使用Python的pandas库操作Excel
Posted 软件开发技术爱好者
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了使用Python的pandas库操作Excel相关的知识,希望对你有一定的参考价值。
使用Python的pandas库操作Excel
最近因需要用Excel电子表格处理数据,使用了其它一些方式处理Excel文件数据,这是学习笔记的整理。
Excel2003及以前版:列数最大256(2的8次方)列,行数最大65536(2的16次方)行;Excel2007及以后版:列数最大16384(2的14次方),行数最大1048576(2的20次方);
获取Excel最大行和最大列的方法:
启动Excel后通过快捷键Ctrl+方向键(←↑↓→),可以定位到最左、最上、最下、最右的单元格,从而可以看到行和列的最大值。
Python中有很多库可以操作Excel,像pandas、xlrd、xlwt、xlutils、openpyxl 等。
xlrd 库:读取 Excel 文件
xlwt 库:写入 Excel 文件
xlutils 库:操作 Excel 文件的实用工具,如复制、分割、筛选等
xlrd、xlwt、xlutils 库可以读写操作后缀为xls的excel文件。
openpyxl库 :操作xlsx后缀的excel文件,还要用到这个库。
本文主要介绍pandas。特别提示:
pandas 库是基于numpy库 的软件库,因此安装Pandas 之前需要先安装numpy库。默认的pandas不能直接读写excel文件,需要安装读、写库即xlrd、xlwt才可以实现xls后缀的excel文件的读写,要想正常读写xlsx后缀的excel文件,还需要安装openpyxl库 。
pandas库简介
pandas官网 https://pandas.pydata.org/
pandas 中文教程 https://www.gairuo.com/p/pandas-tutorial
pandas库是一个Python的核心数据分析支持库,它提供了强大的一维数组和二维数组处理能力,其非常擅长与处理二维表结构,带行列标签的矩阵数据,时间序列数据。pandas提供的两个主要数据结构一维数组(Series)和二维数组(DataFrame)强力的支撑着当今金融、统计、社会科学、工程等诸多领域的数据分析工作。通过pandas我们可以方便的操作数据的增、查、改、删、合并、重塑、分组、统计分析,此外pandas还提供了非常成熟的I/O工具,用于读取文本文件,excel文件,数据库等不同来源数据,利用超快的HDF5格式保存/加载数据。
Series是 pandas 常用的数据结构之一,它是一种类似于一维数组的结构,由一组数据值(value)和一组标签组成,其中标签与数据值之间是一一对应的关系。
Series 可以保存任何数据类型,比如整数、字符串、浮点数、Python 对象等,它的标签默认为整数,从 0 开始依次递增。Series 的结构图,如下所示:

DataFrame (数据帧)一个表格型的数据结构,既有行标签(index),又有列标签(columns),它也被称异构数据表,所谓异构,指的是表格中每列的数据类型可以不同,比如可以是字符串、整型或者浮点型等。其结构图示意图,如下所示:
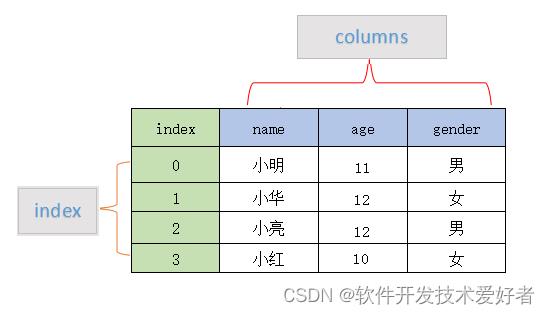
pandas中的数据结构和Excel文档属性的对应关系
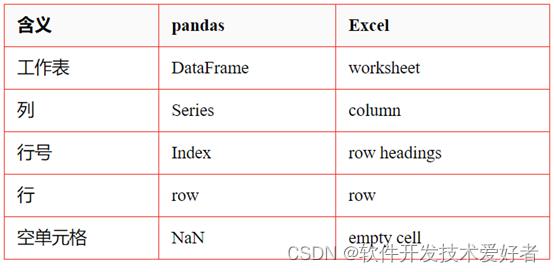
☆ pandas 中的 DataFrame 类似于 Excel 的工作表。但是Excel 工作簿可以包含多个工作表,而 pandas DataFrame 是独立存在的。
☆ Series 表示 DataFrame 的一列数据结构,使用Series类似于引用电子表格的一列。
每个 DataFrame 和 Series 都有一个Index,它是数据行上的标签。
☆ 在 pandas 中,如果未指定索引,则默认使用 RangeIndex(第一行 = 0,第二行 = 1,依此类推),类似于电子表格中的行号(数字)。
pandas 也可以将索引设置为一个(或多个)唯一值,这就像在工作表中拥有一个用作行标识符的列。
