CDH6安装配置和使用LZO压缩
Posted 小基基o_O
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了CDH6安装配置和使用LZO压缩相关的知识,希望对你有一定的参考价值。
文章目录
概述
- Lempel-Ziv-Oberhumer
是一种 无损的 数据压缩算法 - 实现它的一个自由软件工具是
lzop - LZO压缩可用在HDFS,压缩数据并支持分片
在CentOS7使用LZO压缩
安装
yum install -y lzop
lzop命令常见参数 | 说明 |
|---|---|
-v, --verbose | 查看过程信息 |
-d, --decompress, --uncompress | 解压 |
-t, --test | 检查压缩文件的完整性 |
-U, --unlink, --delete | 压缩或解压完成后,删除输入文件 |
-f, --force | 强制执行一些操作,例如覆盖文件 |
搞个文件
echo abc > a.txt
压缩
lzop -Uv a.txt
测试压缩文件的完整性
lzop -t a.txt.lzo
解压
lzop -dv a.txt.lzo
CDH6安装配置LZO
1、安装
主机=>Parcel=>配置

添加
https://archive.cloudera.com/gplextras6/6.x.y/parcels/
其中x和y要替换为CDH的具体版本,我的是6.3.2
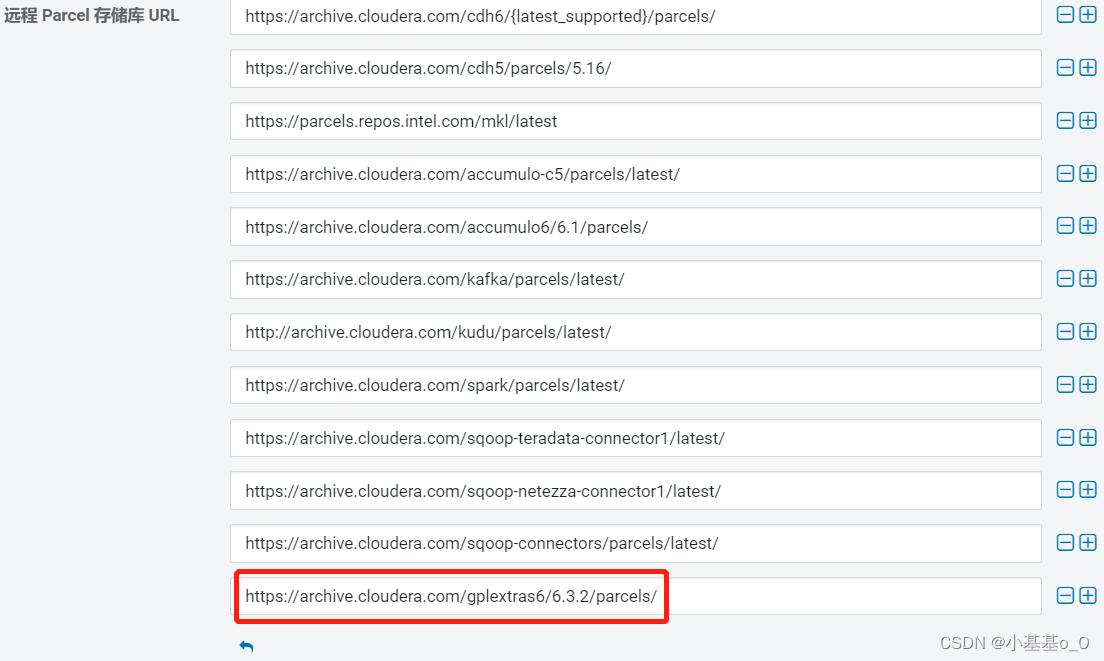
下载,分配,激活
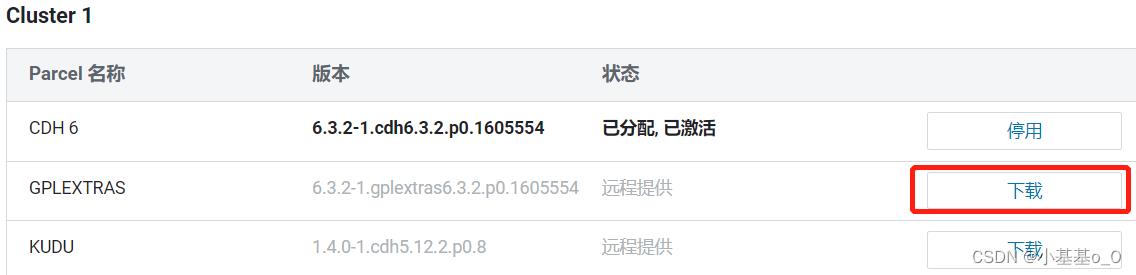
查看
hadoop-lzo.jar路径

