笔记︱目标人群优选的Look-aLike Modeling案例集锦
Posted 悟乙己
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了笔记︱目标人群优选的Look-aLike Modeling案例集锦相关的知识,希望对你有一定的参考价值。
如果把广告主圈出来的那 10w 用户称为种子用户(「seed users」),那么我们可以把需要额外提供的一批相似的用户称之为 「look-alike users」。我们把这种基于种子用户进行相似人群扩展的过程称之为 「look-alike modeling」。所以,look-alike 并不是某种特定的算法,而是一类建模方法的统称。
笔者自己总结比较常规的技术路线是四条:
- TGI的标签扩散方案,基本可以不用算法,通过数据统计就可以;而且可以往:相关品类/竞品/品牌/搜索/流失人群等扩散
- 优势:逻辑简单
- 劣势:人力成本消耗
- 用户社交关系扩散SNA,通过转发行为等进行得人群关系网络构建
- 优势:专注于用户关系发现,这个一般可以和其他方法搭配使用,作为人群放大的一种补充方式;会用到图网络,而且一般是大规模的图网络
- 劣势:没有商品信息融入;需要用用户关系的场景,微博转发,一般数据中台的回收数据可能会比较少
- 种子人群建模,进行扩散,比较科学的一种方式,很多营销数据平台中内嵌了这类建模算法,PU Learning范畴
- 优势:技术含量高,而且技术含量跨度较大,如果是常规的ML,需要额外注意特征工程,消耗量不必TGI少,当然如果又行业经验积累复用同一批还可以
- 劣势:可见[1.1.6]的文章,如果项目多了,不同项目都需要重复建模
- 相似度的 look-alike,大体思路是把所有用户做 user embedding,映射到低维的向量中,对它做基于 k-means 或者局部敏感 hash 做聚类,根据当前用户属于哪个聚类
- 优势:性能强。因为简单,只需要找簇中心,或者向量相似度的计算
- 劣势:因为简单、性能好,模型准确性低;需要工程化部署与实验尝试,且该算法本身不能很好得进行“联想”
- 方法论上:简单的话,如果获得用户embedding,可以用协同过滤的,几种上了规模的模型:spark-ALS,itemCF等
结合业务来看,也有一些场景/活动促销非常特殊,需要结合时点,需要单独建模,可见[1.1.6]
文章目录
- 1 阿里技术 Look-aLike Modeling案例
- 2 Look-alike 算法在微信看一看中的应用
- 3 广告科技公司 Turn Look-alike
- 4 Yahoo Look-alike
- 5 Linkedin Look-alike
- 6 Pinterest Look-alike
- 7 网易云音乐广告算法实践
- 8 Lookalike 在爱奇艺广告投放中的应用
- 9 参考文献
1 阿里技术 Look-aLike Modeling案例
1.1 策略中心的品牌人群定向模型
1.1.1 模型方案
策略中心年货节投放海豹项目,通过大数据+算法的手段,对A品牌的目标人群进行分析,建立人群优选算法模型,挖掘品牌目标潜客。品牌A的年货节实际投放效果,算法优选人群相比基于业务经验使用规则圈选的人群,在“O->IPL”人群关系加深率指标上好47%,显示了人群优选算法的有效性。
业界相关方案主要与程序化广告中人群定向相关,方法基本都是Look-alike人群扩散,具体有以下几种:
- 1)标签扩散:根据已有目标用户画像,给用户打各种标签,再利用标签找到机会人群。
- 2)基于标签的协同过滤:在标签扩散的基础上,采用基于用户的协同过滤算法,找到与种子人群相似的机会人群。