索引值是固定的,所以如果对 DataFrame 中的行重新排序,行的标签也不会改变。
pandas库的安装
Python模块(库、包)安装命令格式:
[py -X.Y -m] pip install [-i 镜像网址] 模块(库、包)名
其中[]部分表示可先的
若安装了多个python版本,为指定Python版本安装模块(库、包),X.Y代表Python版本,多余的部分舍弃如3.8.1取3.8,3.10.5取3.10,即只取第二个点前的部分。仅安装了一个python版本不需要。
常用的镜像网址
清华:https://pypi.tuna.tsinghua.edu.cn/simple
阿里云:https://mirrors.aliyun.com/pypi/simple/
中国科技大学 https://pypi.mirrors.ustc.edu.cn/simple/
【详见 :https://blog.csdn.net/cnds123/article/details/104393385】
安装pandas 之前需要先安装numpy,在CMD中输入:
py -3.10 -m pip install -i http://mirrors.aliyun.com/pypi/simple/ numpy
我已安装过numpy,在此跳过
【查看python第三方模块(库、包)是否安装及其版本号
[py -X.Y -m] pip list
其中[]部分表示可选的,若安装了多个python版本,指定Python版本,查看由X.Y指定python版本关联的模块(库、包)情况】
要安装pandas库 ,打开cmd窗口,输入:
py -3.10 -m pip install -i http://mirrors.aliyun.com/pypi/simple/ Pandas
参见下图:
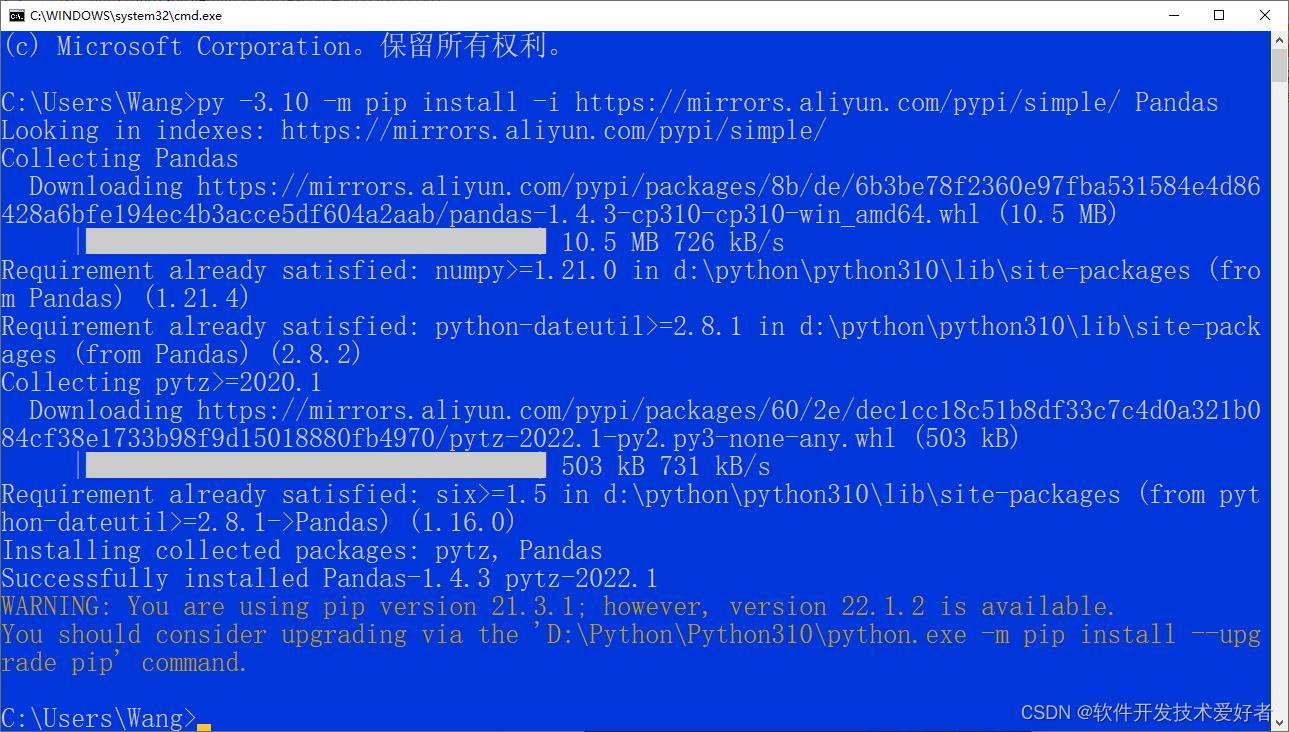
Successfully 表示成功了
WARNING部分大意是又可用的pip新的版本可以进行升级,可按提示中引号中的命令升级操作,也可不用管它
xlrd、xlwt、xlutils、openpyxl库的安装可参照上面的方法
安装成功后,我们就可以导入 pandas使用了。
pandas的基本操作
★数据读取
pandas读取excel的例子
test1.xlsx的内容如下:
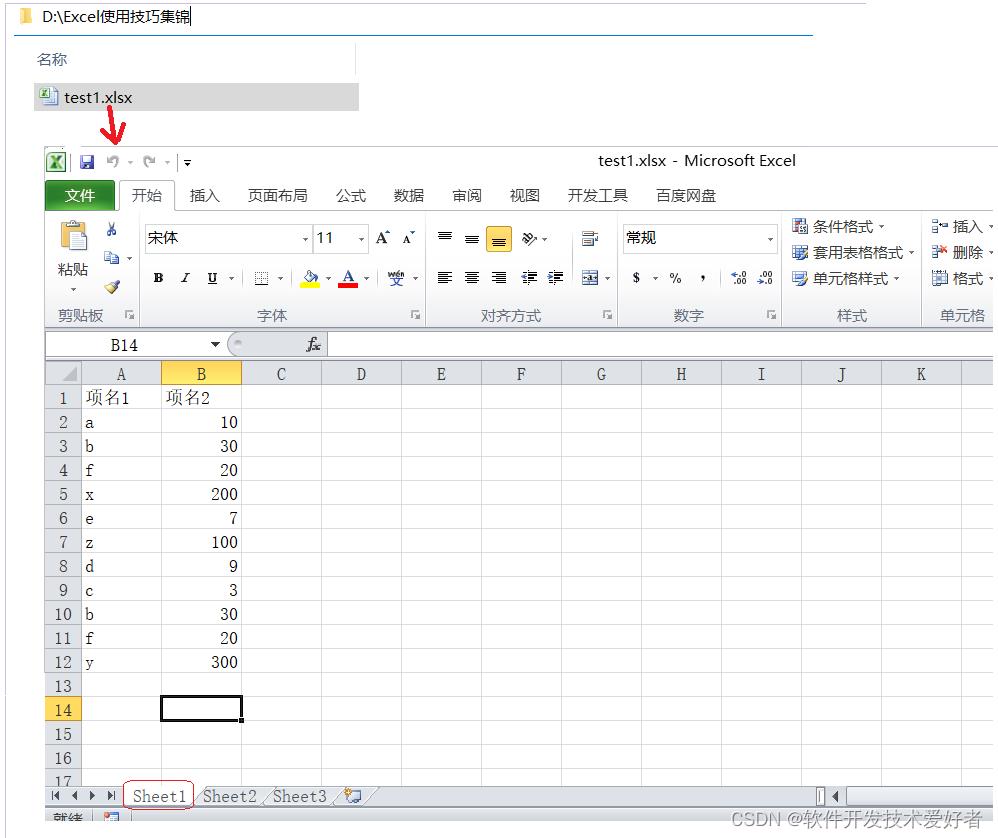
源码如下:
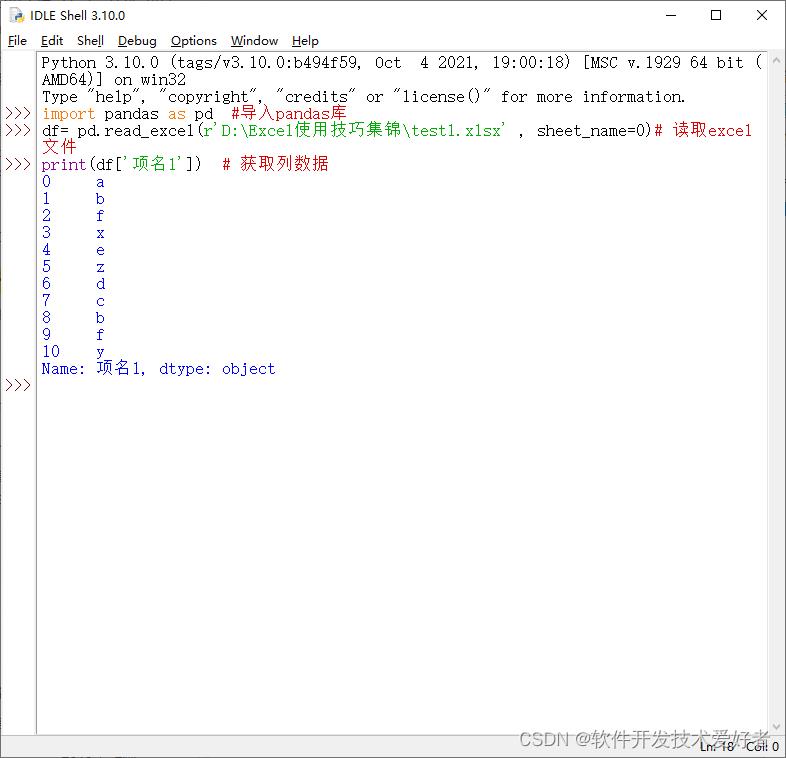
import pandas as pd
file = r'D:\\Excel使用技巧集锦\\test1.xlsx'
data = pd.read_excel(file)
print(data)
运行结果:

提示:
引号中是excel表格的文件路径和文件名,前面加“r”是为了防止python解释器对字符串字符转义处理。如果字符串中出现“\\t”,不加“r”的话“\\t”就会被转义,代表指制表符,代表着四个空格,也就是一个tab键,而加了“r”之后“\\t”就能保留原有的样子。
file = r'D:\\Excel使用技巧集锦\\test1.xlsx' ,若直接写为file ='D:\\Excel使用技巧集锦\\test1.xlsx'将报错!但可改写为 file = 'D:\\\\Excel使用技巧集锦\\\\test1.xlsx' 或file = 'D:/Excel使用技巧集锦/test1.xlsx'
read_excel()方法将Excel文件读取到pandas DataFrame中
有很多的参数详细介绍https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.read_excel.html
常用的参数有
第一个参数指定带路径的文件名(如果需要打开的文件在当前路径下,可以省略文件路径只写文件名)
sheet_name参数可以指定sheet页名称或位置,可用字符串表示工作表(sheet)名称,用 整数索引表示工作表位置,缺省默认0即第一个位置的,如:
df= pd.read_excel(r'D:\\Excel使用技巧集锦\\test1.xlsx' , sheet_name='sheet1')
