编译原理--词法分析器(python语言实现)
Posted 不是祸津神的夜斗
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了编译原理--词法分析器(python语言实现)相关的知识,希望对你有一定的参考价值。
词法分析器
最近在学习编译原理。由于实验要求有词法分析器,这里我就先记录一下词法分析器实现过程以及具体思路。
目标语言
此处我选择的目标语言是c语言的子集来进行词法分析。
实现语言
此处我选用的语言是python,主要还是考虑到python的数据结构比较强大而且包容性强。并且我pyqt用的比较熟练,很容易设计出GUI界面。关于pyqt的相关内容网上资料比较少对初学者不是很友好,我下面会出一些关于pyqt的教程,还望持续关注!
词法分析器主要工作
- 从源程序文件中读入字符
- 统计行数和列数用于进行错误定位
- 识别出单词并用(内码,属性)二元式表示
- 识别出错误记录报告错误但不会终止扫描
- 填写标识符表
设计思路
词法分析不必要设计成单独的一遍,我认为词法分析器应该设计成一个子程序,每当语法分析需要一个单词符号时,那么此时向词法分析器传递一个输入串,词法分析器便要能分析出这个输入串中的单词。
设计流程图

算法思路
对于单词的分析关键在于第一个字符的性质。第一个字符的性质决定了下面的单词分析进程。如果第一个字符是一个数字那么下面这个单词就要判断是否为常量。接下来读取的如果是字符除了是e或E其他字符都可以直接判断此单词非法为error。因此这里可以将其单独分离出一个函数,这里我取名为isDigit()函数。其他包括标识符的判定以及算术或逻辑运算符的判定也可以按照此思路分离出相应的函数。
函数表
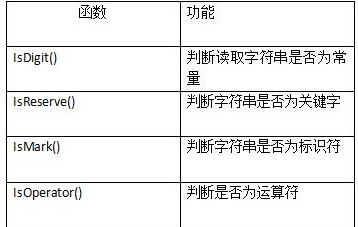
源程序代码
一些初始设定
self.reserveWord = ["auto", "break", "case", "char", "const", "continue",
"default", "do", "double", "else", "enum", "extern",
"float", "for", "goto", "if", "int", "long",
"register", "return", "short", "signed", "sizeof", "static",
"struct", "switch", "typedef", "union", "unsigned", "void",
"volatile", "while"] # c++中的关键字
self.operatorOrDelimiter = ["+", "-", "*", "/", "<", "<=", ">", ">=", "=", "==",
"!=", ";", "(", ")", "^", ",", "\\"", "\\'", "#", "&",
"&&", "|", "||", "%", "~", "<<", ">>", "[", "]", "",
"", "\\\\", ".", ":", "!"] # c++中的一些符号
self.Delimiter = [";", "(", ")", ",", "#", "[", "]", "", "", "\\\\"]
self.RelationOperation = ["<", "<=", ">", ">=", "=", "==", "!=", "^", "&", "&&", "|", "||", "<<", ">>", "!"]
self.Operator = ["+", "-", "*", "/", "%", "~", "+=", "*=", "/=", "-=",
"++", "--"]
处理开头以数字开头的字符串
这里分为四种情况
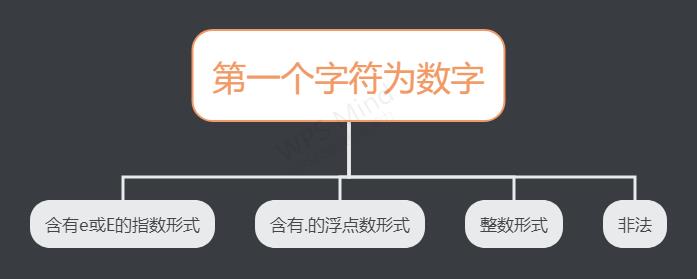
部分代码
// 判断数字代码
def IsDigits(self, inString, pos):
flag = False
for i in inString:
pos += 1
if i.isdigit():
self.token += str(i)
flag = True
elif i == '.' and i not in self.token and 'e' not in self.token and 'E' not in self.token:
self.token += str(i)
elif i == 'e' or i == 'E' and i not in self.token: # 处理含E或e的合法指数情况
self.token += str(i)
else:
if i in self.operatorOrDelimiter or i == ' ' or i == '\\n':
flag = True
else:
flag = False
break
return flag, pos
对应的scan()函数中处理数字开头的代码
if inString[0].isdigit():
judge, index = self.IsDigits(inString, 0)
if judge:
"""if '.' in self.token: # 此处是对常量的转化过程此处写成注释
print("--------")
print(float(self.token))
print("--------")
elif 'e' not in self.token and 'E' not in self.token:
print("--------")
print(int(self.token))
print("--------")
else:
num1 = 0
num2 = 0
if 'E' in self.token:
l = self.token.split('E')
if '.' in l[0]:
num1 = float(l[0])
else:
num1 = int(l[0])
num2 = int(l[1])
elif 'e' in self.token:
l = self.token.split('e')
if '.' in l[0]:
num1 = float(l[0])
else:
num1 = int(l[0])
num2 = int(l[1])
for i in range(0, num2):
num1 *= 10
print("--------")
print(num1)
print("--------")"""
self.result.append([self.token, "常数", (row, col)])
else:
