GlusterFS文件系统弹性哈希算法
Posted 刘爱贵
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了GlusterFS文件系统弹性哈希算法相关的知识,希望对你有一定的参考价值。
(TaoCloud团队原创 作者:林世跃@TaoCloud)
GlusterFS采用独特的无中心对称式架构,与其他有中心的分布式文件系统相比,它没有专用的元数据服务集群。在文件定位的问题上,GlusterFS使用DHT算法进行文件定位,集群中的任何服务器和客户端只需根据路径和文件名就可以对数据进行定位和读写访问。换句话说,GlusterFS不需要将元数据与数据进行分离,因为文件定位可独立并行化进行。
GlusterFS中数据访问流程如下:
1、计算hash值,输入参数为文件路径和文件名;
2、根据hash值在集群中选择子卷(brick,即存储单元),进行文件定位;
3、对所选择的子卷进行数据访问。
GlusterFS目前使用Davies-Meyer算法计算文件名hash值,获得一个32位整数。Davies-Meyer算法具有非常好的hash分布性,计算效率很高,假设逻辑卷中的存储单元Brick有N个,则32位整数空间被平均划分为N个连续子空间,每个空间分别映射到一个存储单元Brick,计算得到的32位hash值就会被投射到一个存储单元Brick。
逻辑卷在新增加一个节点时候,hash值映射空间将会发生变化,现有的文件目录可能会被重新定位到其他的存储服单元Brick,从而导致定位失败。解决问题的方法是对文件目录进行重新分布,把文件移动到正确的存储单元Brick上去,但这大大加重了系统负载,尤其是对于已经存储大量的数据的海量存储系统来说显然是不可行的。
GlusterFS的哈希分布是以目录为基本单位的,文件的父目录利用扩展属性记录了子卷映射信息,其下面子文件目录在父目录所属存储单元中进行分布。GlusterFS逻辑卷新增加一个节点时候提供了多种选择。由于文件目录事先保存了分布信息,因此新增节点不会影响现有文件存储分布,它将从此后的新创建目录开始参与存储分布调度。这种设计,新增节点不需要移动任何文件,但是负载均衡没有平滑处理,老节点负载较重。GlusterFS在设计中考虑了这一问题,在新建文件时会优先考虑容量负载最轻的节点,在目标存储节点上创建文件链接直向真正存储文件的节点。另外,GlusterFS弹性卷管理工具可以在后台以人工方式来执行负载平滑,将进行文件移动和重新分布,此后所有存储服务器都会均会被调度。
Hash范围分布区间
现在我们假设创建了一个四个brick节点,创建GlusterFS dht卷,在服务端的brick挂载目录会给四个brick平均分配2^32次方的区间(在GlusterFS高版本还有根据brick节点的容量当权重,根据容量大小多占区间数,如某个brick容量是其他brick的2倍,那么该brick节点的区间范围也会是其他的2倍),GlusterFS hash分布区间是保存在目录上而不是根据机器去分布区间。如下图,brick*表示的是一个目录。分布区间是保存在每个brick挂载点目录的扩展属性上。