处理数据
#导入pandas库
import pandas as pd
# 读取excel 文件
df= pd.read_excel(r'D:\\Excel使用技巧集锦\\test1.xlsx' , sheet_name='Sheet1')
★ 获取列数据
df['column_name']
例如:
★获取多列 多列中,df[] 括号里边是一个列表
df[['columns_name1','columns_name2']]
★ 获取行数据
df.loc[Line_number [,'column_name']]
其中,Line_number是行号,column_name是列名,可缺省,列名缺省获取整行
★整体数据排序
df.sort_values(by='columns_name',ascending = False)
★Panda DataFrame 对象提供了一个数据去重的函数 drop_duplicates(),即从数据帧中删除重复项
df.drop_duplicates()
to_excel()方法将DataFrame 的内容保存到excel文件
to_excel()方法参数很多 可参见https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.to_excel.html?highlight=to_excel
常用的参数是指定带路径的文件名(如果需要打开的文件在当前路径下,可以省略文件路径只写文件名)
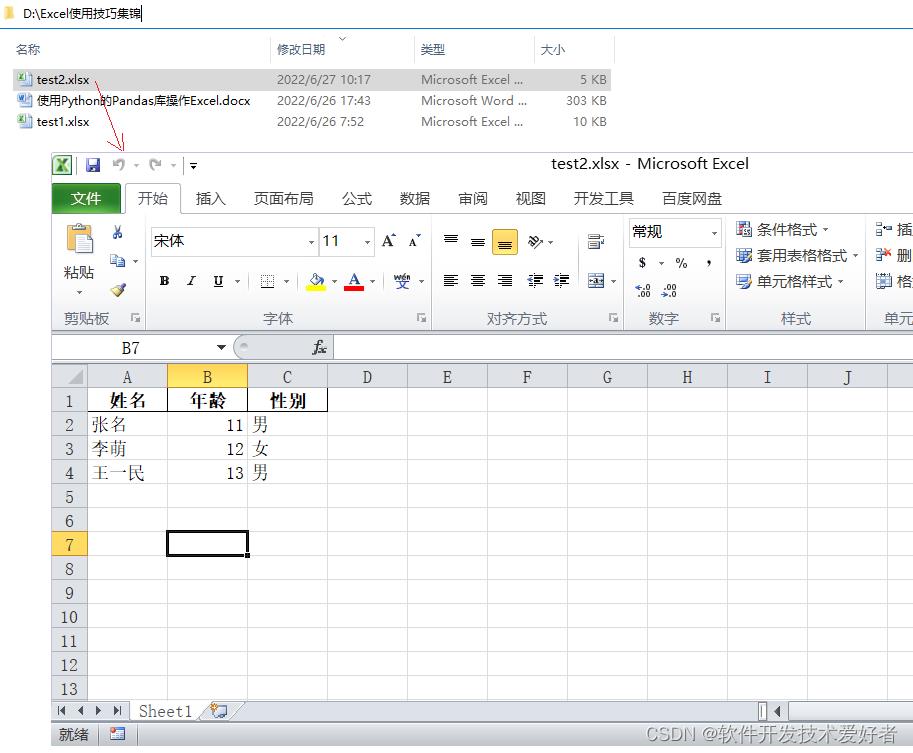
用to_excel()方法生成excel文件的简单示例如下:
import pandas as pd # 导入模块
data = '姓名': ['张名', '李萌', '王一民'], '年龄': [11, 12, 13], '性别': ['男', '女', '男']
df = pd.DataFrame(data)
df.to_excel(r'D:\\Excel使用技巧集锦\\test2.xlsx',index=False)
运行之,结果如下:
下面,给出一个去除重复行的数据保存的例
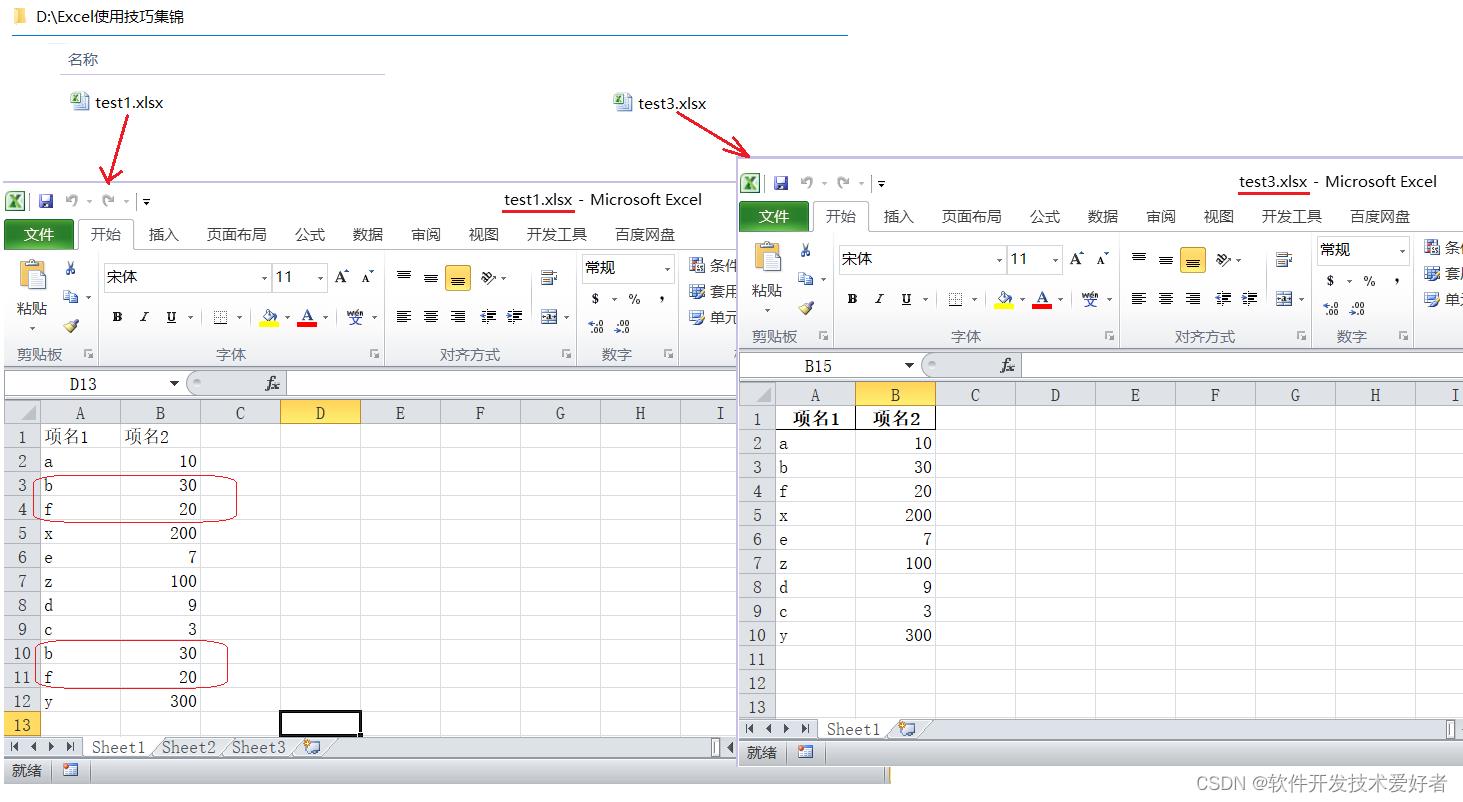
使用pandas读入test1.xlsx中Sheet1的数据删除重复行写入test3.xlsx的Sheet1中,源码如下:
import pandas as pd # 导入模块
# 读取excel 文件test1.xlsx
df= pd.read_excel(r'D:\\Excel使用技巧集锦\\test1.xlsx' , sheet_name='Sheet1')
#从数据帧中删除重复行
no_re_row=df.drop_duplicates()
#保存到test3.xlsx文件
no_re_row.to_excel(r'D:\\Excel使用技巧集锦\\test3.xlsx',index=False)
运行之,结果如下:
附录、进一步学习资料
利用Pandas来清除重复数据 https://blog.csdn.net/qq_42103091/article/details/104236873
pandas 处理excel表格数据的常用方法 https://blog.csdn.net/Flag_ing/article/details/124790461
操作Pandas和Excel表格的区别 https://blog.csdn.net/qq_45464895/article/details/124012761
Python学习:如何使用pandas分析excel数据(续)
1.问题
上篇,简单介绍了pandas库的使用,列出了常见操作的方法。本篇并不是继续讲述pandas库的使用,而是通过封装一个Excel类型,讲述如何封装第三方库,及其为何要封装。
2.方案
2.1.概述
Python的第三方库很多,很多库有官方文档,有的库文档齐全,直接使用也没多大问题。一般情况,我都会自己封装起来再使用,因为使用第三方库存在一定的风险。
封装的目的,主要有以下几个方面的考虑:
- 封装降低复杂性,我们可能只需要库的部分功能,屏蔽用哪些用不到的功能,防止误用。