self.result.append([self.token, "ERROR", (row, col)])
if index - 1 < len(inString) and index - 1 > 0:
if index == len(inString):
print(inString[len(inString) - 1])
self.scan(inString[len(inString) - 1], row, col)
else:
self.scan(inString[index - 1:], row, col)
处理以字母开头的字符串
此处以字母开头的字符串可能出现的情况为:
- 标识符
- 关键字
- 非法字符串
对于这里的判断要注意几种情况:
- 类似i++这种一个标识符后面跟着算术或逻辑运算符
- i;后面跟着终结符这种比较好判断
- 单独的一个标识符或关键字 如 int这种。
部分代码
def isReserve(self, target): # 判断是否为关键字
if target in self.reserveWord:
return True
return False
def isMark(self, inString, pos):
flag = False
for i in inString:
pos += 1
if i.isalpha() or i.isdigit() or i == '_':
self.token += str(i)
flag = True
elif i in self.operatorOrDelimiter: # 遇到算术/逻辑/分隔符结束搜索
flag = True
break
else:
flag = False
return flag, pos
对应scan()中以字母开头部分代码
elif inString[0].isalpha():
judge, index = self.isMark(inString, 0)
if self.isReserve(self.token):
self.result.append([self.token, "关键字", (row, col)])
else:
self.result.append([self.token, "标识符", (row, col)])
if index <= len(inString) and not inString[index - 1].isalpha():
self.scan(inString[index - 1:], row, col)
elif inString[0] == '\\'':
judge, index = self.isChar(inString, 0)
if judge:
self.result.append([self.token, "字符常量", (row, col)])
if index < len(inString) and index - 1 >= 0:
self.scan(inString[index - 1:], row, col)
elif inString[0] == '\\"':
judge, index = self.isString(inString, 0)
index = index + 1 # 最后一个”不能算
if judge:
self.result.append([self.token, "字符串常量", (row, col)])
if index < len(inString) and index - 1 >= 0:
self.scan(inString[index - 1:], row, col)
elif inString[0] in self.Operator or inString[0] in self.RelationOperation:
index = self.IsOperator(inString, 0)
if self.token in self.Operator:
self.result.append([self.token, "算术运算符", (row, col)])
elif self.token in self.RelationOperation:
self.result.append([self.token, "关系运算符", (row, col)])
else:
self.result.append([self.token, "ERROR", (row, col)])
if index <= len(inString) and index - 1 >= 0:
self.scan(inString[index - 1:], row, col)
处理一些算术/逻辑运算符的情况
这里主要是考虑如下一些情况
- 运算符在开头这里也是有可能的比如 ++i;这在c以及c++中均为合法语句,词法分析器应该能够识别出这一个串中的++、i单词
- 运算符在内部,这也是有可能的比如a+b,词法分析器也要识别出a、+、b这几个单词
部分代码
def IsOperator(self, inString, pos):
if len(inString) == 1:
self.token += str(inString[0])
return pos
for i in inString[0:]:
pos += 1
if i in self.operatorOrDelimiter:
self.token += str(i)
else:
break
return pos
scan()函数部分代码
elif inString[0] in self.Operator or inString[0] in self.RelationOperation:
index = self.IsOperator(inString, 0)
if self.token in self.Operator:
self.result.append([self.token, "算术运算符", (row, col)])
elif self.token in self.RelationOperation:
self.result.append([self.token, "关系运算符", (row, col)])
else:
self.result.append([self.token, "ERROR", (row, col)])
if index <= len(inString) and index - 1 >= 0:
self.scan(inString[index - 1:], row, col)
至此一些关键处理代码已经实现,并经过测试后是可以使用的,上面代码部分只是我的思路,我使用了递归调用,这会有一个缺点就是无法更好的得出当前处理的位置,仍需改进。