brick挂载点目录扩展属性的完整内容:
获取目录的扩展属性方法getfattr -d -m . -e hex brick1
trusted.gfid=0x00000000000000000000000000000001
trusted.glusterfs.dht=0x0000000100000000000000007ffffffe
trusted.glusterfs.volume-id=0x779a8547d0054666922c6fe60d52976a
Trusted.gfid是GlusterFS文件系统中文件目录的唯一标识符。trusted.glusterfs.volume-id是卷的唯一标示符,trusted.glusterfs.dht就是分布的每个区间的范围。占用了后面8位既是7ffffffe,即这个目录占用的区间最大值是7ffffffe。
文件快速Hash映射
现在我们将test-file1、test-file2、test-file3、test-file4四个文件通过快速Hash函数计算出对应的key值(2^32范围的数值),然后散列到服务器的brick上。这里需要注意的是两点,GlusterFS里面在处理文件名时候会忽略扩展名,如file.txt,file.pdf。在计算过程其实都是file;GlusterFS是可以忽略分布式算法指定文件落到客户指定的节点上,基本格式是file@client_brick,这样指定了file落到client_brick节点上。在没有特殊处理情况下Hash过程。
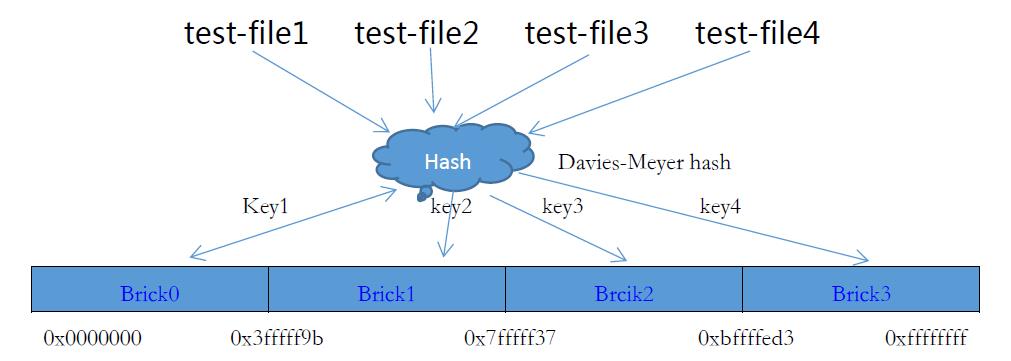
深度目录文件分布
GlusterFS中每个目录都保存着分布区间,文件是根据父目录所在的分布区间范围选择落点,即文件落在哪个brick节点上只是跟父目录有关。这是GlusterFS文件系统为了更好分布文件到各个节点达到更好的均衡。每一次创建一个目录时候会重新在这一层目录再一次划分区间。假设集群有四个节点组成,brick挂载点为 :/sda/brick0, /sdb/brick1, /sdc/brick2, /sdd/brick3。当卷创建时已经对四个brick挂载点进行区间分布,如上图。这时在在客户端创建一个test-dir目录。
1.目录test-dir 根据快速hash得到key值,根据/sd*/brick* 目录的分布区间得到落点;
2.确定落在brick节点,在该节点创建完目录然后在剩余节点创建相同目录;
3.最后对各个节点的 test-dir重新划分区间。