- 3)基于社交关系的扩散:以具有相似社交关系的人也有相似的兴趣爱好/价值观为前提假设,利用社交网络关系进行人群扩散。
- 4)基于聚类的扩散:根据用户画像或标签,采用层次聚类算法(如BIRCH或CURE算法)对人群进行聚类,再从中找出与种子人群相似的机会人群。
- 5)目标人群分类方法:以种子人群为正样本,候选对象为负样本,训练分类模型,然后用模型对所有候选对象进行筛选。涉及PU Learning的问题。
根据项目目标,我们制定了“种子人群聚类细分+聚类人群扩散”和“多方向人群扩散+人群分类优选”的两种方案。由于聚类分群属于无监督学习且分群效果不容易评估,因此选择后者优先实施。
方案整体流程如下图所示:
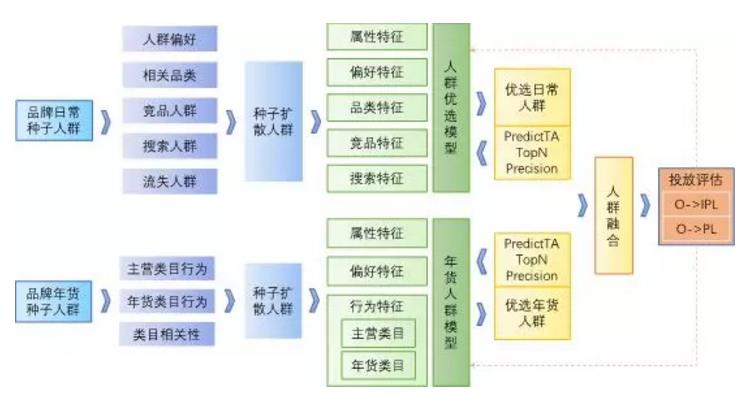
1.1.2 模型评估指标
训练集的正负样本,分别从品牌已购人群和其他品牌的人群中采样得到。从中训练的分类模型,可以较好的区分品牌目标人群和全网其它人群(大都和目标人群相距较远),但对区分和品牌目标人群相距不远的扩散人群则并非同样有效。
因此,直接使用传统的分类指标,只能评估模型在训练集上的效果,不能准确评估其在扩散人群上的分类效果,需要设计新的评估指标。
PredictTA TopNPrecision指标由此而来,表示优选的TopN人群中品牌目标人群的占比,该指标越大说明模型预测效果越好。我们通过对比该指标在不同模型上使用不同topN值的值,验证了它的一致性;并设计NewTA topN Recall指标,即优选人群在之后一段时间品牌新增目标人群的占比,验证了它的正确性。
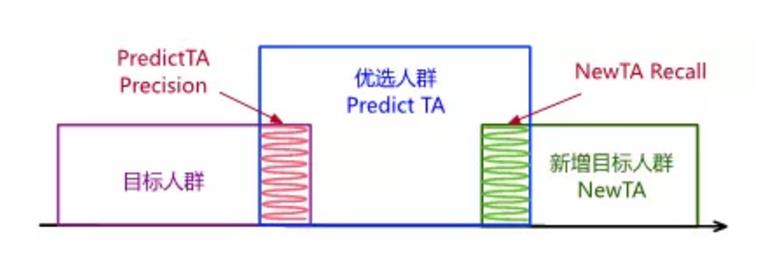
上图中,紫色框表示品牌目标人群即种子人群,蓝色框表示模型优选出的TopN人群,它与种子人群有小部分交集,交集占蓝色框的比例即为PredictTATopN Precision。绿色框表示一周内品牌实际新增人群,与蓝色框的交集为预测准确的人群,交集占绿色框的比例即为NewTA topN Recall。
1.1.3 样本选择
a. 正样本选择:对于线上市场份额大的品牌而言,直接用品牌已购人群即可。但对新品牌或者线上市场份额小的品牌,已购人群可能很小,这时就需要对正样本进行扩充,比如加入兴趣人群、加入与品牌定位相似的其它品牌的人群。
b. 负样本选择:默认从全网其它品牌的人群中随机采样,但发现全网人群中特征缺失的情况比较多,负样本集离扩散人群比较远,因此实验了从全网其它品牌的已购人群中采样,PredictTA TopN Precision(N=300万)指标绝对值有0.8%的提升。
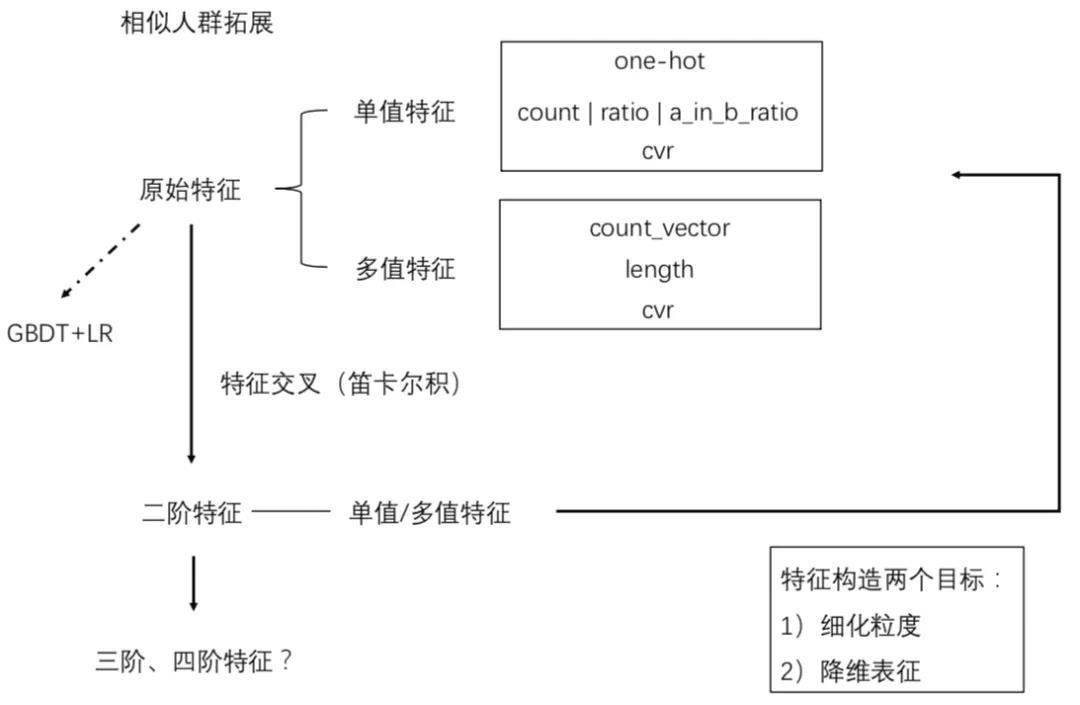
1.1.4 特征工程
a. 数值型特征离散化。年购物天数、近30天订单数等特征进行等距离散,提高模型稳定性和效果。
b. 枚举型特征值筛选。汽车型号、收货省份等特征长尾分布非常明显,筛选出与目标品牌相关的特征值。
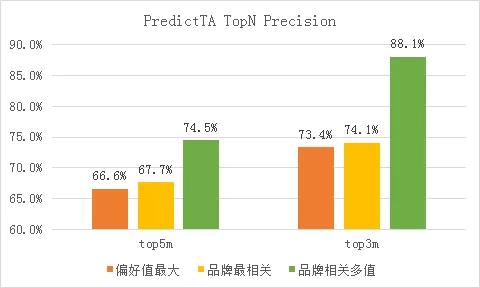
c. 多值特征处理。偏好品牌、偏好类目这样的特征,一个用户可以同时有多个特征值。以品牌A品牌为例,我们在b步筛选的基础上,对比了只保留偏好值最大的特征、只保留品牌最相关的特征、保留品牌相关的多个特征3种不同的处理方法,效果如下:
d. 特征编码。主要采用one-hot编码方式。
e. 稀疏特征embedding。对于类目id,品牌id这种高维高稀疏性的特征,直接将其作为分类模型的特征会影响最终的模型效果,为此,我们借鉴word embedding的思路,将用户过去一段时间内对类目(或品牌)的行为序列作为doc,将类目(或品牌)本身作为word,基于全网活跃用户的行为序列(doc集合)训练类目(或品牌)的embedding表示。具体而言,我们将类目(或品牌)编码为100维的低维稠密向量,并将其作为预测特征用于模型训练。
