用Python怎么写 去掉文本文件的一行中重复的空格符号 的代码
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了用Python怎么写 去掉文本文件的一行中重复的空格符号 的代码相关的知识,希望对你有一定的参考价值。
import retext = ' 123 456 789 '
print re.sub(r'\\s2,', '', text)
删除连续2个(包括2个)以上的空格
参考技术A text.replace(" ", "")vscode Python环境调试输出很多没用的东西,怎么把这些东西去掉,如图
vscode Python环境调试输出很多没用的东西,怎么把这些东西去掉,如图除了hello,其余的都是没用的
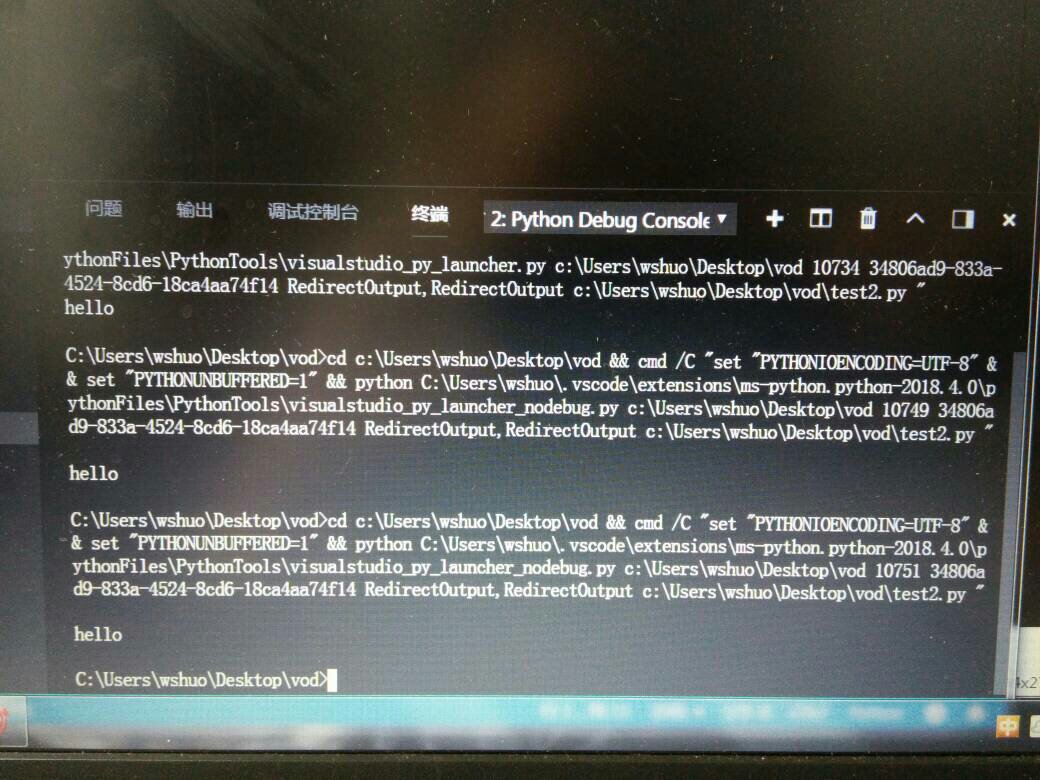
我的解决方案:用浏览器打开 txt文本,复制。在vscode或者任意编辑器下新建文件,粘贴保存即可。
下面是对txt文本的预处理,将全部文本分为120章节,保存为csv文件,代码如下:
简单解释: 首先读取全部文本,用正则表达式reg匹配章节,切分章节回, 去除内容小于200字的章节,最后为120章节,保存为csv文件。 提示:在spilt过程中,章节内容中也会出现匹配情况,全本搜索找到内容中的相关匹配项,删除即可。
首先是读取csv文件。 下面使用python的第三方库jieba分词, 基于tf-idf算法进行关键字提取。
tf-id:阮一峰
对该算法的理解可以参考上述博客,大概有3篇文章, 简单易懂。
简单解释: 第3行:使用算法对每个章节中最关键的1000个词进行关键词提取。 第4行:由于后续处理词向量的格式时空格加关键词, 所以进行简单转换。
输出如下:
下面使用sklearn中的CountVectorizer对上述提取的关键词生成词向量。
python代码实现可以参考我之前写的博客 机器学习之贝叶斯分类
其中简单介绍了如何构建词集或者词袋模型,生成词向量。
代码如下:
简单解释: 首先生成5000个特征的vertorizer, 对vorc进行训练转换, 得到120个词向量。
接着转为array形式,进行聚类。
这里做个假设:假定红楼梦前后不是一个人所写,那么用词方面也会有区别。通过聚类算法,如果得到的结果有明显的界限, 那么可以进行初步判断。下面是我的可视化过程: 代码如下:
简单解释:首先使用kmeans聚类算法,k=2分为两类,打印其类别。基于先前的假设,后四十回为高鹗缩写,因此在80回有明显的区分。 下面看结果:

可以看到前80回和后四十回有明显的区分,为了加强验证,可以将k设为不同的值,进行横向对比。 如下:
可视化结果如下:
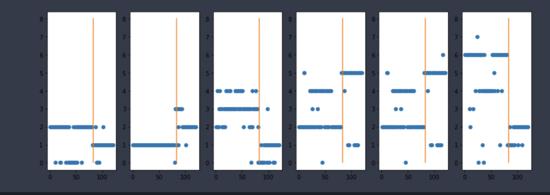
简单解释:
k分为为3, 4, 5, 6 ,7, 8。 首先查看第一图, 每一行的点表示分为同一类 ,可以看到同三类。可以看到后四十回中有少量的章节被分为0,2类,但是大部分还是归为一类,这就表示后十四回的行文风格与前80回有不同。 第二图是分为4类的情况,后面也基本得到类似的情况。 基于以上分析及横向比较,可以初步推断前80回合和后80回不是同一个人所写。
提出疑问:是否因为情节的变化,导致用词习惯,频率有所差异。 这里使用其他两部名著三国演义和水浒传来做个纵向对比。文本预处理,词向量生成都是一样的。具体可看我写的代码。最后的可视化结果如下: 首先是三国演义:

还是按照上面的分析:第一幅图中大概前83回与后面内容不一样。随着k的变化,比如k为4, 5, 6, 8, 部分章节前后章节无法做出明显的区分,因为初步判断为同一人所写。
水浒传的结果:
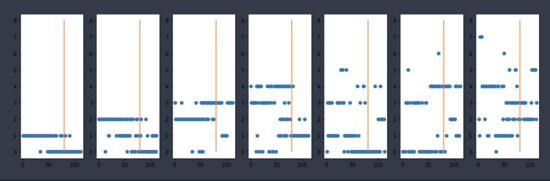
可以做自己的判断。
追问你TM的挺会复制粘贴啊
经验狗,你觉得我是新手吗?
傻B
参考技术A 可以试着把launch.json文件里关于python的配置内容里边的,"console": "integratedTerminal"修改为
"console": "none"。
这样去掉了中间过程的信息,但是缺点是似乎也没办法输入了。。。 参考技术B

你选择哪个external terminal就会在弹出窗口里面输出测试结果,和C++的那个IDE差不多
以上是关于用Python怎么写 去掉文本文件的一行中重复的空格符号 的代码的主要内容,如果未能解决你的问题,请参考以下文章