2、配置
HDFS配置添加
com.hadoop.compression.lzo.LzopCodec

HIVE配置的
Hive 辅助 JAR 目录添加/opt/cloudera/parcels/GPLEXTRAS/lib/hadoop/lib
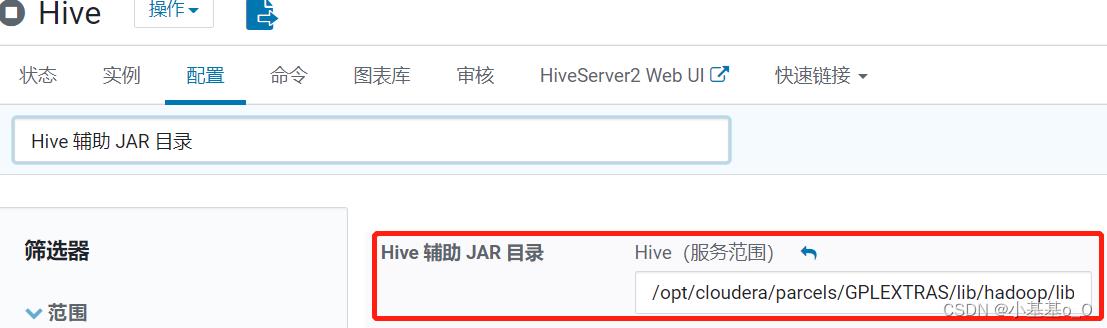
配置修改后重启服务
3、测试
- 生成1个10000000行的文件,约40G
vim a.py
from multiprocessing import Process
from os import system
def append_file(file_name='a.txt'):
for i in xrange(100000):
f1 = 'abcdefghij' * 400
system('echo %s >> %s' % (f1, file_name))
def parallel(f, parallelism=100):
pool = []
for offset in range(parallelism):
pool.append(Process(target=f))
for p in pool:
p.start()
for p in pool:
p.join()
parallel(append_file)
python a.py
- 压缩文件,上传到HDFS
# 压缩
lzop a.txt
ll -h | grep a.txt
# 上传
hadoop fs -put a.txt.lzo /user/hive/warehouse/
hadoop fs -ls -h /user/hive/warehouse/
压缩后文件190M,块大小128M,预期mapper数=2

- HIVE建表,数据装载
-- 建表
DROP TABLE IF EXISTS t;
CREATE TABLE t (f STRING)
STORED AS
INPUTFORMAT 'com.hadoop.mapred.DeprecatedLzoTextInputFormat'
OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat';
-- 数据装载
LOAD DATA INPATH '/user/hive/warehouse/a.txt.lzo' INTO TABLE t;
- 添加LZO索引
sudo -u hive \\
hadoop jar \\
/opt/cloudera/parcels/GPLEXTRAS/lib/hadoop/lib/hadoop-lzo.jar \\
com.hadoop.compression.lzo.DistributedLzoIndexer \\
/user/hive/warehouse/t/a.txt.lzo
- 查看mapper数(切片数)
SET hive.input.format=org.apache.hadoop.hive.ql.io.HiveInputFormat;
SELECT COUNT(1) FROM t;
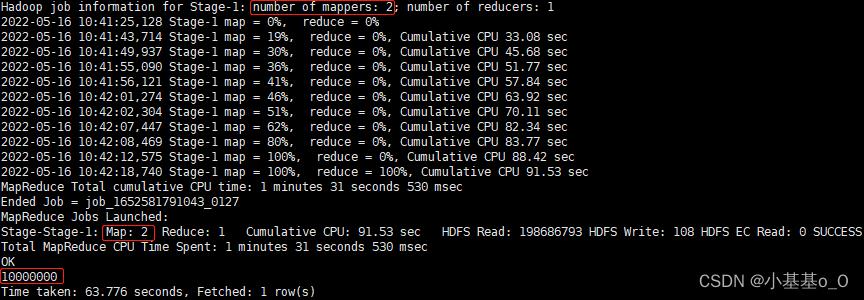
Appendix
| en | 🔉 | cn |
|---|---|---|
| deprecate | ˈdeprəkeɪt | vt. 反对;抨击;轻视;声明不赞成 |
| deprecated | ˈdeprəkeɪtɪd | deprecate 的过去式和过去分词 |
| parcel | ˈpɑːrsl | n. <英>包裹,邮包;一批;一块土地(尤指地产的一部分);v. <英>把……包起来(parcel sth. up) |
| extras | ˈekstrəz | n. 附加设备;额外部分;另外收费的部分(extra的复数) |
| extra | ˈekstrə | adj. 额外的;另外收费的;n. 另收费的事物;临时演员;(非击球所得的)附加分;adv. 额外 |
| unlink | ˌʌnˈlɪŋk | vt. 解开……的环节;拆开;vi. 分开;分离 |
HIVE创建LZO表语法
STORED AS
INPUTFORMAT 'com.hadoop.mapred.DeprecatedLzoTextInputFormat'
OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat';
创建LZO索引语法
hadoop jar /path/to/your/hadoop-lzo.jar com.hadoop.compression.lzo.DistributedLzoIndexer big_file.lzo
HIVE查询LZO表语法
SET hive.input.format=org.apache.hadoop.hive.ql.io.HiveInputFormat;
以上是关于CDH6安装配置和使用LZO压缩的主要内容,如果未能解决你的问题,请参考以下文章