1.1.5 训练模型
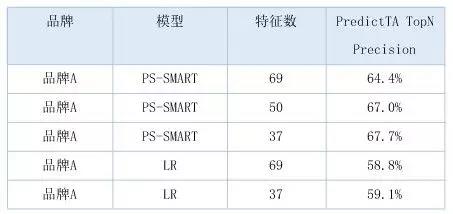
a. LR模型。使用逻辑回归作为baseline的算法,除了模型简单容易理解外,还有个好处是可以得出特征和特征值的重要性。
b. RF模型。对随机森林模型的实验效果并不理想,在相同的样本和特征上Precision和AUC指标均比LR低,且特征重要性结果只能到特征粒度不能到特征值粒度,因此不再使用。
c. PS-SMART。基于PS架构的GBDT算法模型,决策树弱分类器加上GBM算法,具有较强的非线性拟合能力,在应用中相比其它两种算法模型效果更好。因此选择PS-SMART作为最终的算法模型,并对损失函数、树的个数深度、正则系数进行调优。
1.1.6 年货人群模型
此次品牌投放需求临近春节,与年货的相关性很大。虽然可以用最新的样本数据训练日常的目标人群优选模型,但人群扩散方向和相关特征并非针对年货场景而挖掘的,因此不能有效捕捉出于屯年货动机的消费需求,需要针对年货场景单独建立一个人群模型进行预测。
-
样本选择:根据投放时间的农历日期,选取去年当日前1个月有行为的用户做样本。其中以去年当日到元宵节期间转化到品牌PL状态的用户为正样本,随机采用同等数量的其他用户为负样本,训练年货人群模型。
-
模型训练:基于日常人群优选模型的经验,同样采用PS-SMART算法进行模型训练、优化、及特征重要性分析。
-
模型预测:圈选投放日期前1个月对品牌主营类目及相关年货类目有行为的用户,使用年货人群模型进行预测,去除预测分数小于0.5的用户,根据拉新目标去除品牌现有IPL人群。
1.1.7 品牌人群优选模型几个问题
6.2 无历史反馈数据
品牌人群优选模型,由于没有品牌投放历史,不能从用户的历史投放反馈中来学习品牌人群特征。尤其是不能获取大量直接的负样本,只能以随机人群来代替,在样本选择上还有很大的提升空间。
6.3 无历史属性特征
年货人群模型和时间紧密相关,但由于存储周期的原因,只能获取用户去年的行为特征,而无法获取去年的属性和偏好特征,只能用近期的属性和偏好特征来代替,在特征实效性上也有较大提升空间。
6.4 重要的稀疏特征
模型使用的特征中有较多的稀疏特征,这些特征的特征值呈长尾分布,全部使用会引入很多噪声影响模型效果,只选高频特征又会丢失较多信息,为此我们采用特征值的TGI和TA浓度两个指标综合筛选,达到保留相关特征值、减少噪音和信息丢失的目的。
6.5 有效的评估指标
也是由于无历史反馈数据,导致用于优选的扩散人群与训练模型的人群分布有较大差异,单纯的AUC、Precision等指标不能准确衡量优选模型在扩散人群上的效果,为此我们设计并验证了PredictTA TopN Precision评估指标,有效指导了模型的优化。
1.2 淘系用户增长:揭秘淘宝如何进行目标用户的挖掘
文章来源:财报背后的强劲增长 | 揭秘淘宝如何进行目标用户的挖掘【技术人必看!】
1.2.1 背景与使用模型
用户增长平台的目标是希望能构建面向全域运营人员的全维度用户智能洞察分析体系,帮助运营高效触达目标人群。现有运营基于业务经验,将业务需求转化为一系列标签,根据标签筛选出符合条件的目标人群,该方法涉及到的数据链路较长,无法及时支持业务投放。在保证潜在人群与目标人群相似性的前提下,帮助各个垂直业务的运营同学自动化的实现保量提效的投放目标。本文主要介绍在此背景下的相似人群挖掘算法中通用特征体系若干特征处理方法。
