Pandas读写文件操作
Posted En^_^Joy
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Pandas读写文件操作相关的知识,希望对你有一定的参考价值。
文章目录
Pandas写入文件
开始运行可能会报错,需要先安装openpyxl库:pip install openpyxl
写入单个sheet
单个sheet是一个表格文件里面只有一个表格
Series写入
不管有没有a.xlsx,都不会报错,有则覆盖,无则创建
index参数:是否将索引写入
import pandas as pd
a = pd.Series([1, 2, 3],index=['A','B','C'])
# index false为不写入索引
a.to_excel('a.xlsx', sheet_name='Sheet1', index=False)

将index=False改为index=True之后,会将索引写入
import pandas as pd
a = pd.Series([1, 2, 3])
a.to_excel('a.xlsx', sheet_name='Sheet1', index=True)

DataFrame写入
import pandas as pd
a = pd.DataFrame(['a': 0, 'b': 0, 'a': 1, 'b': 2, 'a': 2, 'b': 4])
a.to_excel('a.xlsx', sheet_name='Sheet1', index=True)

import pandas as pd
a = pd.DataFrame(['a': 0, 'b': 0, 'a': 1, 'b': 2, 'a': 2, 'b': 4])
a.to_excel('a.xlsx', sheet_name='Sheet1', index=False)
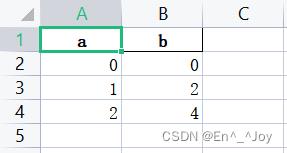
写入多个sheet
一个文件有多个表格
import pandas as pd
sheet1 = pd.DataFrame(['a': 0, 'b': 0, 'a': 1, 'b': 2, 'a': 2, 'b': 4])
sheet2 = pd.DataFrame(['c': 10, 'd': 10, 'c': 11, 'd': 12, 'c': 12, 'd': 14])
with pd.ExcelWriter('a.xlsx') as writer:
sheet1.to_excel(writer, sheet_name='Sheet1', index=False)
sheet2.to_excel(writer, sheet_name='Sheet2', index=False)


新增一个sheet
在ExcelWriter函数里面添加个模式参数mode='a',这样在新建的时候就不会把该文件中原有的表格给覆盖了
import pandas as pd
sheet3 = pd.DataFrame(['e': 40, 'f': 40, 'e': 41, 'f': 42, 'e': 42, 'f': 44])
with pd.ExcelWriter('a.xlsx', mode='a') as writer:
sheet3.to_excel(writer, sheet_name='Sheet3', index=False)
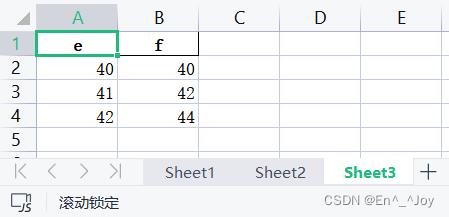
表格追加数据
在一个表格中加入两个数据,利用to_excel的参数startrow、startcol可以防止覆盖,to_excel的参数startrow、startcol为写入的起始行列。header为是否写入列名
import pandas as pd
a = pd.DataFrame(['Li':15,'Liu':26,'Wan':19])
b = pd.DataFrame(['a': 0, 'b': 0, 'a': 1, 'b': 2, 'a': 2, 'b': 4])
with pd.ExcelWriter('a.xlsx') as writer:
a.to_excel(writer, sheet_name='Sheet1', index=False, header=False, startrow=0, startcol=0)
b.to_excel(writer, sheet_name='Sheet1', index=False, header=False, startrow=3, startcol=0)
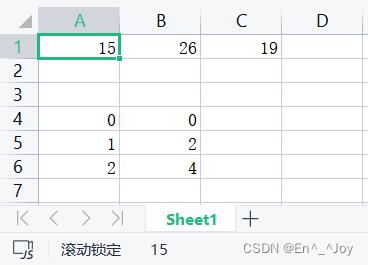
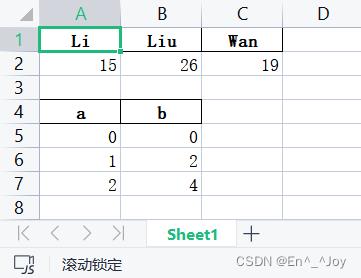
将header=False改为header=True之后
a.to_excel(writer, sheet_name='Sheet1', index=False, header=True, startrow=0, startcol=0)
b.to_excel(writer, sheet_name='Sheet1', index=False, header=True, startrow=3, startcol=0)
Pandas读取数据
读取CSV表格数据
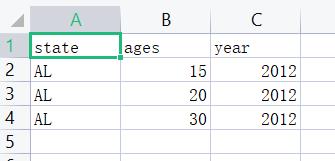
pop = pd.read_csv('a.csv')
print(pop.head())
'''
state ages year
0 AL 15 2012
1 AL 20 2012
2 AL 30 2012
'''
读取Excel表格数据
默认读取第一个表格
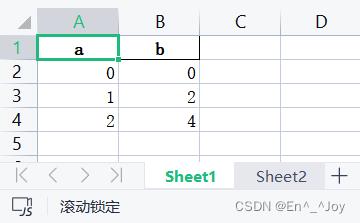
import pandas as pd
a = pd.read_excel('a.xlsx')
print(a.head())
'''
a b
0 0 0
1 1 2
2 2 4
'''
运行可能会报错:xlrd.biffh.XLRDError: Excel xlsx file; not supported
需要将xlrd降级,先删除:pip uninstall xlrd
再下载更低等级:pip install xlrd==1.2.0
sheet_name参数可以是数字、列表名
sheet_name为数字时,sheet_name=1表示读取第二个表格,数字从0开始
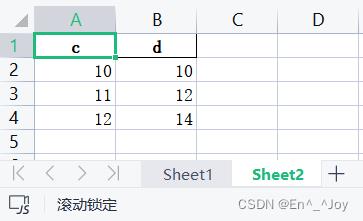
import pandas as pd
a = pd.read_excel('a.xlsx',sheet_name=1)
print(a.head())
'''
c d
0 10 10
1 11 12
2 12 14
'''
sheet_name为列表名时,sheet_name=‘a’表示读取列表名对应的表格