- 封装提高可维护性和可替代性。第三方库可能有多个实现,也可能后续不再维护,如果代码到处充斥着第三方库的代码,后续维护比较麻烦。封装的好处,后续可以进行重新设计或者重构,上层调用的代码无需更改。
- 封装可以降低学习成本,让团队其他成员无需直接面对第三方库。
继续我们的正题。封装pandas,类型的名字叫Excel,暂且只支持xlsx和csv文件,对于其他文件类型,留给读者自行封装。
下面代码要用到的模块,都罗列到这里:
import pandas as pd
import numpy as np
# 用于类型注解
from typing import List, Union
用于测试的数据如下:
| 排名 | 车系 | 官方价 | 品牌 | 销量 |
|---|---|---|---|---|
| 1 | 哈弗H6 | 9.80-15.49万 | 哈弗 | 376864 |
| 2 | 长安CS75 | 10.69-15.49万 | 长安汽车 | 26682 |
| 3 | 本田CR-V | 16.98-27.68万 | 本田 | 249983 |
| 4 | 博越 | 8.98-14.68万 | 吉利汽车 | 24081 |
| 5 | 途观L | 21.58-28.58万 | 大众 | 178574 |
| 6 | 奇骏 | 18.88-27.33万 | 日产 | 175177 |
| 7 | RAV4荣放 | 17.48-25.98万 | 丰田 | 174940 |
| 8 | 探岳 | 18.69-26.49万 | 大众 | 169507 |
| 9 | 本田XR-V | 12.79-17.59万 | 本田 | 168272 |
| 10 | 昂科威 | 18.99-23.99万 | 别克 | 167880 |
2.2.文件读写
pandas读写’xlsx’和’csv’文件,是用不同的函数实现。我们是基于用户使用场景进行封装,因此合并一个函数。代码如下:
class Excel:
def __init__(self, df=None):
self.df = df
def read(self, file_name: str, sheet_name: str = "Sheet1", sep: str = ',', encoding='utf-8'):
if file_name.endswith('.xlsx'):
self.df = pd.read_excel(io=file_name, sheet_name=sheet_name)
elif file_name.endswith('.csv'):
self.df = pd.read_csv(io=file_name, sep=sep, encoding=encoding)
else:
raise Exception(
f'just support csv and xlsx type file: file_name')
def write(self, file_name: str, sheet_name: str = "Sheet1", sep: str = ',', encoding='utf-8'):
if file_name.endswith('.xlsx'):
self.df.to_excel(io=file_name, sheet_name=sheet_name)
elif file_name.endswith('.csv', sep=sep, encoding=encoding):
self.df.to_csv(file_name)
else:
raise Exception(
f'just support csv and xlsx type file: file_name')
csv本身是文本文件,有编码方式的区别,还有默认是用逗号,分隔的。因此,因此开放了sep和encoding参数,并且都提供了默认值。csv文件,只能由一个sheet,实现的时候完全可以忽略’sheet’。- 为了简单起见,本文中
xlsx文件只有一个sheet。
2.3.头和数据
Excel表数据,一般分为表头和数据,我们可以单独设置两个属性,分别可以返回表头和数据。
class Excel:
@property
def headers(self):
return self.df.column
@property
def values(self):