如上图,GlusterFS会对每个不同深度的目录重新划分区间,这样做的好处是文件可以更均衡落在各个brick节点。
1.在每个不同深度目录,不同目录下,每个分布区间都是不一样,这样好处是可以相同文件名在不同目录是落在不同节点。避免了一个节点的磁盘写满,而别的brick节点容量空闲一大部分。
2.文件分布到多个brick节点,多用户在读写不同文件时候,文件分布到不同服务器,减轻服务器压力,避免出现磁盘读写性能瓶颈。
处理节点分布不均衡
根据分层目录划分区间,虽然极大的使文件平衡的分布到各个节点上,但是在各种应用场景下,文件名很多是类似而且是在一层目录下,Hash算法是概率性。出现一个brick容量满而其他brick节点还剩余大量空间容量的情况,目前算法还是无法百分百避免。
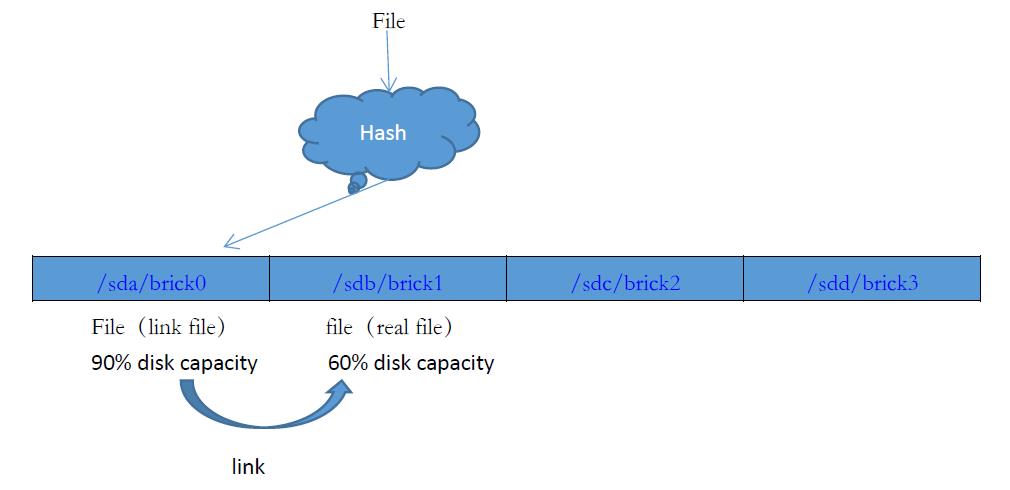
GlusterFS在处理出现节点分布不均衡利用链接技术,假设一个大文件定位了某个brick,而这个brick剩余磁盘容量小于文件大小,这时候文件会在落点区间创建一个T文件(链接文件),然后在其他节点真实得创建文件,写入文件。磁盘在超过90%容量时候,性能会出现断崖式的下跌,所以在GlusterFS会设置一个阈值,当节点容量超过这个阈值,文件会使用链接方式存储文件。File文件在读写时候,会首先定位到/sda/brcik0上,根据文件属性发现是一个T文件,客户端根据返回的扩展属性获取真实文件所在brick节点/sdb/brick1,客户端则会在真实得brick节点上读写。
系统在线动态扩容
当整个卷容量耗尽时候,这时候需要增加新的磁盘,新的brick节点来扩容节点卷的容量。现在分析一下当GlusterFS增加一个节点时候是如何处理。增加一个brick节点,图以4节点扩容为5节点为例。
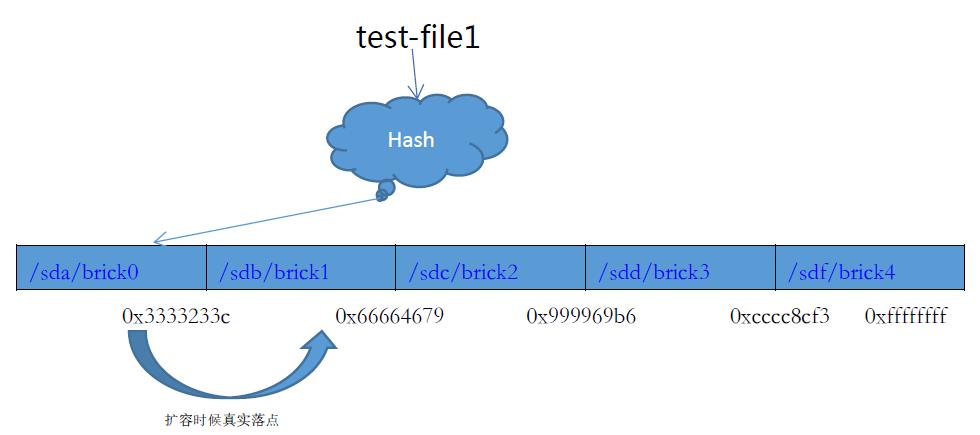
如上图,当卷扩容之后,大量已经写入的文件落点会出现改变,文件需要迁移到真实得落点,当一个大量容量的应用系统时候,则会发生大量的文件进行迁移。当大量文件迁移,一个会是占用了带宽导致上层应用性能下降。而且当文件迁移时候,机器故障可能会导致一些意想不到的情况。
GlusterFS在处理节点增加时候,提供了两种方式:一种是节点扩容,修复所有的目录下的分布区间,从新扩展划分全部的目录的区间,对每一个服务器启动一个进程遍历自身服务器所有的brick节点的文件,对每个文件重新计算hash确定落点,当文件所在节点brick已经不在这个范围,文件就会被迁移。文件在迁移的过程,客户端是会保存原来目录的区间和扩容之后的区间,这样文件在迁移过程,上层应用会在原来的区间进行一次查找,查找到则在原来区间访问,查找不到则会在新的扩容区间查找。这样文件在迁移时候不会影响上层业务;另一种方式:卷扩容节点之后,卷中原来存在的目录区间不再重新分配,当创建新的目录之后才会在新的目录按照新的节点数划分区间。
