技术分享| 快对讲如何降噪
Posted anyRTC
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了技术分享| 快对讲如何降噪相关的知识,希望对你有一定的参考价值。
在日常生活的环境中,噪声是无处不在的,在对讲的场景中噪声是影响语音通话质量的重要因素。语音降噪技术通过消除噪声并提取干净语音,从而提高语音质量和可懂度。在实际生活或生产场景中噪声又分为稳态噪声和非稳态噪声,例如,环境背景噪声,路边的汽车来来回回的噪声都属于稳态噪音;而鼠标点击声、键盘声、敲击声、空调声、厨房碗碟碰撞声等都属于非稳态噪音。相比于稳态噪声,非稳态噪声在处理上的难度更高。近年来,以深度学习为代表的AI降噪技术无需像传统语音增强算法一样对信号特性进行假设,在非平稳噪声上的表现取得了显著提升。

当前降低噪声的主流方案主要有传统降噪和AI降噪。常规去噪方法运算量小,具有实时降噪的优点,但同时,由于其基于数学原理和物理原理的推导,不可避免地基于人类认知的理想先验假设,这使得传统降噪对于真实场景中频繁发生的多种类非稳态噪声表现不佳,特别是在对讲的场景中,使用环境非常复杂,作业场景中的突发非稳态噪声的种类特别多。
AI去噪是近年来兴起的一种基于数据驱动的降噪方法,可以有效地应对各种非平稳噪声,但是前期需要进行大量的数据训练,快对讲将实际用户场景中共享的大量音频数据作为数据源,并建立适当的数据模型作为基础。在移动端模型的部署中,还需要综合考虑各种因素,如模型大小、降噪效果、CPU占用率和内存占用率,也对降噪技术的实现提出了挑战。
得益于谷歌开源的TensorFlow,可以让我们更方便快捷的创建了AI降噪模型训练框架。快对讲结合用户不断提出的高要求,使用TensorFlow机器学习平台上构建了一个并行训练的AI降噪与噪声场景的框架,以及音频降噪、音质升级和模型优化算法。
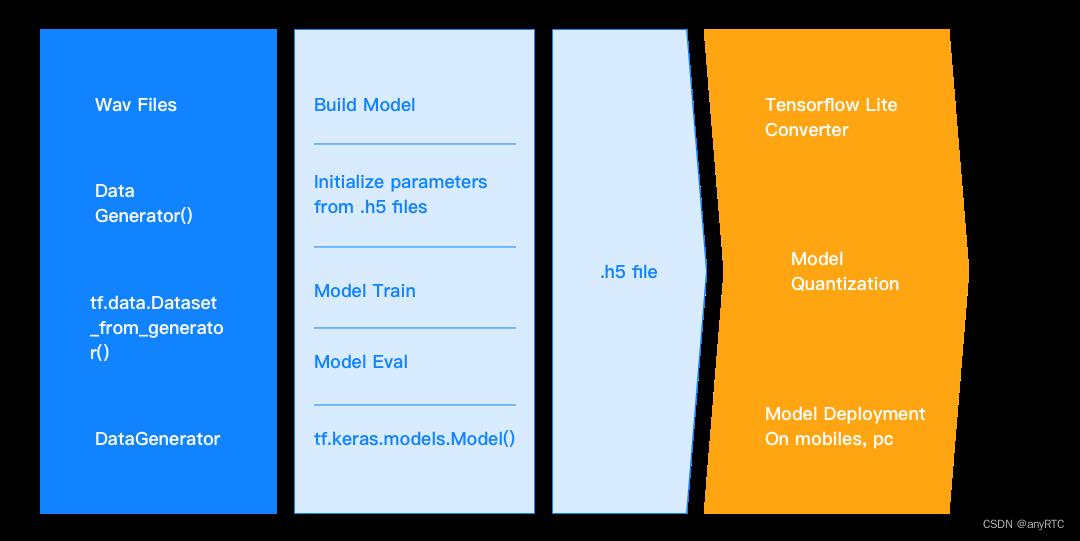
我们的团队通过对多个时段的音频数据进行“投喂”和场景训练,通过适当的数据扩展,进一步增强模型泛化能力,结合精细化设计的网络结构,使AI降噪模型能适应生活和作业中常见的数以百计种噪声,能通过AI技术为用户提供智能通信体验。所以多个时间的噪声数据是提高降噪模型泛化能力的关键。与此同时,团队中的音频专家们也借助TensorFlowLite的量化功能,将其成功地部署到更多的产品功能中,而降噪效果也基本不受影响。
同时AI的降噪算法包括音频降噪模块和音质升级模块。获取好的音质首先要去除噪声,语音去噪模块主要是对含噪声音频中的干净人声进行建模,然后提取带噪音频的频域特征,将带噪音频与干净音频的频域特性进行比较和计算,这样,就能使AI在人声之外,具有更精确的声音识别能力,如敲击声、鸣笛声、撞击声等,从噪音环境中去除干净声音。然后还可以对人声进行进一步增强,让声音更饱满浑厚,可以有效提高音质和用户体验。

以上是关于技术分享| 快对讲如何降噪的主要内容,如果未能解决你的问题,请参考以下文章