#注意这里反馈的类型
return self.df.values
-
只用
@property,是定义属性,有个好处是如果给属性赋值会出错。表头和表数据,我们不提供直接赋值的方法。 -
df.column和df.values都不是list类型,但都可以迭代。我们也可以转换成普通的类型返回,只是效率比较低。代码如下:
class Excel:
@property
def headers(self):
return self.df.column.to_list()
@property
def values(self):
ret = list()
for row in self.df.values:
col_data = list()
for col in row:
col_data.append(col)
ret.append(col_data)
return ret
验证代码:
xlsx = Excel()
xlsx.read('./data/2020-suv-top10.xlsx')
print(xlsx.headers)
print(xlsx.values)
输出结果如下:
['排名', '车系', '官方价', '品牌', '销量']
[[1 '哈弗H6' '9.80-15.49万' '哈弗' 376864]
[2 '长安CS75 PLUS' '10.69-15.49万' '长安汽车' 266824]
[3 '本田CR-V' '16.98-27.68万' '本田' 249983]
[4 '博越' '8.98-14.68万' '吉利汽车' 240811]
[5 '途观L' '21.58-28.58万' '大众' 178574]
[6 '奇骏' '18.88-27.33万' '日产' 175177]
[7 'RAV4荣放' '17.48-25.98万' '丰田' 174940]
[8 '探岳' '18.69-26.49万' '大众' 169507]
[9 '本田XR-V' '12.79-17.59万' '本田' 168272]
[10 '昂科威' '18.99-23.99万' '别克' 167880]]
2.4.行列数据
2.4.1.数据获取
Excel数据操作,最直接的诉求,就是获取行数据和列数据,因此我们按照行或者列的维度进行封装。代码如下:
def get_col_data(self, col_name: str):
return self.df[col_name]
def get_row_data(self, row_index: int):
return self.df.iloc[row_index]
同样,我们可以提供返回普通类型的实现:
def get_col_data(self, col_name: str):
return self.df[col_name].to_list()
def get_row_data(self, row_index: int):
ret = list()
for it in self.df.iloc[row_index]:
ret.append(it)
return ret
self.df.iloc[row_index]返回的字典类型,实际应用,获取行数据返回更偏向于返回一个list。for it in self.df.iloc[row_index]中的it,实际也不一定是普通类型,可以转换成str。pandas行数据获取,支持切片。获取行数据,同样可以设计成下面这种形式,是因为我们聚焦应用场景,不一定需要提供完整的切片使用方式,简单封装即可。def get_row_data(self, start, stop=None, step=None): return self.df.iloc[start:stop:step]
如果你是库的设计者,库会给很多人使用,倒是应该按照切片的方式封装,提高易用性。但,这也是双刃剑,提高易用性的同时,可能也提高了学习成本或者技术门槛。
每个语言都有自己的优秀特性,比如python的切片,用起来也很方便。但是,要完全支持切片,对于对python并不是很熟悉的情况下,要完全掌握切片的使用,对语言技能的要求会很高。因此封装的时候,要根据实际情况取舍,如果使用的人对python语言没有那么熟悉,简单封装即可。类似C语言的函数风格,容易理解,使用起来也不会很困难。