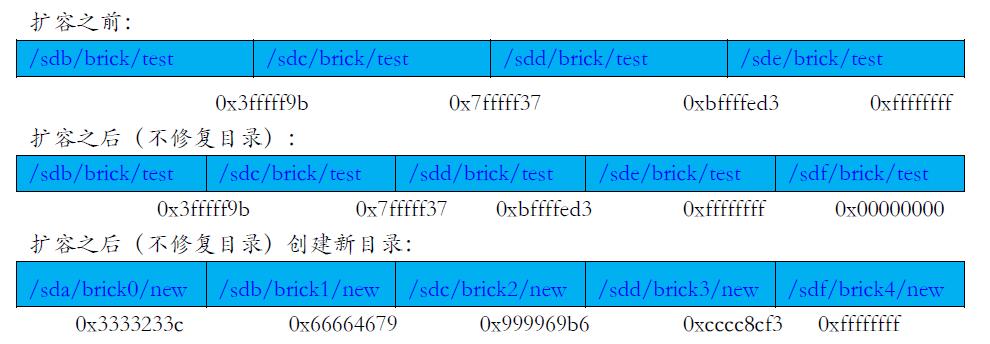
上图可以看出,在不修复目录情况,原先的目录在扩容之后不可能再存储到文件。扩容之后的文件只能在新建的目录才能落到扩容的节点。这样会照成老节点负载加大。
Hash值计算流程
现在看看GlusterFS计算hash值的流程,文件是如何根据算法最后得出一个无符号的32数字以及GlusterFS是如何管理这些分布区间的。
GlusterFS文件系统利用layout结构体保存所有的分布区间,现在看看layout结构细节。
struct dht_layout
int cnt;
struct
int err;
uint32_t start; //区间的开始值
uint32_t stop; //区间的结束值
uint32_t commit_hash;
xlator_t *xlator; //指向的服务端brick节点
list[];
layout_t;
结构体中省略了一些参数,这是为了更专注去了解整个hash值计算的过程,现在看看计算的代码流程。list保存了整个集群区间的分布,也就是目录的区间数。
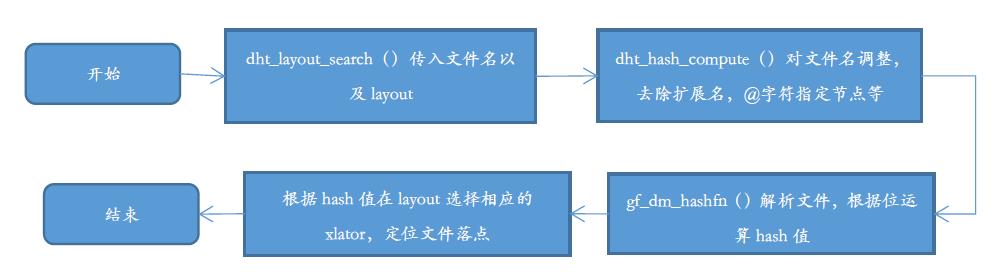
从上面的流程图看可以看出GlusterFS文件系统是如何对一个文件名计算出一个2^32内的值,如果文件名带有扩展名会剔除扩展名,带有一些特殊的字符会也是剔除之后计算,如@,@在GlusterFS中作为一个特殊字符使用,主要是用在指定文件落在服务端的那个brick节点上。如果指定了落在哪个brick上,则会直接在相应的brcik上查找文件,忽略算法。
文件查找流程
Xlator是GlusterFS中使用实现每一个功能层的结构体,在网络连接层,xlator结构体包含了服务端brick的ip以及挂载目录,这里把xlator简单的成代表指向一个服务器的brick。从上一小节知道layout包含了集群里面的所以指向服务器的brick。在集群当中一个layout保存了完整的分布区间而一个xlator保存了一个区间,比如一个集群有5个brick节点,这时候分成了5个区间,一个xlator指向一个区间,在GlusterFS里面一个区间可以称作一个hash卷,一个服务端brick为一个子卷。一个layout包含了整个区间。
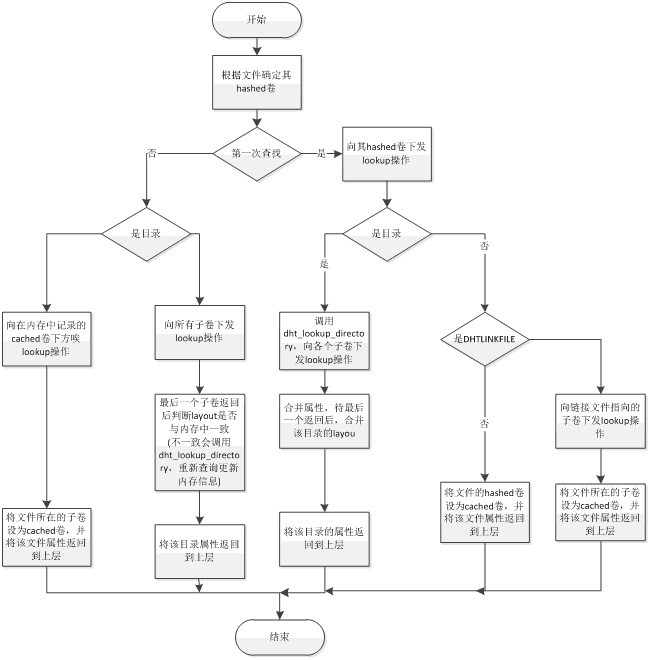
根据上面的的知识,现在看看GlusterFS是如何查找一个文件的。这个在代码对应的是lookup函数。文件查找过程:
1)根据文件目录名获取其hash卷;
2)若不是第一次查询且是目录,则向所有子卷下发lookup操作,比对与inode中的信息是否一致,若不一致则更新。
3)若不是第一次查询但不是目录,则向cached下发lookup操作,若不存在,则需调用dht_lookup_everywhere.,找到后为其创建DHTLINKFILE。