一般进行投放时,先通过种子人群找到扩展人群,其后将扩展人群作为运营触达的目标用户,当有多个种子人群时,可以先找到各个种子人群的扩展人群,然后取各个种子人群的扩展人群的交集作为最终投放的目标用户。
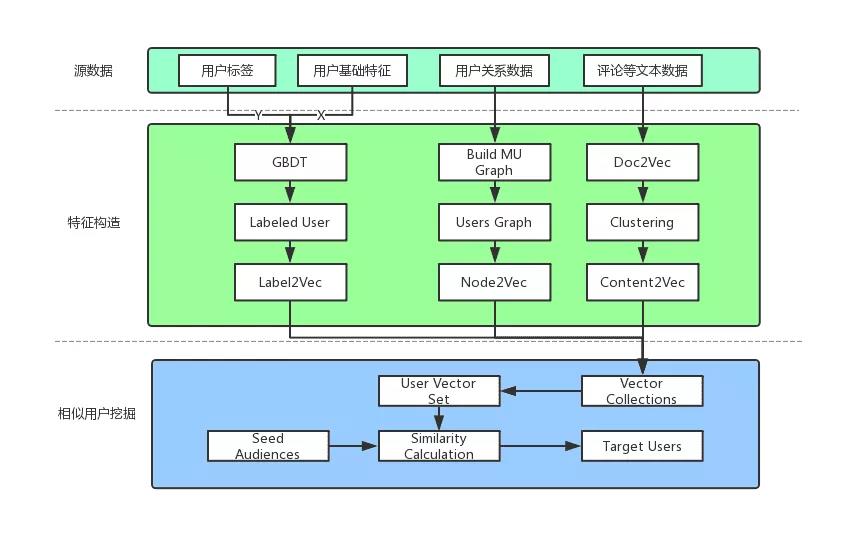
使用的数据:
- 提取用户基础属性数据,如性别、年龄、学历、职业、地域、能力标签等;
- 抽取平台已积累用户标签(Audience label);
- 提取用户的评论信息等文本内容,进行观点挖掘和倾向性分析;
- 提取用户之间的关系,比如亲情号相关,分享、转发关系等
根据用户基础特征和已有的标签体系。利用 GBDT 算法将没有标签的用户全部打上标签。
将标签进行向量化处理,可以用 Label2Vec(类似word2vec)方法处理后得到用户标签的向量化信息,在模型效果上有 0.5% 左右的提升。
将上述步骤中得到的向量做拼接,得到表示每个用户的多特征向量集(User Vector Set,UVS)。最后的特征输出表达了用户的社交关系、用户属性、发出的内容、感兴趣的内容等混合特征向量。
将全量用户的多特征向量集进行聚类,然后提取每个类别的中心向量和以用户 ID 作为主键以离线形式存储,当运营人群上传种子人群后,采取同样的方式计算得到种子人群的若干类别中心向量。
1.2.2 人群挖掘的方式
- 获取种子用户 user_id ,以及期望获取的相似人群数量N;
- 检查种子用户是否存在于 UVS 中,将存在的用户向量化,并进行在线聚类,输出种子人群类簇中心;
- 计算潜在用户群类簇中心和种子用户类簇中心的相似度,提取最相似的前 topN 个类簇作为召回类簇;
- 通过分类器对步骤 3 中召回的潜在类簇进行精准截断输出。
1.2.3 离线评估指标:覆盖度 + 相似度
覆盖度
由于相似人群挖掘属于无监督学习,且模型效果无法通过单纯的 AUC、Precision 等指标准确评估,所以需要设计新的评估指标来有效指导模型的优化。
覆盖度指标由此而来,对种子人群进行随机采样,切分为 A、B 两个人群, A 人群通过相似人群挖掘算法得到扩散后的人群 C ,覆盖度 =B∩C/B ,覆盖度表示扩人群中人群 B 的占比,考验的是算法通过人群 A 对人群 B 的“恢复”能力,具体实验中通过将种子人群进行 5 倍扩散后根据相似人群的覆盖度是否有提升来对模型进行迭代优化。
相似度
扩展人群相似度概念的提出主要有以下几点原因:
- 在人群规模探查阶段,运营希望在人群相似度可控的范围内探查潜在人群的规模,使用相似人群查找之前并不会明确给出目标人群的数量;
- 若将同一种子人群通过随机降采样缩小 10 倍和缩小 5 倍,然后分别通过相似人群挖掘算法得到扩展 5 倍后的人群及其覆盖度,自然缩小 5 倍的人群作为种子人群扩散后的覆盖度较高,但人群覆盖度指标并不能完全表征相似人群与种子人群的的近似程度,需要配合人群相似度一起评估。
人群相似度计算步骤:
- 分别计算扩散人群到种子人群聚类中心的 cosine 距离;
- 按照步骤 1 的结果进行最大最小值归一化,将值域归一化到 [0,1] 之间;
- 根据 sigmoid 函数,将步骤 2 产生的归一化后结果通过 sigmoid 函数移动到 [0.5,1) 之间。
人群相似度基于扩散人群与种子人群间的距离计算,能够表征扩散人群与种子人群的相似程度,运营通过设置固定的人群相似度阈值,能够直接获得潜在人群的规模并进行下一步的分析或者营销活动。
2 Look-alike 算法在微信看一看中的应用
参考:
PALM:实时 Look-alike 算法在微信看一看中的应用
RALM: 实时 look-alike 算法在推荐系统中的应用
《五个工业风满满的 Look-alike 算法》
2.1 业务背景:高时效性要求