import pandas as pd
a = pd.read_excel('a.xlsx',sheet_name='a')
print(a.head())
'''
c d
0 10 10
1 11 12
2 12 14
'''
一次读取多个表格,返回字典

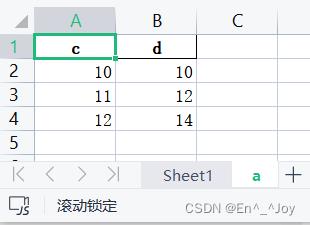
import pandas as pd
a = pd.read_excel('a.xlsx',sheet_name=['Sheet1','a'])
print(a)
'''
'Sheet1': a b
0 0 0
1 1 2
2 2 4, 'a': c d
0 10 10
1 11 12
2 12 14
'''
header参数:用哪一行作列名
默认为0 ,如果设置为[0,1],则表示将前两行作为多重索引

import pandas as pd
a = pd.read_excel('a.xlsx',sheet_name='a', header=[0,1])
print(a)
'''
c d
10 10
0 11 12
1 12 14
'''
names参数:自定义最终的列名
长度必须和Excel列长度一致,否则会报错
import pandas as pd
a = pd.read_excel('a.xlsx',sheet_name='a', names=['q','w'])
print(a)
'''
q w
0 10 10
1 11 12
2 12 14
'''
index_col参数:用作索引的列
参数值可以是数值,也可以是列名
import pandas as pd
a = pd.read_excel('a.xlsx',sheet_name='a', index_col = [0, 1])
print(a)
'''
e f
c d
10 11 12 13
11 12 13 14
12 14 16 18
'''
usecols参数:需要读取哪些列
import pandas as pd
a = pd.read_excel('a.xlsx',sheet_name='a', usecols = [0, 1, 3])
print(a)
'''
c d f
0 10 11 13
1 11 12 14
2 12 14 18
'''
import pandas as pd
a = pd.read_excel('a.xlsx',sheet_name='a', usecols = 'A:B, d')
print(a)
'''
c d f
0 10 11 13
1 11 12 14
2 12 14 18
'''
squeeze参数:当数据仅包含一列
squeeze为True时,返回Series,反之返回DataFrame

import pandas as pd
a = pd.read_excel('a.xlsx',sheet_name='Sheet1', squeeze=True)
print(a)
'''
0 0
1 1
2 2
Name: 3, dtype: int64
'''
import pandas as pd
a = pd.read_excel('a.xlsx',sheet_name='Sheet1', squeeze=False)
print(a)
'''
3
0 0
1 1
2 2
'''
skiprows参数:跳过特定行
skiprows= n, 跳过前n行; skiprows = [a, b, c],跳过第a+1,b+1,c+1行
import pandas as pd
a = pd.read_excel('a.xlsx',sheet_name='a', skiprows = 2)
print(a.head())
'''
11 12 13 14
0 12 14 16 18
'''
import pandas as pd
a = pd.read_excel('a.xlsx',sheet_name='a', skiprows = [0,1])
print(a.head())
'''
11 12 13 14
0 12 14 16 18
'''
nrows参数:需要读取的行数

import pandas as pd
a = pd.read_excel('a.xlsx',sheet_name='a', nrows=2)
print(a.head())
'''
c d e f
0 10 11 12 13
1 11 12 13 14
'''
skipfooter参数:跳过末尾n行
import pandas as pd
a = pd.read_excel('a.xlsx',sheet_name='a', skipfooter=2)
print(a.head())
'''
c d e f
0 10 11 12 13
'''
以上是关于Pandas读写文件操作的主要内容,如果未能解决你的问题,请参考以下文章