下面是验证代码:
xlsx = Excel()
xlsx.read('./data/2020-suv-top10.xlsx')
print(xlsx.get_col_data('品牌'))
print(xlsx.get_row_data(1))
输出如下:
['哈弗', '长安汽车', '本田', '吉利汽车', '大众', '日产', '丰田', '大众', '本田', '别克']
[2, '长安CS75 PLUS', '10.69-15.49万', '长安汽车', 266824]
2.4.2.数据修改
我们再来看行列数据的修改内容。修改行列数据的代码如下:
def set_col_data(self, col_name: str, col_data: list):
# 这里要确保col_data的长度与行数相当,可以增加检查
for index, data in enumerate(col_data):
self.df[col_name][index] = data
def set_row_data(self, row_index: int, row_data: list):
# 这里要使用Series类型(跟dict类似),row_data长度要与列个数相等
new_row = pd.Series(row_data, self.headers)
self.df.iloc[row_index] = new_row
链式调用越来越流行,我们封装的时候,可以考虑支持,只要让set函数返回对象的引用即可,当然也可以利用类型注解进行标注返回值。代码如下:
def set_col_data(self, col_name: str, col_data: list) -> "Excel":
# 这里要确保col_data的长度与行数相当,可以增加检查
for index, data in enumerate(col_data):
self.df[col_name][index] = data
return self
def set_row_data(self, row_index: int, row_data: list) -> "Excel":
# 这里要使用Series类型(跟dict类似),row_data长度要与列个数相等
new_row = pd.Series(row_data, self.headers)
self.df.iloc[row_index] = new_row
return self
测试代码下:
xlsx = Excel()
xlsx.read('./data/2020-suv-top10.xlsx')
print(xlsx.get_col_data('官方价'))
print(xlsx.get_row_data(2))
# 链式调用,可以一直调用下去
xlsx.set_col_data('官方价', ['0万' for x in range(10)]).set_row_data(2, [0, 0, 0, 0, 0])
print(xlsx.get_col_data('官方价'))
print(xlsx.get_row_data(2))
输出:
['9.80-15.49万', '10.69-15.49万', '16.98-27.68万', '8.98-14.68万', '21.58-28.58万', '18.88-27.33万', '17.48-25.98万', '18.69-26.49万', '12.79-17.59万', '18.99-23.99万']
[3, '本田CR-V', '16.98-27.68万', '本田', 249983]
['0万', '0万', 0, '0万', '0万', '0万', '0万', '0万', '0万', '0万']
[0, 0, 0, 0, 0]
2.4.3.数据插入
2.5.单元格数据
2.5.1.获取
单元格数据获取,比较简单,代码如下:
def get_cell_data(self, row_index, col_index):
return self.df.iloc[row_index][col_index]
验证代码:
xlsx = Excel()
xlsx.read('./data/2020-suv-top10.xlsx')