4)若是第一次查询且是目录,则会向其hashed卷下发lookup操作,然后再向其它子卷下发lookup操作,合并后返回。
5)若是第一次查询但不是目录,则会向其hashed卷下发lookup操作,若返回的是DHT_LINKFILE,则还有向其cached卷下发lookup操作,将其属性返回。
从上面具体去分析,首先分析根节点文件的查找,可以知道GlusterFS有对hash节点做缓存的,在先前查找之后会有缓存一个hash卷,下次访问时候就会根据inode的ctx获取从而缩短了时间。但是缓存是有时间限制,现在我们分析一下GlusterFS列目录(即ls)动作为什么会这么慢。假设操作都是第一次查找而且文件处于几层目录下面,在查询目录需要检测集群中每一个目录,而且这些动作是一个一个目录去查询的,也就是需要跟整个集群的机器去通信。当出现缓存不一致时候或者目录损坏(被删除,或者扩展属性不一致),这时候还会先修复目录,在访问该目录下文件的时候,还需要把所有的机器的全部文件查找一遍。在GlusterFS挂载点上做一次ls,这个时候基本会调用lookup,stat,getxattr,opendir等函数,这些每调用一次这个函数都需要进行一次通信而且在需要访问整个集群上面得机器。这样就会导致ls出现过于慢的情况。
根据ls去分析简单分析小文件读写为什么这么慢的原因。我们假设一次需要写入一万个64Kb的小文件,集群规模为10台60个brick节点,那么一万个文件就会散落到整个集群的60个brcik节点上面。GusterFS对一个文件读写的基本操作是lookup->stat->open->read/write,假设集群整体状态是正常的,文件目录都是健康的情况下,分布区间都是正确的,目录是三层目录。这一万文件在读写时候,首先需要把集群的两层目录整体都遍历一遍,也就说需要依次对60个节点上的目录进行访问,检测状态时候正常。当这些工作执行结束之后开始对每个文件进行读写,而一个读写过程需要多个操作,也就是多次的网络通信。但是读写过程其实只是进行了一次的通信。也就是说基本一次的读写,需要去多次的网络通信。这样当大量的小文件就会出现比大量的lookup->stat->open->read/write操作从而进行了很多次网络通信而正真意义上的read/write只是占了一小部分。这里需要介绍GlusterFS一个针对小文件设置的参数performance.quick-read,这个参数开启之后会在一次lookup时候会把小于64Kb的小文件读出来即合并lookup->stat->open->read/write多个操作为一个lookup操作。
目录创建流程
已知了GlusterFS的分布区间是保存在每一层目录的扩展属性下面的,而不同深度的目录下的区间是不一致的,上面也简单介绍了。而这样的目的主要是能够尽量去保证每个每个节点都容量分布均匀。