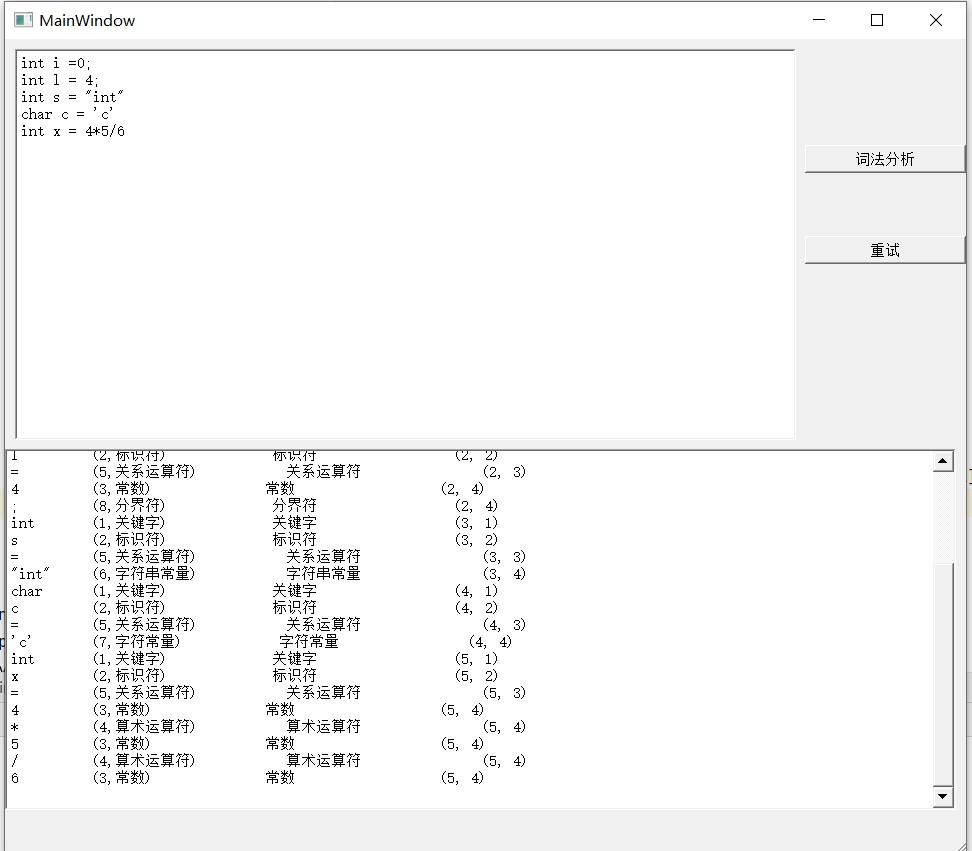
运行测试图片
更新内容
我加入了GUI界面并对其进行了代码优化,优化的代码在上面已经进行了更新。下面贴出整体GUI部分代码
# -*- coding: utf-8 -*-
# Form implementation generated from reading ui file 'analysis.ui'
#
# Created by: PyQt5 UI code generator 5.15.4
#
# WARNING: Any manual changes made to this file will be lost when pyuic5 is
# run again. Do not edit this file unless you know what you are doing.
from PyQt5 import QtCore, QtGui, QtWidgets
class Ui_MainWindow(object):
def setupUi(self, MainWindow):
MainWindow.setObjectName("MainWindow")
MainWindow.resize(961, 816)
self.centralwidget = QtWidgets.QWidget(MainWindow)
self.centralwidget.setObjectName("centralwidget")
self.code = QtWidgets.QTextEdit(self.centralwidget)
self.code.setGeometry(QtCore.QRect(10, 10, 781, 391))
self.code.setObjectName("code")
self.result = QtWidgets.QTextEdit(self.centralwidget)
self.result.setGeometry(QtCore.QRect(0, 410, 951, 361))
self.result.setObjectName("result")
self.gridLayoutWidget = QtWidgets.QWidget(self.centralwidget)
self.gridLayoutWidget.setGeometry(QtCore.QRect(800, 50, 161, 231))
self.gridLayoutWidget.setObjectName("gridLayoutWidget")
self.gridLayout = QtWidgets.QGridLayout(self.gridLayoutWidget)
self.gridLayout.setContentsMargins(0, 0, 0, 0)
self.gridLayout.setObjectName("gridLayout")
self.pushButton = QtWidgets.QPushButton(self.gridLayoutWidget)
self.pushButton.setObjectName("pushButton")
self.gridLayout.addWidget(self.pushButton, 0, 0, 1, 1)
self.pushButton_2 = QtWidgets.QPushButton(self.gridLayoutWidget)
self.pushButton_2.setObjectName("pushButton_2")
self.gridLayout.addWidget(self.pushButton_2, 1, 0, 1, 1)
MainWindow.setCentralWidget(self.centralwidget)
self.menubar = QtWidgets.QMenuBar(MainWindow)
self.menubar.setGeometry(QtCore.QRect(0, 0, 961, 26))
self.menubar.setObjectName("menubar")
MainWindow.setMenuBar(self.menubar)
self.statusbar = QtWidgets.QStatusBar(MainWindow)
self.编译原理实验:实验一 简单词法分析程序设计(必修)(Python实现)
一、实验目的
了解词法分析程序的基本构造原理,掌握词法分析程序的手工构造方法。
二、实验内容
1、了解编译程序的词法分析过程。
2、根据PASCAL语言的说明语句形式,用手工方法构造一个对说明语句进行词法分析的程序。该程序能对从键盘输入或从文件读入形如:
“const count=10,sum=81.5, char1=’f’, string1=”hj”,max=169;”
的常量说明串进行处理,分析常量说明串中各常量名、常量类型及常量值,并统计各种类型常量个数。
三、实验要求
1、输入的常量说明串,要求最后以分号作结束标志;
2、根据输入串或读入的文本文件中第一个单词是否为“const”判断输入串或文本文件是否为常量说明内容;