print(xlsx.get_cell_data(3,2))
输出如下:
8.98-14.68万
2.5.2.设置
单元格数据修改,代码如下:
def set_cell_data(self, row_index, col_index, cell_data):
self.df.iloc[row_index][col_index] = cell_data
return self
不过问题是上述代码,并没有修改单元格的值,问题是
self.df.iloc[row_index][col_index]返回的是数据拷贝。
通过整数形式的行号和列号获取和设置数据,只是我们容易理解的方式。但是对于pandas库,单元格设置,其中行可以是整数或字符串,但列却是字符类型(类似字典dict),对于列是整数形式好像没有直接支持。列支持整数形式,可以使得列可以重名(excel中,并没有假定列名不能一样),基于应用两者最好都要支持。代码重新设计如下:
def get_cell_data(self, row_index, col: Union[int, str]):
if type(col) is int:
return self.df.iloc[row_index][col]
else:
return self.df.at[row_index, col]
def set_cell_data(self, row_index, col: Union[int, str], cell_data):
if type(col) is int:
self.df.at[row_index, self.headers[col]] = cell_data
else:
self.df.at[row_index, col] = cell_data
return self
验证代码:
xlsx = Excel()
xlsx.read('./data/2020-suv-top10.xlsx')
print(xlsx.get_row_data(3))
xlsx.set_cell_data(3, 2, 'new data').set_cell_data(3, 3, 'haha')
print(xlsx.get_row_data(3))
输出:
[4, '博越', '8.98-14.68万', '吉利汽车', 240811]
[4, '博越', 'new data', 'haha', 240811]
2.6.数据筛选
pandas数据筛选是比较复杂也比较灵活。数据筛选,一般都是通过列进行筛选。
之前都是返回表行、列或者单元格数据,实际应用需要通过筛选一个列或者多个列,返回子表的数据,本节来实现这样的使用场景。
2.6.1.筛选
按照常用的过滤条件有=, >, >=, <, <=, in, not等,由于python不提供函数重载能力,因此用不同的函数来替代,代码如下:
def filter_eq(self, col_name, col_data):
df = self.df[self.df[col_name] == col_data]
return Excel(df)
def filter_not(self, col_name, col_data):
df = self.df[self.df[col_name] != col_data]
return Excel(df)
def filter_lt(self, col_name, col_data, eq=False):
if eq:
df = self.df[self.df[col_name] <= col_data]
else:
df = self.df[self.df[col_name] < col_data]
return Excel(df)
def filter_gt(self, col_name, col_data, eq=False):
if eq:
df = self.df[self.df[col_name] >= col_data]
else:
df = self.df[self.df[col_name] > col_data]
return Excel(df)
def filter_in(self, col_name: str, col_data):
