 字典的形式
dup_labels = pd.Index(['foo', 'foo', 'bar', 'bar'])
dup_labels

三、基本功能
1、重新索引
pandas对象的一个重要方法是reindex,其作用是创建一个新对象,它的数据符合新的索引。
obj = pd.Series([4.5, 7.2, -5.3, 3.6], index=['d', 'b', 'a', 'c'])
obj2 = obj.reindex(['a', 'b', 'c', 'd', 'e'])

对于时间序列这样的有序数据,重新索引时可能需要做一些插值处理。method选项即可达到此目的,例如,使用ffill可以实现前向值填充:

借助DataFrame,reindex可以修改(行)索引和列。只传递一个序列时,会重新索引结果的行:

列可以用columns关键字重新索引:
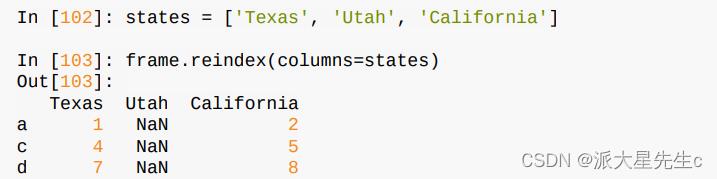

2、丢弃指定轴上的项
丢弃某条轴上的一个或多个项很简单,只要有一个索引数组或列表即可。由于需要执行一些数据整理和集合逻辑,所以drop方法返回的是一个在指定轴上删除了指定值的新对象:
obj = pd.Series(np.arange(5.), index=['a', 'b', 'c', 'd', 'e'])
new_obj = obj.drop('c')
obj.drop(['d', 'c'])
a 0.0
b 1.0
e 4.0
dtype: float64
data = pd.DataFrame(np.arange(16).reshape((4, 4)),
index=['Ohio', 'Colorado', 'Utah', 'New York'],
columns=['one', 'two', 'three', 'four'])
data.drop(['Colorado', 'Ohio'])

通过传递axis=1或axis='columns’可以删除列的值:
data.drop('two', axis=1)
data.drop(['two', 'four'], axis='columns')

3、索引、选取和过滤
索引
切片

过滤

4、用loc和iloc进行选取
对于DataFrame的行的标签索引,我引入了特殊的标签运算符loc和iloc。它们可以让你用类似NumPy的标记,使用轴标签(loc)或整数索引(iloc),从DataFrame选择行和列的子集。

这两个索引函数也适用于一个标签或多个标签的切片:

5、在算术方法中填充值
df1 = pd.DataFrame(np.arange(12.).reshape((3, 4)),
columns=list('abcd'))
df2 = pd.DataFrame(np.arange(20.).reshape((4, 5)),
columns=list('abcde'))
df2.loc[1, 'b'] = np.nan
df1
df2

df1 + df2

使用df1的add方法,传入df2以及一个fill_value参数:
指定一个填充值


6、排序和排名
根据条件对数据集排序(sorting)也是一种重要的内置运算。要对行或列索引进行排序(按字典顺序),可使用sort_index方法,它将返回一个已排序的新对象:
obj = pd.Series(range(4), index=['d', 'a', 'b', 'c'])
obj.sort_index()
对于DataFrame,则可以根据任意一个轴上的索引进行排序:

数据默认是按升序排序的,但也可以降序排序:

当排序一个DataFrame时,你可能希望根据一个或多个列中的值进行排序。将一个或多个列的名字传递给sort_values的by选项即可达到该目的:

四、汇总和计算描述统计



Pandas之入门
pandas入门
由于最近公司要求做数据分析,pandas每天必用,只能先跳过numpy的学习,先学习大Pandas库
Pandas是基于Numpy构建的,让以Numpy为中心的应用变得更加简单
pandas的数据结构介绍
Series
- 由一组数据以及一组数据标签即索引组成
import pandas as pd from pandas import Series,DataFrame obj = Series([4,7,-5,3]) # 索引在左边,值在右边,默认从0开始 obj 0 4 1 7 2 -5 3 3 dtype: int64 # 制定索引 obj2 = Series([4,7,-5,3],index = [‘a‘,‘b‘,‘c‘,‘d‘]) obj2 a 4 b 7 c -5 d 3 dtype: int64 # 查看索引 obj2.index Index([‘a‘, ‘b‘, ‘c‘, ‘d‘], dtype=‘object‘) # 查询 obj2[[‘a‘,‘b‘,‘c‘]] a 4 b 7 c -5 dtype: int64 obj2[obj2>0] a 4 b 7 d 3 dtype: int64- 还可以直接看成一个关系型字典
sdata = {‘ke‘:35000,‘text‘:70000,‘orgen‘:16000} obj3 = Series(sdata) obj3 ke 35000 text 70000 orgen 16000 dtype: int64 keys = [‘ke‘,‘text‘,‘orgen‘,‘xu‘] obj4 = Series(sdata, index=keys) obj4 ke 35000.0 text 70000.0 orgen 16000.0 xu NaN dtype: float64- 检测缺失值的重要两个函数 isnull和notnull
obj4[obj4.isnull()] xu NaN dtype: float64 obj4[obj4.notnull()] ke 35000.0 text 70000.0 orgen 16000.0 dtype: float64- Series本身和索引都有一个name属性
# 可以理解成对象名称 obj4.name = ‘pop‘ # 对象的索引的名称 obj4.index.name = ‘state‘ obj4 state ke 35000.0 text 70000.0 orgen 16000.0 xu NaN Name: pop, dtype: float64 # Series的索引可以就地修改 obj4.index = [‘new_ke‘,‘new_text‘,‘new_orgen‘,‘new_xu‘] new_ke 35000.0 new_text 70000.0 new_orgen 16000.0 new_xu NaN Name: pop, dtype: float64- DataFrame
- DataFrame是一个表格型数据结构,最常用的是直接传入一个由等长列表或者是Numpy数组组成的字典
data = {‘state‘:[‘oh‘,‘oh‘,‘vad‘,‘vad‘], ‘yead‘:[2000,2001,2002,2003], ‘pop‘:[1.5,1.7,3.6,2.4] } frame = DataFrame(data) # 自动有序排列 yead state pop 0 2000 oh 1.5 1 2001 oh 1.7 2 2002 vad 3.6 3 2003 vad 2.4 # 如果传入的列在数据中找不到,就产生NaN DataFrame(data,columns=[‘yar‘,‘yead‘]) yar yead 0 NaN 2000 1 NaN 2001 2 NaN 2002 3 NaN 2003
以上是关于pandas入门的主要内容,如果未能解决你的问题,请参考以下文章