3、识别输入串或打开的文本文件中的常量名。常量名必须是标识符,定义为字母开头,后跟若干个字母,数字或下划线;
4、根据各常量名紧跟等号“=”后面的内容判断常量的类型。其中:字符型常量定义为放在单引号内的一个字符;字符串常量定义为放在双引号内所有内容;整型常量定义为带或不带+、- 号,不以0开头的若干数字的组合;实型常量定义为带或不带+、- 号,不以0开头的若干数字加上小数点再后跟若干数字的组合;
5、统计并输出串或文件中包含的各种类型的常量个数;
6、以二元组(类型,值)的形式输出各常量的类型和值;
7、根据常量说明串置于高级语言源程序中时可能出现的错误情况,模仿高级语言编译器对不同错误情况做出相应处理;
代码实现:考虑到Python的正则表达式的强大,我就用了Python来实现,也正好练练自己的Python代码能力,学习Python这么久了,自己还没用Python正式写过项目,实在不敢说自己学过Python。
考虑到实验内容,我分别用了几个函数来提取const关键字,提取每一个常量定义的句子,和提取变量标识符,和判断变脸的类型。
代码如下:
1 import re
2 """5个做统计的全局变量"""
3 int_num = 0
4 char_num = 0
5 string_num = 0
6 float_num = 0
7 bool_num = 0
8 """用来去掉正则时产生的 中括号 以及 分号 ‘ """
9 def myReplace(s):
10 s = s.replace(‘[\‘‘,‘‘)
11 s = s.replace(‘\‘]‘,‘‘)
12 s = s.replace(‘[‘,‘‘)
13 s = s.replace(‘]‘,‘‘)
14 return s
15 """判断是否是bool型常量"""
16 def IsBool(s,currn):
17 s = s + ‘ ‘
18 global bool_num
19 bool_error = re.findall(r‘= *([a-z]+ +[^ ]+) ‘,s,0)#优先匹配错误情况,比如 x = true hdfkjg(中间空格分开的字符)
20 if(bool_error):
21 return False
22 bool_T = re.findall(r‘= *(true) ‘,s,0)#匹配true情况
23 if(bool_T):
24 print(currn+‘(bool,‘+bool_T[0]+‘)‘)
25 bool_num = bool_num + 1
26 return True
27 bool_F = re.findall(r‘= *(false) ‘,s,0)#匹配false情况
28 if(bool_F):
29 print(currn + ‘(bool,‘ + bool_F[0] + ‘)‘)
30 bool_num = bool_num + 1
31 return True
32
33 """判断是否是字符串常量"""
34 def IsStrings(s,currn):
35 global string_num
36 String = (re.findall(‘=[\ ]*([\“|\"][^\“\"]*[\”|\"])[\ |,|;]*‘,s,0))
37 for strings in String:
38 strings = str(strings)
39 if(strings):
40 print(currn+‘(string,‘+strings+‘)‘)
41 string_num = string_num + 1
42 return True
43 else:
44 return False
45 """判断是否是字符常量"""
46 def IsChar(s,currn):
47 Char = re.findall(‘=\ *([\‘|\‘][^\‘\‘\’]+[\’|\‘])‘,s,0)
48 global char_num
49 for C in Char:
50 C = str(C)
51 if(C):
52 if(len(C)==3):
53 print(currn+‘(char, ‘+C+‘)‘)
54 char_num = char_num + 1
55 else:
56 print(currn+‘(Wrong! There are more than one char in ‘’.)‘)
57 return True
58 else:
59 return False
60
61 """判断是否是浮点数常量"""
62 def IsFloat(s,currn):
63 s = s + ‘ ‘
64 global float_num
65 Float_first = re.findall(r‘= *([+|-]?0?.[0-9]+) ‘,s,0)#匹配整数部分为0或者没有的情况的情况
66 if(Float_first):
67 print(currn+‘(float,‘+Float_first[0]+‘)‘)
68 float_num = float_num + 1
69 return True