df = self.df[col_name].str.contains(col_data, na=False, case=False)
return Excel(self.df[df])
过滤函数返回Excel对象,方便实现链式调用,使用起来比较方便。但上述过滤函数封装,还有很多限制,比如只能单列过滤,每次过滤只能过滤一个条件等等。
针对多列过滤,比较复杂,本文就不打算继续实施,pandas库非常完善,有兴趣的同学可以参考。
上述有一些操作可能需要支持多个值过滤,比如=操作,可以用车系=大众|奥迪|斯柯达表示德国大众的过滤条件。这个值得我们封装起来使用。代码如下:
def filter_eq(self, col_name, col_data):
if type(col_data) is not list:
df = self.df[self.df[col_name] == col_data]
return Excel(df)
df_list = list()
for it in col_data:
df = self.df[self.df[col_name] == it]
df_list.append(df)
# 这里用了合并数据,但是需要忽略index
df_result = pd.concat(df_list, ignore_index=True)
return Excel(df_result)
根据使用上的考虑,重新实现的过滤如下:
def filter_eq(self, col_name, col_data: Union[any, list]):
if type(col_data) is not list:
df = self.df[self.df[col_name] == col_data]
return Excel(df)
df_list = list()
for it in col_data:
df = self.df[self.df[col_name] == it]
df_list.append(df)
# 需要忽略index
df_result = pd.concat(df_list, ignore_index=True)
return Excel(df_result)
def filter_not(self, col_name, col_data):
df = self.df[self.df[col_name] != col_data]
return Excel(df)
def filter_lt(self, col_name, col_data, eq=False):
if eq:
df = self.df[self.df[col_name] <= col_data]
else:
df = self.df[self.df[col_name] < col_data]
return Excel(df)
def filter_gt(self, col_name, col_data, eq=False):
if eq:
df = self.df[self.df[col_name] >= col_data]
else:
df = self.df[self.df[col_name] > col_data]
return Excel(df)
def filter_in(self, col_name: str, col_data: Union[str, List[str]]):
if type(col_data) is not list:
return Excel(self.df[self.df[col_name].str.contains(col_data, na=False, case=False)])
con = ''
for it in col_data:
con = con + it + "|"
con = con[:-1]
return Excel(self.df[self.df[col_name].str.contains(con, na=False, case=False)])
def filter_notin(self, col_name: str, col_data: Union[str, List[str]]):
if type(col_data) 以上是关于使用Python的pandas库操作Excel的主要内容,如果未能解决你的问题,请参考以下文章