GlusterFS在首次挂载客户端时候才会对brick节点进行根节点的区间分布而后在创建目录时候又会对目录进行区间分布,在实际上不管是首次挂载目录还是创建目录时候的划分区间都是用的用一个函数。现在根据mkdir操作去了解目录创建过程和如何分布区间的。
创建目录的主要步骤有:
1) 根据目录名计算哈希值,由其哈希值所在的hash区间确定hashed卷。
2) 向hashed卷下发mkdir操作。
3) 待hashed卷返回后,再向除hashed卷之外的所有子卷下发mkdir操作。
4) 待所有子卷均返回后,合并目录属性。
5) 为每个子卷在该目录上分配hash区间。
6) 将各自的hash区间写入子卷上该目录的扩展属性中。
7) 创建目录结束。
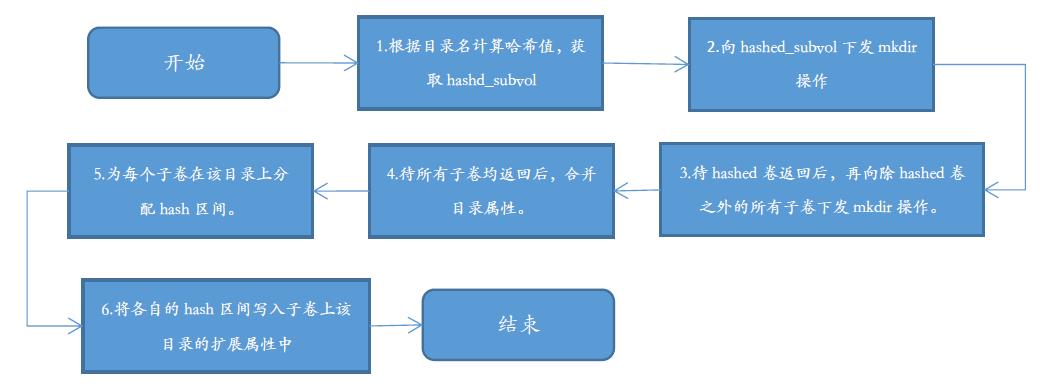
根据上图的流程,这里主要分析的第6步的过程,既是分析如果在各个目录划分区间的,而像第1步这样的过程可以参考“hash值计算流程”这个小节。现在重点是分析第6步这个流程图。
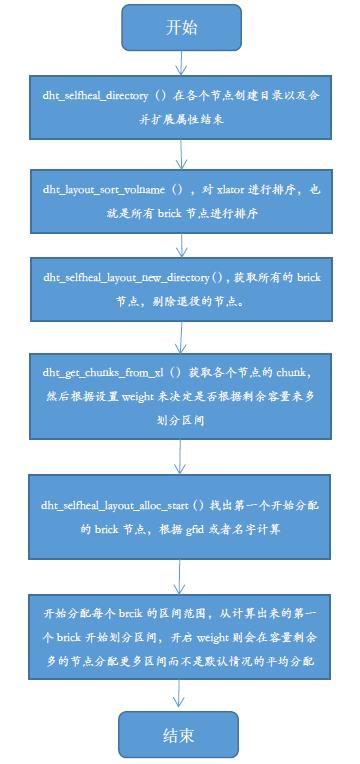
这里根据创建目录流程了解GlusterFS文件是如何划分每个目录的区间,所以省略部分流程。如根据节点容量作为权重划分,锁机制,退役节点检查,出现异常情况节点没有启动等情况。
上图右边是可以看出GlusterFS是如何根据文件名计算出一个2^32范围的整型数字,根据父目录的区间定位节点。左边是目录在创建时候的的流程,在查找目录所落在的节点最先创建目录,接着会依次在每个节点创建相同的目录,根据整个路径计算,确定开始节点,最后依次对每个节点进行分配区间。如果开启了weight by size功能,在分配区间大小时候会根据剩余容量去划分区间的数值范围。
文件定位程序
根据上面的基本了解,可以不依赖GlusterFS实现一个定位文件的程序,只要给定一个文件的绝对路径,这样就可以知道文件落在的集群中的具体哪个节点。对于一些应用,需要知道监控文件所在的服务器从而去监控文件的变化以及在备份时候一致等这些问题还是很有帮助的。实现文件定位的需要解决几个问题:
1. 文件计算成2^32次方的hash值
2. 知道目录的分布区间值
3. 知道文件的brick节点关系,是副本还是纠删码
xdfs_locate是基于GlusterFS文件定位算法原理实现的一个独立定位小程序,这里简要介绍一下xdfs_locate文件定位的程序流程。
1. 首先会有一个配置文件保存这个卷的信息:卷模式,brick节点数,根brick节点的区间范围。当执行xdfs_locate运行之后,先获取配置文件的信息,获得卷信息,brick节点的分布区间保存到一个layout结构体。保存了layout区间分布,卷类型。
2. 实现Davies-Meyer算法,计算文件的hash值。
