ubuntu上配置好hadoop后,运行MapReduce
Posted 小铎的bb
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了ubuntu上配置好hadoop后,运行MapReduce相关的知识,希望对你有一定的参考价值。
ubuntu上配置好hadoop后,运行官网MapReduce教程
初学者,可能有一些做的不好,望大家多多指教。很多错误是因为我不了解linux的操作而造成的失误,一同写出,希望可以帮助到大家。
无需使用eclipse,全部使用命令行。我个人比较习惯使用vim,当然不使用也是可以的,大家根据自己的习惯来使用。
首先先使用
sudo vim ~/.bashrc
命令,确保其中能够有如下配置,特别是HADOOP_CLASSPATH,因为可能在配置hadoop的时候是没有配的,我就是忘记配这个了,会一直报错。
export JAVA_HOME=/usr/java/default
export PATH=$JAVA_HOME/bin:$PATH
export HADOOP_CLASSPATH=$JAVA_HOME/lib/tools.jar
官网是以单词计数WordCount.java为例的,WordCount.java代码如下
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class WordCount
public static class TokenizerMapper
extends Mapper<Object, Text, Text, IntWritable>
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context
) throws IOException, InterruptedException
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens())
word.set(itr.nextToken());
context.write(word, one);
public static class IntSumReducer
extends Reducer<Text,IntWritable,Text,IntWritable>
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values,
Context context
) throws IOException, InterruptedException
int sum = 0;
for (IntWritable val : values)
sum += val.get();
result.set(sum);
context.write(key, result);
public static void main(String[] args) throws Exception
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
然后对其进行编译处理,最好单独创建一个文件夹来做实验,然后将WordCount.java和编译好的文件、打包好的wc.jar放在一个包下。在有上述包的文件夹下,打开命令行,输入如下指令
#如果没有配好HADOOP_CLASSPATH,运行第一句会报错,第二句是在哪里运行包打在哪里,所以最好就是在同一个文件夹,第一次写的时候我就是不在同一个文件夹,然后没有写清楚WordCount*.class路径,导致一直写不对
$ bin/hadoop com.sun.tools.javac.Main WordCount.java
$ jar cf wc.jar WordCount*.class
得到的结果如下
接着开始准备输入文件和输出文件,只需要创建input文件,不要创建output文件,否则后面运行会出错,因为运行的时候它会自己创建一个。
在hdfs中怎么添加文件夹呢?代码如下,千万不要在hadoop前面加sudo,会报错说没有该命令。
#创建单级目录
hadoop fs -mkdir input
#创建多级目录
hadoop fs -mkdir -p /user/joe/wordcount/input
准备好了以后,在本地创建两个file01的和file02文件。我是这样创建的
#第一步
sudo vim file01
#第二步 已经进入了vim文本编辑器,按“i”进入编辑模式,在文本编辑器中输入如下内容
Hello World Bye World
#第三步 然后按“Esc”退出文本编辑模式,按“:wq”保存并退出,可以习惯性的输入下面命令(个人习惯)
source file01
按照上述方法创建好了两个本地的file01和file02,但是需要使用的是hdfs中的file01和file02,那么使用如下命令将其上传到hdfs中
#hadoop dfs -put 你的文件路径 hdfs中的路径
#你的路径,如果是在当前文件夹下,可以直接和下面一样这样写,但是不一样的话请复制完整的路径,尽量减少手打,因为很容易错
hadoop dfs -put file* /user/joe/wordcount/input
使用官网的命令进行查看,得到如下图所示

然后使用如下命令运行,一定要注意,不要创建output,会报错。然后如果WordCount和wc.jar不在一个文件夹的,请写好完整的路径。最好还是一个文件夹的方便。
hadoop jar wc.jar WordCount /user/joe/wordcount/input /user/joe/wordcount/output
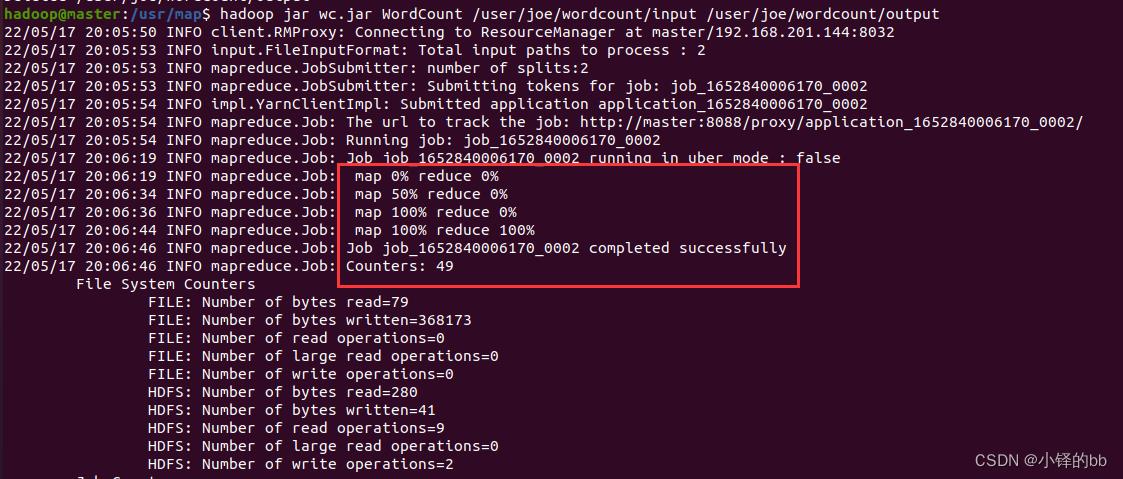
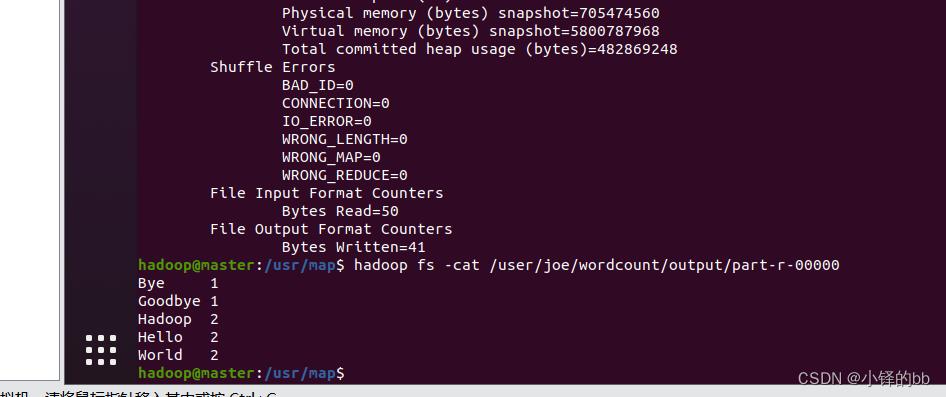
然后使用如下命令查看output
hadoop fs -cat /user/joe/wordcount/output/part-r-00000
那么,我运行一次了就会有output对吗,有了output我下次运行会报错,那么我如何解决?
第一种,删除就可以了
hadoop fs -rm -r /user/joe/wordcount/output
第二种,改一个输出路径,比如将output改成output1
哈哈哈 就这样就可以做完实验了
以上是关于ubuntu上配置好hadoop后,运行MapReduce的主要内容,如果未能解决你的问题,请参考以下文章