微信看一看团队在 KDD2019 上发表的一篇论文,文章在 look-alike 方法基础上,针对微信看一看的应用场景设计了一套实时 look-alike 框架,在解决长尾问题的同时也满足了资讯推荐的高时效性要求。
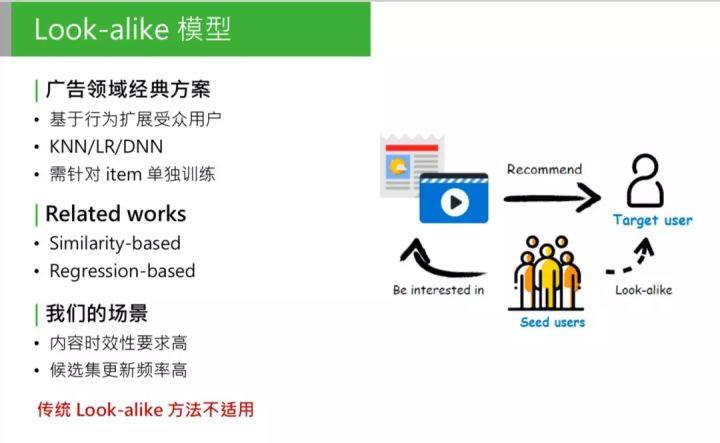
Look-alike 在广告领域的应用已经很完善,也有很多方式。可以把 look-alike 相关的研究分成两个方向:
- 第一种是基于相似度的 look-alike,这种 look-alike 比较简单,大体思路是把所有用户做 user embedding,映射到低维的向量中,对它做基于 k-means 或者局部敏感 hash 做聚类,根据当前用户属于哪个聚类,把这个种子用户的类感兴趣的内容推给目标用户。
这种方法的特点:性能强。因为简单,只需要找簇中心,或者向量相似度的计算,因为简单、性能好,模型准确性低。 - 第二种是和第一种相反的,基于回归。包括 LR,或者树模型,或者 DNN or deep model 的方法,主要思路是直接建模种子用户的特征。
把种子用户当做模型的正样本, 针对每个 item 训练一个回归模型,做二分类,得出种子用户的特征规律。
这种方法的优点是:准确性高,因为会针对每个 item 建模。
缺点也明显:训练开销大,针对每个 item 都要单独训练一个模型。对于广告来说,可以接受,因为广告的候选集没有那么大,更新频率也没那么高。
但是对于我们的推荐场景,有一些问题:
- 对内容时效性要求高,如推荐的新闻专题,必须在5分钟或10分钟内要触达用户;
- 候选集更新频率高,我们每天的候选集上千万,每分钟、每一秒都有新内容,如果新内容无法进入推荐池,会影响推荐效果。
2.2 模型设计
在我们的场景下,如果还用广告领域的经典的 look-alike,是无法解决的。
如果要对每个候选集建模,采用 regression-base 的方法,如每分钟都要对新加进来的候选集做建模,包括积累种子用户、做负采样、训练,等模型收敛后离线预测 target user 的相似分,这对于线上的时效性是不能接受的。
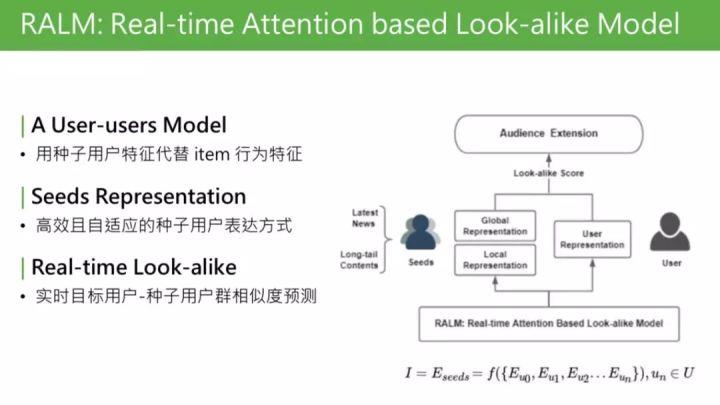
① 模型可总结为 user-users 的 model。回想下经典的 CTR 预估模型,是 user2item 的 point-wise 的处理流程建模。User、item、label,我们做的最大的变化,是借鉴了 look-alike 的思想,把 item 替换成种子用户。用种子用户的用户特征,代替 item 的行为特征。所以模型从 user2item 的 model,变成 user2user 的 model。
② 完善的 seeds representation。用种子用户代替 item 行为特征。这样面临的问题是:怎样更好地表达一个人群。这个 seeds representation,是我们研究中的核心步骤
③ real-time。最终目标是部署在线上,实时预测种子用户群体相似度,需要是能够实现 real-time 的框架。
线上需要实现实时预测,系统实际部署到线上,需要整套系统架构。简单介绍下 RALM 的配套体系。
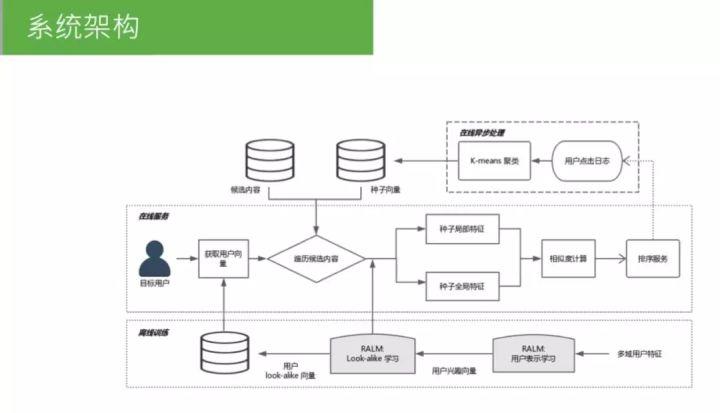
3 广告科技公司 Turn Look-alike
Look-alike 有多种类型,包括基于相似计算的 「Similarity-based」,基于回归模型预测的 「Regression-based」,基于标签相似性的 「Approximation-based」,基于用户相似网络的 「Graph-based」,基于 attention 优化的 「Attention-based」等。