70 Float_0 = re.findall(r‘= *([+|-]?0[0-9]+.[0-9]+) ‘,s,0)#匹配整数部分以0开始的错误情况
71 if(Float_0):
72 print(currn + ‘(Wrong! The float can’t be started with ‘0’.)‘)
73 return False
74 Float_E = re.findall(r‘= *([+|-]?[1-9].[0-9]+[E|e]-[1-9][0-9]*) ‘,s,0)#匹配正确的实型科学计数法,未考虑错误情况
75 if(Float_E):
76 print(currn + ‘(float,‘ + Float_E[0]+ ‘)‘)
77 float_num = float_num + 1
78 return True
79 Float = str(re.findall(r‘\=[\ ]*([+|-]?[0-9]*\.[0-9]+) ‘,s,0))
80 Float = myReplace(Float)
81 if(Float):
82 print(currn+‘(float,‘+Float+‘)‘)
83 float_num = float_num + 1
84 return True
85 else:
86 return False
87
88 """判断是否是整形常量"""
89 def IsInt(s,currn):
90 s = s + ‘ ‘
91 global int_num
92 Int_E = re.findall(r‘= *([+|-]?[1-9].[0-9]+[E|e][+][1-9][0-9]*) ‘,s,0)#匹配整型为科学计数法的情况,未考虑错误情况
93 if(Int_E):
94 print(currn + ‘(integer,‘ + Int_E[0] + ‘)‘)
95 int_num = int_num + 1
96 return True
97 Int_first = re.findall(r‘= *([0]) ‘,s,0)#匹配数值为0的情况
98 if(Int_first):
99 int_num = int_num + 1
100 print(currn + ‘(integer,‘ + ‘0‘ + ‘)‘)
101 return True
102 Int_0 = re.findall(r‘= *([+|-]?0[0-9]*) ‘,s,0)#匹配数值以0开头的情况(已去掉单个0情况)
103 if(Int_0):
104 print(currn + ‘(Wrong! The integer can’t be started with ‘0’.)‘)
105 return False
106 Int = (str)(re.findall(r‘= *([+|-]?[1-9][0-9]*) ‘,s,0))
107 Int = myReplace(Int)
108 if(Int):
109 print(currn+‘(integer,‘+Int+‘)‘)
110 int_num = int_num + 1
111 return True
112 else:
113 return False
114 """判断变量名是否合法"""
115 def pd(s):
116 bian = str(re.findall(r‘ *([A-Za-z0-9_]*) *=‘,s,0))
117 bian = myReplace(bian)
118 if(bian and (not(bian[0]>=‘0‘and bian[0]<=‘9‘))):
119 return bian
120 else:
121 print(bian+‘(Wrong! It is not aidentifier!)‘)
122 return ‘0error‘
123 """获得const关键字"""
124 def getcon(s):
125 fir = re.findall(‘[\ ]*(const)\ ‘, s, 0)
126 if(len(fir) == 1):
127 return fir
128 else:
129 return ‘None‘
130 """获得变量的类型"""
131 def getType(s):
132 fir = (re.findall(r‘[ |,|,|]+?(.*?[^,;]+)[,|;]*?‘,s,0))#将输入正确的串按照 ,(逗号) 或者 ;(分号)分开,/
133 #操作后的fir就是一个个变量定义的集合 例如 [x = 1, y=2.2]
134 for men in fir:
135 currn = pd(str(men))#判断变量名是否合法,并取出合法的变量名,如果变量名不合法,currn=‘0error‘
136 if(currn==‘0error‘):
137 continue
138 else:
139 if(IsBool(men,currn)):
140 continue
141 if(IsStrings(men,currn)):
142 continue
143 if(IsChar(men,currn)):
144 continue