3. 实现目录分配区间的功能,首先配置文件保存了根节点的分布区间,当需要计算根目录下的目录时候,则根据Davies-Meyer算法计算所在的节点,然后根据最开始的落点平均给各个目录计算区间构建一个完整的区间。
4. 创建了文件的上层目录的分布区间之后,计算文件的hash值,确定文件hash值在那个区间,输出这个区间的ip,挂载点,brick对应关系。
举个例子:查找 /taocloud/xdfs/nas/file的落点。
程序执行如下: xdfs_locate dht-vol /taocloud/xdfs/nas/file
1. xdfs_locate为程序名,dht-vol为卷名,/taocloud/xdfs/nas/file为绝对路径。程序运行,首先在配置文件中获取相应卷的根目录挂载点的分布区间保存到layout_t当中,切割/taocloud/xdfs/nas/file 路径项目为 taocloud , xdfs, nas, file。
2. 计算taocloud的hash值,根据根节点的区间分布,确定落在哪个节点上,从最开始的落点开始对taocloud分布区间保存到新的layout_t当中。同理xdfs根据taocloud确定分布区间的layout_t,nas根据xdfs确定layout_t。
3. 这时候确定了file父目录nas的分布式区间情况,计算file的hash值。遍历nas的layout_t的区间值,确定file的hash值落在哪个区间范围内。
4. 最后根据file确定的nas区间映射到根据点的区间,输入相应的brick节点,ip。
最后总结一下Hash文件分布算法的优点:
1. 在每一层目录下去保存节点的区间,这个能够更均衡的保证节点之间容量的平衡。
2. 文件名转化key值时候使用 Davies-Meyer算法可以在极短的时间计算出来。
3. 增加节点时候提供了两种方式的扩容方式,可以避免出现大量数据迁移。
4. 当文件落在不相同节点情况下,多用户多客户端多线程情况下,性能会极大的发挥服务端性能。
Hash文件分布算法也会导致一些问题:
1. 因为每一层目录重新划分区间,这样文件在访问深层的目录时候,需要一层一层目录的查看。假如目录深度到达了十层,客户端需要跟服务端通信至少十次才能确定文件的落点,这样导致了性能下降,网络延迟加大,iops会降低。
2. 区间保存在目录的扩展属性,各个节点之间都有相同的目录,这时候需要保证元数据的一致性以及区间是否出现了重合等情况,当某个目录出现元数据毁坏,这时候需要去修复,而GlusterFS是触发机制,当访问到时候才会去同步修复,这样会导致读写性能下降。
3. 在实际的应用场景,文件名有大部分会是相似的,而Davies-Meyer算法计算相似的文件名很大概率数字是相近的。
4. 遍历目录慢,ls会出现极慢问题。
以上是关于GlusterFS文件系统弹性哈希算法的主要内容,如果未能解决你的问题,请参考以下文章