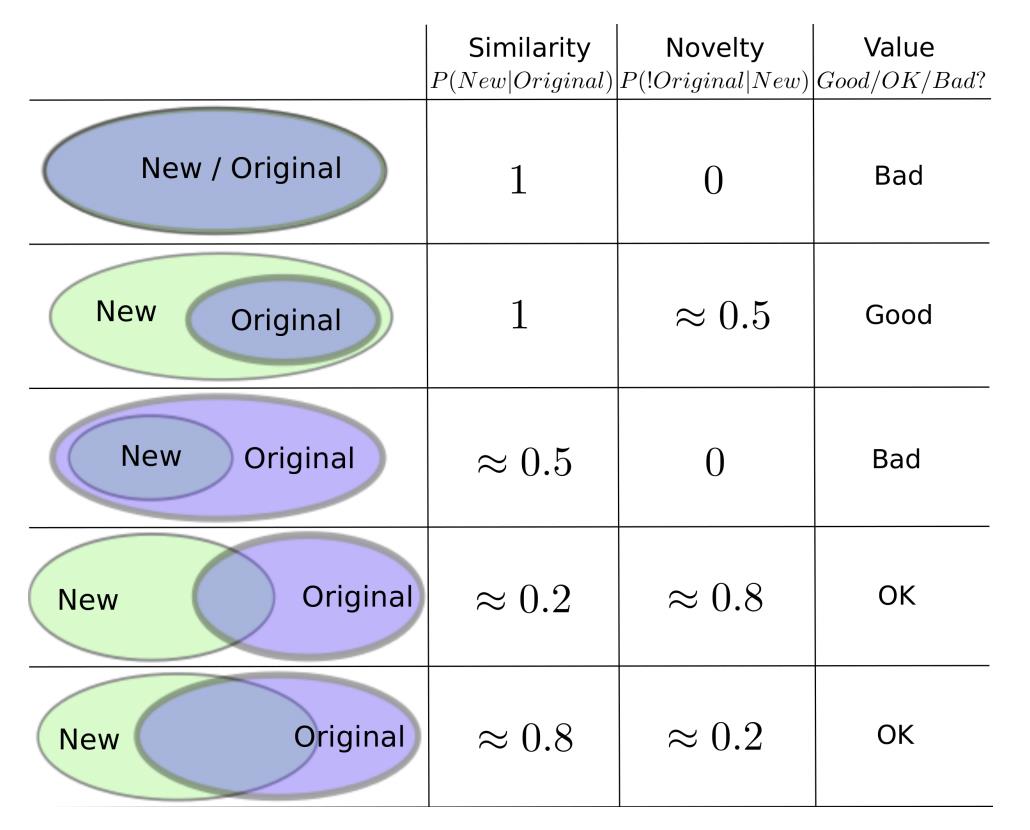
Weighted Criteria-based Algorithm 是由广告科技公司 Turn 构建的一套 Approximation-based 算法,发表于 ACM 2015,该算法主要是通过计算相关标签进行人群扩散,其从相似性、新奇性和质量分三个角度综合评估标签对。
相似性公式:
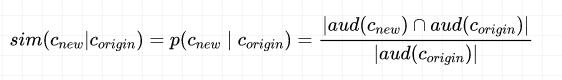
新奇性的计算公式:
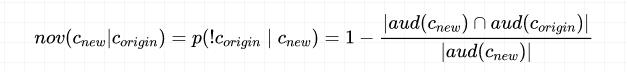
还要定义质量分 q,其主要包括 CTR、CVR、ROI,这个可以自己的特定场景自己定义。
我们对上述三种指标进行加权相乘: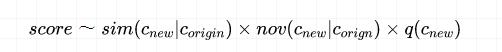
取 log,加上权重得到最终的评估结果,然后我们便算出了标签之间的分数,并可以利用相似标签进行人群扩展。
4 Yahoo Look-alike
Look-alike 有多种类型,包括基于相似计算的 「Similarity-based」,基于回归模型预测的 「Regression-based」,基于标签相似性的 「Approximation-based」,基于用户相似网络的 「Graph-based」,基于 attention 优化的 「Attention-based」等。
Yahoo Look-alike Model 是 Graph-based,其结合了 Similartiy-based 和 Regression-based 方法,系统架构如下: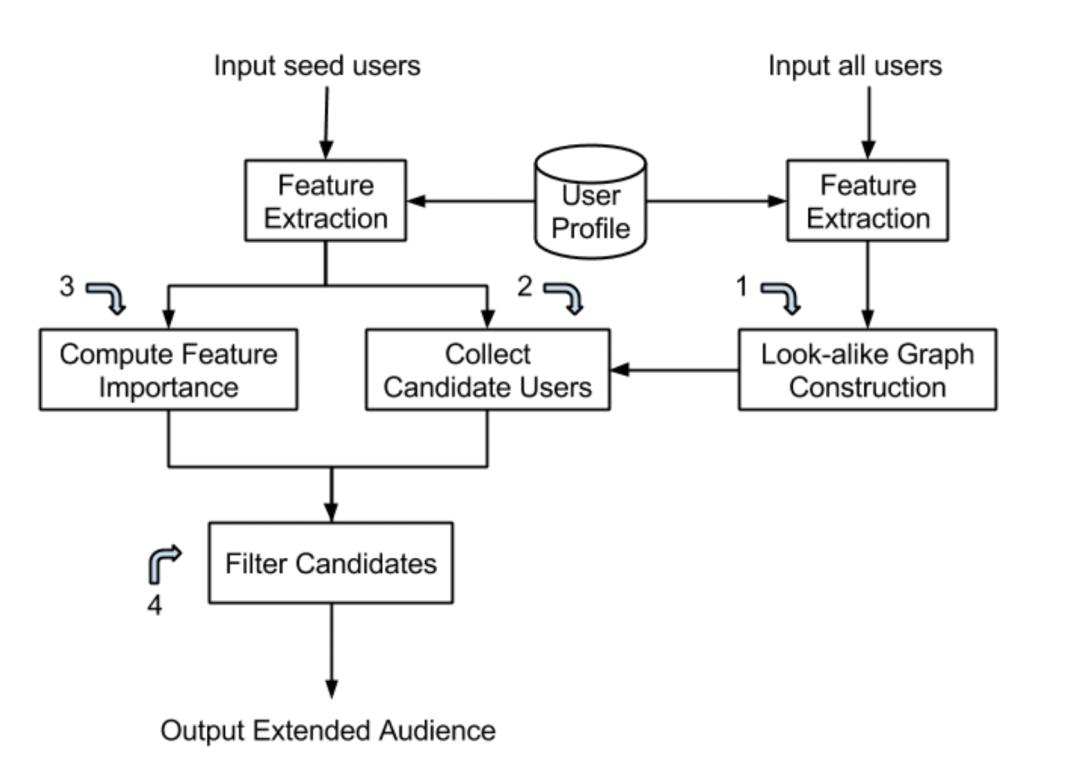
主要包含四个部分:
- 基于用户间相似度构建用户相似网络,并利用 LSH 对用户进行分桶;
- 粗召回:将种子用户在同一个桶的用户作为候选用户;
- 特征筛选:基于特征 IV 进行特征筛选,挑出能代表种子用户的正特征;
- 精排序:计算用户得分并排序,返回得分最高的用户集。
5 Linkedin Look-alike
Look-alike 有多种类型,包括基于相似计算的 「Similarity-based」,基于回归模型预测的 「Regression-based」,基于标签相似性的 「Approximation-based」,基于用户相似网络的 「Graph-based」,基于 attention 优化的 「Attention-based」等。
Linkedin 在 KDD 16 上发表了他们的 look-alike 系统,其架构如下图所示:
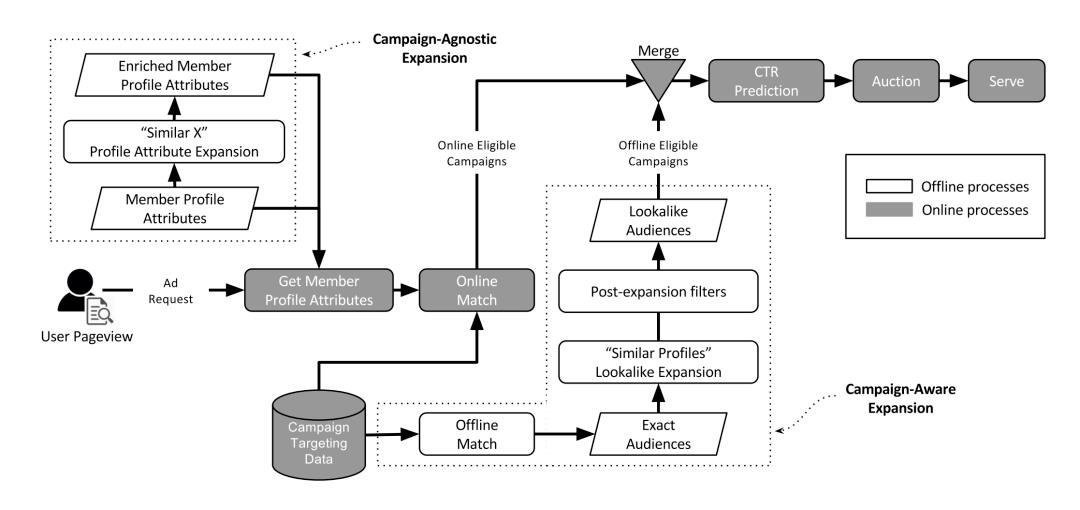
大致分为线上和线下两部分,分别称为 「Campaign-Agnostic Expansion」 和 「Campaign-Aware Expansion」。
- 「Campaign-Agnostic Expansion」 框架主要是利用实体进行扩展,比如 Data Mining 可以扩展到 Big Data 和 Machine Learning。该框架的算法是采用 LR 模型去从历史交互数据中捕获实体间的相似性,这种扩展方法可以直接在系统中使用 (不需要再去额外计算)。
- 「Campaign-Aware Expansion」 框架是采用近邻搜索,基于用户的属性进行相似用户扩展。