145 if(IsFloat(men,currn)):
146 continue
147 if(IsInt(men,currn)):
148 continue
149
150 """Main 函数入口"""
151 if __name__ == ‘__main__‘:
152 while(True):
153 bool_num = int_num = float_num = char_num = string_num = 0
154 st = input()
155 fir = getcon(st)#获得const标识符
156 if(fir!=‘None‘):
157 getType(st)
158 print("int_num=%d; char_num=%d; string_num=%d; float_num=%d; bool_num=%d."%(int_num,char_num,string_num,float_num,bool_num))
159 else:
160 print(‘It is not a constant declaration statement!‘)
161 print(‘Please input a string again!‘)
162
163
164 """
const count=10,sum=81.5,char1=‘f’,max=169,str1=“h*54 2..4S!AAsj”, char2=‘@’,str2=“aa!+h”;
count(float,10)
sum(float,81.5)
char1(char, ‘f’)
max(float,169)
str1(string,“h*54 2..4S!AAsj”)
char2(char, ‘@’)
str2(string,“aa!+h”)
int_num=0; char_num=2; string_num=2; float_num=3; bool_num=0.
Aconstt count=10,sum=81.5,char1=‘f’;
It is not a constant declaration statement!
Please input a string again!
const count=10,12sum=81.5,char1=‘ff’,max=0016;
count(float,10)
12sum(Wrong! It is not aidentifier!)
char1(Wrong! There are more than one char in ‘’.)
max(float,0016)
int_num=0; char_num=0; string_num=0; float_num=2; bool_num=0.
const dx = 1.27e+7,de = 1.27e-21,dd=89.7,fdg=678.6.7.6,4554, rtrtryt=.9898,gfgffggf=8.45,rt = +11.23,rr = -0.01,ry=-00.11;
dx(integer,1.27e+7)
de(float,1.27e-21)
dd(float,89.7)
(Wrong! It is not aidentifier!)
rtrtryt(float,.9898)
gfgffggf(float,8.45)
rt(float,+11.23)
rr(float,-0.01)
ry(Wrong! The float can’t be started with ‘0’.)
int_num=1; char_num=0; string_num=0; float_num=6; bool_num=0.
const x = 1,y=2.2,z=‘u‘,u="hdfjksah",dd=true,dt=false,ry=true ,ri= false , zx = true ui,mr = false dslk;
x(float, 1)
y(float,2.2)
z(char, ‘u‘)
u(string,"hdfjksah")
dd(bool,true)
dt(bool,false)
ry(bool,true)
ri(bool,false)
int_num=0; char_num=1; string_num=1; float_num=2; bool_num=4.
const x = 1,y=2.2,z=‘u’,u="hdfjksah";
It is not a constant declaration statement!
Please input a string again!
x(float, 1)
y(float,2.2)
z(char, ‘u’)
u(string,"hdfjksah")
int_num=0; char_num=1; string_num=1; float_num=2; bool_num=0.
"""
六、分析与讨论
1、若考虑用E或e的科学计数法来表示整数和实数,应该如何实现?
2、若考虑布尔型常量,且规定其值只能为true或false,应该如何实现?
3、如何对手工构造的词法分析程序做进一步的优化,以提高代码质量和运行效率?
优化咋办还没有考虑,希望大神帮忙指点。