Linkedin 将每个实体建模为一个多域的结构化 doc(structured multi-fielded document),并提取四种类型的字段,包括:n-grams/词典、标准化命名的数据类型(standardized,公司名、行业名等)、派生数据类型(derived,互联网公司可以派生出网络开发、软件开发等)和相近实体(proximities,基于用户和公司交互的网络确定其他相关公司)。举个例子:
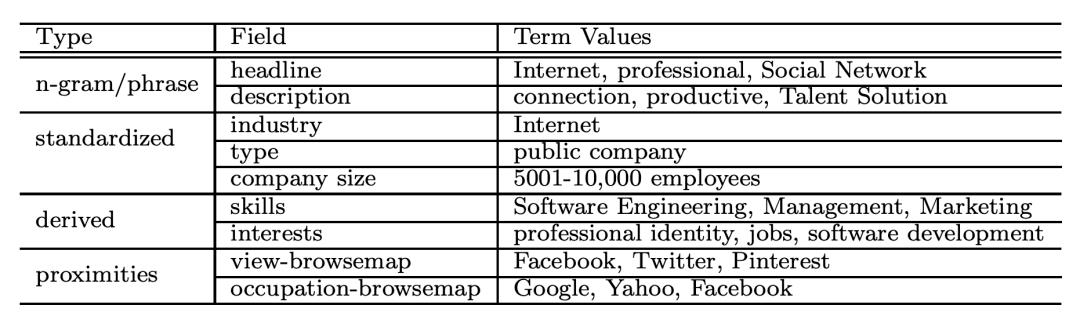
Linkedin 将用户和公司分别进行上述实体建模,然后将用户关注的公司作为正样本,没关注的公司作为负样本,并用 LR 模型进行训练。
PS:会不会出现极端情况,导致召回量不够。
6 Pinterest Look-alike
Look-alike 有多种类型,包括基于相似计算的 「Similarity-based」,基于回归模型预测的 「Regression-based」,基于标签相似性的 「Approximation-based」,基于用户相似网络的 「Graph-based」,基于 attention 优化的 「Attention-based」等。
Pinterest look-alike 于 KDD 19 发表了他们的 look-alike 模型,其大致分为两部分基于 LR 的分类模型和基于 Embedding 的相似搜索的模型。
Pinterest 的baseline 是用 LR 模型去做个分类模型,种子样本为正样本,随机选取非种子样本为负样本,然后训练一个分类模型去给所有用户打分排序。
Pinterest 探索的新方法,大致分为两块:
- 一块是训练 Embedding
- 另一块是基于 Embedding 和 LSH 找相似用户
首先是计算用户的特征向量,其基于 StarSpace 的方法进行训练(Pair-wise):
- 用户:用户作为 Piar A,concat 用户的离散特征+归一化后的连续特征,经过一层线性激活函数的 Dense,输出得到用户特征向量;
- Topic:Item 的 Topic 作为 Pair B,经过 lookup 得到 Topic 的特征向量;
- 训练样本:取与用户交户过的 Item,用 Item 的 Topic 作为 Pair B;其他随机选取 k 个的 Topic 作为负样本,与用户组成样本对;
- 训练集:与用户交户过的 Item 的 Topic 作为正样本,随机选取的 k 个 Topic 作为负样本
得到用户特征向量后,利用 LSH 对用户进行映射,然后基于种子用户的个数进行投票选出哪些区域,并取区域内用户作为扩展用户。
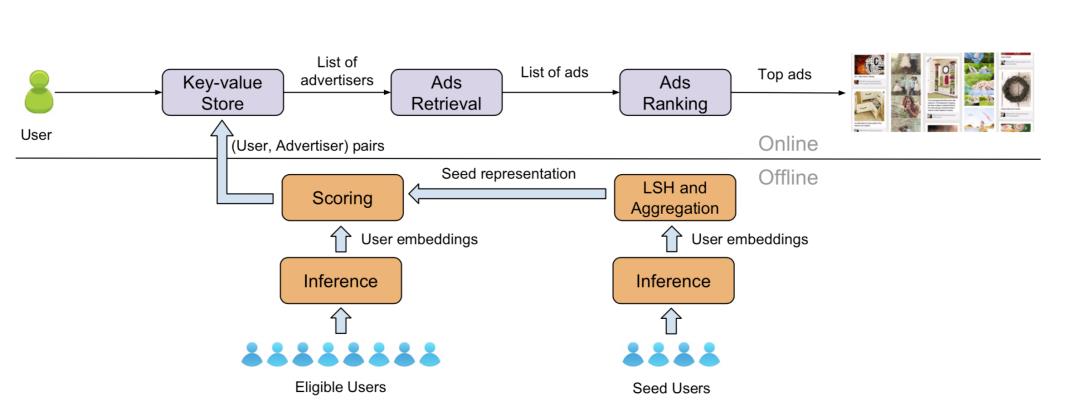
下方为离线计算:
- 首先,离线计算好用户的特征向量;
- 然后,基于种子用户 m 次映射结果,计算所有区域的得分;
- 再者,对最近访问过 Pinterest 用户计算得分,排序后卡一个阈值。(利用桶排序,阈值大小根据广告主需求排定,满足广告投放需求即可);
- 最后,组成 <user, adv> 进行广告投放
7 网易云音乐广告算法实践
来源于DataFun-2021的讲座分享《网易云音乐广告算法实践》
用户向量建模业务背景
问题:新广告投放冷启动
- 新广告、新广告主无历史投放记录
- CTR/CVR模型由于没有新广告的特征和样本,很难准确预估
Lookalike拓展相似人群的几种方式:
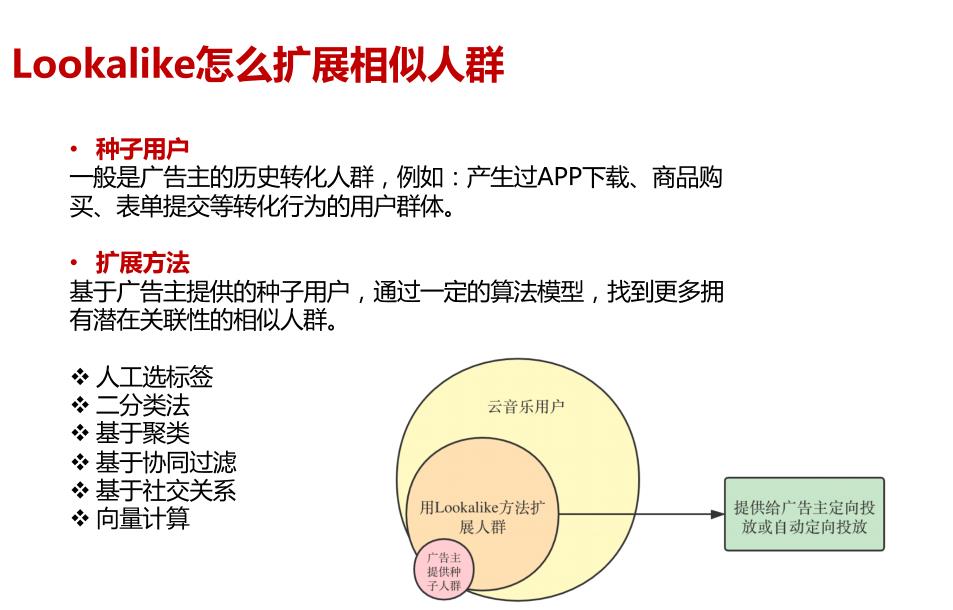
基于用户向量表示召回相似用户,计算种子用户的向量表示与候选用户的相似度,基于相似度打分来召回相似用户。
- 优点:用户向量可通用,能服务于所有广告主的扩量。
- 难点:如何有效地学习到用户向量表示。
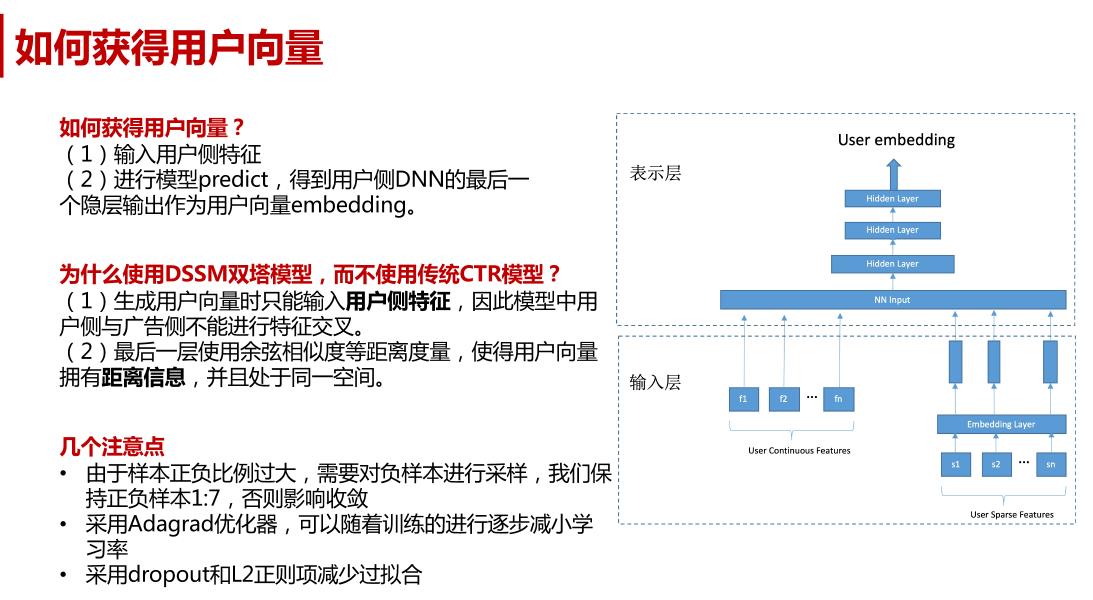
如何获得用户向量?
(1)输入用户侧特征
(2)进行模型predict,得到用户侧DNN的最后一个隐层输出作为用户向量embedding。
如何衡量候选用户与种子人群的相似度,措施:
- 种子人群向量聚类
使用种子人群的K个向量聚类中心表示种子人群 - K个聚类簇的重要程度衡量
增加种子人群每个聚类簇的历史统计CTR作为权重 - 候选用户与种子人群的相似度打分
(1)计算候选用户与K个聚类中心的向量余弦相似度
(2)使用K个聚类簇的权重对相似度进行加权
(3)选择候选用户与K个聚类中心的加权相似度的最大值作为候选用
户与种子人群的相似度打分
8 Lookalike 在爱奇艺广告投放中的应用
爱奇艺的广告业务场景下,先后探索实现了基于标签选择和基于机器学习的Lookalike算法,以下是这两种方法的简单介绍:
8.1 基于标签选择的Lookalike算法
通过对用户观影、搜索行为的深度挖掘,爱奇艺构建了丰富的用户画像体系,每个用户都拥有数以万计的标签,包括基础属性、兴趣偏好等。我们可以对种子用户进行画像分析,挑选出种子用户中表现显著的标签进行人群扩展。例如,分析某化妆品牌种子用户,发现性别<女>、年龄<18-25>、爱购物、喜爱观看时尚节目这些标签非常显著,可以从全站用户中寻找更多具备相同标签的用户提供给广告主作为扩展人群。
算法实现上我们参考了Yahoo的一篇论文[1],文中提出了一种对用户标签打分的方法,从标签覆盖用户和种子用户的相似度、新颖度及标签质量三个维度对所有标签进行打分排序,最后将TOP-N的标签所覆盖的用户作为扩展结果。三个维度具体含义如下:
- a) 相似度。衡量标签覆盖用户和种子用户的重合度,重合度越高,相似度得分越高。
- b) 新颖度。Lookalike最终目标是寻找新用户,新颖度用来衡量标签覆盖用户中新用户出现的比例,比例越高,新颖度得分越高。
- c) 标签质量。可以使用标签覆盖用户历史投放效果(如CTR、CVR、ROI等)作为评价指标。
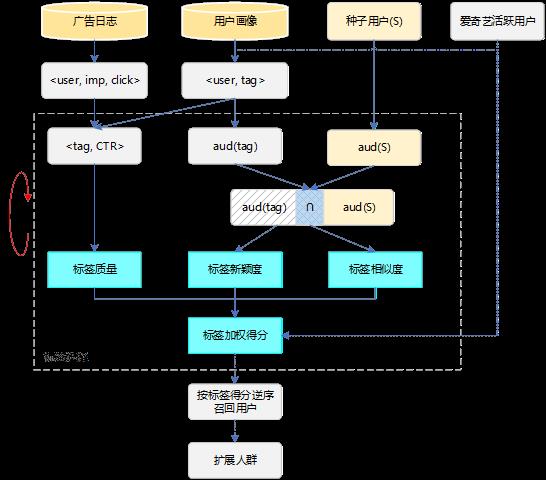
该方法的优点是原理简单,易于实现,有一定的解释性。缺点是调参复杂,需要反复线上实验,且按标签得分顺序召回粒度偏粗,无法从多个标签维度综合比较新用户和种子用户的相似度。
8.2 基于机器学习的Lookalike算法
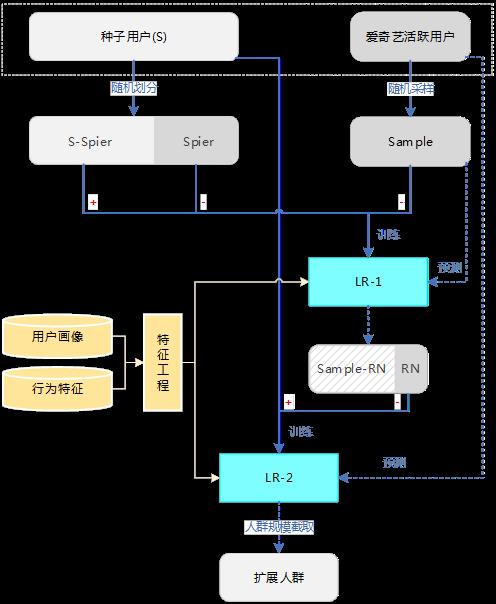
针对标签选择算法存在的问题,我们尝试用有监督的机器学习算法来解决Lookalike问题。将种子用户作为正样本,目标是预测活跃用户为正例的概率。具体实现包含以下步骤:
a) 正负样本划分
进行有监督学习遇到的第一个问题是缺少负样本,种子用户是正样本,其余用户是无标注样本。这和文本分类里的PU-Learning问题[2]类似,我们借鉴了相关思想,结合不同的场景,分别使用两种方法生成负样本:
- 使用广告主历史投放的负反馈(跳过广告、观看未点击)用户作为负样本。
- 使用Spy方法[3]自动生成一部分可靠的负样本(RN)。
b) 模型选择
在模型选择上,常用的分类模型都可以用于这一场景,例如LR、GBDT、FM等。具体到广告的业务场景中,由于我们希望模型具备较强的解释性,方便向广告主说明扩展人群特点,所以选择了LR作为线上使用的模型。
另外,由于扩展人群存在用户复现率的问题,相较普通投放缩小了广告触达的用户范围,可能导致订单缺量,为了避免缺量,最终的扩展人群除了考虑模型预测概率和广告订单预订量外,还加入了用户的历史访问频率进行综合排序。
c) 特征工程
在特征工程方面,除了爱奇艺DMP拥有的用户基础人口属性、观影偏好、搜索偏好、商业兴趣等数据外,我们还探索了用户在广告、行业等维度的行为特征(例如,用户对不同行业广告的反馈、广告对用户的新鲜度等),并取得了不错的效果。
9 参考文献
以上是关于笔记︱目标人群优选的Look-aLike Modeling案例集锦的主要内容,如果未能解决你的问题,请参考以下文章
笔记︱目标人群优选的Look-aLike Modeling案例集锦